기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
SageMaker AI DeepAR 예측 알고리즘 사용
Amazon SageMaker AI DeepAR 예측 알고리즘은 반복 신경망(RNN)을 사용하여 스칼라(1차원) 시계열을 예측하기 위한 지도 학습 알고리즘입니다. 자동 회귀적 통합 이동 평균(ARIMA) 또는 지수 평활(ETS)과 같은 고전적 예측 방법은 단일 모델을 개별 시계열에 맞춥니다. 그런 다음 해당 모델을 사용하여 시계열을 미래로 추정합니다.
그러나 많은 애플리케이션에서 일련의 횡단적 단위에 걸쳐 비슷한 시계열이 많이 있습니다. 예를 들어, 다양한 제품, 서버 로드 및 웹페이지에 대한 요청을 위한 시계열 그룹화가 있을 수 있습니다. 이러한 유형의 애플리케이션의 경우 모든 시계열에 대해 단일 모델을 공동으로 훈련하는 것이 이로울 수 있습니다. DeepAR는 이러한 접근 방법을 사용합니다. 데이터세트에 수백 개의 관련 시계열이 포함되어 있는 경우, DeepAR이 표준 ARIMA 및 ETS 방법보다 우수합니다. 또한 훈련받은 모델과 유사한 새 시계열에 대한 예상을 생성하기 위해 훈련받은 모델을 사용할 수도 있습니다.
DeepAR 알고리즘에 대한 훈련 입력은 동일한 프로세스 또는 유사한 프로세스에 의해 생성된 하나 또는 그 이상의 target 시계열입니다. 알고리즘은 이 입력 데이터세트을 기반으로 이 프로세스/프로세스에 대한 근사치를 학습하는 모델을 훈련시키고 이를 사용하여 표적 시시계열이 어떻게 발전하는지를 예측합니다. 각 대상 시계열은 선택적으로 cat 필드에서 제공하는 정적(시간 독립) 범주형 형상의 벡터 및 dynamic_feat 필드가 제공하는 동적(시간 종속) 시계열의 벡터와 연관될 수 있습니다. SageMaker AI는 훈련 데이터 세트의 각 대상 시계열에서 훈련 예제를 무작위로 샘플링하여 DeepAR 모델을 훈련합니다. 각 훈련 예제는 미리 정의된 길이가 고정된 한 쌍의 인접 컨텍스트 및 예상 창으로 구성됩니다. 네트워크에서 과거를 어느 시점까지 볼 수 있는지 제어하려면 context_length 하이퍼파라미터를 사용합니다. 미래의 어느 시점까지 예측할 수 있는지 제어하려면 prediction_length 하이퍼파라미터를 사용합니다. 자세한 내용은 DeepAR 알고리즘 작동 방법 섹션을 참조하세요.
주제
DeepAR 알고리즘을 위한 입력/출력 인터페이스
DeepAR은 두 가지 데이터 채널을 지원합니다. 필수 train 채널은 훈련 데이터세트를 설명합니다. 선택적 test 채널은 알고리즘에서 훈련 후 모델 정확성을 평가하는 데 사용하는 데이터세트를 설명합니다. JSON Lines
훈련 및 테스트 데이터에 대한 경로를 지정할 때 단일 파일을 지정하거나 여러 파일이 포함된 디렉터리를 지정할 수 있습니다. 후자의 경우 여러 파일은 하위 디렉터리에 저장할 수 있습니다. 디렉터리를 지정하면 DeepAR에서는 이 디렉터리의 모든 파일을 해당 채널의 입력으로 사용할 수 있지만 마침표(.)로 시작하거나 _SUCCESS라고 이름이 지정된 파일은 예외입니다. 그러면 Spark 작업에서 생성된 출력 폴더를 DeepAR 훈련 작업에 대한 입력 채널로 직접 사용할 수 있습니다.
기본적으로, DeepAR 모델은 지정된 입력 경로에 있는 파일 확장자(.json, .json.gz 또는 .parquet)를 통해 입력 형식을 확인합니다. 경로가 이러한 확장자 중 하나로 끝나지 않으면 SDK for Python에 형식을 명시적으로 지정해야 합니다. s3_inputcontent_type 파라미터를 사용하세요.
입력 파일의 레코드에는 다음 필드가 포함되어 있어야 합니다.
