Disaster recovery planning
Disaster recovery (DR) is a critical service for enterprise business continuity and compliance. AMS partners with you to help you plan, implement and maintain your DR strategy on AMS.
AMS landing zone (LZ), multi-account and single-account, provides native, multi-AZ, high-availability for AMS infrastructure components that meet most disaster protection scenarios. However, depending on your business's geographical coverage, you might need regional protection. For cross-region availability and DR, another AMS account is required in a different region (this is so for both multi-account landing zone and single-account landing zone).
AMS aligns with AWS DR guidance as described in this blog,
Rapidly recover mission-critical systems in a disaster
Multi Site (or Highly Available)
Warm Standby
Pilot Light
Backup and Restore
These options and AMS support for them are described in the following sections.
Multi-site or highly available (HA)
The HA solution is usually provided by the application's built-in functionality, such as clustering or synchronous replication. Users are directed to both Prod and HA/DR nodes. DNS points either to the nodes directly or through an elastic load balancer (ELB).
Your AMS cloud architect (CA) will work with you as part of your Well-Architected-Review and DR planning.
HA DR utilizes application and AWS-native services and features, as illustrated in the following graphic:

The DR site can be in the same or different AWS Region.
Note
Different region (Cross-Region) will have a different Active Directory environment.
DR (failover) steps: Automatic failover, no manual steps are required. In case of a failure in the primary LZ, the users will be automatically re-routed to the DR/HA node. This is achieved by both DNS and application configuration.
HA DR metrics:
Recovery Point Objective (RPO): <5 min
Recovery Time Objective and (RTO): <5 min
Maintenance: High (Synchronous changes are required in both environments, like Application configuration, patching, SG or ALB, certificates, and so on).
Cost: High
Warm standby
The term "warm standby" is used to describe a disaster recovery (DR) scenario in which a scaled-down version of the environment is running in the cloud.
Data replication is handled by the application layer, usually asynchronously, to an online instance, while the rest of the instances (for example, Application and Web tier) might be turned off to save the cost. Users are directed only to the Production site. Other AWS resources like elastic load balancer (ELB) may be pre-provisioned in the DR site as well.
Your AMS Cloud Architect (CA) will work with you as part of your Well-Architected-Review and DR planning.
Warm Standby DR utilizes application and AWS-native services and features, as illustrated in the following graphic:

DR site can be in the same or different AWS Region.
Note
Different region (Cross-Region) will have a different Active Directory environment.
DR (failover) steps:
Brake the data replication and make the data instance in the DR site the master
Update application configuration as required (new IP, server name, and so on)
Redirect DNS to the DR site (ELB)
AD Dependencies if required (Service accounts, SPNs, GPOs, and so on)
HA DR metrics:
Recovery Point Objective (RPO): <1hr
Recovery Time Objective and (RTO): <1 hr (depends on the number of instances and orchestration)
Maintenance: High (Synchronous changes are required in both environments, like Application configuration, patching, security groups (SG) or application load balancer (ALB), certificates, and so on).
Cost: Medium
Pilot light
In this disaster recovery (DR) approach, you replicate part of your Prod environment for a limited set of core services. A small part of your infrastructure is always running, simultaneously syncing mutable data (such as databases or documents), while other parts of your infrastructure are switched off and used only during testing. Unlike a backup and recovery approach, you must ensure that your most critical core elements are already configured and running in the DR landing zone (the pilot light).
Your AMS Cloud Architect will work with you as part of your Well-Architected-Review and DR planning.
Pilot Light DR utilizes application and AWS-native services and features, as illustrated in the following graphic:

DR site can be in the same or different AWS Region.
Note
Different region (Cross-Region) will have a different Active Directory environment.
DR (failover) steps:
Brake the data replication and make the data instance in the DR site the master
Start the turned off instances and infrastructure
Update application configuration as required (new IP, server name, and so on)
Add the instances to the ELB as required
Redirect DNS to the DR site (ELB)
AD Dependencies, if required (Service accounts, SPNs, GPOs, and so on)
Pilot Light DR metrics:
Recovery Point Objective (RPO): <1hr
Recovery Time Objective and (RTO): ~1 hr (depends on the number of instances and orchestration)
Maintenance: Medium
Cost: Medium
Backup and restore
This simple and low cost disaster recovery (DR) approach backs up your data and applications from anywhere to the DR landing zone for use during recovery from a disaster.
Your AMS Cloud Architect works with you as part of your Backup and DR planning.
Backup and Restore DR utilizes AMS automated tooling and processes, as illustrated in the following graphic:
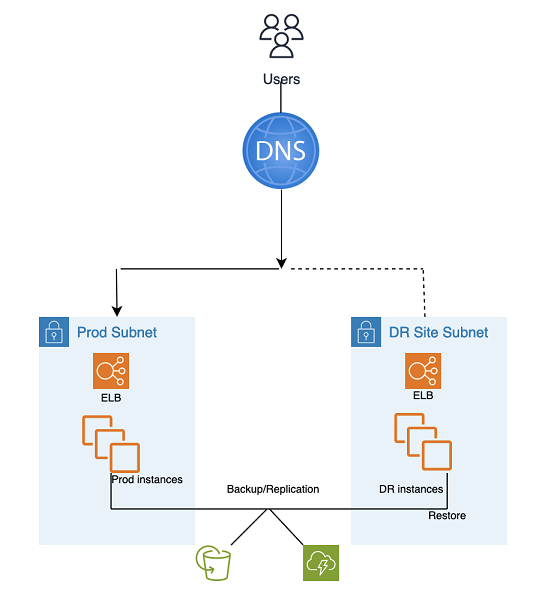
Two backup and replication methods can be used:
EBS snapshot (Recovery Point Objective (RPO) > 1hr), known as "EBS"
AWS Elastic Disaster Recovery (Recovery Point Objective (RPO) ~ 0.25hrs), known as "DRS"
The DR site can be in the same or in a different AWS Region.
Note
A different Region (Cross-Region) has a different Active Directory environment.
DR (failover) steps:
Restore the instances from snapshots (two-step process with placeholder instance first)
Update application configuration (new IP, server name,and so on)
Set up other infrastructure as required (SG, ELB, and so on)
Redirect DNS to the DR site (ELB)
Update or restore AD dependencies if required (service accounts, service principal names (SPNs), group policy objects (GPOs), and so on)
Backup and Restore DR metrics:
Recovery Point Objective (RPO): >1hr or ~0.25hrs (depends on the solution selected - EBS or DRE)
Recovery Time Objective and (RTO): ~1 hr (depends on the number of instances and orchestration)
Maintenance: High (Synchronous changes are required in both environments, like application configuration, patching, security groups or application load balancers, certificates, and so on.
Cost: Medium
Disaster protection for EC2 with EBS snapshots on AMS
Prerequisites:
AMS Prod Landing Zone (source)
AMS DR Landing Zone (DR target)
EBS snapshots are enabled for EC2 instances (AWS Backup)
Snapshot replication solution:
Cross AZ: Not applicable - EBS snapshot are highly available within the Region by design
Cross-Region: AWS Backup
The following diagram represents the EC2 restore process from EBS snapshots on AMS:

