기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
필터 표현식 사용
필터 표현식을 사용하여 특정 요청, 서비스, 두 서비스 간의 연결(엣지) 또는 조건을 만족하는 요청에 대해 트레이스 맵 또는 트레이스를 표시할 수 있습니다. X-Ray는 요청 헤더, 응답 상태 및 원래 세그먼트의 인덱싱된 필드에 포함된 데이터를 기반으로 요청, 서비스 및 엣지를 필터링하는 필터 표현식 언어를 제공합니다.
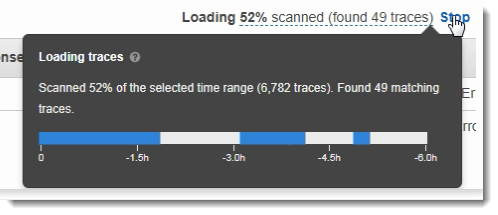
X-Ray 콘솔에서 볼 트레이스의 기간을 선택할 때 콘솔에서 표시할 수 있는 결과보다 더 많은 결과를 얻을 수 있습니다. 우측 상단 모서리에서 콘솔은 스캔한 트레이스의 수 및 사용 가능한 트레이스가 더 있는지를 표시합니다. 필터 표현식을 사용하면 찾고자 하는 트레이스로 결과 범위를 좁힐 수 있습니다.
필터 표현식 세부 정보
트레이스 맵에서 노드를 선택하면 콘솔이 해당 노드의 서비스 이름 및 사용자의 선택에 따라 다르게 나타나는 오류 유형을 기반으로 필터 표현식을 생성합니다. 성능 문제를 표시하거나 특정 요청과 관련된 트레이스를 찾으려면 콘솔에서 제공하는 표현식을 조정하거나 자체적으로 표현식을 생성합니다. X-Ray SDK로 주석을 추가하는 경우 주석 키의 존재 또는 키 값을 기준으로 필터링할 수도 있습니다.
참고
트레이스 맵에서 상대적 시간 범위를 선택하고 노드를 선택하면 콘솔에서 시간 범위를 절대 시작 및 종료 시간으로 변환합니다. 노드에 대한 트레이스가 검색 결과에 나타나도록 하고 노드가 활성 상태가 아닐 때 시간을 스캔하지 않도록 하기 위해 시간 범위에 노드가 트레이스를 보냈을 때 시간만 포함됩니다. 현재 시간에 상대적으로 검색하려는 경우 트레이스 페이지의 상대적 시간 범위로 다시 전환한 후 다시 스캔할 수 있습니다.
콘솔에서 표시할 수 있는 것보다 더 많은 결과가 계속 제공되는 경우 콘솔에서 일치한 트레이스 수와 스캔한 트레이스 수를 표시합니다. 표시된 백분율은 스캔한 선택된 시간 프레임의 백분율입니다. 결과에 나타난 일치하는 트레이스를 모두 보려면 필터 표현식의 범위를 더 좁히거나 보다 짧은 시간 범위를 선택합니다.
가장 최근 결과를 먼저 얻으려면 콘솔이 시간 범위의 끝에서 스캔을 시작하고 역방향으로 진행합니다. 트레이스 개수가 매우 많은데 결과가 거의 없는 경우 콘솔은 시간 범위를 청크로 분할하고 해당 청크를 병렬로 스캔합니다. 진행률 표시줄에서 스캔한 시간 범위 부분을 표시합니다.
그룹에 필터 표현식 사용
그룹은 필터 표현식으로 정의한 추적 모음입니다. 그룹을 사용하여 추가 서비스 그래프를 작성하여 Amazon CloudWatch 지표를 공급할 수 있습니다.
그룹은 이름 또는 Amazon 리소스 이름(ARN)으로 식별되며 필터 표현식을 포함합니다. 이 서비스는 수신 트레이스를 표현식과 비교하여 그에 따라 저장합니다.