-
start-YYYY-MM-DD HH:MM:SS형식의 문자열. 시작 타임스탬프에는 시간대 정보가 포함될 수 없습니다. -
target- 시계열을 나타내는 부동 소수점 값 또는 정수로 구성된 배열. 누락된 값은null리터럴, JSON 형식의"NaN"문자열 또는 Parquet 형식의nan부동 소수점 값으로 인코딩할 수 있습니다. -
dynamic_feat(선택 사항) - 사용자 지정 기능 시계열(동적 특성)의 벡터를 나타내는 부동 소수점 값 또는 정수로 구성된 배열. 이 필드를 설정하면 모든 레코드에 동일한 수의 내측 배열이 있어야 합니다(요인(feature) 시계열과 동일한 수). 또한 각 내측 배열은 연결된target값에prediction_length를 더한 것과 길이가 같아야 합니다. 누락된 값은 요인(feature)에서 지원되지 않습니다. 예를 들어, 표적 시계열이 서로 다른 제품의 수요를 나타낼 경우, 연결된dynamic_feat는 특정 제품에 프로모션이 적용되었는지 여부(적용 1, 비적용 0)를 나타내는 부울 시계열일 수 있습니다.{"start": ..., "target": [1, 5, 10, 2], "dynamic_feat": [[0, 1, 1, 0]]} -
cat(선택 사항) - 레코드가 속한 그룹을 인코딩하는 데 사용할 수 있는 범주형 기능의 배열입니다. 범주 요인(feature)은 양의 정수의 0부터 시작하는 시퀀스로 인코딩해야 합니다. 예를 들어, 범주형 도메인 {R, G, B}은 {0, 1, 2}로 인코딩할 수 있습니다. 각 범주형 도메인의 모든 값이 훈련 데이터세트에 나타나야 합니다. 이는 DeepAR 알고리즘이 훈련 중 관찰된 범주에 대해서만 예측할 수 있기 때문입니다. 각 범주 요인(feature)은 차원이embedding_dimension하이퍼파라미터로 제어되는 저차원 공간에서 임베딩됩니다. 자세한 내용은 DeepAR 하이퍼파라미터 섹션을 참조하세요.
JSON 파일을 사용하는 경우 이 파일은 JSON Lines
{"start": "2009-11-01 00:00:00", "target": [4.3, "NaN", 5.1, ...], "cat": [0, 1], "dynamic_feat": [[1.1, 1.2, 0.5, ...]]} {"start": "2012-01-30 00:00:00", "target": [1.0, -5.0, ...], "cat": [2, 3], "dynamic_feat": [[1.1, 2.05, ...]]} {"start": "1999-01-30 00:00:00", "target": [2.0, 1.0], "cat": [1, 4], "dynamic_feat": [[1.3, 0.4]]}
이 예에서 각 시계열에는 연결된 범주 요인(feature) 2개와 시계열 요인(feature) 하나가 있습니다.
Parquet의 경우 동일한 3개 필드를 열로 사용합니다. 추가로 "start"는 datetime 유형일 수 있습니다. Parquet 파일은 gzip(gzip) 또는 Snappy 압축 라이브러리(snappy)를 사용하여 압축할 수 있습니다.
알고리즘이 cat 필드와 dynamic_feat 필드 없이 훈련되면 추론 시간에 표적 시계열의 특정 ID에 구애받지 않고 그 형상에만 조건화되는 "global" 모델을 학습합니다.
모델이 각 시계열에 대해 제공된 cat 및 dynamic_feat 요인(feature) 데이터에 대해 조건화되면, 예측은 해당 cat 요인과 함께 시계열의 특성의 영향을 받을 것입니다. 예를 들어 target 시계열이 의류 품목의 수요를 나타낼 경우, 첫 구성 요소에 품목 유형(예 0 = 신발, 1 = 드레스)를 인코딩하고 두 번째 구성 요소에 품목 색상(예 0 = 빨간색, 1 = 파란색)을 인코딩하는 2차원 cat 벡터를 연결할 수 있습니다. 샘플 입력은 다음과 같습니다.
{ "start": ..., "target": ..., "cat": [0, 0], ... } # red shoes { "start": ..., "target": ..., "cat": [1, 1], ... } # blue dress
추론 시, 훈련 데이터에서 관찰된 cat 값의 조합인 cat 값으로 표적에 대한 예측을 요청할 수 있습니다.
{ "start": ..., "target": ..., "cat": [0, 1], ... } # blue shoes { "start": ..., "target": ..., "cat": [1, 0], ... } # red dress
훈련 데이터에는 다음 지침이 적용됩니다.
-
시계열의 시작 시간과 길이는 다를 수 있습니다. 예를 들어 마케팅에서 제품은 서로 다른 날짜에 소매 카탈로그에 입력되는 경우가 많으므로 이에 따라 시작 날짜가 다릅니다. 하지만 모든 시계열은 빈도, 범주 요인(feature) 수 및 동적 요인 수가 동일해야 합니다.
