기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
중복성이 있는 가용성
워크로드가 여러 독립적이고 중복된 하위 시스템을 사용하는 경우 단일 하위 시스템을 사용하는 경우보다 이론적으로 더 높은 수준의 가용성을 달성할 수 있습니다. 예를 들어 두 개의 동일한 하위 시스템으로 구성된 워크로드를 고려하세요. 하위 시스템 1이나 하위 시스템 2가 작동 중이면 완전히 작동할 수 있습니다. 전체 시스템이 다운되려면 두 하위 시스템이 동시에 다운되어야 합니다.
한 하위 시스템의 고장 확률이 1 - α인 경우 두 개의 중복 하위 시스템이 동시에 다운될 확률은 각 하위 시스템의 고장 확률의 곱, F = (1−α1) × (1− α2)입니다. 두 개의 중복 하위 시스템이 있는 워크로드의 경우 방정식 (3)을 사용하면 다음과 같이 정의된 가용성이 제공됩니다.
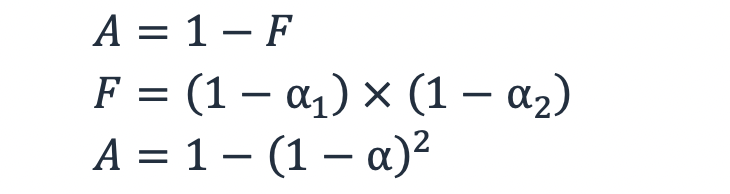
방정식 5
따라서 가용성이 99%인 두 하위 시스템의 경우 한 하위 시스템에 고장이 발생할 확률은 1%이고 둘 다 고장 날 확률은 (1-99%) × (1-99%) = 0.01%입니다. 따라서 두 개의 중복 하위 시스템을 사용할 경우 가용성이 99.99% 향상됩니다.
이를 일반화하여 추가 중복 스페어, s,도 통합할 수 있습니다. 수식 (5)에서는 스페어를 하나만 가정했지만, 워크로드에는 스페어가 2개, 3개 또는 그 이상 있을 수 있으므로 여러 하위 시스템이 동시에 손실되어도 가용성에 영향을 주지 않고 버틸 수 있습니다. 워크로드에 세 개의 하위 시스템이 있고 두 개가 스페어 시스템인 경우 세 개의 하위 시스템이 모두 동시에 실패할 확률은 (1−α) × (1−α) × (1−α) or (1−α)3입니다. 일반적으로 s개의 스페어가 있는 워크로드는 s + 1개의 하위 시스템에 고장이 발생하는 경우에만 고장 납니다.
n개의 하위 시스템과 s개의 스페어가 있는 워크로드의 경우 f는 고장 모드의 수 또는 s + 1개의 하위 시스템이 n개 중 고장을 일으킬 수 있는 방법을 나타냅니다.
이것은 사실상 이항 정리로, n개의 집합에서 k개의 요소를 선택하거나 “n은 k를 선택한다”는 조합 수학입니다. 이 경우 k는 s + 1입니다.
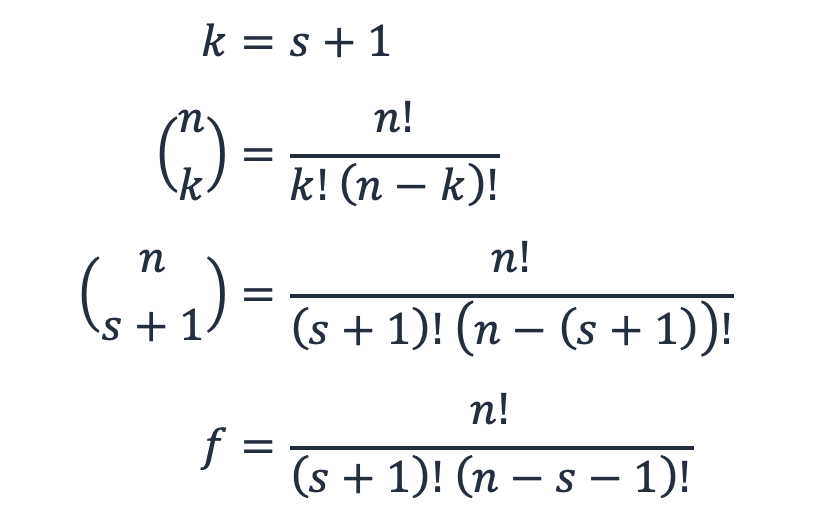
방정식 6
그런 다음 고장 모드와 스페어링 수를 포함하는 일반화된 가용성 근사치를 산출할 수 있습니다. (근사치로 이러한 이유를 이해하려면 Highleyman 등의 부록 2를 참조하세요. 가용성 장벽을 허물다
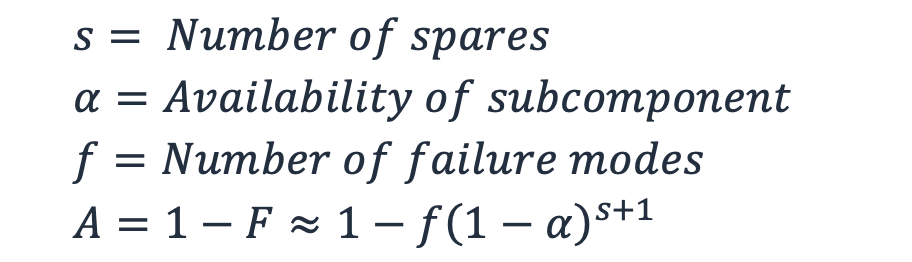
방정식 7
스페어링은 독립적으로 고장이 발생하는 리소스를 제공하는 모든 종속성에 적용할 수 있습니다. 그 예로는 여러 AZ에 있는 Amazon EC2 인스턴스, 다른 AWS 리전에 있는 Amazon S3 버킷이 포함됩니다. 스페어를 사용하면 종속 항목이 총 가용성을 높여 워크로드의 가용성 목표를 지원하는 데 도움이 됩니다.