필터 표현식 검색 창 왼쪽에 있는 드롭다운 메뉴를 사용하여 그룹을 생성하고 수정할 수 있습니다.
참고
서비스가 그룹을 규정하는 데 오류가 발생하면 해당 그룹은 더 이상 수신 트레이스 처리에 포함되지 않으며 오류 지표가 기록됩니다.
그룹에 대한 자세한 정보는 그룹 구성 섹션을 참조하세요.
필터 표현식 구문
필터 표현식은 키워드, 유너리 또는 바이너리 연산자, 비교를 위한 값을 포함할 수 있습니다.
keyword operator value다양한 유형의 키워드에 대해 다양한 연산자를 사용할 수 있습니다. 예를 들어 responsetime은 숫자 키워드이며 숫자와 관련된 연산자를 사용하여 비교할 수 있습니다.
예 – 응답 시간이 5초를 초과한 요청
responsetime > 5AND 및 OR 연산자를 사용하여 여러 표현식을 하나의 복합 표현식으로 결합할 수 있습니다.
예 – 총 기간이 5~8초인 요청
duration >= 5 AND duration <= 8단순한 키워드 및 연산자를 사용하면 트레이스 수준에서만 문제가 발견됩니다. 오류가 다운스트림에서 발생하지만 애플리케이션에 의해 처리되고 사용자에게 반환되지 않는 경우 error 검색에서는 발견되지 않습니다.
다운스트림 문제가 있는 트레이스를 찾기 위해 복합 키워드 service()와 edge()를 사용할 수 있습니다. 이러한 키워드를 사용하면 필터 표현식을 모든 다운스트림 노드, 단일 다운스트림 노드 또는 두 노드 간 에지에 적용할 수 있습니다. 더욱 세분화하려면 id() 함수를 사용하여 서비스와 엣지를 필터링할 수 있습니다.
부울 키워드
부울 키워드 값은 true 또는 false입니다. 오류가 발생한 트레이스를 찾으려면 이 키워드를 사용합니다.
부울 키워드
-
ok– 응답 상태 코드가 2XX Success. -
error– 응답 상태 코드가 4XX Client Error. -
throttle– 응답 상태 코드가 429 요청 과다. -
fault– 응답 상태 코드가 5XX Server Error. -
partial– 요청에 완료되지 않은 세그먼트가 있음. -
inferred– 요청에 추론된 세그먼트가 있음 -
first– 요소가 열거된 목록의 첫 번째임 -
last– 요소가 열거된 목록의 마지막임 -
remote– 근본 원인 개체가 원격임 -
root– 서비스가 트레이스의 진입점 또는 루트 세그먼트임
부울 연산자는 지정된 키가 true 또는 false인 세그먼트를 찾습니다.
부울 연산
-
none – 키워드가 true이면 표현식이 true입니다.
-
!– 키워드가 false이면 표현식이 true입니다. -
=,!=– 키워드의 값을 문자열true또는false와 비교합니다. 이러한 연산자는 다른 연산자와 동일하게 작동하지만 보다 명시적입니다.
예 – 응답 상태가 2XX OK
ok예 – 응답 상태가 2XX OK가 아님
!ok예 – 응답 상태가 2XX OK가 아님
ok = false예 – 마지막에 열거된 결함 트레이스의 오류 이름이 “deserialize”임
rootcause.fault.entity { last and name = "deserialize" }예 – 범위가 0.7보다 크고 서비스 이름이 “traces"인 원격 세그먼트가 포함된 요청
rootcause.responsetime.entity { remote and coverage > 0.7 and name = "traces" }예 – 서비스 유형이 "AWS:DynamonDB"인 추론 세그먼트가 포함된 요청
rootcause.fault.service { inferred and name = traces and type = "AWS::DynamoDB" }예 – 이름이 “data-plane”인 세그먼트가 루트로 포함된 요청
service("data-plane") {root = true and fault = true}숫자 키워드
숫자 키워드를 사용하면 특정 응답 시간, 기간 또는 응답 상태를 갖는 요청을 찾을 수 있습니다.
