기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
내보내기
Data Wrangler 흐름에서 데이터 처리 파이프라인에 대해 수행한 변환 중 일부 또는 전부를 내보낼 수 있습니다.
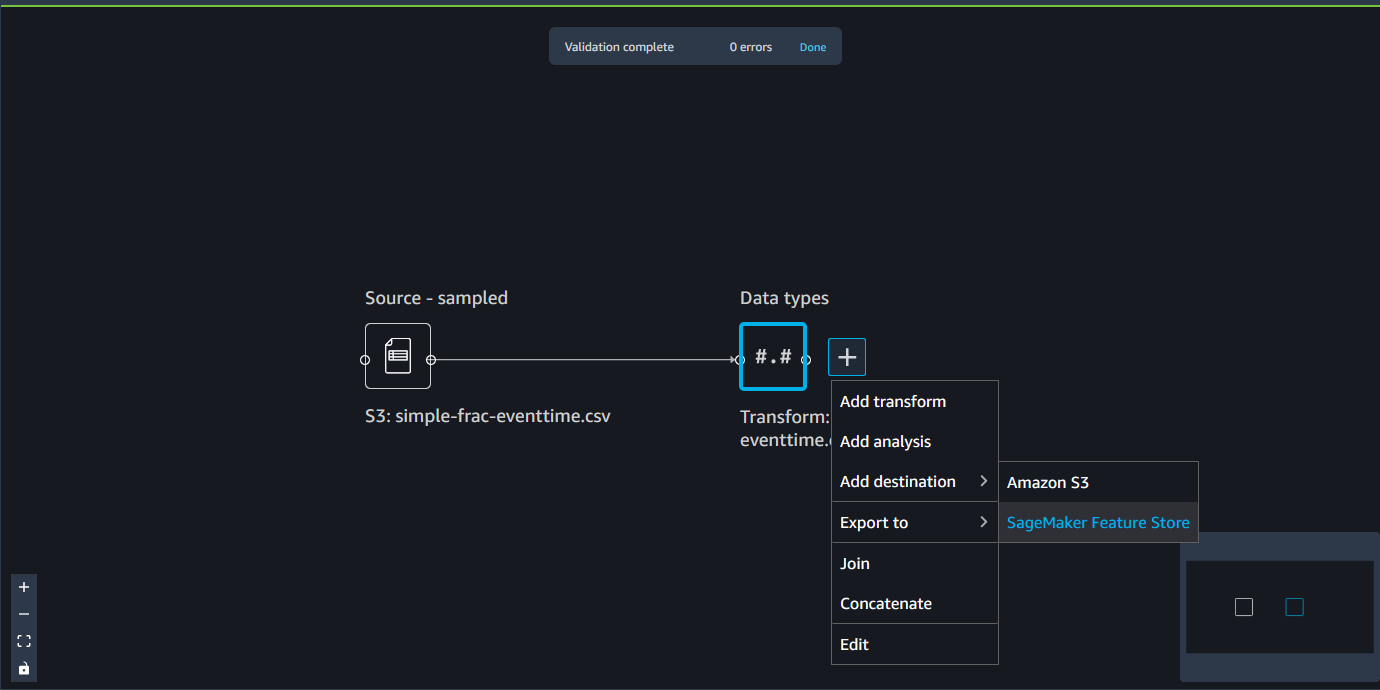
Data Wrangler 흐름은 데이터에 대해 수행한 일련의 데이터 준비 단계입니다. 데이터 준비 과정에서 데이터에 대한 변환을 한 번 이상 수행합니다. 각 변환은 변환 단계를 사용하여 이루어집니다. 흐름에는 데이터 가져오기와 자신이 수행한 변환을 나타내는 일련의 노드가 있습니다. 노드 예는 다음 이미지를 참조하세요.
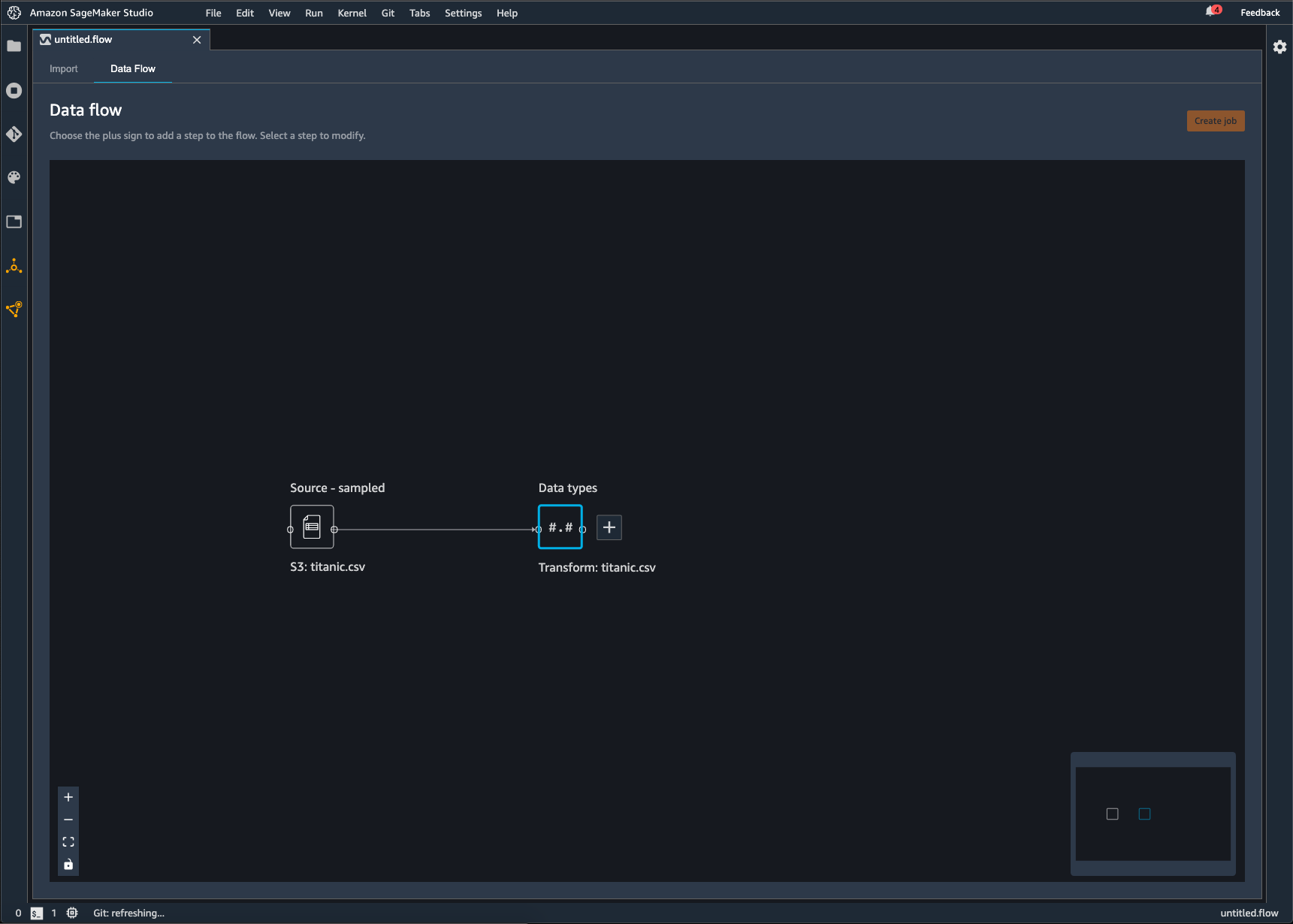
