Amazon Redshift는 2025년 11월 1일부터 새 Python UDF 생성을 더 이상 지원하지 않습니다. Python UDF를 사용하려면 이 날짜 이전에 UDF를 생성하세요. 기존 Python UDF는 정상적으로 계속 작동합니다. 자세한 내용은 블로그 게시물
Amazon Redshift Serverless 데이터 웨어하우스 시작하기
Amazon Redshift Serverless를 처음 사용하는 경우 Amazon Redshift Serverless 사용을 시작하는 데 도움이 되도록 다음 섹션을 읽는 것이 좋습니다. Amazon Redshift Serverless의 기본 흐름은 서버리스 리소스를 생성하고, Amazon Redshift Serverless에 연결하고, 샘플 데이터를 로드한 다음 데이터에 대해 쿼리를 실행하는 것입니다. 이 안내서에서는 Amazon Redshift Serverless 또는 Amazon S3 버킷에서 샘플 데이터를 로드하도록 선택할 수 있습니다. 샘플 데이터는 Amazon Redshift 설명서 전체에서 기능을 설명하는 데 사용됩니다. Amazon Redshift 프로비저닝 데이터 웨어하우스 사용을 시작하려면 Amazon Redshift 프로비저닝된 데이터 웨어하우스 시작하기 섹션을 참조하세요.
AWS에 가입
아직 계정이 없는 경우 AWS 계정에 가입합니다. 계정이 이미 있는 경우 이 사전 조건 단계를 건너뛰고 기존 계정을 사용할 수 있습니다.
온라인 지시 사항을 따릅니다.
AWS 계정에 가입하면 AWS 계정 루트 사용자가 생성됩니다. 루트 사용자에게는 계정의 모든 AWS 서비스 및 리소스에 액세스할 수 있는 권한이 있습니다. 보안 모범 사례는 관리 사용자에게 관리자 액세스 권한을 할당하고, 루트 사용자만 사용하여 루트 사용자 액세스 권한이 필요한 작업을 수행하는 것입니다.
Amazon Redshift Serverless를 사용하여 데이터 웨어하우스 생성
Amazon Redshift Serverless 콘솔에 처음 로그인하면 서버리스 리소스를 생성하고 구성하는 데 사용할 수 있는 시작하기 환경에 액세스하라는 메시지가 표시됩니다. 이 안내서에서는 Amazon Redshift Serverless의 기본 설정을 사용하여 서버리스 리소스를 생성해보겠습니다.
설정을 더 세밀하게 제어하려면 Customize settings(설정 사용자 지정)를 선택합니다.
참고
Redshift Serverless를 사용하려면 3개의 서로 다른 가용 영역에 3개의 서브넷이 있는 Amazon VPC가 필요합니다. 또한 Redshift Serverless에는 최소 3개의 사용 가능한 IP 주소가 필요합니다. 계속하기 전에 Redshift Serverless에 사용하는 Amazon VPC의 세 가용 영역에 3개의 서브넷이 있고 3개 이상의 사용 가능한 IP 주소가 있는지 확인합니다. Amazon VPC에서 서브넷을 생성하는 방법에 대한 자세한 내용은 Amazon Virtual Private Cloud 사용 설명서에서 서브넷 생성을 참조하세요. Amazon VPC의 IP 주소에 대한 자세한 내용은 VPC 및 서브넷의 IP 주소 지정을 참조하세요.
기본 설정으로 구성하려면:
AWS Management Console에 로그인한 후 https://console.aws.amazon.com/redshiftv2/
에서 Amazon Redshift 콘솔을 엽니다. Redshift Serverless 무료 평가판 사용해보기를 선택합니다.
-
Configuration(구성) 아래에서 Use default settings(기본 설정 사용)를 선택합니다. Amazon Redshift Serverless가 이 네임스페이스에 연결된 기본 작업 그룹을 사용하여 기본 네임스페이스를 생성합니다. 구성 저장을 선택합니다.
참고
네임스페이스는 데이터베이스 객체와 사용자의 모음입니다. 네임스페이스는 스키마, 테이블, 사용자, 데이터 공유 및 스냅샷과 같이 Redshift Serverless에서 사용하는 모든 리소스를 함께 그룹화합니다.
작업 그룹은 컴퓨팅 리소스의 모음입니다. 작업 그룹에는 Redshift Serverless가 컴퓨팅 작업을 실행하는 데 사용하는 컴퓨팅 리소스가 있습니다.
다음 스크린샷은 Amazon Redshift Serverless의 기본 설정을 보여줍니다.
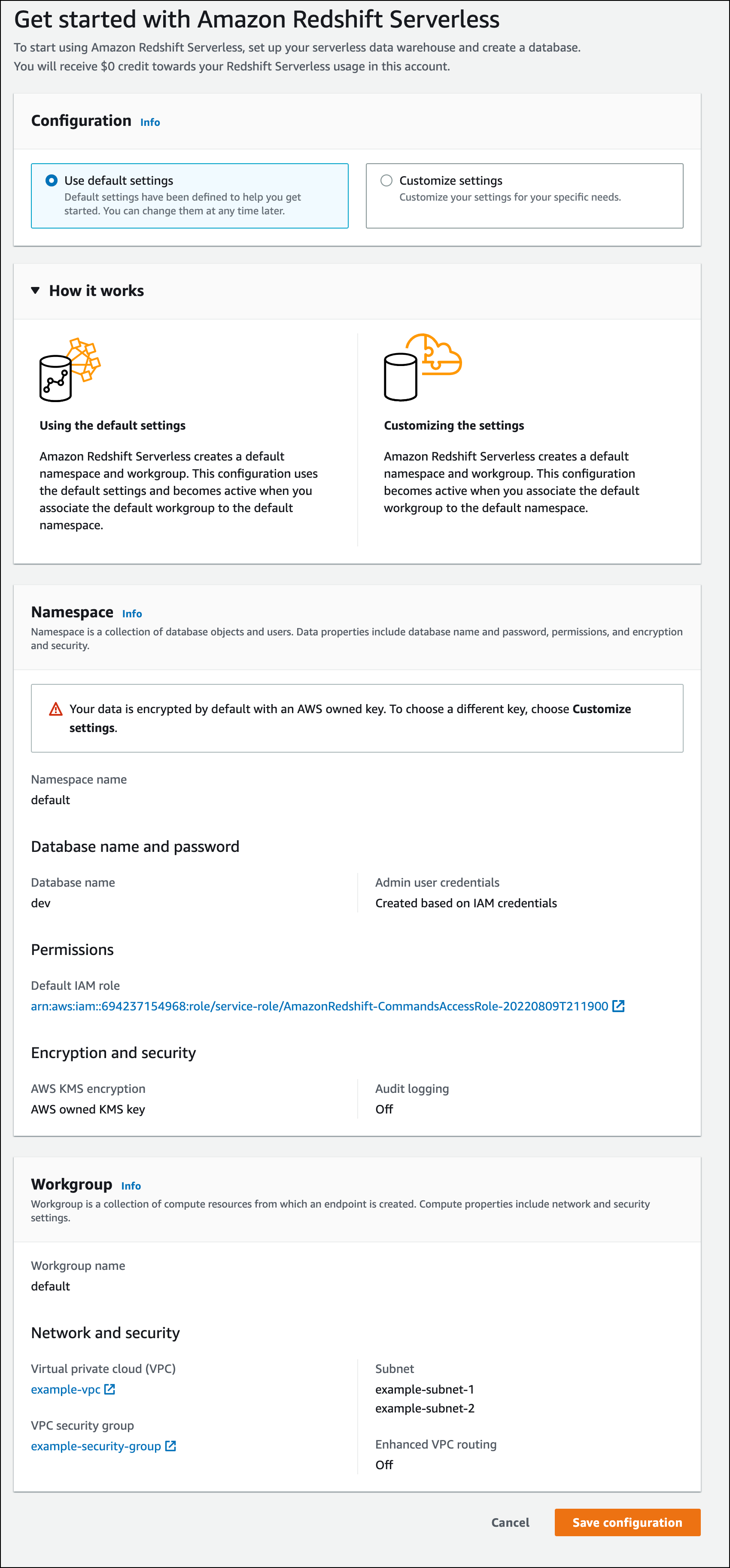
-
설정이 완료된 후 계속(Continue)을 선택하여 서버리스 대시보드(Serverless dashboard)로 이동합니다. 서버리스 작업 그룹과 네임스페이스를 사용할 수 있는 것을 확인할 수 있습니다.