-
파일 내에서 시계열의 위치와 관련해 훈련 파일을 셔플합니다. 다시 말해 시계열이 파일에서 임의 순서로 발생해야 합니다.
-
start필드를 올바르게 설정했는지 확인합니다. 이 알고리즘은start타임스탬프를 사용하여 내부 요인(feature)을 가져옵니다. -
범주 요인(feature)(
cat)을 사용하는 경우 모든 시계열에 동일한 수의 범주 요인(feature)이 있어야 합니다. 데이터세트에cat필드가 있는 경우 이 알고리즘은 이 필드를 사용하여 데이터세트에서 여러 그룹의 카디널리티를 추출합니다. 기본적으로cardinality는"auto"입니다. 데이터세트에cat필드가 포함되어 있지만 사용하지 않으려는 경우cardinality를""으로 설정하여 비활성화할 수 있습니다.cat요인(feature)을 사용하여 모델을 훈련한 경우에는 추론에 이 요인(feature)을 포함해야 합니다. -
데이터세트에
dynamic_feat필드가 포함된 경우 이 알고리즘은 이 필드를 자동으로 사용합니다. 모든 시계열에는 동일한 수의 요인(feature) 시계열이 있어야 합니다. 각 요인(feature) 시계열의 시점은 대상의 시점과 일대일로 대응합니다. 또한dynamic_feat필드의 항목은 길이가target과 동일해야 합니다. 데이터세트에dynamic_feat필드가 포함되어 있지만 사용하지 않으려는 경우num_dynamic_feat를""으로 설정하여 비활성화할 수 있습니다.dynamic_feat필드를 사용하여 모델을 훈련한 경우 추론에 이 필드를 제공해야 합니다. 또한 각 요인(feature)은 제공된 대상의 길이와prediction_length를 더한 것과 길이가 같아야 합니다. 즉, 향후 요인(feature) 값을 제공해야 합니다.
선택 사항인 test 채널 데이터를 지정하는 경우 DeepAR 알고리즘은 다른 정확도 지표를 사용하여 교육된 모델을 평가합니다. 알고리즘은 다음과 같이 테스트에 걸쳐 평균 제곱근 오차(RMSE)를 계산합니다.
-y(i,t))^2))](images/deepar-1.png)
yi,t는 시간 t에서 시계열 i의 참값입니다. ŷi,t는 평균 예측입니다. 합은 테스트 세트의 전체 n 시계열이고 각 시계열에 대한 마지막 T 시점입니다. 여기서 T는 예측 구간과 일치합니다. prediction_length 하이퍼파라미터를 설정하여 예측 구간의 길이를 지정합니다. 자세한 내용은 DeepAR 하이퍼파라미터 섹션을 참조하세요.
또한 이 알고리즘은 가중 분위 손실을 사용하여 예측 배포의 정확성을 평가됩니다. 범위 [0, 1]의 분위에 대해 가중 분위 손실은 다음과 같이 정의됩니다.
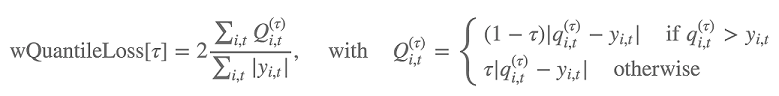
qi,t(τ)는 모델이 예측한 배포의 τ-분위입니다. 손실을 계산할 분위를 지정하려면 test_quantiles 하이퍼파라미터를 설정합니다. 또한, 지정된 분위 손실 평균이 훈련 로그의 일부로 보고됩니다. 자세한 내용은 DeepAR 하이퍼파라미터을 참조하세요.
추론을 위해 DeepAR은 JSON 형식과 다음 필드를 수락합니다.
-
"instances": 하나 이상의 시계열을 JSON Lines 형식으로 포함하고 있습니다. -
"configuration"의 이름: 예측 생성을 위한 파라미터를 포함하고 있습니다.
자세한 내용은 DeepAR 추론 형식 섹션을 참조하세요.
DeepAR 알고리즘 사용의 모범 사례
시계열 데이터를 준비할 때 최적의 결과를 얻으려면 다음 모범 사례를 따르세요.