앞서 나온 이미지는 두 개의 노드가 있는 Data Wrangler 흐름을 보여줍니다. Source - sampled 노드는 데이터를 가져온 데이터 소스를 보여줍니다. Data types 노드는 Data Wrangler가 데이터세트를 사용 가능한 형식으로 바꾸도록 변환했음을 나타냅니다.
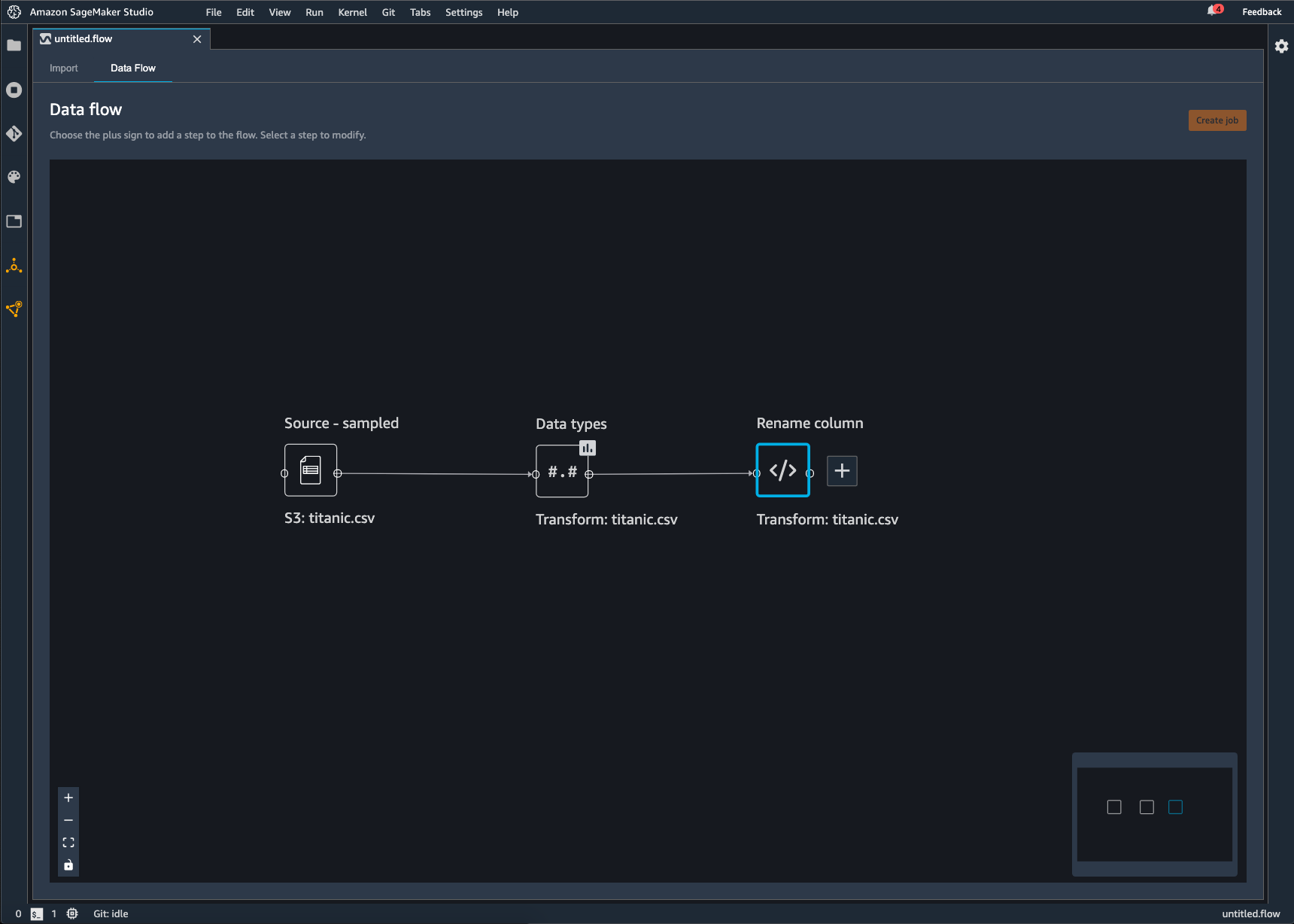
Data Wrangler 흐름에 추가하는 각 변환은 추가 노드로 나타납니다. 추가할 수 있는 변환에 대한 자세한 내용은 데이터 변환하기 섹션을 참조하세요. 다음 이미지는 데이터세트의 열 이름을 변경하기 위해 Rename-column 노드가 있는 Data Wrangler 흐름을 보여줍니다.
데이터 변환을 다음으로 내보낼 수 있습니다.
