기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Data Wrangler 흐름을 생성합니다.
Amazon SageMaker Data Wrangler 흐름 또는 데이터 흐름을 사용하여 데이터 준비 파이프라인을 생성하고 수정하세요. 데이터 흐름은 생성한 데이터세트, 변환, 분석 또는 단계를 연결하고 파이프라인을 정의하는 데 사용할 수 있습니다.
인스턴스
Amazon SageMaker Studio Classic에서 Data Wrangler 흐름을 만들면 Data Wrangler는 Amazon EC2 인스턴스를 사용하여 흐름의 분석 및 변환을 실행합니다. 기본적으로 Data Wrangler는 m5.4xlarge 인스턴스를 사용합니다. m5 인스턴스는 컴퓨팅과 메모리 간의 균형을 제공하는 범용 인스턴스입니다. m5 인스턴스를 다양한 컴퓨팅 워크로드에 사용할 수 있습니다.
Data Wrangler는 또한 r5 인스턴스를 사용할 수 있는 옵션을 제공합니다. r5 인스턴스는 메모리에서 대규모 데이터세트를 처리하는 빠른 성능을 제공하도록 설계되었습니다.
워크로드에 가장 최적화된 인스턴스를 선택하는 것이 좋습니다. 예를 들어 r5.8xlarge는 m5.4xlarge보다 가격이 더 높을 수 있지만 r5.8xlarge는 워크로드에 더 잘 최적화될 수 있습니다. 더 잘 최적화된 인스턴스를 사용하면 더 적은 시간에 더 저렴한 비용으로 데이터 흐름을 실행할 수 있습니다.
Data Wrangler 흐름을 실행하는 데 사용할 수 있는 인스턴스가 다음 테이블에 나와 있습니다.
| 표준 인스턴스 | vCPU | 메모리 |
|---|---|---|
| ml.m5.4xlarge | 16 | 64GiB |
| ml.m5.8xlarge | 32 | 128GiB |
| ml.m5.16xlarge | 64 |
256GiB |
| ml.m5.24xlarge | 96 | 384 GiB |
| r5.4xlarge | 16 | 128GiB |
| r5.8xlarge | 32 | 256GiB |
| r5.24xlarge | 96 | 768GiB |
r5 인스턴스에 대한 자세한 내용은 Amazon EC2 R5 인스턴스
각 Data Wrangler 흐름에는 연결된 Amazon EC2 인스턴스가 있습니다. 단일 인스턴스에 연결된 플로우가 여러 개 있을 수 있습니다.