숫자 키워드
-
responsetime– 서버가 응답을 전송하는 데 걸린 시간. -
duration– 모든 다운스트림 호출을 포함한 총 요청 기간입니다. -
http.status– 응답 상태 코드. -
index– 열거 목록에서 요소의 위치 -
coverage– 루트 세그먼트 응답 시간 경과에 따른 개체 응답 시간의 십진 비율 응답 시간 근본 원인 개체일 때만 사용 가능합니다.
숫자 연산자
숫자 키워드는 표준 등식 및 비교 연산자를 사용합니다.
-
=,!=– 이 키워드는 숫자값과 같음 또는 같지 않음입니다. -
<,<=,>,>=– 이 키워드는 숫자값보다 작음 또는 큼입니다.
예 – 응답 상태가 200 OK가 아님
http.status != 200예 – 총 기간이 5~8초인 요청
duration >= 5 AND duration <= 8예 – 모든 다운스트림 호출을 포함하여 3초 이내에 성공적으로 완료된 요청
ok !partial duration <3예 – 5보다 큰 인덱스가 포함된 열거된 목록 개체
rootcause.fault.service { index > 5 }예 – 0.8보다 큰 범위가 포함된 마지막 개체인 요청
rootcause.responsetime.entity { last and coverage > 0.8 }문자열 키워드
문자열 키워드를 사용하면 요청 헤더 또는 특정 사용자 ID에 특정 텍스트가 포함된 트레이스를 찾을 수 있습니다.
문자열 키워드
-
http.url– 요청 URL. -
http.method– 요청 메서드. -
http.useragent– 요청 사용자 에이전트 문자열. -
http.clientip– 요청자 IP 주소. -
user– 트레이스 내 세그먼트의 사용자 필드 값. -
name– 서비스 또는 예외 이름 -
type– 서비스 유형 -
message– 예외 메시지 -
availabilityzone– 트레이스 내 세그먼트의 availabilityzone 필드 값 -
instance.id– 트레이스 내 세그먼트의 인스턴스 ID 필드 값 -
resource.arn– 트레이스 내 세그먼트의 리소스 ARN 필드 값
문자열 연산자는 특정 텍스트와 같거나 이를 포함하는 값을 찾습니다. 값은 항상 인용 부호를 사용하여 지정해야 합니다.
문자열 연산자
-
=,!=– 이 키워드는 숫자값과 같음 또는 같지 않음입니다. -
CONTAINS– 이 키워드는 특정 문자열을 포함합니다. -
BEGINSWITH,ENDSWITH– 이 키워드는 특정 문자열로 시작하거나 끝납니다.
예 – http.url 필터
http.url CONTAINS "/api/game/"트레이스에서 값과 상관없이 특정 필드가 존재하는지 테스트하려면 필드가 빈 문자열을 포함하는지 확인합니다.
예 – 사용자 필터
사용자 ID가 있는 모든 트레이스를 찾습니다.
user CONTAINS ""예 – “Auth”라는 이름의 서비스가 포함된 결함 근본 원인이 있는 트레이스를 선택합니다.
rootcause.fault.service { name = "Auth" }예 – 마지막 서비스에 DynamoDB 유형이 포함된 응답 시간 근본 원인이 있는 트레이스를 선택합니다.
rootcause.responsetime.service { last and type = "AWS::DynamoDB" }예 – 마지막 예외에 "access denied for account_id: 1234567890" 메시지가 포함된 결함 근본 원인이 있는 추적을 선택합니다.
rootcause.fault.exception { last and message = "Access Denied for account_id: 1234567890" 복합 키워드
복합 키워드를 사용하여 서비스 이름, 엣지 이름 또는 주석 값을 기준으로 요청을 찾을 수 있습니다. 서비스 및 엣지의 경우 서비스 또는 엣지에 적용되는 추가 필터 표현식을 지정할 수 있습니다. 주석의 경우 부울, 숫자 또는 문자열 연산자를 사용하여 특정 키로 주석 값을 필터링할 수 있습니다.