규칙 5
스페어링을 사용하여 워크로드의 종속성 가용성을 높이세요.
하지만 스페어링에는 대가가 따릅니다. 예비 부품을 추가할 때마다 원래 모듈과 비용이 동일하므로 비용이 최소한 선형적으로 늘어납니다. 스페어를 사용할 수 있는 워크로드를 구축하면 복잡성도 증가합니다. 종속성 고장을 식별하고, 적절한 리소스로 작업량을 줄이고, 워크로드의 전체 용량을 관리하는 방법을 알아야 합니다.
중복성은 최적화 문제입니다. 스페어가 너무 적으면 워크로드가 원하는 것보다 더 자주 고장 나고, 스페어가 너무 많으면 워크로드 실행 비용이 너무 많이 들 수 있습니다. 스페어를 더 추가할 경우 보증된 추가 가용성보다 비용이 더 많이 드는 임계값이 있습니다.
스페어 사용 일반 가용성 공식인 수식 (7) 을 사용하면 가용성이 99.5% 이고 스페어가 두 개 있는 서브시스템의 경우 워크로드 가용성은 A ≈ 1 − (1)(1−.995)3 = 99.9999875%(연간 약 3.94초의 가동 중지)고, 스페어 10개를 사용할 경우 A ≈ 1 − (1)(1−.995)11 = 25.5 9′s가 됩니다(대략적인 가동 중지는 연간 1.26252 × 10-15ms이며, 사실상 0입니다). 이 두 워크로드를 비교한 결과 스페어링 비용이 5배 증가하여 연간 가동 중지를 4초 줄였습니다. 대부분의 워크로드에서 이러한 비용 증가는 가용성 증가에 비해 부당합니다. 다음 그림은 이 관계를 보여줍니다.
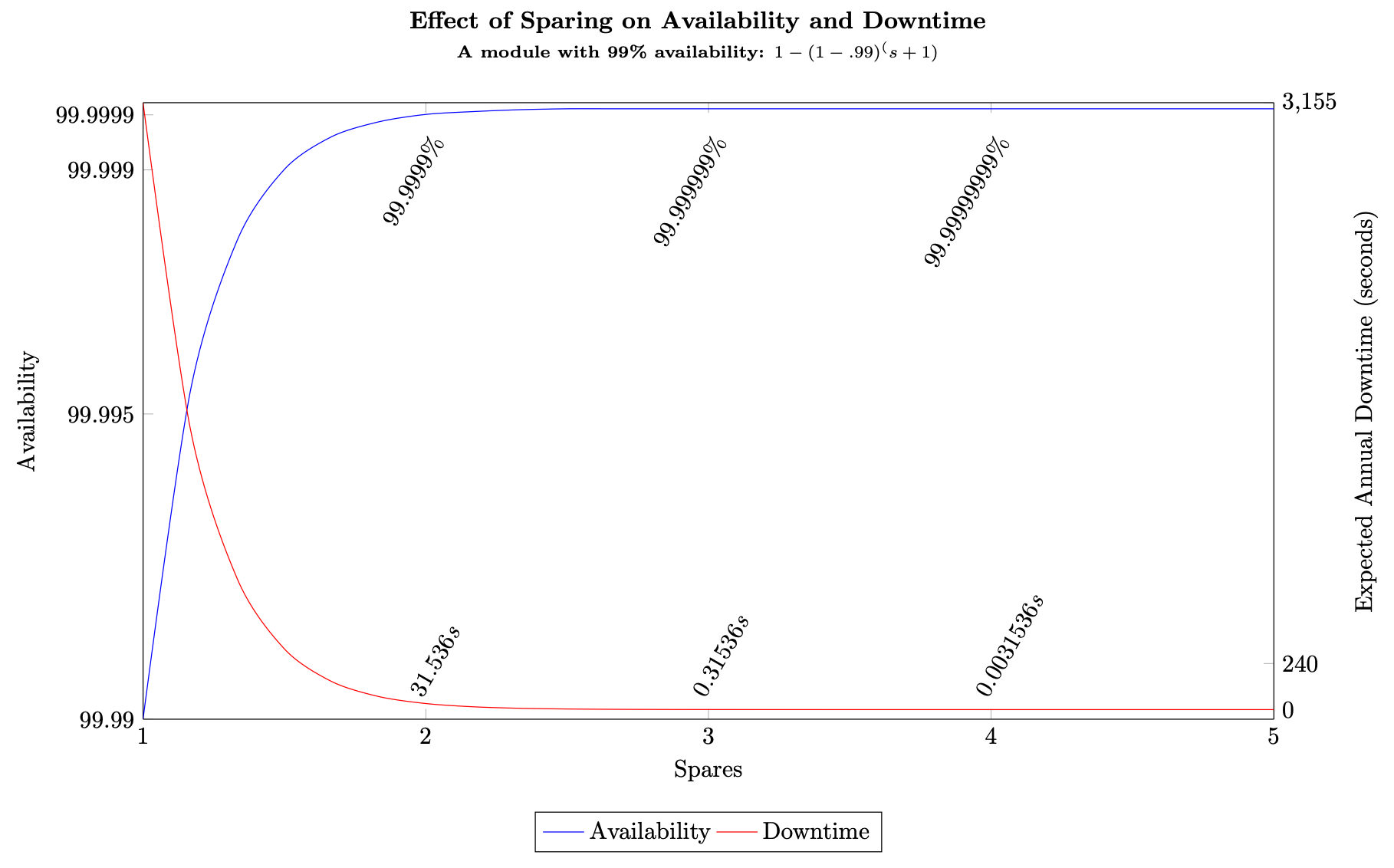
스페어링 증가로 인한 수익 감소