각 흐름 파일에 대해 인스턴스 유형을 원활하게 전환할 수 있습니다. 인스턴스 유형을 전환해도 흐름을 실행하는 데 사용한 인스턴스는 계속 실행됩니다.
흐름의 인스턴스 유형을 전환하려면 다음과 같이 하세요.
-
터미널 및 커널 실행 아이콘(
 )을 선택합니다.
)을 선택합니다. -
사용 중인 인스턴스로 이동하여 선택합니다.
-
삭제하려는 인스턴스를 선택합니다.
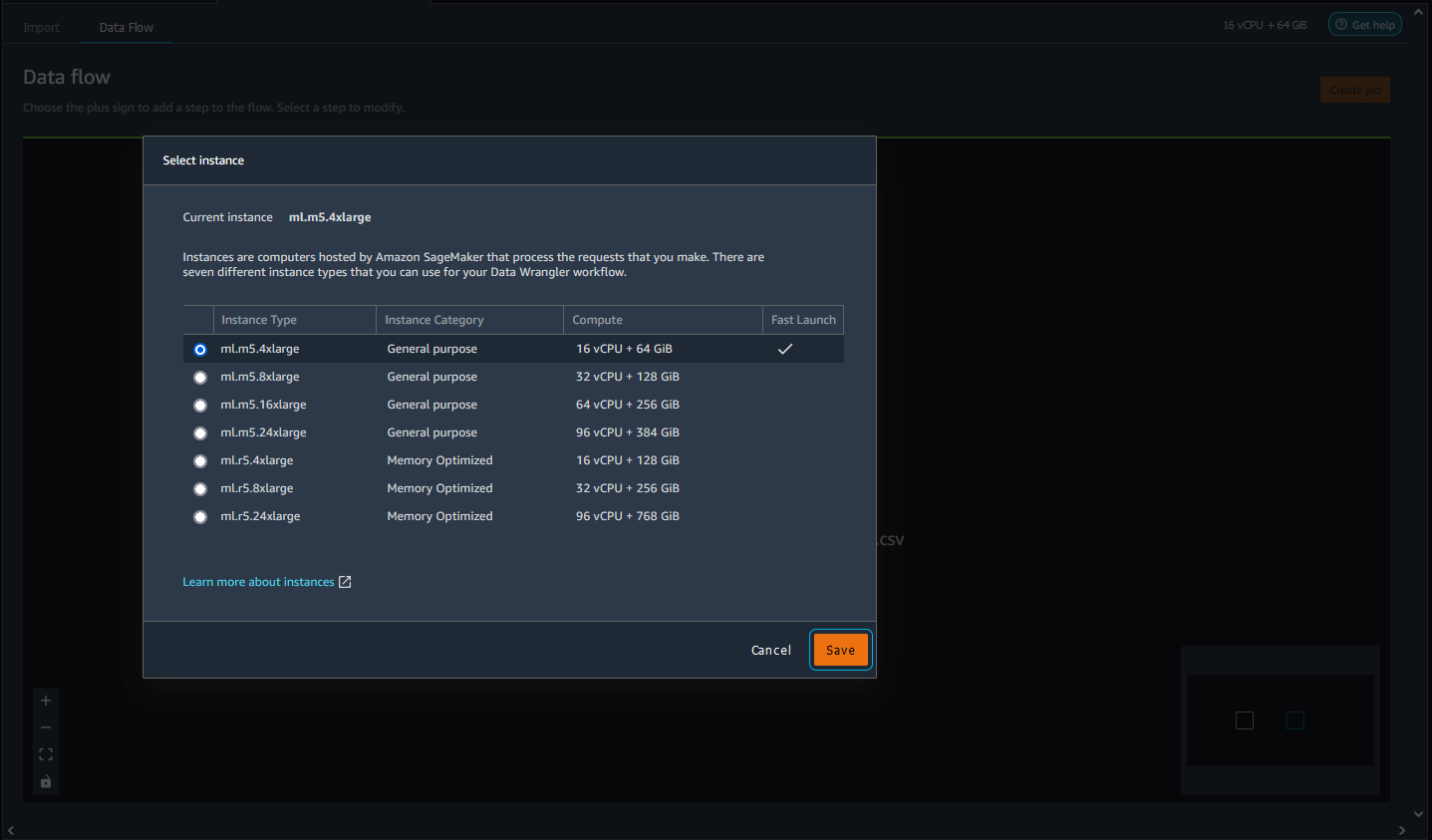
-
저장을 선택합니다.
두 인스턴스가 실행되는 동안에는 두 인스턴스에 대해 요금이 청구됩니다. 추가 요금이 발생하지 않도록 하려면 사용하지 않는 인스턴스를 수동으로 종료하세요. 실행 중인 인스턴스를 종료하려면 다음 절차를 사용하세요.
실행 중인 인스턴스를 종료하려면
-
인스턴스 아이콘을 선택합니다. 다음 이미지는 실행 중인 인스턴스 아이콘을 선택할 수 있는 위치를 보여줍니다.
-
종료하려는 인스턴스 옆의 종료를 선택합니다.
흐름을 실행하는 데 사용된 인스턴스를 종료하면 일시적으로 흐름에 액세스할 수 없습니다. 이전에 종료한 인스턴스를 실행하는 흐름을 열려고 시도하는 동안 오류가 발생하는 경우 5분 동안 기다린 후 다시 열어 보세요.
Amazon 심플 스토리지 서비스 또는 Amazon SageMaker 피처 스토어와 같은 위치로 데이터 흐름을 내보내는 경우 Data Wrangler는 Amazon SageMaker 처리 작업을 실행합니다. 처리 작업에 다음 인스턴스 중 하나를 사용할 수 있습니다. 데이터 내보내기에 대한 자세한 내용은 내보내기 섹션을 참조하세요.
| 표준 인스턴스 | vCPU | 메모리 |
|---|---|---|
| ml.m5.4xlarge | 16 | 64GiB |
| ml.m5.12xlarge | 48 |
192GiB |
| ml.m5.24xlarge | 96 | 384 GiB |
사용 가능한 인스턴스 유형 사용에 따른 시간당 비용에 대한 자세한 내용은 SageMaker 가격
데이터 흐름 UI
데이터세트를 가져오면 원본 데이터세트이 데이터 흐름에 나타나고 이름은 Source입니다. 데이터를 가져올 때 샘플링을 설정한 경우 이 데이터세트의 이름은 Source - sampled입니다. Data Wrangler는 데이터세트의 각 열 유형을 자동으로 유추하여 Data types이라는 새 데이터 프레임을 만듭니다. 이 프레임을 선택하여 유추된 데이터 유형을 업데이트할 수 있습니다. 데이터세트 하나를 업로드하면 다음 이미지에 표시된 것과 비슷한 결과가 나타납니다.