-
Amazon S3
-
Pipelines
-
Amazon SageMaker 특성 저장소
-
Python 코드
중요
IAM AmazonSageMakerFullAccess 관리형 정책을 사용하여 Data Wrangler를 사용할 수 있는 AWS 권한을 부여하는 것이 좋습니다. 관리형 정책을 사용하지 않는 경우 Data Wrangler에 Amazon S3 버킷 액세스 권한을 부여하는 IAM 정책을 사용할 수 있습니다. 정책에 대한 자세한 정보는 보안 및 권한 섹션을 참조하세요.
데이터 흐름을 내보내면 사용하는 AWS 리소스에 대한 요금이 부과됩니다. 비용 할당 태그를 사용하여 해당 리소스의 비용을 구성하고 관리할 수 있습니다. 사용자 프로필용으로 이러한 태그를 만들면 Data Wrangler가 데이터 흐름을 내보내는 데 사용되는 리소스에 해당 태그를 자동으로 적용합니다. 자세한 내용은 비용 할당 태그 사용하기를 참조하세요.
Amazon S3로 내보내기
Data Wrangler를 사용하면 Amazon S3 버킷 내 위치로 데이터를 내보낼 수 있습니다. 다음 방법 중 하나를 사용하여 위치를 지정할 수 있습니다.
-
대상 노드 – Data Wrangler가 데이터를 처리한 후 저장하는 위치입니다.
-
내보낼 위치 – Amazon S3로 변환한 결과 데이터를 내보냅니다.
-
데이터 내보내기 – 작은 데이터세트의 경우 변환한 데이터를 빠르게 내보낼 수 있습니다.