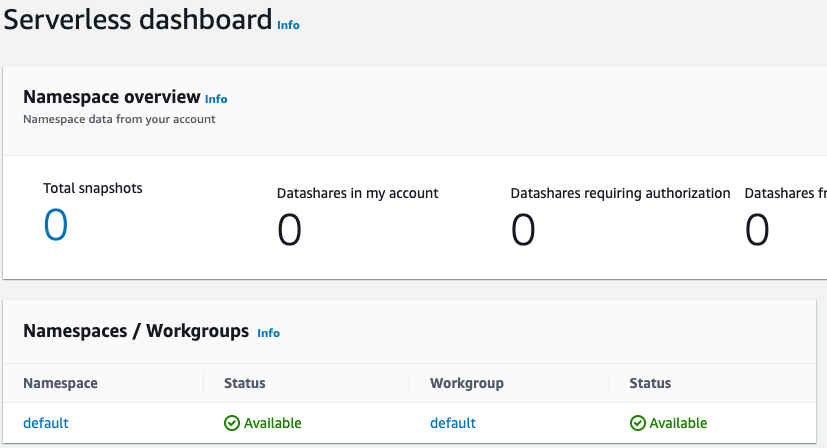
참고
Redshift Serverless가 작업 그룹을 성공적으로 생성하지 못한 경우 다음과 같이 해볼 수 있습니다.
Amazon VPC에 서브넷이 너무 적은 경우 등 Redshift Serverless에서 보고하는 오류를 모두 해결합니다.
Redshift Serverless 대시보드에서 기본 네임스페이스를 선택한 다음 작업, 네임스페이스 삭제를 선택하여 네임스페이스를 삭제합니다. 네임스페이스를 삭제하는 데 몇 분 정도 걸립니다.
Redshift Serverless 콘솔을 다시 열면 시작 화면이 나타납니다.
샘플 데이터 로드
Amazon Redshift Serverless로 데이터 웨어하우스를 설정했으므로 이제 Amazon Redshift 쿼리 에디터 v2를 사용하여 샘플 데이터를 로드할 수 있습니다.
-
Amazon Redshift Serverless 콘솔에서 쿼리 에디터 v2를 실행하려면 데이터 쿼리를 선택합니다. Amazon Redshift Serverless 콘솔에서 쿼리 편집기 v2를 호출하면 쿼리 편집기와 함께 새 브라우저 탭이 열립니다. 쿼리 편집기 v2는 클라이언트 시스템에서 Amazon Redshift Serverless 환경으로 연결합니다.
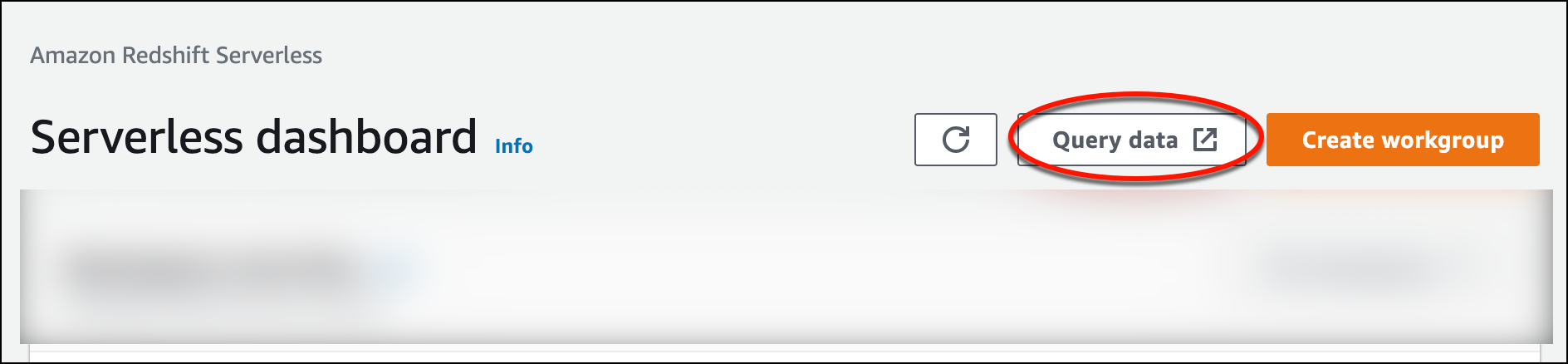
-
이 가이드에서는 AWS 관리자 계정과 기본 AWS KMS key를 사용합니다. 필요한 권한을 포함하여 쿼리 에디터 v2를 구성하는 방법에 대한 자세한 내용은 Amazon Redshift 관리 안내서의 AWS 계정 구성을 참조하세요. 고객 관리형 키를 사용하거나 Amazon Redshift에서 사용하는 KMS 키를 변경하도록 Amazon Redshift를 구성하는 방법에 대한 자세한 내용은 네임스페이스의 AWS KMS 키 변경을 참조하세요.
-
작업 그룹에 연결하려면 트리 보기 패널에서 작업 그룹 이름을 선택합니다.