복합 키워드
-
annotation[–key]key필드가 있는 주석의 값. 주석 값은 부울, 숫자 또는 문자열일 수 있으므로 이러한 유형의 비교 연산자를 모두 사용할 수 있습니다. 이 키워드는service또는edge키워드와 함께 사용할 수 있습니다. 점(마침표)이 포함된 주석 키는 대괄호([ ])로 묶어야 합니다. -
edge(–source,destination) {filter}source서비스와destination서비스 사이를 연결합니다. 선택적으로, 이 연결의 세그먼트에 적용되는 필터 표현식을 중괄호로 묶을 수 있습니다. -
group.– 그룹 이름 또는 그룹 ARN으로 참조되는 그룹의 필터 표현식 값입니다.name/ group.arn -
json– JSON 근본 원인 객체. 프로그래밍 방식으로 JSON 개체를 생성하는 단계는 AWS X-Ray에서 데이터 가져오기를 참조하세요. -
service(– 이름이name) {filter}name인 서비스. 선택적으로, 서비스에서 생성하는 세그먼트에 적용되는 필터 표현식을 중괄호로 묶을 수 있습니다.
트레이스 맵에서 특정 노드에 도달한 요청의 트레이스를 찾으려면 서비스 키워드를 사용합니다.
복합 키워드 연산자는 지정된 키가 설정되었거나 설정되지 않은 세그먼트를 찾습니다.
복합 키워드 연산자
-
none – 키워드가 설정된 경우 표현식이 true입니다. 키워드가 부울 유형인 경우 부울 값으로 평가됩니다.
-
!– 키워드가 설정되지 않은 경우 표현식이 true입니다. 키워드가 부울 유형인 경우 부울 값으로 평가됩니다. -
=,!=- 키워드의 값을 비교합니다. -
edge(–source,destination) {filter}source서비스와destination서비스 사이를 연결합니다. 선택적으로, 이 연결의 세그먼트에 적용되는 필터 표현식을 중괄호로 묶을 수 있습니다. -
annotation[–key]key필드가 있는 주석의 값. 주석 값은 부울, 숫자 또는 문자열일 수 있으므로 이러한 유형의 비교 연산자를 모두 사용할 수 있습니다. 이 키워드는service또는edge키워드와 함께 사용할 수 있습니다. -
json– JSON 근본 원인 객체. 프로그래밍 방식으로 JSON 개체를 생성하는 단계는 AWS X-Ray에서 데이터 가져오기를 참조하세요.
트레이스 맵에서 특정 노드에 도달한 요청의 트레이스를 찾으려면 서비스 키워드를 사용합니다.
예 – 서비스 필터
api.example.com 호출을 포함하고 오류(500 시리즈 오류)가 발생한 요청
service("api.example.com") { fault }서비스 이름을 제외하여 필터 표현식을 서비스 맵의 모든 노드에 적용할 수 있습니다.
예 – 서비스 필터
트레이스 맵의 어느 곳에서든 오류를 일으킨 요청입니다.
service() { fault }에지 키워드는 필터 표현식을 두 노드 간 연결에 적용합니다.
예 – 엣지 필터
api.example.com 서비스가 backend.example.com을 호출했으나 실패하고 오류가 발생한 요청
edge("api.example.com", "backend.example.com") { error }또한 서비스 및 에지 키워드와 함께 ! 연산자를 사용하여 다른 필터 표현식의 결과에서 서비스 또는 에지를 제외할 수 있습니다.
