분산 시스템 가용성
분산 시스템은 소프트웨어 구성 요소와 하드웨어 구성 요소로 구성됩니다. 일부 소프트웨어 구성 요소는 그 자체가 또 다른 분산 시스템일 수 있습니다. 기본 하드웨어와 소프트웨어 구성 요소 모두의 가용성은 결과적으로 워크로드의 가용성에 영향을 미칩니다.
MTBF와 MTTR을 사용한 가용성 계산은 하드웨어 시스템에 그 뿌리를 두고 있습니다. 하지만 분산 시스템이 실패하는 이유는 하드웨어와는 매우 다릅니다. 제조업체가 하드웨어 구성 요소가 마모되기까지 걸리는 평균 시간을 일관되게 계산할 수 있는 경우 분산 시스템의 소프트웨어 구성 요소에는 동일한 테스트를 적용할 수 없습니다. 하드웨어는 일반적으로 고장률의 “욕조” 곡선을 따르는 반면, 소프트웨어는 새 릴리즈마다 발생하는 추가 결함으로 인해 생기는 엇갈린 곡선을 따릅니다(소프트웨어 신뢰성
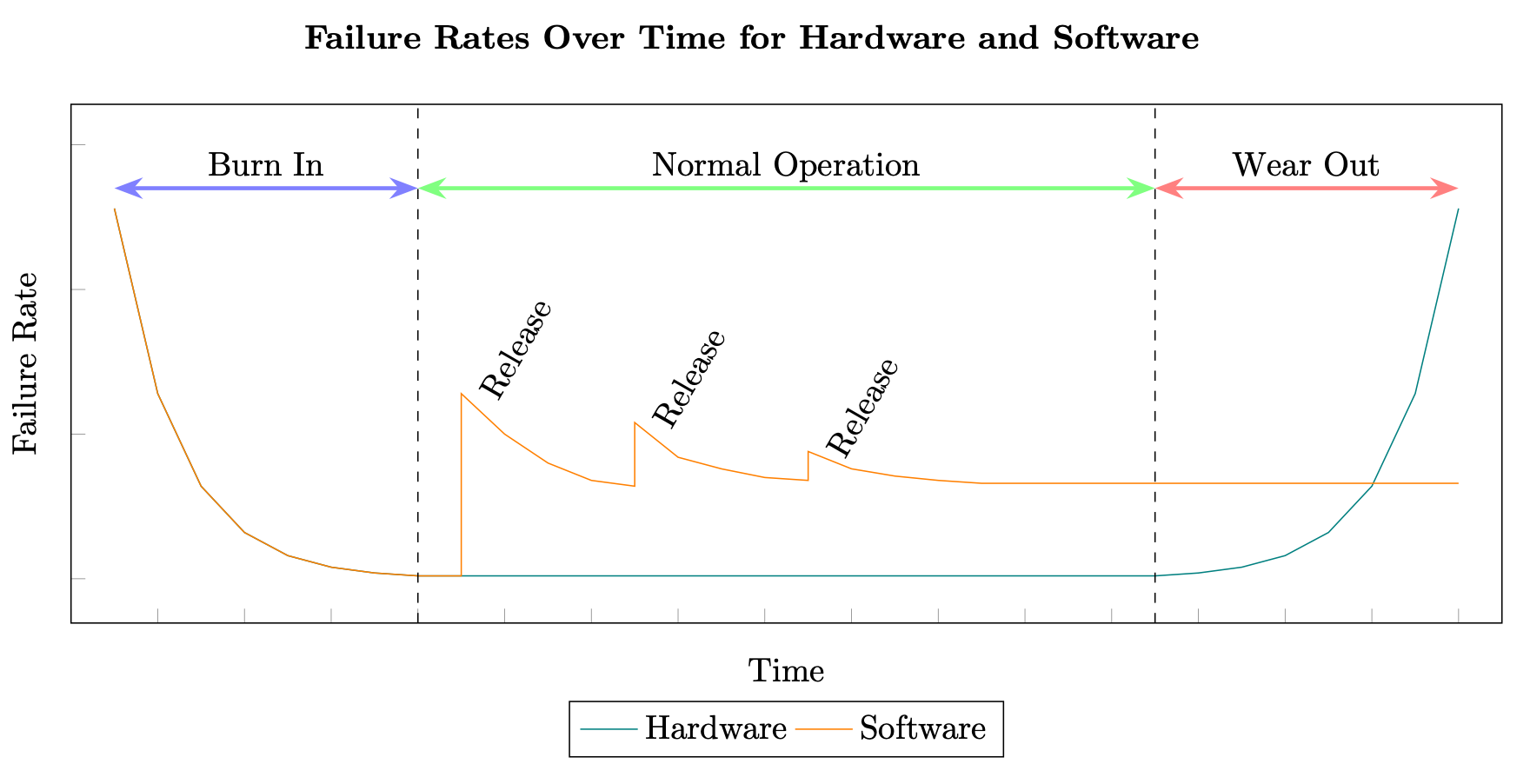
하드웨어 및 소프트웨어 고장률
또한 분산 시스템의 소프트웨어는 일반적으로 하드웨어보다 기하급수적으로 높은 속도로 변경됩니다. 예를 들어, 표준 마그네틱 하드 드라이브의 연간 평균 고장률(AFR)은 0.93%일 수 있으며, 이는 HDD의 실제 수명이 마모 기간에 도달하기까지 최소 3~5년이 걸릴 수 있으며, 이는 더 길어질 수 있습니다(Backblaze 하드 드라이브 데이터 및 통계, 2020 참조).