다음 섹션을 통해 이런 각각의 옵션에 대해 자세히 알아보세요.
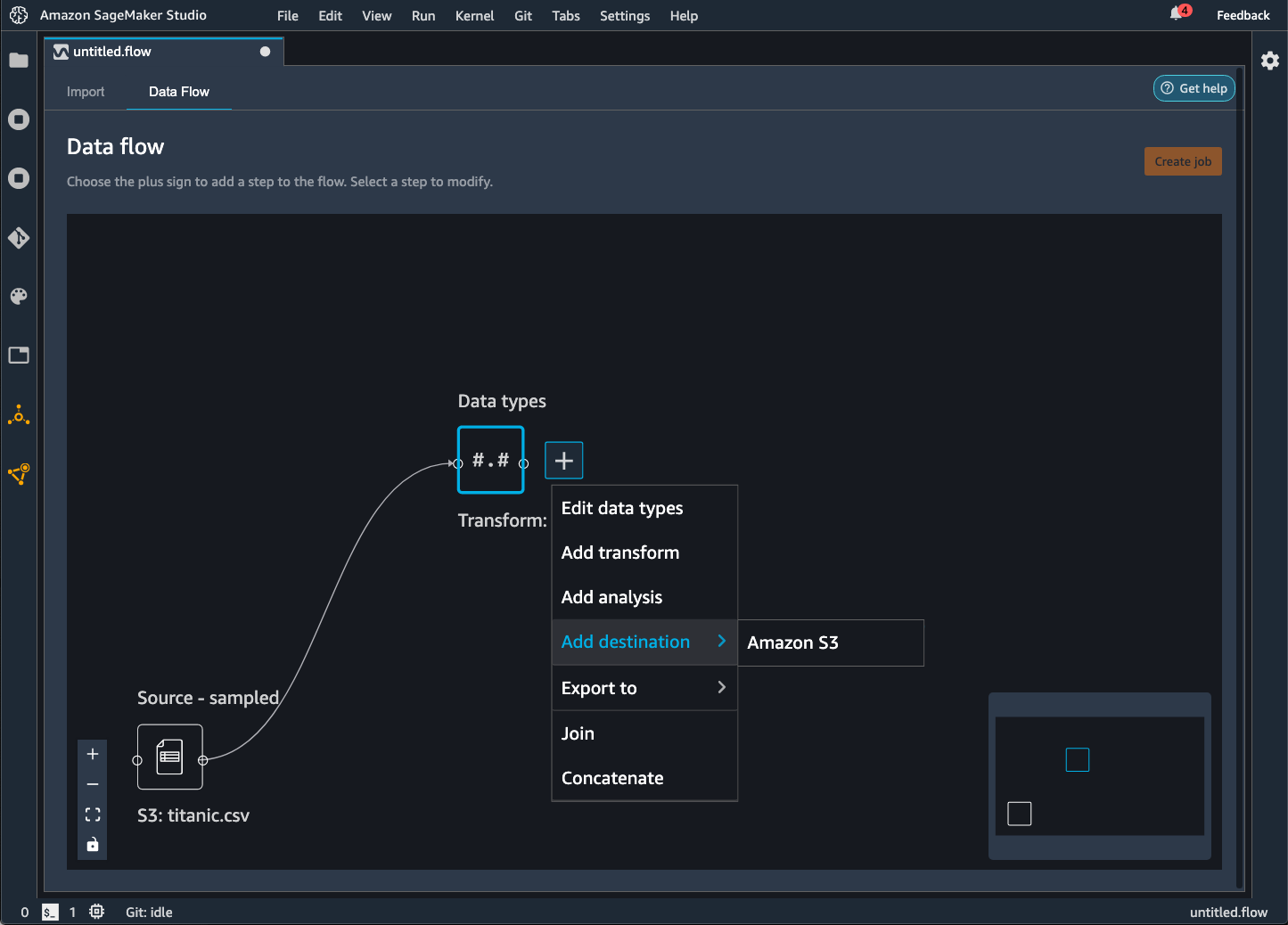
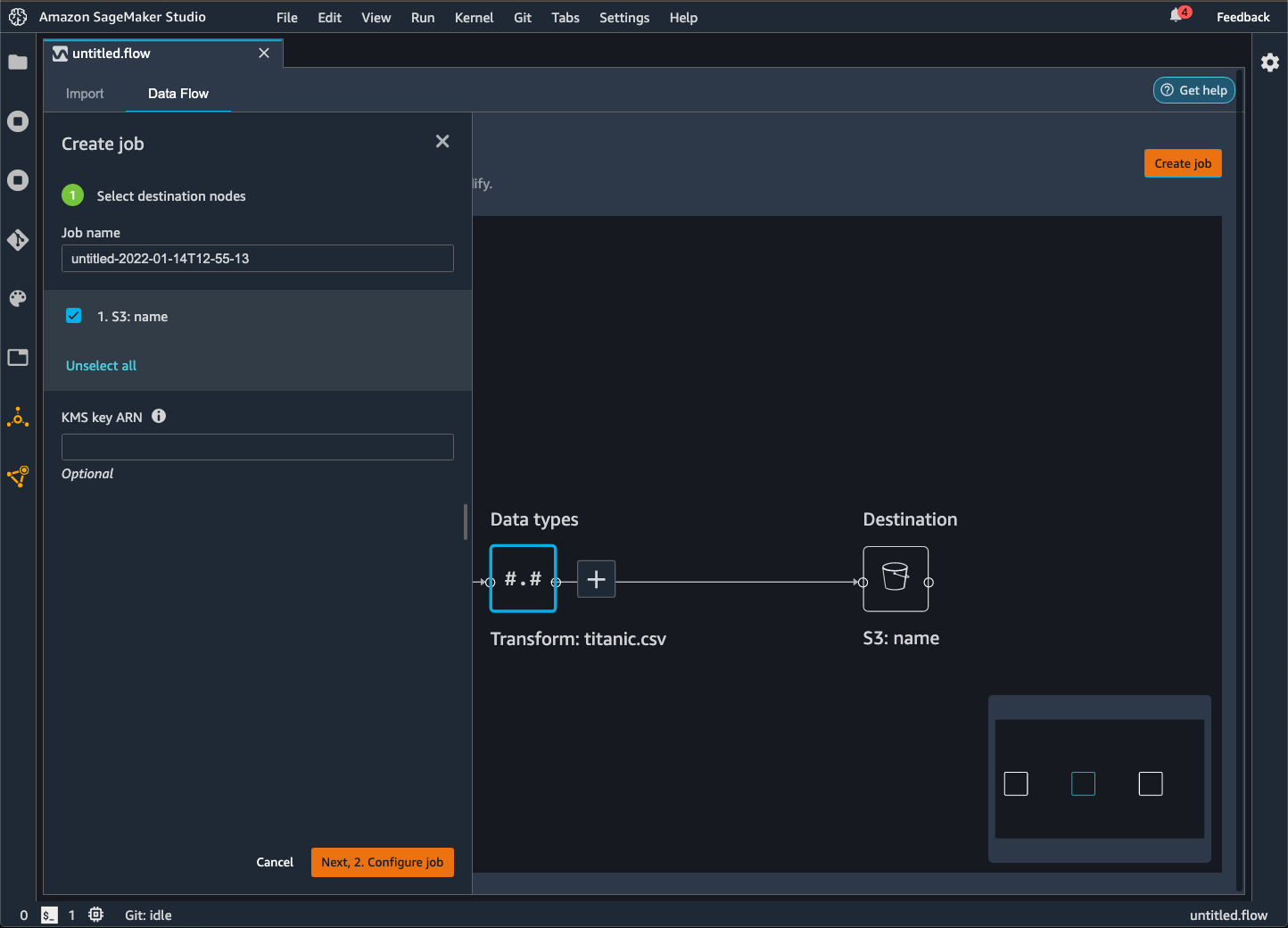
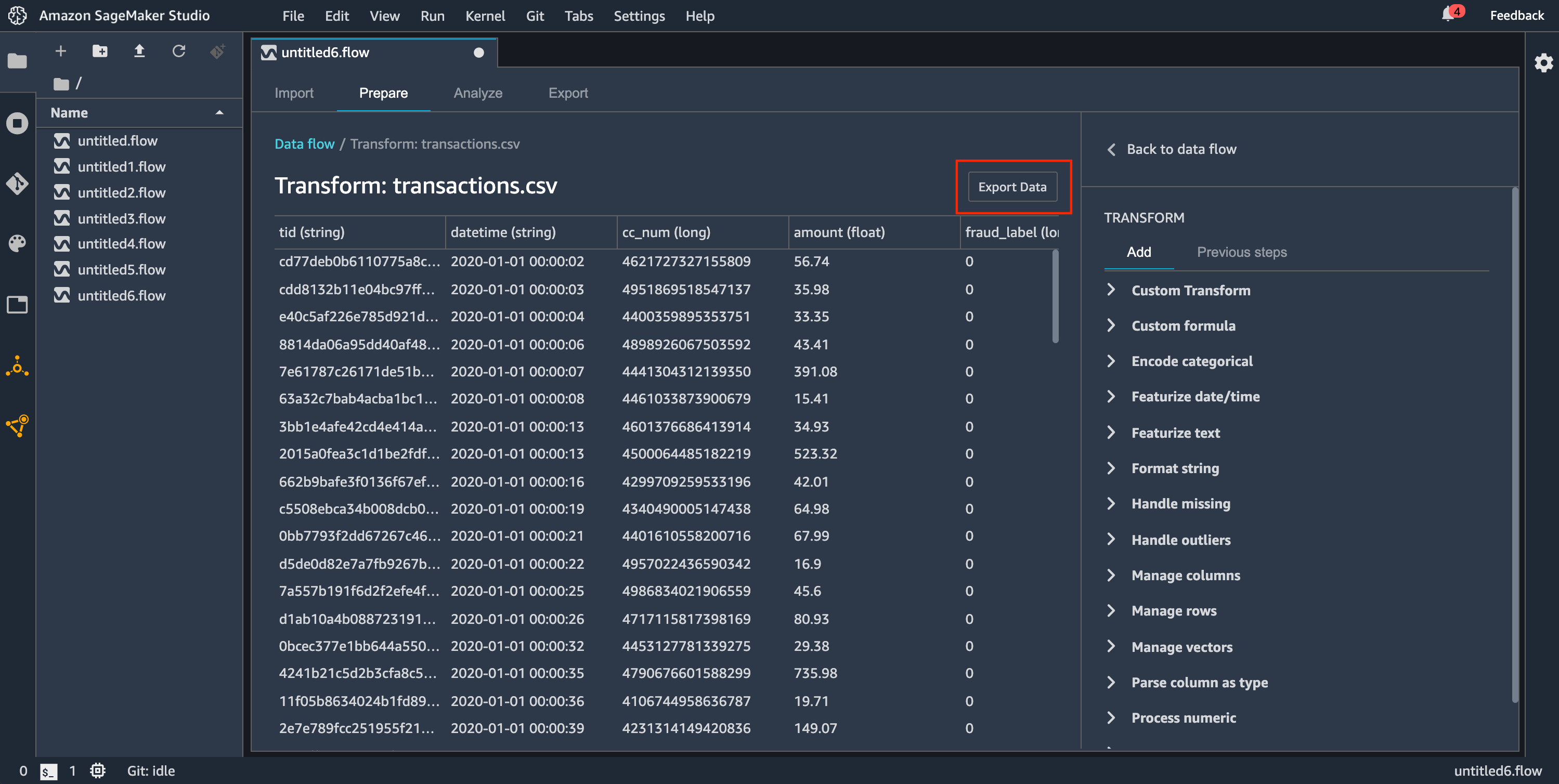
데이터 흐름을 Amazon S3 버킷으로 내보낼 경우 Data Wrangler는 흐름 파일의 복사본을 S3 버킷에 저장합니다. 그러면 흐름 파일이 data_wrangler_flow 접두사 아래에 저장됩니다. 기본 Amazon S3 버킷을 사용하여 흐름 파일을 저장하는 경우 sagemaker- 명명 규칙을 사용합니다. 예를 들어, 계정 번호가 111122223333이고 us-east-1에서 Studio Classic을 사용하는 경우 가져온 데이터세트는 region-account
numbersagemaker-us-east-1-111122223333에 저장됩니다. 이 예에서는 us-east-1에서 생성된 .flow 파일이 s3://sagemaker-에 저장됩니다.region-account
number/data_wrangler_flows/
Pipelines으로 내보내기
대규모 기계 학습(ML) 워크플로를 구축하고 배포하려는 경우 파이프라인을 사용하여 SageMaker AI 작업을 관리하고 배포하는 워크플로를 생성할 수 있습니다. 