예 – 서비스 및 요청 필터
URL이 http://api.example.com/으로 시작하고 /v2/를 포함하지만 api.example.com 서비스에 연결되지 않는 요청
http.url BEGINSWITH "http://api.example.com/" AND http.url CONTAINS "/v2/" AND !service("api.example.com")예 – 서비스 및 응답 시간 필터
http url이 설정되어 있고 응답 시간이 2초보다 큰 트레이스를 찾습니다.
http.url AND responseTime > 2주석의 경우 annotation[가 설정된 모든 트레이스를 직접 호출하거나 값 유형에 해당하는 비교 연산자를 사용할 수 있습니다.key]
예 – 문자열 값을 포함하는 주석
문자열 값이 gameid인 "817DL6VO"라는 주석이 포함된 요청
annotation[gameid] = "817DL6VO"예 – 주석이 설정되었습니다.
age set이라는 주석이 포함된 요청.
annotation[age]예 – 주석이 설정되지 않았습니다.
age set이라는 주석이 없는 요청.
!annotation[age]예 – 숫자 값을 포함하는 주석
주석의 수명이 숫자 값 29보다 큰 요청
annotation[age] > 29예 – 서비스 또는 엣지와 조합한 주석
service { annotation[request.id] = "917DL6VO" }edge { source.annotation[request.id] = "916DL6VO" }edge { destination.annotation[request.id] = "918DL6VO" }예 – 사용자가 있는 그룹
트레이스가 high_response_time 그룹 필터(예:responseTime > 3)를 충족하고 사용자 이름이 Alice인 요청.
group.name = "high_response_time" AND user = "alice"예 – 근본 원인 개체가 포함된 JSON
일치하는 근본 원인 개체가 포함된 요청
rootcause.json = #[{ "Services": [ { "Name": "GetWeatherData", "EntityPath": [{ "Name": "GetWeatherData" }, { "Name": "get_temperature" } ] }, { "Name": "GetTemperature", "EntityPath": [ { "Name": "GetTemperature" } ] } ] }]id 함수
service 또는 edge 키워드에 서비스 이름을 제공하면 해당 이름의 모든 노드가 결과로 반환됩니다. 보다 세밀하게 필터링하려면 id 함수로 이름 외에 서비스 유형도 지정하여 이름이 같은 노드를 구별할 수 있습니다.
모니터링 계정에서 여러 계정의 트레이스를 볼 때 이 account.id 함수를 사용하여 서비스의 특정 계정을 지정합니다.
id(name: "service-name", type:"service::type", account.id:"account-ID")서비스 및 엣지 필터에 서비스 이름 대신 id 함수를 사용할 수 있습니다.
service(id(name: "service-name", type:"service::type")) { filter }edge(id(name: "service-one", type:"service::type"), id(name: "service-two", type:"service::type")) { filter }예를 들어 AWS Lambda 함수는 트레이스 맵에 두 개의 노드를 생성합니다. 하나는 함수 호출용이고 다른 하나는 Lambda 서비스용입니다. 두 노드는 이름이 같지만 유형이 다릅니다. 표준 서비스 필터는 두 노드 모두의 트레이스를 찾습니다.
예 – 서비스 필터
random-name이라는 서비스에 대한 오류를 포함하는 요청
service("random-name") { error }서비스로 인한 오류를 제외하고 함수 자체의 오류로 검색 범위를 좁히려면 id 함수를 사용합니다.
예 – id 함수를 사용한 서비스 필터
유형이 random-name인 AWS::Lambda::Function 서비스의 오류를 포함하는 요청
service(id(name: "random-name", type: "AWS::Lambda::Function")) { error }또한 이름을 완전히 제외하여 노드를 유형별로 검색할 수 있습니다.
예 – id 기능 및 서비스 유형을 포함하는 서비스 필터
유형이 AWS::Lambda::Function인 서비스의 오류를 포함하는 요청
service(id(type: "AWS::Lambda::Function")) { error }특정 노드를 검색하려면 계정 ID를 AWS 계정지정합니다.
예 – id 기능 및 계정 ID를 사용한 서비스 필터
특정 계정 ID AWS::Lambda::Function 내에 서비스를 포함하는 요청.
service(id(account.id: "account-id"))