예비 부품이 3개 이상이면 연간 예상 가동 중지 시간의 1분의 1분의 1에 불과합니다. 즉, 이 시점 이후에는 수익이 감소하는 영역에 도달하게 됩니다. 더 높은 수준의 가용성을 달성하기 위해 “그냥 추가하고 싶다”는 충동이 들 수도 있지만 실제로는 비용상의 이점이 매우 빠르게 사라집니다. 예비 부품을 3개 이상 사용한다고 해서 실질적인 효과를 얻을 수 있는 것은 아닙니다. 하위 시스템 자체의 가용성이 99% 이상이면 거의 모든 워크로드에서 눈에 띄는 이득을 얻을 수 있습니다.
규칙 6
스페어링의 비용 효율성에는 상한선이 있습니다. 필요한 가용성을 달성하는 데 필요한 최소한의 스페어를 활용하세요.
올바른 스페어 수를 선택할 때는 고장 단위를 고려해야 합니다. 예를 들어, 최대 용량을 처리하기 위해 EC2 인스턴스 10개가 필요하고 단일 AZ에 배포된 워크로드를 살펴보겠습니다.
AZ는 고장 격리 경계를 설정하도록 설계되었으므로 단일 EC2 인스턴스에만 고장이 발생하는 것은 아닙니다. AZ 전체에 해당하는 EC2 인스턴스가 함께 고장이 발생할 수 있기 때문입니다. 이 경우 다른 AZ와 중복성을 추가하여 AZ 고장 발생 시 부하를 처리할 EC2 인스턴스 10개를 추가로 배포하여 총 20개의 EC2 인스턴스(정적 안정성 패턴 적용)를 구축하는 것이 좋습니다.
이는 10개의 예비 EC2 인스턴스인 것처럼 보이지만 실제로는 단일 스페어 AZ에 불과하므로 수익이 감소하는 지점을 넘지 않았습니다. 하지만 AZ를 3개 활용하고 AZ당 EC2 인스턴스 5개를 배포하면 가용성을 높이는 동시에 비용 효율성을 높일 수 있습니다.
이렇게 하면 1개의 스페어 AZ에 총 15개의 EC2 인스턴스가 제공되지만(20개의 인스턴스가 있는 두 개의 AZ에 비해), 단일 AZ에 영향을 미치는 이벤트 발생 시 최대 용량을 제공하는 데 필요한 총 10개의 인스턴스가 계속 제공됩니다. 따라서 워크로드가 사용하는 모든 장애 격리 경계(인스턴스, 셀, AZ, 지역)에서 내결함성을 갖추도록 스페어링을 구축해야 합니다.
