기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
DeepAR 알고리즘 작동 방법
훈련 과정에서 DeepAR은 훈련 데이터세트 및 선택적 테스트 데이터세트를 수락합니다. 그리고 테스트 데이터세트를 사용하여 훈련받은 모델을 평가합니다. 일반적으로 데이터세트에는 동일한 시계열 집합이 포함될 필요가 없습니다. 주어진 훈련 세트에 대해 훈련된 모델을 사용하여 훈련 세트에서 미래의 시계열 및 기타 시계열에 대한 예상을 생성할 수 있습니다. 훈련 및 테스트 데이터세트는 모두 하나 또는 바람직하게는 그 이상의 대상 시계열로 구성됩니다. 각 대상 시계열은 선택적으로 요인(feature) 시계열의 벡터 및 범주 요인(feature)의 벡터와 선택적으로 연결할 수 있습니다. 자세한 내용은 DeepAR 알고리즘을 위한 입력/출력 인터페이스 섹션을 참조하세요.
예를 들어, 다음은 목표 시계열 Zi,t와 두 개의 관련 특징 시계열 Xi,1,t와 Xi,2,t 구성된 i로 인덱싱된 훈련 세트의 요소입니다.
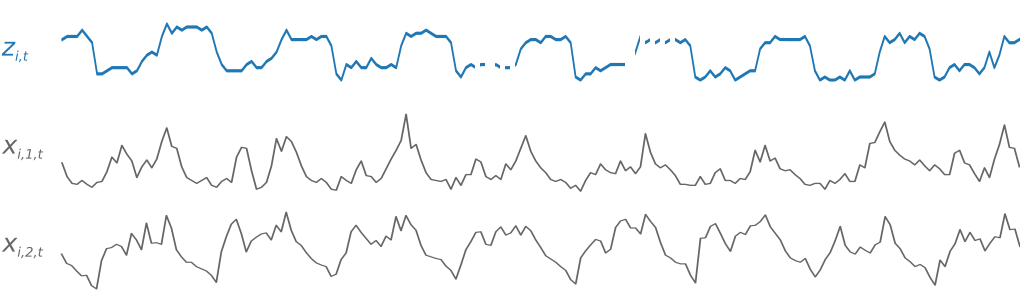
대상 시계열에 누락된 값이 있을 수 있습니다. 이러한 값은 시계열에서 선 끊김으로 표현됩니다. DeepAR은 미래에 알려지는 기능 시계열만 지원합니다. 따라서 "what if?"를 실행할 수 있습니다. 예: 제품의 가격을 어떤 식으로든 변경하면 어떻게 됩니까?
각 대상 시계열은 여러 가지 범주 요인(feature)과 연결될 수 있습니다. 이러한 요인(feature)을 사용하여 시계열이 속하는 그룹을 인코딩할 수 있습니다. 범주 요인(feature)을 사용하면 모델에서 그룹에 대한 일반적인 행동을 학습할 수 있으므로, 이를 통해 모델 정확성을 향상시킬 수 있습니다. DeepAR은 그룹의 모든 시계열의 공통 속성을 포착하는 각 그룹에 대한 임베딩 벡터를 학습하여 이를 구현합니다.
DeepAR 알고리즘에서 요인(feature) 시계열이 작동하는 방법
주말의 급증과 같이 시간에 따라 달라지는 패턴을 쉽게 학습할 수 있도록 DeepAR은 대상 시계열의 빈도를 기반으로 요인(feature) 시계열을 자동으로 생성합니다. 이 파생 요인(feature) 시계열을 훈련 및 추론 중에 제공하는 사용자 지정 요인(feature) 시계열과 함께 사용합니다. 다음 그림은 파생된 시계열 요인 중 두 가지를 보여주는데 ui,1,t는 시간을, ui,2,t는 요일을 나타냅니다.
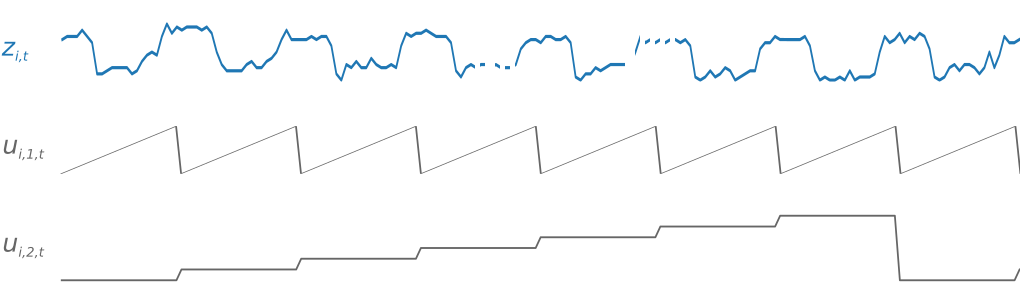
DeepAR 알고리즘은 이러한 요인(feature) 시계열을 자동으로 생성합니다. 다음 표에는 지원되는 기본 시간 빈도에 대한 파생 요인(feature)이 나열되어 있습니다.