또한 하드웨어에는 계획된 노후화 개념이 적용됩니다. 즉, 수명이 내장되어 있으며 일정 기간이 지나면 교체해야 합니다. (위대한 전구 음모 참조)
즉, 하드웨어에서 MTBF 및 MTTR 번호를 생성하는 데 사용하는 것과 동일한 테스트 및 예측 모델이 소프트웨어에는 적용되지 않습니다. 1970년대 이후 이 문제를 해결하기 위해 모델을 구축하려는 시도가 수백 번 있었지만, 모두 일반적으로 예측 모델링과 추정 모델링이라는 두 가지 범주로 나뉩니다. (소프트웨어 신뢰성 모델 목록
따라서 분산 시스템에 대한 미래 예측 MTBF 및 MTTR 계산, 따라서 미래 예측 가용성은 항상 특정 유형의 예측 또는 예보에서 도출됩니다. 예측 모델링, 확률적 시뮬레이션, 과거 분석 또는 엄격한 테스트를 통해 생성될 수 있지만 이러한 계산이 가동 시간이나 가동 중지 시간을 보장하지는 않습니다.
과거에 분산 시스템이 고장 났던 이유는 다시 발생하지 않을 수 있습니다. 미래에 고장 나는 이유는 다를 수 있으며 아마도 알 수 없을 것입니다. 향후 고장 발생 시 필요한 복구 메커니즘은 과거에 사용된 메커니즘과 다를 수 있으며 소요 시간도 크게 다를 수 있습니다.
또한 MTBF와 MTTR은 평균값입니다. 평균값과 실제 값 사이에 약간의 차이가 있을 수 있습니다(이 변동을 측정한 표준 편차 γ는 이 변동을 측정합니다). 따라서 실제 프로덕션 사용에서는 워크로드에 고장이 발생한 후 복구 시간이 걸리는 시간이 짧거나 길어질 수 있습니다.
그렇긴 하지만 분산 시스템을 구성하는 소프트웨어 구성 요소의 가용성은 여전히 중요합니다. 소프트웨어는 여러 가지 이유로 장애가 발생할 수 있으며(다음 항목에서 자세히 설명) 워크로드의 가용성에 영향을 미칠 수 있습니다. 따라서 가용성이 높은 분산 시스템의 경우 하드웨어 및 외부 소프트웨어 하위 시스템과 마찬가지로 소프트웨어 구성 요소의 가용성을 계산, 측정 및 개선하는 데 중점을 두어야 합니다.
규칙 2
워크로드의 소프트웨어 가용성은 워크로드의 전체 가용성을 결정하는 중요한 요소이므로 다른 구성 요소와 마찬가지로 중점을 두어야 합니다.
분산 시스템에서 MTBF와 MTTR은 예측하기 어렵지만 여전히 가용성 개선 방법에 대한 주요 통찰력을 제공한다는 점에 유의해야 합니다. 고장 빈도를 줄이면(MTBF가 높음), 고장 발생 후 복구 시간을 줄이면(MTTR이 낮아짐) 모두 경험적 가용성을 높일 수 있습니다.
분산 시스템의 고장 유형
분산 시스템에는 일반적으로 보어버그와 하이젠버그라는 애칭으로 불리는 두 종류의 버그가 있습니다(“브루스 린지와의 대화”, ACM Queue vol. 2, No. 8 - 2004년 11월
보어버그는 반복해서 작동하는 소프트웨어 문제입니다. 동일한 입력이 주어지면 버그는 일관되게 동일한 잘못된 출력을 생성합니다(예: 확실하고 쉽게 감지할 수 있는 결정론적 보어 원자 모델). 워크로드가 프로덕션에 들어갈 때쯤이면 이런 유형의 버그는 거의 발생하지 않습니다.
하이젠버그는 일시적인 버그입니다. 즉, 특정하고 흔하지 않은 상황에서만 발생합니다. 이러한 조건은 일반적으로 하드웨어(예: 일시적인 장치 장애 또는 레지스터 크기와 같은 하드웨어 구현 세부 사항), 컴파일러 최적화 및 언어 구현, 제한 조건(예: 일시적으로 스토리지 부족) 또는 경쟁 조건(예: 다중 스레드 작업에 세마포어를 사용하지 않음)와 관련이 있습니다.
하이젠버그는 프로덕션 환경에서 발생하는 버그의 대부분을 차지하며 관찰하거나 디버깅하려고 할 때 동작이 바뀌거나 사라지는 것처럼 보이기 때문에 찾기가 어렵습니다. 그러나 프로그램을 다시 시작하면 운영 환경이 약간 달라서 하이젠버그를 발생시킨 조건이 사라지기 때문에 고장 난 작업이 성공할 가능성이 높습니다.
따라서 대부분의 프로덕션 실패는 일시적이며 작업을 다시 시도해도 다시 고장 날 가능성은 거의 없습니다. 복원력을 갖추려면 분산 시스템이 하이젠버그에 대한 내결함성을 갖추어야 합니다. 분산 시스템 MTBF 늘리기 항목에서 이를 실현하는 방법을 살펴보겠습니다.