파이프라인을 사용하면 SageMaker AI 데이터 준비, 모델 훈련 및 모델 배포 작업을 관리하는 워크플로를 구축할 수 있습니다. Pipelines을 사용하여 SageMaker AI가 제공하는 자사 알고리즘을 사용할 수 있습니다. Pipelines에 대한 자세한 내용은 SageMaker Pipelines을 참조하세요.
데이터 흐름에서 Pipelines으로 하나 이상의 단계를 내보내는 경우 Data Wrangler는 파이프라인을 정의, 인스턴스화, 실행, 관리하는 데 사용할 수 있는 Jupyter Notebook을 만듭니다.
Jupyter notebook을 사용하여 파이프라인 생성하기
다음 절차를 사용하여 Jupyter Notebook을 만들어 Data Wrangler 흐름을 Pipelines으로 내보냅니다.
다음 절차를 사용하여 Jupyter notebook을 생성하고 이를 실행하여 Data Wrangler 흐름을 Pipelines으로 내보냅니다.
-
내보내고자 하는 노드 옆에 있는 +를 선택합니다.
-
Export to(내보내기)를 선택합니다.
-
(Jupyter Notebook을 통해) Pipelines을 선택합니다.
-
Jupyter notebook을 실행합니다.
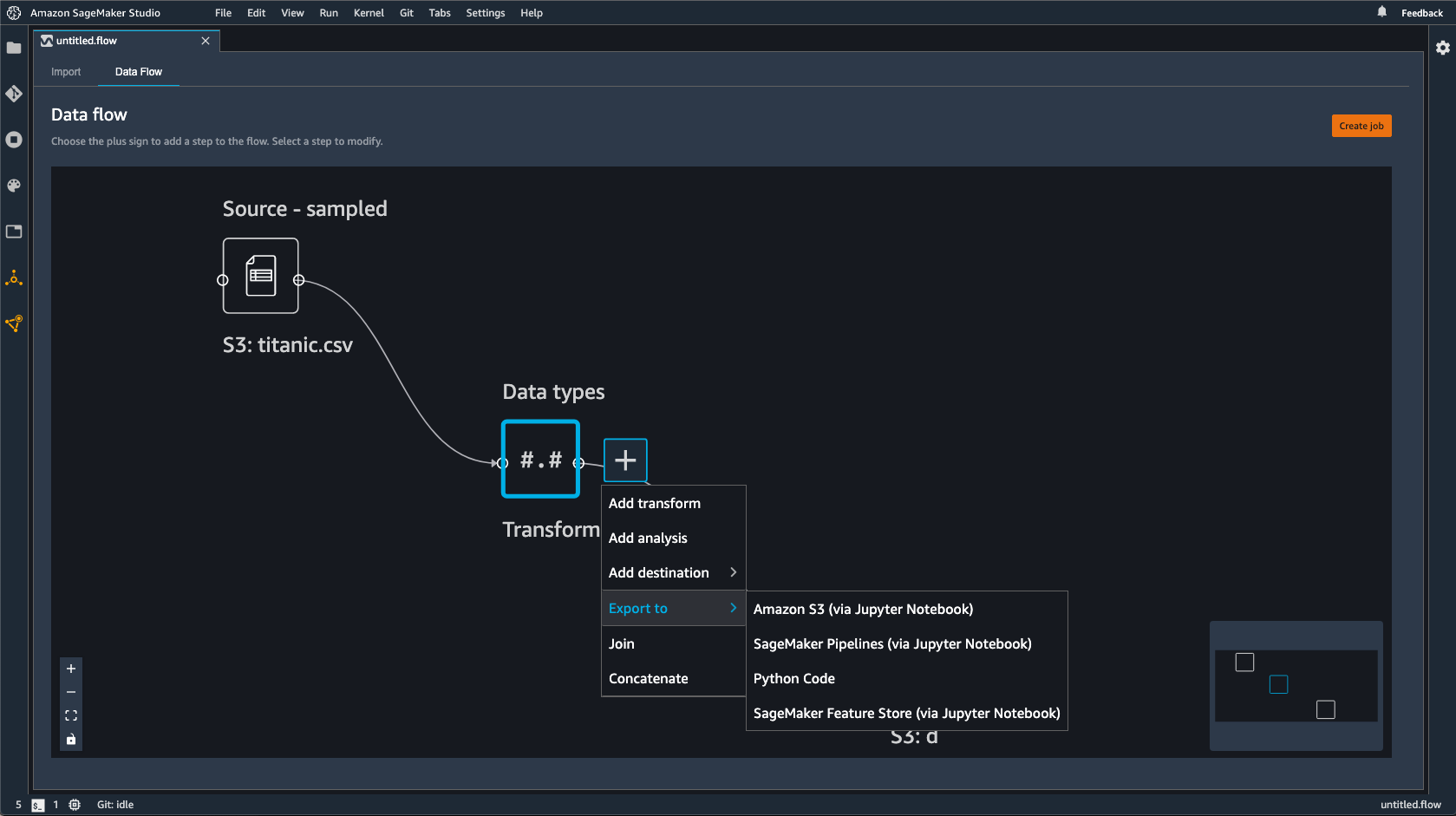
Data Wrangler가 생성하는 Jupyter notebook을 사용하여 파이프라인을 정의할 수 있습니다. 파이프라인에는 Data Wrangler 흐름으로 정의되는 데이터 처리 단계가 포함됩니다.