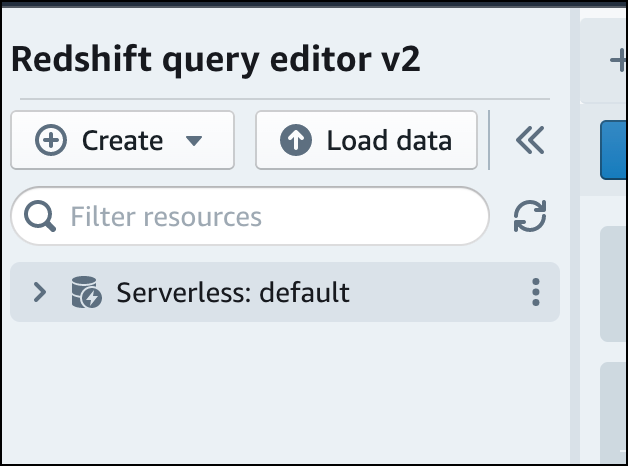
-
쿼리 에디터 v2에서 새 작업 그룹에 처음 연결하는 경우 작업 그룹에 연결하는 데 사용할 인증 유형을 선택해야 합니다. 이 안내서에서는 페더레이션 사용자를 선택한 상태로 두고 연결 생성을 선택합니다.
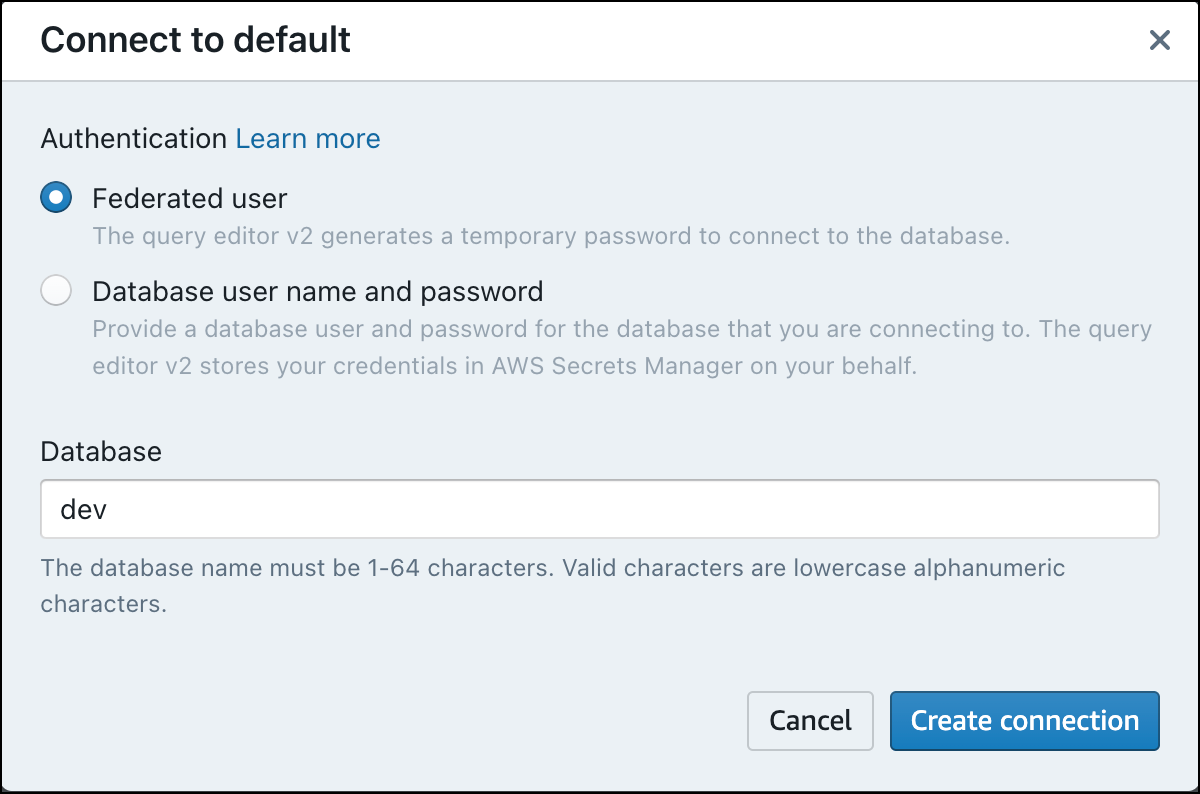
연결되면 Amazon Redshift Serverless 또는 Amazon S3 버킷에서 샘플 데이터를 로드하도록 선택할 수 있습니다.
-
Amazon Redshift Serverless 기본 작업 그룹 아래에서 sample_data_dev 데이터베이스를 펼칩니다. 세 개의 샘플 스키마가 있는데, 이들은 Amazon Redshift Serverless 데이터베이스로 로드할 수 있는 세 개의 샘플 데이터 세트에 해당합니다. 로드하려는 샘플 데이터 세트를 선택하고 샘플 노트북 열기를 선택합니다.
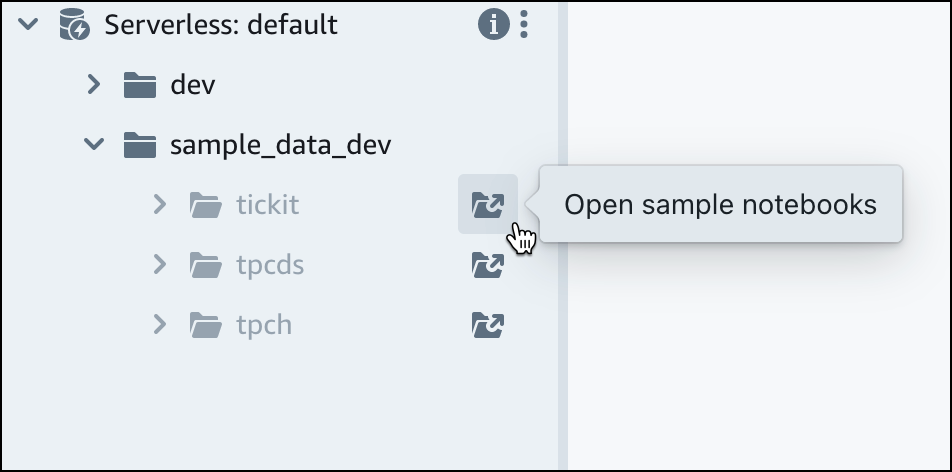
참고
SQL 노트북은 SQL 및 마크다운 셀의 컨테이너입니다. 노트북을 사용하여 하나의 문서에서 여러 SQL 명령을 구성하고 주석을 달고 공유할 수 있습니다.
-
처음으로 데이터를 로드하면 쿼리 에디터 v2에서 샘플 데이터베이스를 만들라는 메시지가 표시됩니다. 생성(Create)을 선택합니다.
