기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
연습 1: 객체 및 장면 감지(콘솔)
이 섹션은 Amazon Rekognition의 객체 및 장면 감지 기능이 아주 높은 수준에서 어떻게 작동하는지 보여 줍니다. 이미지를 입력으로 지정하면 서비스는 해당 이미지에서 객체와 장면을 감지하고 각 객체와 장면의 백분율 신뢰도 점수와 함께 객체 및 장면을 반환합니다.
예를 들어 Amazon Rekognition은 샘플 이미지에서 객체와 장면(스케이트보드, 스포츠, 사람, 자동차, 차량)을 감지합니다.

Amazon Rekognition은 다음 샘플 응답에 나온 것처럼 샘플 이미지에서 감지된 각 객체의 신뢰도 점수도 반환합니다.
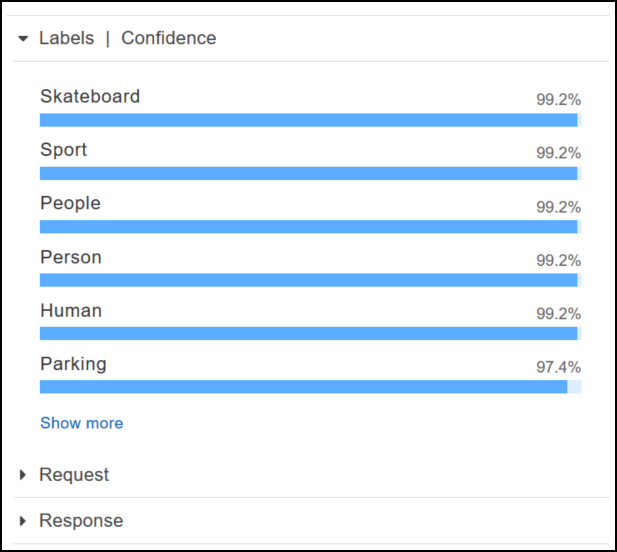
이 응답에 표시된 모든 신뢰도 점수를 보려면 레이블 | 신뢰도 창에서 Show more를 선택합니다.
API에 대한 요청과 API의 응답을 참조로 볼 수도 있습니다.
요청
{ "contentString":{ "Attributes":[ "ALL" ], "Image":{ "S3Object":{ "Bucket":"console-sample-images", "Name":"skateboard.jpg" } } } }
응답
{ "Labels":[ { "Confidence":99.25359344482422, "Name":"Skateboard" }, { "Confidence":99.25359344482422, "Name":"Sport" }, { "Confidence":99.24723052978516, "Name":"People" }, { "Confidence":99.24723052978516, "Name":"Person" }, { "Confidence":99.23908233642578, "Name":"Human" }, { "Confidence":97.42484283447266, "Name":"Parking" }, { "Confidence":97.42484283447266, "Name":"Parking Lot" }, { "Confidence":91.53300476074219, "Name":"Automobile" }, { "Confidence":91.53300476074219, "Name":"Car" }, { "Confidence":91.53300476074219, "Name":"Vehicle" }, { "Confidence":76.85114288330078, "Name":"Intersection" }, { "Confidence":76.85114288330078, "Name":"Road" }, { "Confidence":76.21503448486328, "Name":"Boardwalk" }, { "Confidence":76.21503448486328, "Name":"Path" }, { "Confidence":76.21503448486328, "Name":"Pavement" }, { "Confidence":76.21503448486328, "Name":"Sidewalk" }, { "Confidence":76.21503448486328, "Name":"Walkway" }, { "Confidence":66.71541595458984, "Name":"Building" }, { "Confidence":62.04711151123047, "Name":"Coupe" }, { "Confidence":62.04711151123047, "Name":"Sports Car" }, { "Confidence":61.98909378051758, "Name":"City" }, { "Confidence":61.98909378051758, "Name":"Downtown" }, { "Confidence":61.98909378051758, "Name":"Urban" }, { "Confidence":60.978023529052734, "Name":"Neighborhood" }, { "Confidence":60.978023529052734, "Name":"Town" }, { "Confidence":59.22066116333008, "Name":"Sedan" }, { "Confidence":56.48063278198242, "Name":"Street" }, { "Confidence":54.235477447509766, "Name":"Housing" }, { "Confidence":53.85226058959961, "Name":"Metropolis" }, { "Confidence":52.001792907714844, "Name":"Office Building" }, { "Confidence":51.325313568115234, "Name":"Suv" }, { "Confidence":51.26075744628906, "Name":"Apartment Building" }, { "Confidence":51.26075744628906, "Name":"High Rise" }, { "Confidence":50.68067932128906, "Name":"Pedestrian" }, { "Confidence":50.59548568725586, "Name":"Freeway" }, { "Confidence":50.568580627441406, "Name":"Bumper" } ] }
자세한 내용은 Amazon Rekognition 작동 방식 단원을 참조하십시오.
제공한 이미지에서 객체 및 장면 감지
Amazon Rekognition 콘솔에 소유하고 있는 이미지를 업로드하거나 이미지의 URL을 입력으로 제공할 수 있습니다. Amazon Rekognition은 제공된 이미지에서 감지한 객체와 장면 및 각 객체와 장면의 신뢰도 점수를 반환합니다.
참고
이미지는 크기가 5MB 미만이어야 하며 JPEG 또는 PNG 형식이어야 합니다.
제공한 이미지에서 객체 및 장면을 감지하려면
https://console.aws.amazon.com/rekognition/
에서 Amazon Rekognition 콘솔을 엽니다. 레이블 감지를 선택합니다.
다음 중 하나를 수행합니다.
이미지 업로드 - 업로드를 선택하고 이미지를 저장한 위치로 이동한 다음 이미지를 선택합니다.
URL 사용 - 텍스트 상자에 URL을 입력한 다음 이동을 선택합니다.
[Labels | Confidence] 창에서 감지된 각 레이블의 신뢰도 점수를 확인합니다.
더 많은 이미지 분석 옵션을 보려면 이미지 작업 섹션을 참조하세요.
제공한 비디오에서 사람과 객체 감지
Amazon Rekognition 콘솔에 소유하고 있는 비디오를 업로드하여 입력으로 제공할 수 있습니다. Amazon Rekognition은 비디오에서 감지된 사람, 객체 및 레이블을 반환합니다.
참고
데모 동영상은 길이가 1분을 초과하거나 용량 30MB를 초과할 수 없습니다. MP4 파일 형식이어야 하며 H.264 코덱을 사용하여 인코딩해야 합니다.
제공한 비디오에서 사람 및 객체를 감지하려면
https://console.aws.amazon.com/rekognition/
에서 Amazon Rekognition 콘솔을 엽니다. 탐색 모음에서 저장된 비디오 분석을 선택합니다.
드롭다운 메뉴의 샘플 선택 또는 자체적으로 업로드에서 자체 비디오를 선택합니다.
비디오를 드래그 앤 드롭하거나 저장한 위치에서 비디오를 선택합니다.
더 많은 비디오 분석 옵션을 보려면 저장된 비디오 분석 작업나 스트리밍 비디오 이벤트 작업 섹션을 참조하세요.