노트북의 다음 코드에 있는 steps 목록에 단계를 추가하여 파이프라인에 다른 단계를 추가할 수 있습니다.
pipeline = Pipeline( name=pipeline_name, parameters=[instance_type, instance_count], steps=[step_process], #Add more steps to this list to run in your Pipeline )
파이프라인 정의에 대한 자세한 내용은 SageMaker AI 파이프라인 정의를 참조하세요.
추론 엔드포인트로 내보내기
Data Wrangler 흐름을 사용하여 Data Wrangler 흐름에서 SageMaker AI 직렬 추론 파이프라인을 생성하여 추론 시 데이터를 처리합니다. 추론 파이프라인은 훈련된 모델이 새 데이터에 대해 예측하도록 하는 일련의 단계입니다. Data Wrangler 내의 직렬 추론 파이프라인은 원시 데이터를 변환하여 예측을 위해 기계 학습 모델에 제공합니다. Studio Classic 내 Jupyter Notebook에서 추론 파이프라인을 만들고, 실행하고, 관리합니다. 노트북에 액세스하는 방법에 대한 자세한 내용은 Jupyter notebook을 사용하여 추론 엔드포인트 생성하기 섹션을 참조하세요.
노트북 내에서 기계 학습 모델을 훈련시키거나 이미 훈련한 모델을 지정할 수 있습니다. Amazon SageMaker Autopilot 또는 XGBoost를 사용하여 Data Wrangler 흐름에서 변환한 데이터를 사용하여 모델을 훈련할 수 있습니다.
파이프라인은 배치 추론 또는 실시간 추론을 수행하는 기능을 제공합니다. SageMaker Model Registry에 Data Wrangler 흐름을 추가할 수도 있습니다. 호스팅 모델에 대한 자세한 내용은 다중 모델 엔드포인트 섹션을 참조하세요.
중요
다음과 같은 변환이 있는 경우 Data Wrangler 흐름을 추론 엔드포인트로 내보낼 수 없습니다.
-
조인
-
연결
-
그룹화 기준
이전 변환을 사용하여 데이터를 준비해야 하는 경우 다음 절차에 따르세요.
지원되지 않는 변환으로 추론할 수 있도록 데이터를 준비하려면
-
Data Wrangler 흐름을 생성합니다.
-
지원되지 않는 이전 변환을 적용합니다.
-
Amazon S3 버킷으로 데이터를 내보냅니다.
-
별도의 Data Wrangler 흐름을 생성합니다.
-
이전 흐름에서 내보낸 데이터를 가져옵니다.
-
나머지 변환을 적용합니다.
-
당사에서 제공하는 Jupyter notebook을 사용하여 직렬 추론 파이프라인을 생성합니다.
Amazon S3 버킷으로 데이터를 내보내는 방법에 대한 자세한 내용은 Amazon S3로 내보내기 섹션을 참조하세요. 직렬 추론 파이프라인을 생성하는 데 사용되는 Jupyter notebook을 여는 방법에 대한 자세한 내용은 Jupyter notebook을 사용하여 추론 엔드포인트 생성하기 섹션을 참조하세요.
Data Wrangler는 추론 시 데이터를 제거하는 변환을 무시합니다. 예를 들어 누락 삭제 구성을 사용하는 경우 Data Wrangler는 누락된 값 처리 변환을 무시합니다.
변환을 전체 데이터세트에 재구성한 경우 변환은 추론 파이프라인으로 이어집니다. 예를 들어 중앙값을 사용하여 누락된 값을 대입한 경우 변환 재구성의 중앙값이 추론 요청에 적용됩니다. Jupyter notebook을 사용하거나 추론 파이프라인으로 데이터를 내보내는 경우 Data Wrangler 흐름에서 변환을 재구성할 수 있습니다. 변환 재구성에 대한 자세한 내용은 변환을 전체 데이터세트로 재구성하고 내보내기 섹션을 참조하세요.
직렬 추론 파이프라인은 입력 및 출력 문자열에 대해 다음 데이터 형식을 지원합니다. 각 데이터 형식에는 일련의 요구 사항이 있습니다.
지원되는 데이터 형식
-
text/csv– CSV 문자열의 데이터 형식-
문자열에는 헤더가 있을 수 없습니다.
-
추론 파이프라인에 사용되는 특성은 훈련 데이터세트의 특성과 순서가 같아야 합니다.
-
특성 간에는 쉼표 구분 기호가 있어야 합니다.
-
레코드는 줄 바꿈 문자로 구분해야 합니다.