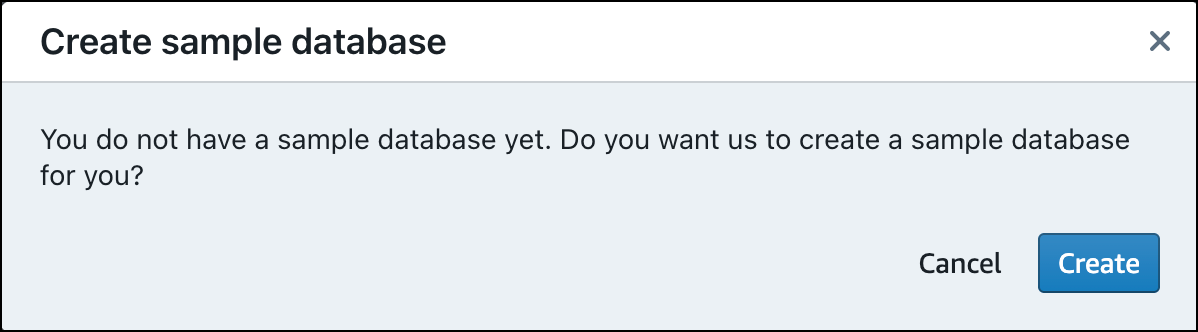
샘플 쿼리 실행
Amazon Redshift Serververless를 설정한 후 Amazon Redshift Serververless의 샘플 데이터 세트를 사용할 수 있습니다. 바로 데이터를 쿼리할 수 있도록 Amazon Redshift Serverless가 tickit 데이터 세트와 같은 샘플 데이터 세트를 자동으로 로드합니다.
-
Amazon Redshift Serverless가 샘플 데이터 로드를 완료하면 모든 샘플 쿼리가 편집기에 로드됩니다. 모두 실행을 선택하여 샘플 노트북의 모든 쿼리를 실행할 수 있습니다.
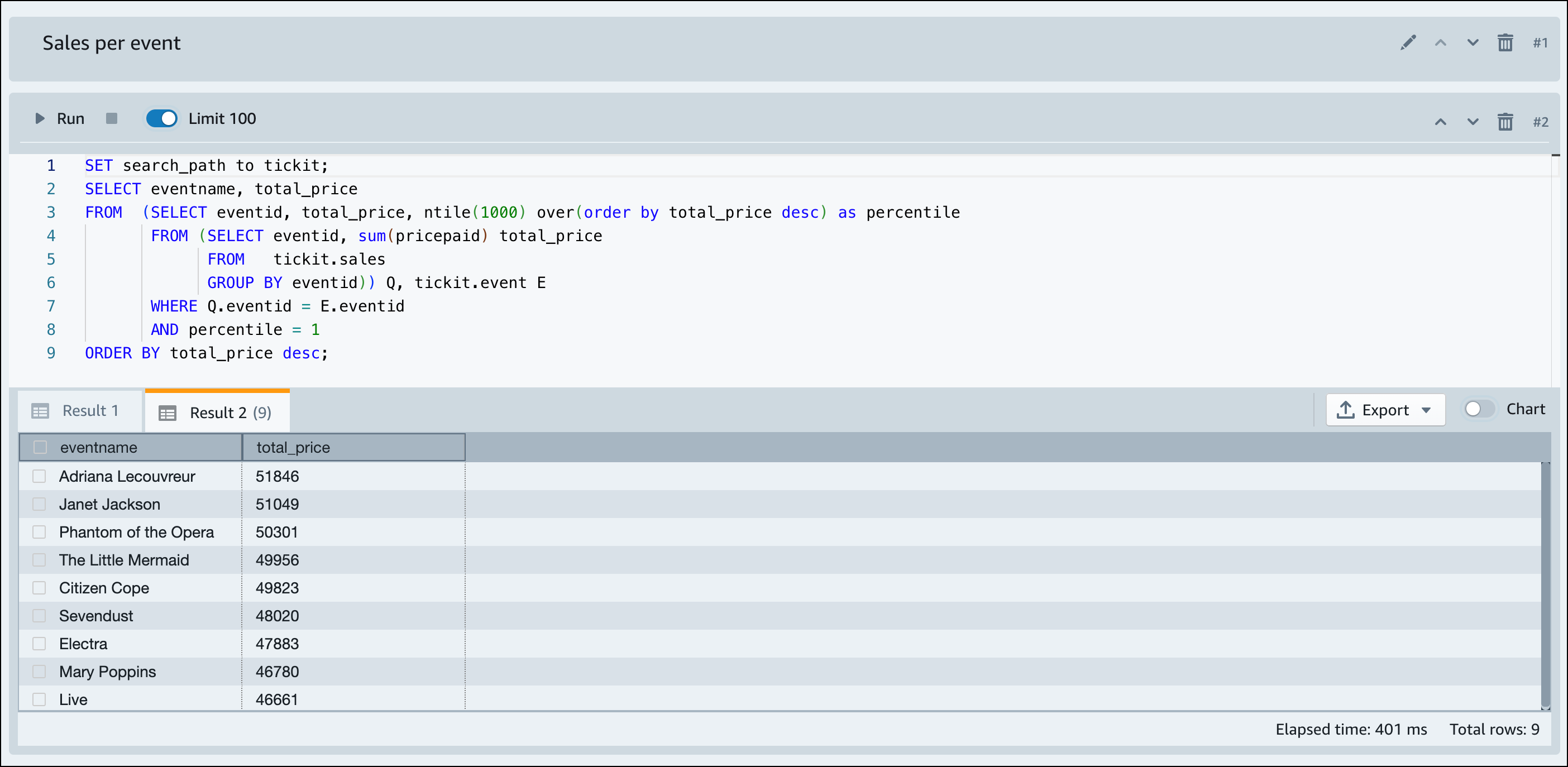
결과를 JSON 또는 CSV 파일로 내보내거나 차트에서 결과를 볼 수도 있습니다.