변환 단계를 추가할 때마다 새 데이터 프레임이 생성됩니다. 여러 변환 단계(조인 또는 연결 제외)가 동일한 데이터세트에 추가되면 해당 단계가 누적됩니다.
조인 및 연결은 조인되거나 연결된 새 데이터세트를 포함하는 독립형 단계를 만듭니다.
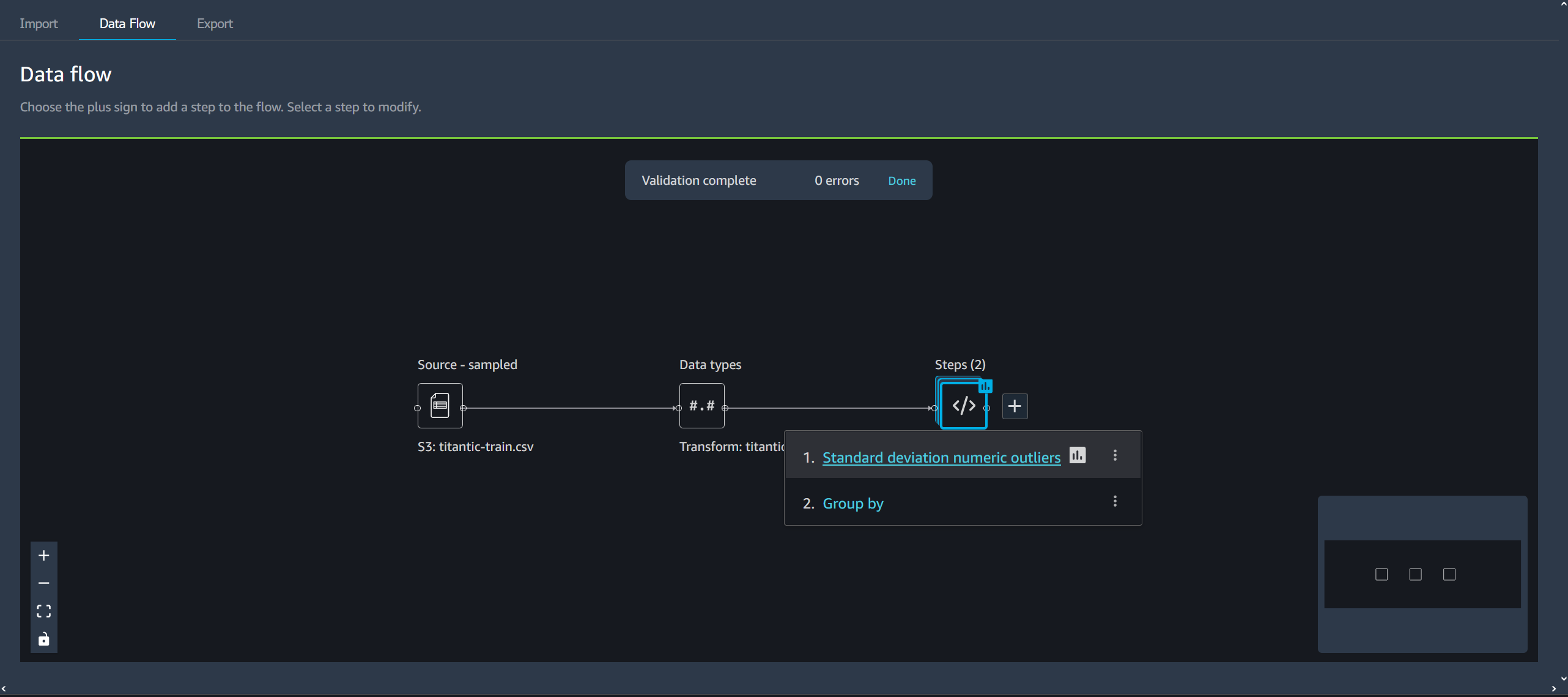
다음 다이어그램은 두 데이터세트 간의 조인과 두 단계 스택이 있는 데이터 흐름을 보여줍니다. 첫 번째 스택(단계(2))은 데이터 유형 데이터세트에서 유추된 유형에 두 개의 변환을 추가합니다. 다운스트림 스택 또는 오른쪽 스택은 demo-join이라는 조인의 결과로 데이터세트에 변환을 추가합니다.