다음은 추론 요청에 제공할 수 있는 유효한 형식의 CSV 문자열의 예입니다.
abc,0.0,"Doe, John",12345\ndef,1.1,"Doe, Jane",67890 -
-
application/json– JSON 문자열의 데이터 형식-
추론 파이프라인용 데이터세트에 사용되는 특성은 훈련 데이터세트의 특성과 순서가 같아야 합니다.
-
데이터에는 특정 스키마가 있어야 합니다. 스키마를 일련의
features이 있는 단일instances객체로 정의합니다. 각features객체는 관측치를 나타냅니다.
다음은 추론 요청에서 제공할 수 있는 유효한 형식의 JSON 문자열의 예입니다.
{ "instances": [ { "features": ["abc", 0.0, "Doe, John", 12345] }, { "features": ["def", 1.1, "Doe, Jane", 67890] } ] } -
Jupyter notebook을 사용하여 추론 엔드포인트 생성하기
Data Wrangler 흐름을 내보내 추론 파이프라인을 생성하려면 다음 절차를 따르세요.
Jupyter notebook을 사용하여 추론 파이프라인을 만들려면 다음을 수행하세요.
-
내보내고자 하는 노드 옆에 있는 +를 선택합니다.
-
Export to(내보내기)를 선택합니다.
-
SageMaker AI 추론 파이프라인(Jupyter Notebook을 통해)을 선택합니다.
-
Jupyter notebook을 실행합니다.
Jupyter notebook을 실행하면 추론 흐름 아티팩트가 생성됩니다. 추론 흐름 아티팩트는 직렬 추론 파이프라인을 생성하는 데 사용되는 추가 메타데이터가 포함된 Data Wrangler 흐름 파일입니다. 내보내는 노드에는 이전 노드의 모든 변환이 포함됩니다.
중요
Data Wrangler가 추론 파이프라인을 실행하려면 추론 흐름 아티팩트가 필요합니다. 자체 흐름 파일을 아티팩트로 사용할 수 없습니다. 이전 절차를 사용하여 생성해야 합니다.
Python 코드로 내보내기
데이터 흐름의 모든 단계를 데이터 처리 워크흐름에 수동으로 통합할 수 있는 Python 파일로 내보내려면 다음 절차를 따르세요.
다음 절차에 따라 Jupyter notebook을 생성하고 실행하여 Data Wrangler 흐름을 Python Code로 내보냅니다.
-
내보내고자 하는 노드 옆에 있는 +를 선택합니다.
-
내보낼 위치를 선택합니다.
-
Python 코드를 선택합니다.
-
Jupyter notebook을 실행합니다.
파이프라인에서 실행되도록 Python 스크립트를 구성해야 할 수도 있습니다. 예를 들어 Spark 환경을 실행하는 경우 AWS 리소스에 액세스할 권한이 있는 환경에서 스크립트를 실행하고 있는지 확인합니다.
Amazon SageMaker 특성 저장소로 내보내기
Data Wrangler를 사용하여 생성한 특성을 Amazon SageMaker 특성 저장소로 내보낼 수 있습니다. 특성은 데이터세트의 열입니다. 특성 저장소는 특성 및 관련 메타데이터를 위한 중앙 집중식 저장소입니다. 특성 저장소를 사용하여 기계 학습(ML) 개발을 위해 큐레이션된 데이터를 생성, 공유, 관리할 수 있습니다. 중앙 집중식 저장소를 사용하면 데이터를 더 쉽게 검색하고 재사용할 수 있습니다. 특성 저장소에 대한 자세한 내용은 Amazon SageMaker 특성 저장소를 참조하세요.
특성 저장소의 핵심 개념은 특성 그룹입니다. 특성 그룹은 특성, 특성 레코드(관측치), 관련 메타데이터의 모음입니다. 데이터베이스의 테이블과 유사합니다.
Data Wrangler를 사용하여 다음 중 하나를 수행할 수 있습니다.
-
기존 특성 그룹을 새 레코드로 업데이트합니다. 레코드는 데이터세트의 관측치입니다.
-
Data Wrangler 흐름의 노드에서 새 특성 그룹을 생성합니다. Data Wrangler는 데이터세트의 관측치를 특성 그룹의 레코드로 추가합니다.
기존 특성 그룹을 업데이트하는 경우 데이터세트의 스키마가 특성 그룹의 스키마와 일치해야 합니다. 특성 그룹의 모든 레코드가 데이터세트의 관측치로 바뀝니다.
Jupyter notebook 또는 대상 노드를 사용하여 데이터세트의 관측치로 특성 그룹을 업데이트할 수 있습니다.
Iceberg 테이블 형식의 특성 그룹에 사용자 지정 오프라인 저장소 암호화 키가 있는 경우 이를 사용할 Amazon SageMaker Processing 작업 권한을 사용 중인 IAM에 부여해야 합니다. 최소한, Amazon S3에 쓰는 데이터를 암호화할 권한을 부여해야 합니다. 권한을 부여하려면 IAM 역할에 GenerateDatakey를 사용할 권한을 부여하세요. IAM 역할에 AWS KMS 키 사용 권한을 부여하는 방법에 대한 자세한 내용은 섹션을 참조하세요. https://docs.aws.amazon.com/kms/latest/developerguide/key-policies.html
노트북은 이러한 구성을 사용하여 특성 그룹을 생성하고 데이터를 대규모로 처리한 다음, 처리된 데이터를 온라인 및 오프라인 특성 저장소에 수집합니다. 자세히 알아보려면 데이터 소스 및 수집을 참조하세요.
변환을 전체 데이터세트로 재구성하고 내보내기
데이터를 가져올 때 Data Wrangler는 데이터 샘플을 사용하여 인코딩을 적용합니다. 기본적으로, Data Wrangler는 처음 50,000개 행을 샘플로 사용하지만 전체 데이터세트를 가져오거나 다른 샘플링 방법을 사용할 수 있습니다. 자세한 내용은 가져오기 단원을 참조하세요.
다음 변환은 데이터를 사용하여 데이터세트에 열을 생성합니다.