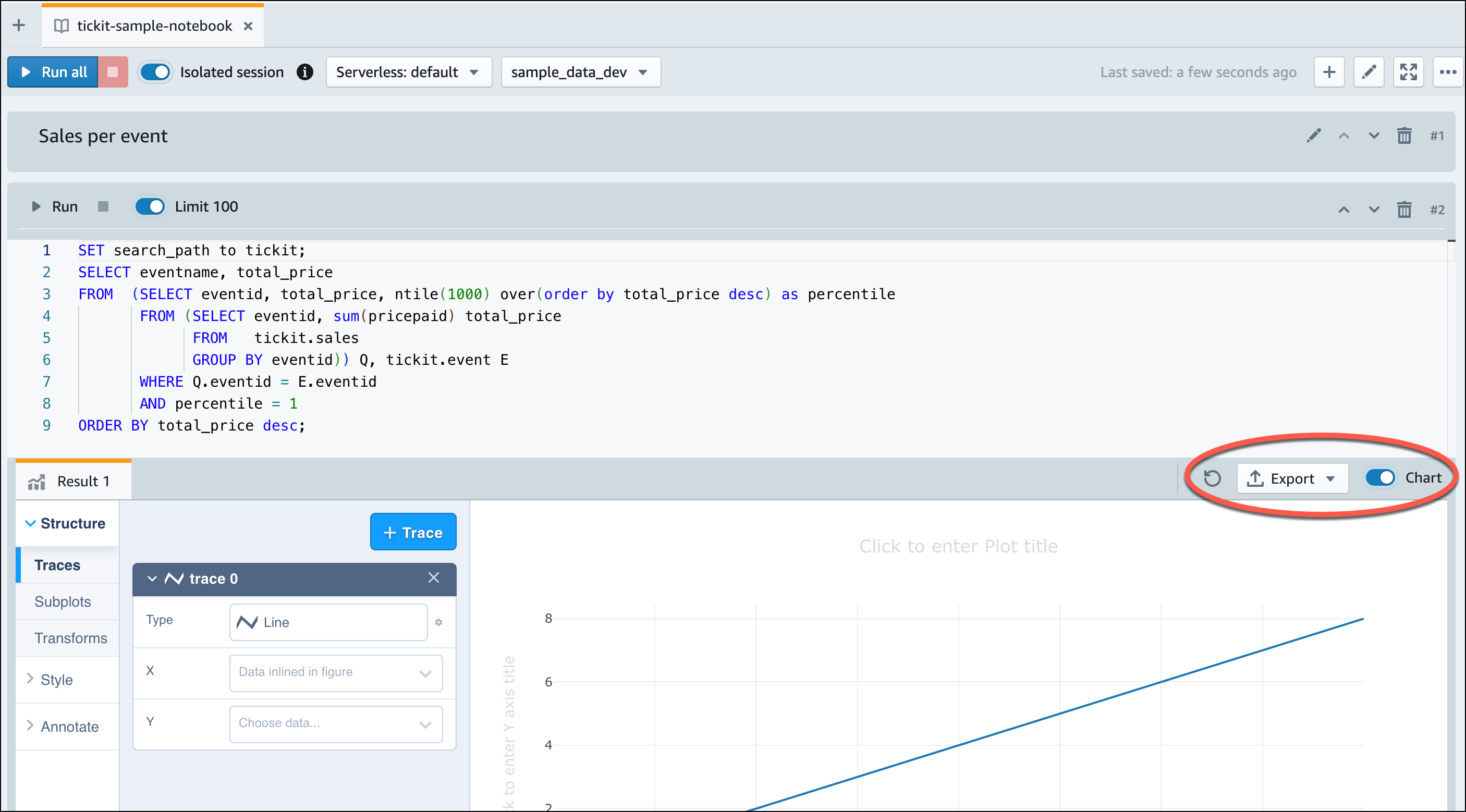
Amazon S3 버킷에서 데이터를 로드할 수도 있습니다. 자세한 내용은 Amazon S3에서 데이터 로드 섹션을 참조하세요.
Amazon S3에서 데이터 로드
데이터 웨어하우스 생성후 Amazon S3에서 데이터를 로드할 수 있습니다.
이 시점에는 dev라는 이름의 데이터베이스가 있습니다. 다음으로 데이터베이스에 테이블 몇 개를 생성하고, 해당 테이블에 데이터를 업로드하고, 쿼리를 실행해 봅니다. 편의상 Amazon S3 버킷에 있는 샘플 데이터를 로드합니다.
-
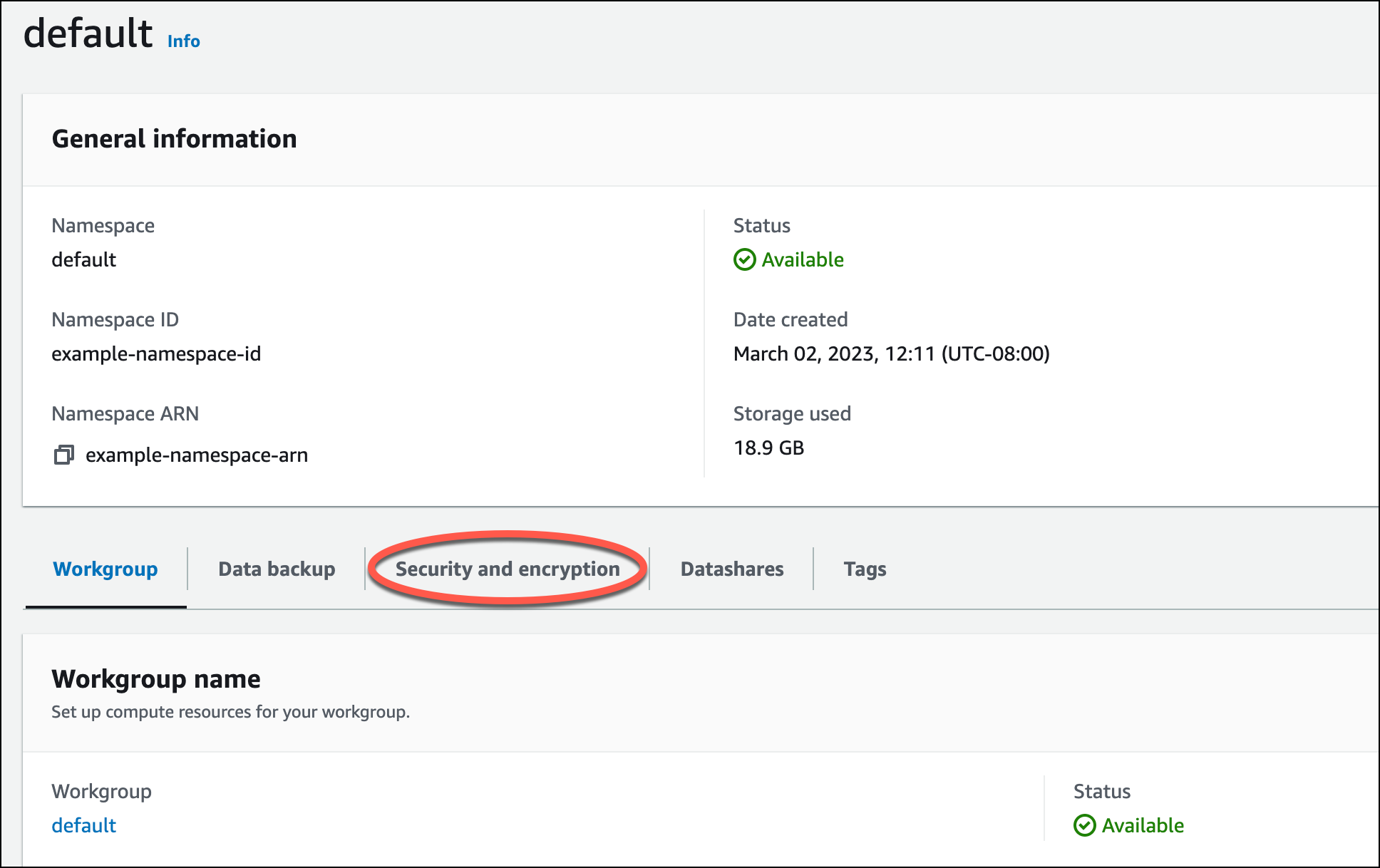
Amazon S3에서 데이터를 로드하려면 먼저 필요한 권한을 가진 IAM 역할을 생성하여 서버리스 네임스페이스에 연결해야 합니다. 이렇게 하려면 Redshift Serverless 콘솔로 돌아가 네임스페이스 구성을 선택합니다. 탐색 메뉴에서 네임스페이스를 선택하고 보안 및 암호화를 선택합니다. 그런 다음 IAM 역할 관리를 선택합니다.