데이터 흐름의 오른쪽 하단에 있는 작은 회색 상자는 흐름의 스택과 단계 수, 흐름의 레이아웃에 대한 개요를 제공합니다. 회색 상자 안의 밝은 상자는 UI 뷰에 있는 단계를 나타냅니다. 이 상자를 사용하여 UI 보기를 벗어나는 데이터 흐름 섹션을 볼 수 있습니다. 화면 맞춤 아이콘(
 )을 사용하여 모든 단계와 데이터세트를 UI 뷰에 맞출 수 있습니다.
)을 사용하여 모든 단계와 데이터세트를 UI 뷰에 맞출 수 있습니다.
왼쪽 하단 내비게이션 바에는 데이터 흐름을 확대(
 ) 및 축소(
) 및 축소(
 )하고 화면에 맞게 데이터 흐름의 크기를 조정(
)하는 데 사용할 수 있는 아이콘이 있습니다. 잠금 아이콘(
)하고 화면에 맞게 데이터 흐름의 크기를 조정(
)하는 데 사용할 수 있는 아이콘이 있습니다. 잠금 아이콘(
 )을 사용하여 화면에서 각 단계의 위치를 잠그거나 잠금 해제할 수 있습니다.
)을 사용하여 화면에서 각 단계의 위치를 잠그거나 잠금 해제할 수 있습니다.
데이터 흐름에 단계 추가
데이터세트 또는 이전에 추가한 단계 옆의 +를 선택하고 다음 옵션 중 하나를 선택합니다.
-
데이터 유형 편집(데이터 유형 단계만 해당): 데이터 유형 단계에 변환을 추가하지 않은 경우 데이터 유형 편집을 선택하여 데이터세트를 가져올 때 Data Wrangler가 추론한 데이터 유형을 업데이트할 수 있습니다.
-
변환 추가: 새 변환 단계를 추가합니다. 추가할 수 있는 데이터 변환에 대해 자세히 알아보려면 데이터 변환하기 섹션을 참조하세요.
-
분석 추가: 분석을 추가합니다. 이 옵션을 사용하여 데이터 흐름의 어느 시점에서든 데이터를 분석할 수 있습니다. 단계에 분석을 하나 이상 추가하면 해당 단계에 분석 아이콘(
 )이 나타납니다. 추가할 수 있는 분석에 대한 자세한 내용은 분석 및 시각화 섹션을 참조하세요.
)이 나타납니다. 추가할 수 있는 분석에 대한 자세한 내용은 분석 및 시각화 섹션을 참조하세요. -
조인: 두 데이터세트를 조인하고 결과 데이터세트를 데이터 흐름에 추가합니다. 자세한 내용은 데이터세트 조인하기 단원을 참조하세요.
-
연결: 두 데이터세트를 연결하고 결과 데이터세트를 데이터 흐름에 추가합니다. 자세한 내용은 데이터세트 연결하기 단원을 참조하세요.
데이터 흐름에서 한 단계 삭제
단계를 삭제하려면 단계를 선택하고 삭제를 선택합니다. 노드가 단일 입력이 있는 노드인 경우 선택한 단계만 삭제합니다. 입력이 하나인 단계를 삭제해도 그 뒤에 오는 단계는 삭제되지 않습니다. 소스, 조인 또는 연결 노드의 단계를 삭제하는 경우 해당 단계를 따르는 모든 단계도 삭제됩니다.
단계 스택에서 단계를 삭제하려면 스택을 선택한 다음 삭제할 단계를 선택합니다.
다운스트림 단계를 삭제하지 않고 다음 절차 중 하나에 따라 단계를 삭제할 수 있습니다.