-
훈련 및 데이터를 위해 세트를 분리하는 경우를 제외하고는 훈련 및 테스트 시 그리고 추론을 위해 모델을 호출할 때 항상 전체 시계열을 제공합니다.
context_length를 설정한 방법에 관계없이 시계열을 분할하거나 시계열 중 일부만 제공하지 마세요. 모델은 지연된 값 요인(feature)에 대해context_length에 설정된 값보다 더 뒤쪽의 데이터 포인트를 사용합니다. -
DeepAR 모델을 튜닝하는 경우 데이터세트를 분할해 훈련 데이터세트와 테스트 데이터세트를 생성할 수 있습니다. 일반적인 평가에서는 훈련에 사용된 것과 동일한 시계열에 대해 모델을 테스트하지만 이후에는 훈련 중에 표시된 마지막 시점 직후
prediction_length시점에 대해 테스트합니다. 테스트 세트로 전체 데이터세트(사용 가능한 시계열의 전체 길이)를 사용하고 훈련에 대한 각 시계열에서 마지막prediction_length시점을 제거하여 이러한 기준을 충족하는 훈련 및 테스트 데이터세트를 생성할 수 있습니다 훈련 중에는 모델이 테스트 중에 평가된 시점의 대상 값을 볼 수 없습니다. 테스트 중 알고리즘은 테스트 세트 내 각 시계열의 마지막prediction_length지점을 보류하고 예측을 생성합니다. 그런 다음 예측을 보류된 값과 비교합니다. 테스트 세트에서 시계열을 여러 번 반복하면서 다른 엔드포인트에서 잘라내어 더 복잡한 평가를 생성할 수 있습니다. 이러한 접근 방식을 통해 여러 시점의 다양한 예측에 대해 정확도 지표가 평균화됩니다. 자세한 내용은 DeepAR 모델 튜닝 섹션을 참조하세요. -
모델이 느려지고 정확도가 떨어지므로
prediction_length에 매우 큰 값(> 400)을 사용하지 마세요. 향후 추가 예측을 원하는 경우 더 낮은 빈도로 데이터를 집계할 것을 고려하세요. 예를 들어1min대신5min을 사용하세요. -
시차가 사용되기 때문에 모델은
context_length에 대해 지정된 값보다 시계열에서 훨씬 멀리 볼 수 있습니다. 따라서 이 파라미터 큰 값으로 설정할 필요가 없습니다.prediction_length에 사용한 값으로 시작하는 것이 좋습니다. -
가능한 많은 시계열로 DeepAR 모델을 훈련하는 것이 좋습니다. 단일 시계열에 대해 훈련한 DeepAR 모델이 잘 작동할지라도 ARIMA 또는 ETS 등과 같은 표준 예측 알고리즘이 더욱 정확한 결과를 제공할 수 있습니다. DeepAR 알고리즘은 데이터세트에 수백 개의 관련 시계열이 있을 때 표준 방법보다 성능이 더 크게 증가하기 시작합니다. 현재 DeepAR에는 모든 훈련 시계열에서 사용 가능한 총 관측 수가 최소 300개 이상 필요합니다.
DeepAR 알고리즘을 위한 EC2 인스턴스 권장 사항
단일 또는 다중 머신 설정의 GPU 및 CPU 인스턴스에서 DeepAR을 훈련할 수 있습니다. 단일 CPU 인스턴스(예: ml.c4.2xlarge 또는 ml.c4.4xlarge)로 시작한 다음 필요한 경우에만 GPU 인스턴스 및 다중 머신으로 전환하는 것이 좋습니다. 여러 개의 GPU와 머신을 사용하면 (계층마다 많은 셀이 있고 많은 수 계층이 있는) 큰 모델과 큰 미니 배치 크기(예: 512 이상)의 경우에만 처리량이 늘어납니다.
추론을 위해 DeepAR은 CPU 인스턴스만 지원합니다.
context_length, prediction_length, num_cells, num_layers 또는 mini_batch_size에 대해 큰 값을 지정하면 스몰 인스턴스에는 너무 큰 모델이 생성될 수 있습니다. 이러한 경우에는 더 큰 인스턴스 유형을 사용하거나 파라미터에 대한 값을 줄입니다. 이러한 문제는 하이퍼파라미터 튜닝 작업을 실행하는 경우 자주 발생합니다. 문제가 발생한 경우에는 작업 실패를 방지하기 위해 모델 튜닝 작업에 충분히 큰 인스턴스 유형을 사용하고 중요한 파라미터의 상한값을 제한할 것을 고려하세요.
DeepAR 샘플 노트북
SageMaker AI DeepAR 알고리즘 훈련을 위한 시계열 데이터 세트를 준비하는 방법과 추론 수행을 위해 훈련된 모델을 배포하는 방법을 보여주는 샘플 노트북은 실제 데이터 세트에서 DeepAR의 고급 기능을 보여주는 전기 데이터 세트에 대한 DeepAR 데모
Amazon SageMaker AI DeepAR 알고리즘에 대한 자세한 내용은 다음 블로그 게시물을 참조하세요.