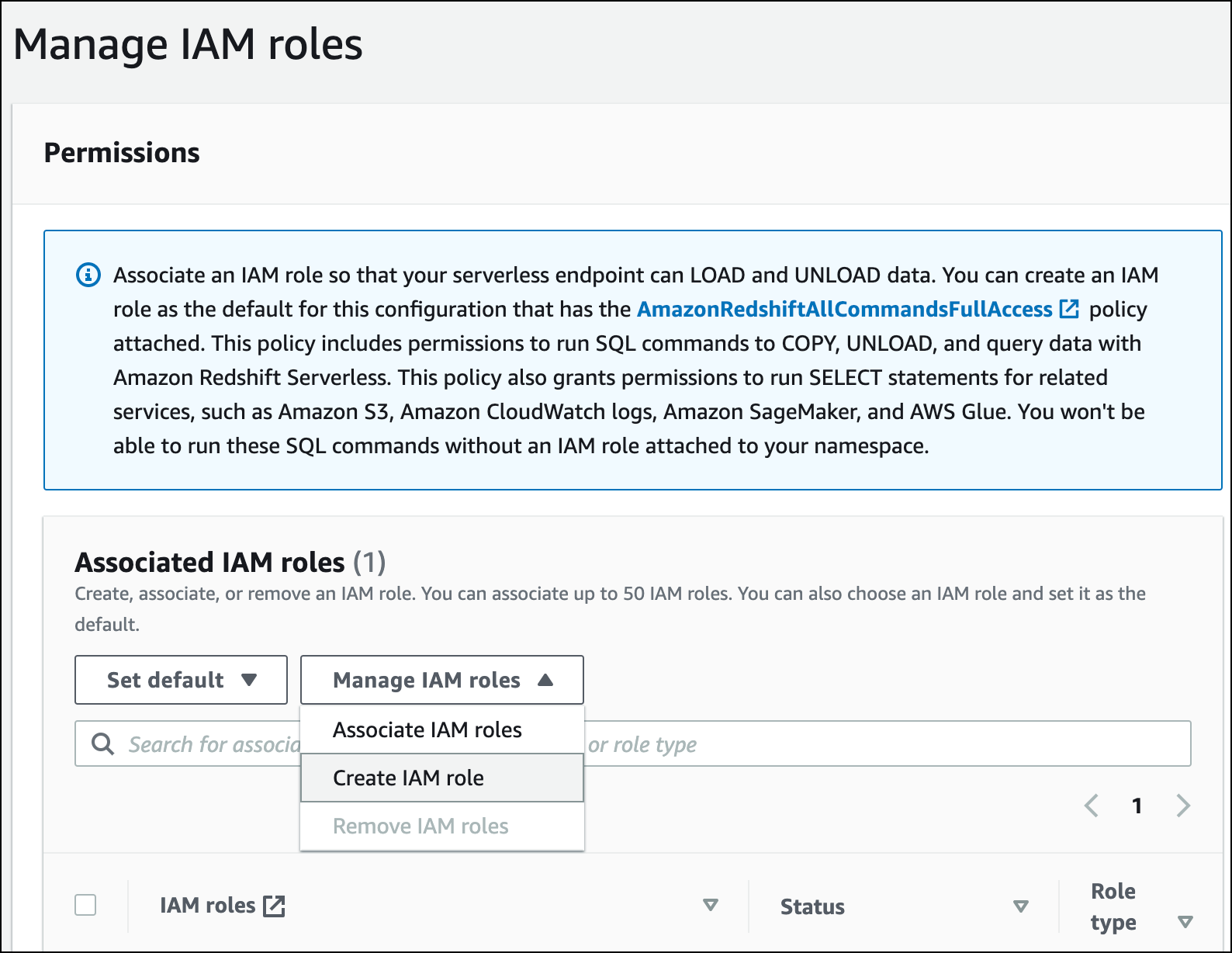
IAM 역할 관리 메뉴를 확장하고 IAM 역할 생성을 선택합니다.
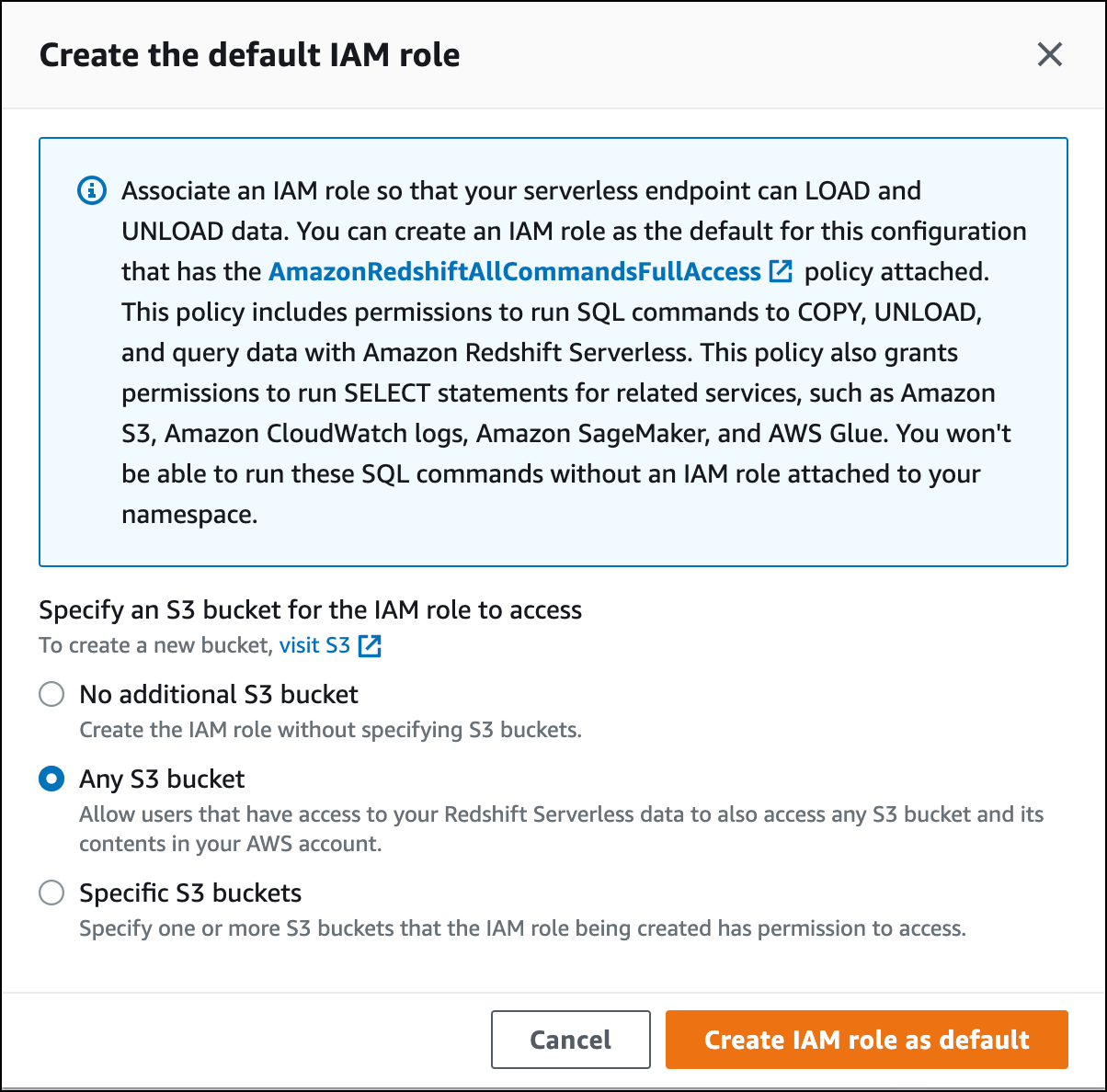
이 역할에 부여하려는 S3 버킷 액세스 수준을 선택하고 IAM 역할을 기본값으로 생성을 선택합니다.
-
변경 사항 저장을 선택합니다. 이제 Amazon S3에서 샘플 데이터를 로드할 수 있습니다.
다음 단계는 퍼블릭 Amazon Redshift S3 버킷 내의 데이터를 사용하지만 자체 S3 버킷 및 SQL 명령을 사용하여 동일한 단계를 재현할 수 있습니다.
Amazon S3에서 샘플 데이터 로드
-
쿼리 에디터 v2에서
 추가를 선택한 다음 노트북을 선택하여 새 SQL 노트북을 생성합니다.
추가를 선택한 다음 노트북을 선택하여 새 SQL 노트북을 생성합니다.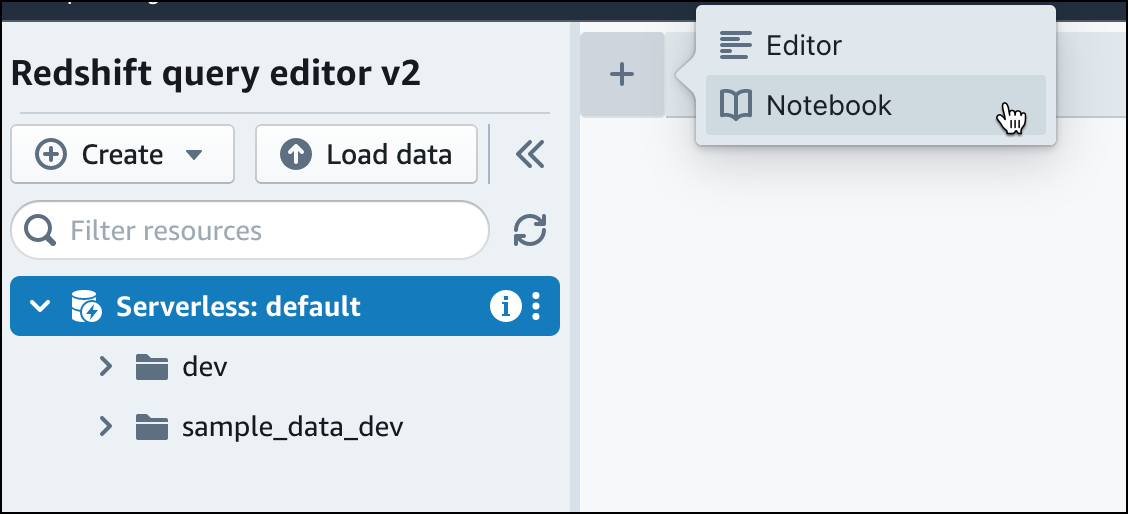
-
dev데이터베이스로 전환합니다.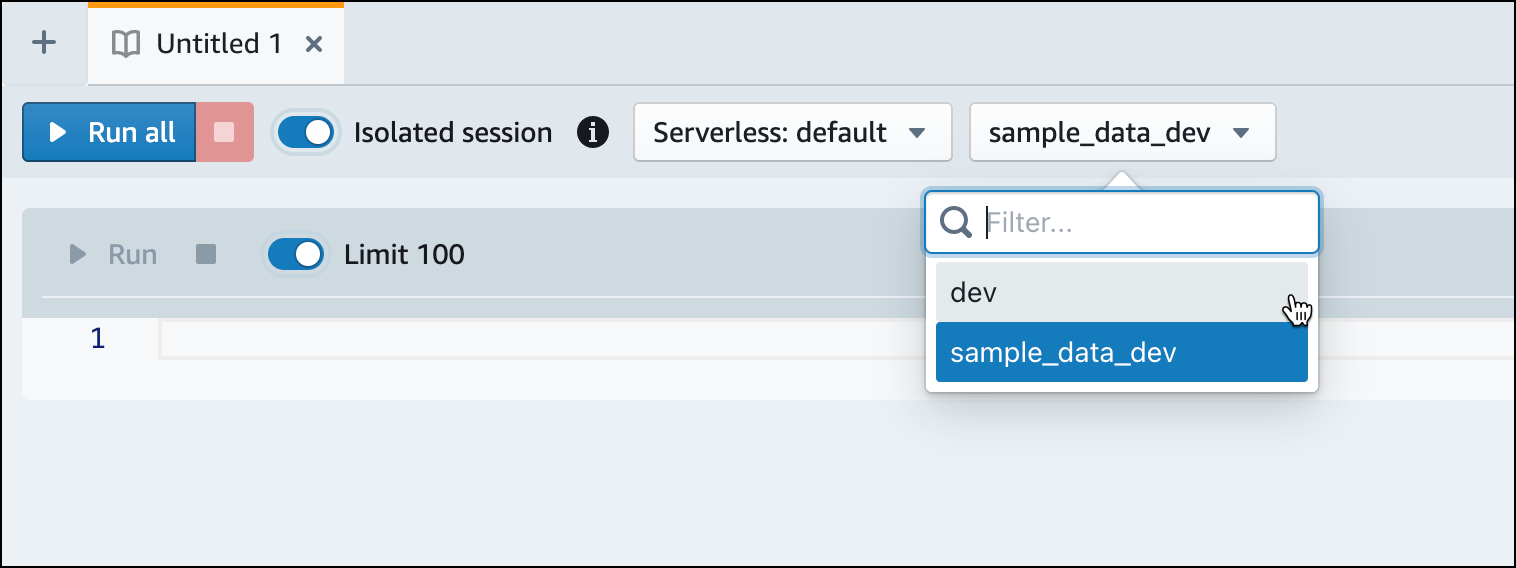
-
테이블을 만듭니다.