샘플링을 사용하여 데이터를 가져온 경우 이전 변환은 샘플의 데이터만 사용하여 열을 생성합니다. 변환에서 관련 데이터를 모두 사용하지는 않았을 수도 있습니다. 예를 들어 카테고리 인코딩 변환을 사용하는 경우 전체 데이터세트에 샘플에는 없는 카테고리가 있었을 수 있습니다.
대상 노드나 Jupyter notebook을 사용하여 변환을 전체 데이터세트에 맞춰 재구성할 수 있습니다. Data Wrangler는 흐름에서 변환을 내보낼 때 SageMaker Processing 작업을 생성합니다. 처리 작업이 완료될 때 Data Wrangler는 기본 Amazon S3 위치 또는 사용자가 지정한 S3 위치에 다음 파일을 저장합니다.
-
데이터세트에 맞게 재구성되는 변환을 지정하는 Data Wrangler 흐름 파일
-
재구성 변환이 적용된 데이터세트
Data Wrangler 내에서 Data Wrangler 흐름 파일을 열고 변환을 다른 데이터세트에 적용할 수 있습니다. 예를 들어 훈련 데이터세트에 변환을 적용한 경우 Data Wrangler 흐름 파일을 열고 사용하여 추론에 사용되는 데이터세트에 변환을 적용할 수 있습니다.
대상 노드를 사용하여 변환을 재구성하고 내보내는 방법에 대한 자세한 내용은 다음 페이지를 참조하세요.
다음 절차에 따라 Jupyter notebook을 실행하여 변환을 재구성하고 데이터를 내보냅니다.
Jupyter notebook을 실행하고 변환을 재구성하고 Data Wrangler 흐름을 내보내려면 다음을 수행하세요.
-
내보내고자 하는 노드 옆에 있는 +를 선택합니다.
-
내보낼 위치를 선택합니다.
-
데이터를 내보낼 위치를 선택합니다.
-
refit_trained_params객체의 경우refit을True로 설정합니다. -
output_flow필드의 경우 재구성 변환이 포함된 출력 흐름 파일의 이름을 지정합니다. -
Jupyter notebook을 실행합니다.
새 데이터를 자동으로 처리하는 일정을 생성합니다.
데이터를 주기적으로 처리하는 경우 처리 작업을 자동으로 실행하는 일정을 생성할 수 있습니다. 예를 들어 새 데이터를 받을 때 처리 작업을 자동으로 실행하는 일정을 생성할 수 있습니다. 처리 작업에 대한 자세한 내용은 Amazon S3로 내보내기 및 Amazon SageMaker 특성 저장소로 내보내기 섹션을 참조하세요.
작업을 생성할 때는 작업을 생성할 권한이 있는 IAM 역할을 지정해야 합니다. 기본적으로 Data Wrangler에 액세스하는 데 사용하는 IAM 역할은 SageMakerExecutionRole입니다.
다음 권한을 통해 Data Wrangler가 EventBridge에 액세스하고 EventBridge가 처리 작업을 실행하도록 할 수 있습니다.
-
Data Wrangler에 EventBridge 사용 권한을 제공하는 Amazon SageMaker Studio Classic 실행 역할에 다음 AWS 관리형 정책을 추가합니다.
arn:aws:iam::aws:policy/AmazonEventBridgeFullAccess정책에 대한 자세한 내용은 EventBridge의AWS 관리형 정책을 참조하세요.
-
Data Wrangler에서 작업을 생성할 때 지정하는 IAM 역할에 다음 정책을 추가합니다.
기본 IAM 역할을 사용하는 경우 Amazon SageMaker Studio Classic 실행 역할에 이전 정책을 추가합니다.
다음 신뢰 정책을 이 역할에 추가하여 EventBridge가 신뢰 정책을 받아들이도록 합니다.
{ "Effect": "Allow", "Principal": { "Service": "events.amazonaws.com" }, "Action": "sts:AssumeRole" }
중요
일정을 생성하면 Data Wrangler는 EventBridge에 eventRule을 생성합니다. 생성한 이벤트 규칙과 처리 작업 실행에 사용되는 인스턴스에 모두 요금이 부과됩니다.
EventBridge 요금에 대한 자세한 내용은 Amazon EventBridge 요금
다음 방법 중 하나를 사용하여 일정을 설정할 수 있습니다.
다음 섹션에는 작업 생성 절차가 나와 있습니다.
Amazon SageMaker Studio Classic을 사용하여 실행하도록 예약된 작업을 볼 수 있습니다. 처리 작업은 Pipelines 내에서 실행됩니다. 각 처리 작업에는 자체적인 파이프라인이 있습니다. 파이프라인 내에서 처리 단계로 실행됩니다. 파이프라인 내에서 생성한 일정을 볼 수 있습니다. 파이프라인을 보는 방법에 대한 자세한 내용은 파이프라인 세부 정보 보기 섹션을 참조하세요.
예약한 작업을 보려면 다음 절차를 따르세요.
예약한 작업을 보려면 다음을 수행하세요.
-
Amazon SageMaker Studio Classic을 엽니다.
-
Pipelines 열기
-
생성한 작업의 파이프라인을 확인합니다.
작업을 실행 중인 파이프라인은 작업 이름을 접두사로 사용합니다. 예를 들어
housing-data-feature-enginnering이라는 작업을 생성한 경우 파이프라인의 이름은data-wrangler-housing-data-feature-engineering입니다. -
작업이 포함된 파이프라인을 선택합니다.
-
파이프라인의 상태를 확인합니다. 성공 상태인 파이프라인이 처리 작업을 성공적으로 실행했습니다.
처리 작업의 실행을 중지하려면 다음을 수행하세요.
처리 작업의 실행을 중지하려면 일정을 지정하는 이벤트 규칙을 삭제하세요. 이벤트 규칙을 삭제하면 일정과 관련된 모든 작업의 실행이 중지됩니다. 규칙 삭제에 대한 자세한 내용은 Amazon EventBridge 규칙 비활성화 또는 삭제를 참조하세요.
일정과 관련된 파이프라인도 중지하고 삭제할 수 있습니다. 파이프라인 중지에 대한 자세한 내용은 StopPipelineExecution을 참조하세요. 파이프라인 삭제에 대한 자세한 내용은 DeletePipeline을 참조하세요.