EC2 DR steps on AMS:
Raise an RFC to share the EBS snapshots with the target account (required for Cross-Region DR).
: Management, Advanced Stack Components, EBS Snapshot, Share
Create a placeholder EC2 AMS stack in the destination subnet (DR site subnet). The recommendation is to use CFN ingestion to create the stack as the customer can combine the steps of assigning security groups and other (like adding the instance to an ELB) in the same stack.
Change type: Deployment, Ingestion, Stack from CloudFormation Template, Create
Raise an RFC to perform EC2 stack volume restore.
Change type: Management, Advanced Stack Components, EC2 instance stack, Restore volumes.
The CT restores the volumes from the snapshots shared in step 1 and attaches to the placeholder instance created in step 2.
Volume Restore CT functionality:
Shut the placeholder instance down
Restore volumes from the snapshots
Swap out the volumes
Start the instance
Leave the old domain
Change the hostname
Reboot. AMS bootstrap scripts join the instance to the target (DR) domain upon start up
Volume restore CT input:
InstanceId (placeholder instance ID)
RootDeviceSnapshotId, the EBS snapshot for the restored root volume
KMSKeyId, the KMS key identifier, or ARN, to encrypt all restored volumes on the EC2 instance
DeviceNames, up to 25 (optional)
SnapshotIds, up to 25 (optional). List of snapshots of the volumes to be restored
Disaster protection for EC2 with Elastic Disaster Recovery on AMS
Prerequisites:
AMS Prod Landing Zone (source)
AMS DR Landing Zone (DR target)
You must first initialize the Elastic Disaster Recovery service for all AWS Regions that you plan to use it in.
Create an IAM role in your DR landing zone (LZ) for Elastic Disaster Recovery console access.
Important: An SSM Document is created as a Post Launch Action within DRS. This Action must be enabled on all your servers on the PostLaunch settings.
the destination (placeholder) instance must have a tag key: "AWSDRS", value: "AllowLaunchingIntoThisInstance". Placeholder instance must be in the stopped state. Otherwise, AMS can't select the placeholder instance under the launch settings and Elastic Disaster Recovery can't restore on top of the placeholder instance.
For a diagram of the Elastic Disaster Recovery setup and restore process for EC2 on AMS, see AWS Elastic Disaster Recovery (AWS DRS) general architecture.
EC2 DR steps with Elastic Disaster Recovery on AMS:
Create a placeholder EC2 AMS stack in the destination subnet (DR site subnet) with proper tags, for more information, see the previous section. We recommend using CFN ingestion to create the stack as you can combine the steps of assigning security groups and tagging the instance, EBS volume, and other (like adding the instance to an ELB) in the same stack.
Change type: Deployment, Ingestion, Stack from CloudFormation Template, Create
Stop the placeholder instance.
Change type: Management, Advanced stack components, EC2 instance, Stop
If not done in step 1, tag the placeholder instance and its EBS volume with key: "AWSDRS", value: "AllowLaunchingIntoThisInstance".
Change type: Management, Advanced stack components, Tag, Update.
Use the placeholder instance from step 1 as the target under Launch into instance ID, DRS Launch Settings for the source server. Initiate instance recovery drill from the Elastic Disaster Recovery console for the Source Server.
Note
The placeholder instance volumes are retained in the account. To delete these volumes, submit a Management | Advanced stack components | EBS Volume | Delete change type (ct-3e3h8u0sp5z80) at the end of the disaster recovery operation.
Elastic Disaster Recovery restore workflow:
The target (placeholder) instance needs to be in the stopped state
Swap out the volumes and delete the source (placeholder) root volume
Start the instance
Run the Post Launch Actions to complete the following items:
Activate the SSM Agent.
Swap out the volumes and delete the source (placeholder) root volume.
Start the instance
Run PostLaunchScript SSM Document. This document does following:
Leaves the old domain.
Changes the hostname.
Reboot. AMS bootstrap scripts join the instance to the target (DR) domain during startup.