쿼리 에디터 v2를 사용하는 경우 다음 create table 문을 복사하고 실행하여
dev데이터베이스에 테이블을 생성합니다. 구문에 대한 자세한 내용은 Amazon Redshift 데이터베이스 개발자 안내서의 CREATE TABLE 섹션을 참조하세요.create table users( userid integer not null distkey sortkey, username char(8), firstname varchar(30), lastname varchar(30), city varchar(30), state char(2), email varchar(100), phone char(14), likesports boolean, liketheatre boolean, likeconcerts boolean, likejazz boolean, likeclassical boolean, likeopera boolean, likerock boolean, likevegas boolean, likebroadway boolean, likemusicals boolean); create table event( eventid integer not null distkey, venueid smallint not null, catid smallint not null, dateid smallint not null sortkey, eventname varchar(200), starttime timestamp); create table sales( salesid integer not null, listid integer not null distkey, sellerid integer not null, buyerid integer not null, eventid integer not null, dateid smallint not null sortkey, qtysold smallint not null, pricepaid decimal(8,2), commission decimal(8,2), saletime timestamp); -
쿼리 에디터 v2에서 노트북에 새 SQL 셀을 생성합니다.
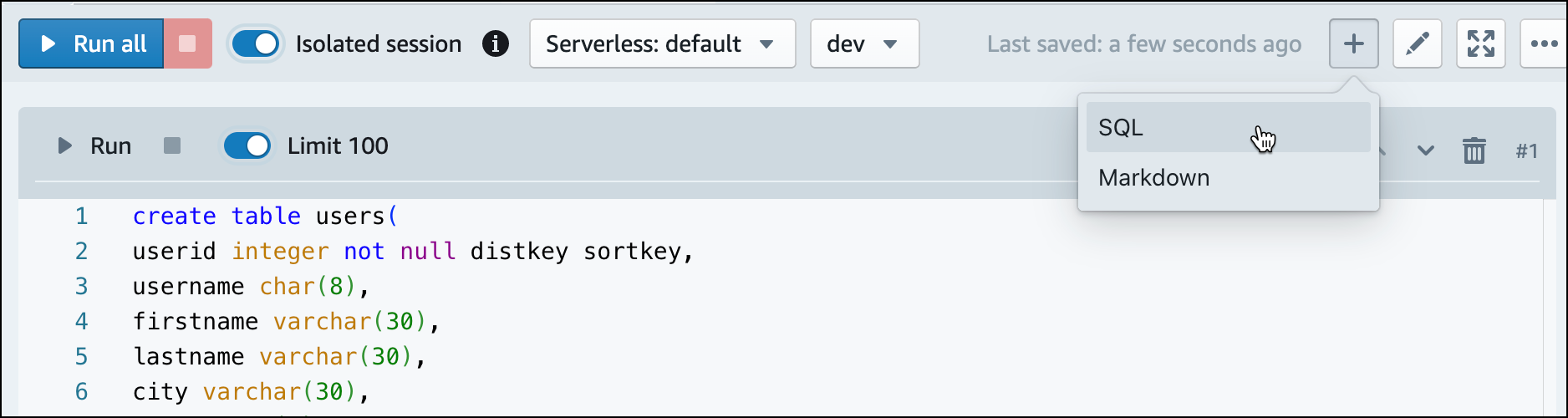
-
이제 쿼리 에디터 v2에서 COPY 명령을 사용하여 Amazon S3 또는 Amazon DynamoDB에서 Amazon Redshift로 대규모 데이터 세트를 로드합니다. COPY 구문에 대한 자세한 내용은 Amazon Redshift 데이터베이스 개발자 안내서의 COPY 섹션을 참조하세요.
퍼블릭 S3 버킷에서 사용 가능한 일부 샘플 데이터를 사용하여 COPY 명령을 실행할 수 있습니다. 쿼리 에디터 v2에서 다음 SQL 명령을 실행합니다.
COPY users FROM 's3://redshift-downloads/tickit/allusers_pipe.txt' DELIMITER '|' TIMEFORMAT 'YYYY-MM-DD HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; COPY event FROM 's3://redshift-downloads/tickit/allevents_pipe.txt' DELIMITER '|' TIMEFORMAT 'YYYY-MM-DD HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; COPY sales FROM 's3://redshift-downloads/tickit/sales_tab.txt' DELIMITER '\t' TIMEFORMAT 'MM/DD/YYYY HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; -
데이터를 로드한 후 노트북에 다른 SQL 셀을 만들고 몇 가지 예제 쿼리를 시도해 보세요. SELECT 명령 작업에 대한 자세한 내용은 Amazon Redshift 개발자 안내서의 SELECT 섹션을 참조하세요. 샘플 데이터의 구조와 스키마를 이해하려면 쿼리 에디터 v2를 사용해 살펴보세요.
-- Find top 10 buyers by quantity. SELECT firstname, lastname, total_quantity FROM (SELECT buyerid, sum(qtysold) total_quantity FROM sales GROUP BY buyerid ORDER BY total_quantity desc limit 10) Q, users WHERE Q.buyerid = userid ORDER BY Q.total_quantity desc; -- Find events in the 99.9 percentile in terms of all time gross sales. SELECT eventname, total_price FROM (SELECT eventid, total_price, ntile(1000) over(order by total_price desc) as percentile FROM (SELECT eventid, sum(pricepaid) total_price FROM sales GROUP BY eventid)) Q, event E WHERE Q.eventid = E.eventid AND percentile = 1 ORDER BY total_price desc;
이제 데이터를 로드하고 몇 가지 샘플 쿼리를 실행했으므로 Amazon Redshift Serverless의 다른 영역을 탐색할 수 있습니다. Amazon Redshift Serverless를 사용하는 방법에 대해 자세히 알아보려면 다음 목록을 참조하세요.
-
Amazon S3 버킷에서 데이터를 로드할 수 있습니다. 자세한 내용은 Amazon S3에서 데이터 로드를 참조하세요.
-
쿼리 에디터 v2를 사용하여 크기가 5MB 미만인, 문자로 구분된 로컬 파일에서 데이터를 로드할 수 있습니다. 자세한 내용은 로컬 파일에서 데이터 로드를 참조하세요.
-
JDBC 및 ODBC 드라이버가 있는 타사 SQL 도구를 사용하여 Amazon Redshift Serverless에 연결할 수 있습니다. 자세한 내용은 Amazon Redshift Serverless에 연결을 참조하세요.
-
Amazon Redshift Data API를 사용하여 Amazon Redshift Serverless에 연결할 수도 있습니다. 자세한 내용은 Amazon Redshift 데이터 API 사용
을 참조하세요. -
Amazon Redshift Serverless의 데이터를 Redshift ML과 함께 사용하여 CREATE MODEL 명령으로 기계 학습 모델을 생성할 수 있습니다. Redshift ML 모델을 구축하는 방법을 알아보려면 자습서: 고객 이탈 모델 구축을 참조하세요.
-
Amazon Redshift Serverless에 데이터를 로드하지 않아도 Amazon S3 데이터 레이크의 데이터를 쿼리할 수 있습니다. 자세한 내용은 데이터 레이크 쿼리를 참조하세요.