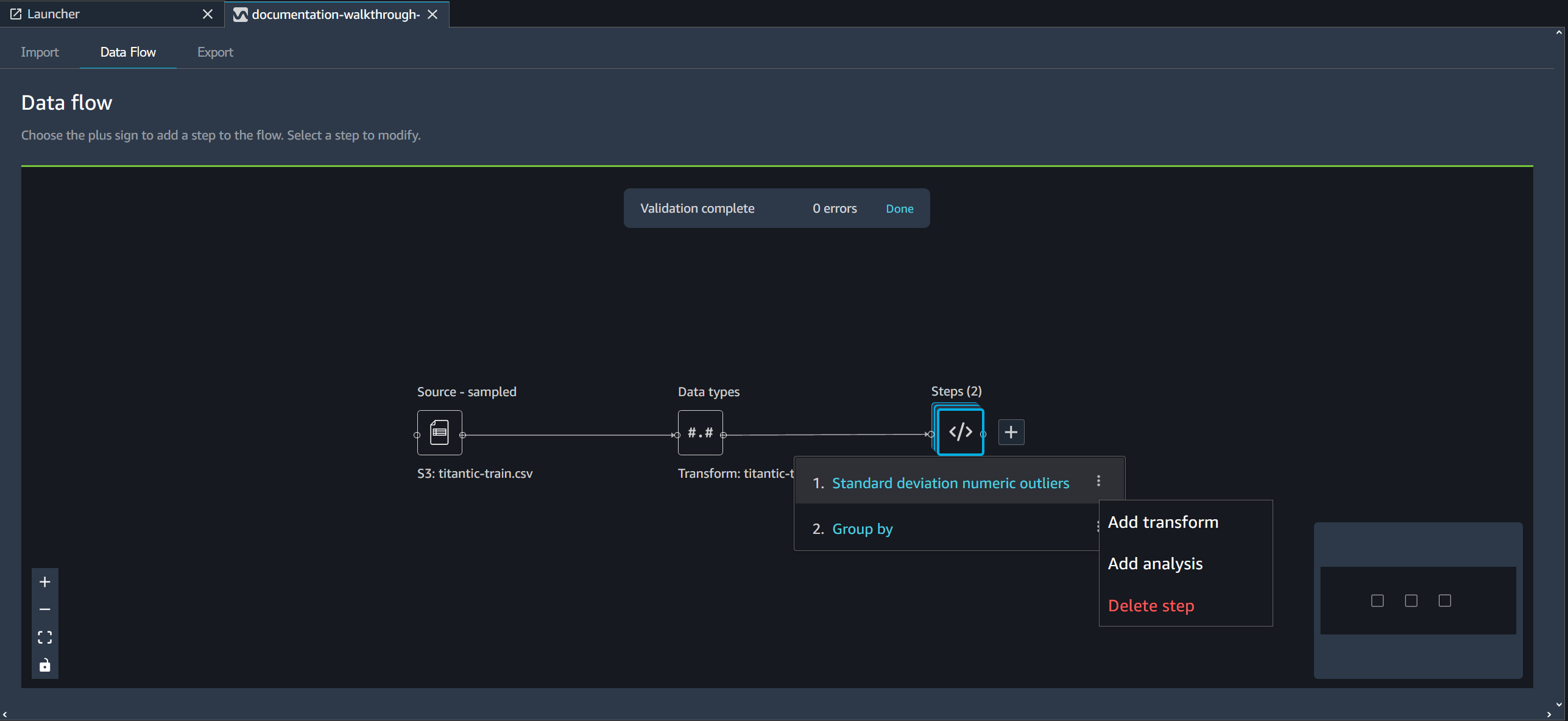
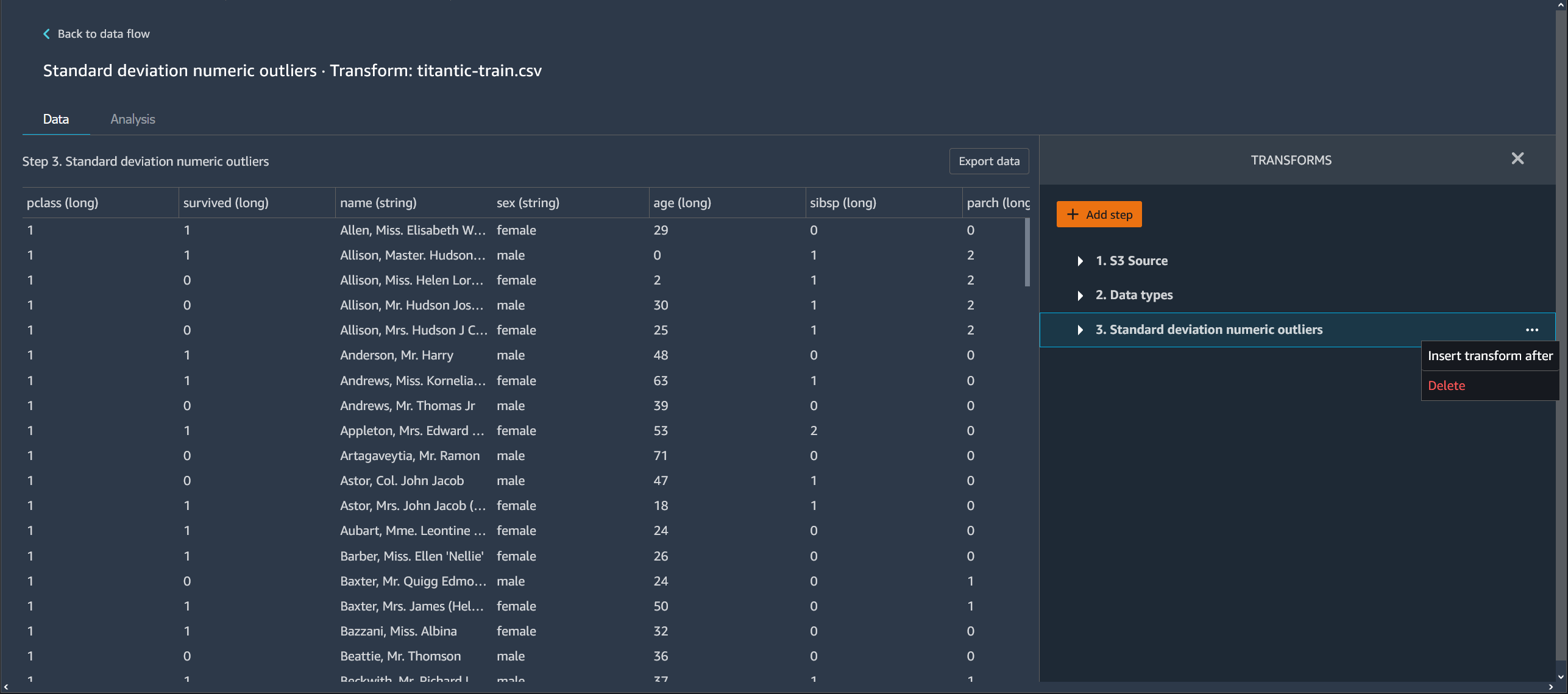
Data Wrangler 플로우에서 단계 편집
Data Wrangler 흐름에 추가한 각 단계를 편집할 수 있습니다. 단계를 편집하여 열의 변환 또는 데이터 유형을 변경할 수 있습니다. 단계를 편집하여 더 나은 분석을 수행할 수 있도록 변경할 수 있습니다.
단계를 편집할 수 있는 방법은 여러 가지가 있습니다. 일부 예로는 값을 이상값으로 간주하기 위한 임계값 변경 또는 대치 방법 변경 등이 있습니다.
스토리를 재생하려면 다음 절차에 따르세요.
단계를 편집하려면 다음과 같이 하세요.
-
Data Wrangler 흐름에서 단계를 선택하여 테이블 보기를 엽니다.
-
데이터 흐름에서 단계를 선택합니다.
-
단계를 편집합니다.
다음 그림에 의 예가 나와 있습니다.

참고
Amazon SageMaker AI 도메인 내의 공유 스페이스를 사용하여 Data Wrangler 흐름에서 공동 작업할 수 있습니다. 공유 공간 내에서 사용자와 공동 작업자는 플로우 파일을 실시간으로 편집할 수 있습니다. 하지만 사용자와 공동 작업자 모두 변경 사항을 실시간으로 확인할 수 없습니다. Data Wrangler 흐름을 변경하는 사람이 있으면 즉시 저장해야 합니다. 누군가 파일을 저장하면 공동 작업자는 파일을 닫았다가 다시 열지 않는 한 해당 파일을 볼 수 없습니다. 한 사람이 저장하지 않은 모든 변경 내용은 변경 내용을 저장한 사람이 덮어씁니다.