| 시계열의 빈도 | 파생 요인(feature) |
|---|---|
Minute |
|
Hour |
|
Day |
|
Week |
|
Month |
month-of-year |
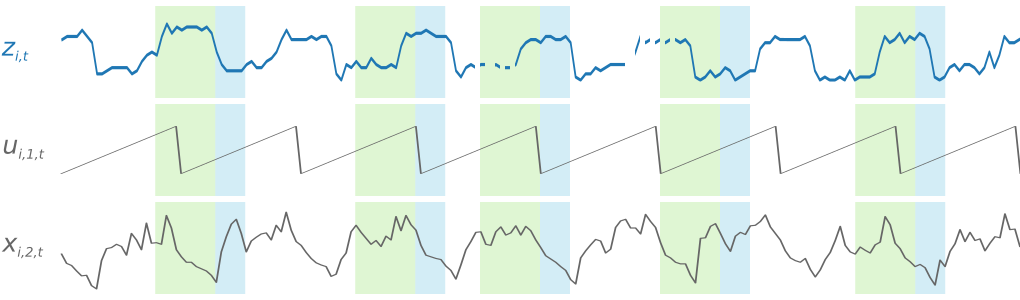
DeepAR은 훈련 데이터세트의 각 시계열에서 여러 훈련 예제를 무작위로 샘플링하여 모델을 훈련합니다. 각 훈련 예제는 미리 정의된 길이가 고정된 한 쌍의 인접 컨텍스트 및 예상 창으로 구성됩니다. context_length 하이퍼파라미터는 과거 네트워크에서 확인 가능한 거리를 제어하며, prediction_length 하이퍼파라미터는 향후 예상할 수 있는 범위를 제어합니다. 훈련 중 이 알고리즘은 지정된 예측 길이보다 짧은 시계열이 포함된 훈련 세트 요소를 무시합니다. 다음 그림은 i에서 얻은 12시간의 컨텍스트 길이와 6시간의 예측 길이를 갖는 5개의 샘플을 보여줍니다. 간략하게 설명하기 위해 요인 시계열 xi,1,t 및 ui,2,t는 생략했습니다.
계절성 패턴을 캡처하기 위해 DeepAR은 또한 대상 시계열에서 지연된 값을 자동으로 공급합니다. 시간 기준 빈도가 적용된 이 예제에서는 각 시간 인덱스 t = T에 대해 모델이 과거에 약 1, 2, 3일 동안 발생했던 zi,t 값을 노출합니다.
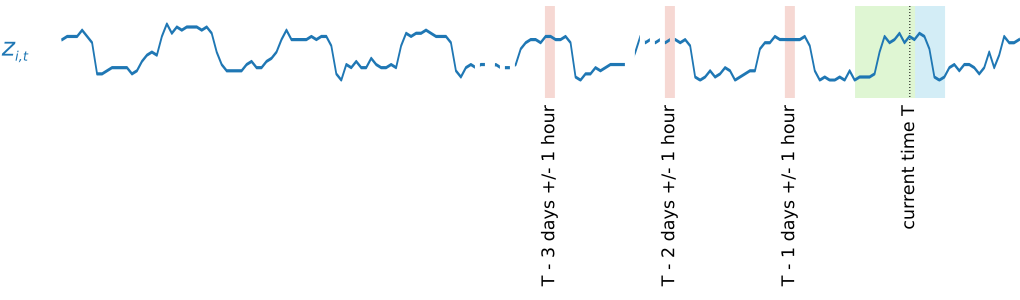
추론을 위해 훈련된 모델은 훈련 중에 사용되었을 수도 있고 사용되지 않았을 수도 있는 대상 시계열을 입력으로 받아 다음 prediction_length 값에 대한 확률 분포를 예상합니다. DeepAR이 전체 데이터세트에 대해 훈련받았기 때문에 이 예상에는 비슷한 시계열의 학습 패턴이 고려됩니다.
DeepAR의 수학적 계산에 대한 자세한 정보는 DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks
