Learning to Rank for Amazon OpenSearch Service
OpenSearch uses a probabilistic ranking framework called BM-25 to calculate relevance scores. If a distinctive keyword appears more frequently in a document, BM-25 assigns a higher relevance score to that document. This framework, however, doesn’t take into account user behavior like click-through data, which can further improve relevance.
Learning to Rank is an open-source plugin that lets you use machine learning and behavioral
data to tune the relevance of documents. It uses models from the XGBoost and Ranklib libraries
to rescore the search results. The Elasticsearch
LTR plugin
Learning to Rank requires OpenSearch or Elasticsearch 7.7 or later. To use the Learning to Rank plugin, you must have full admin permissions. To learn more, see Modifying the master user.
Note
This documentation provides a general overview of the Learning to Rank plugin and helps
you get started using it. Full documentation, including detailed steps and API descriptions,
is available in the Learning to
Rank
Getting started with Learning to Rank
You need to provide a judgment list, prepare a training dataset, and train the model outside of Amazon OpenSearch Service. The parts in blue occur outside of OpenSearch Service:
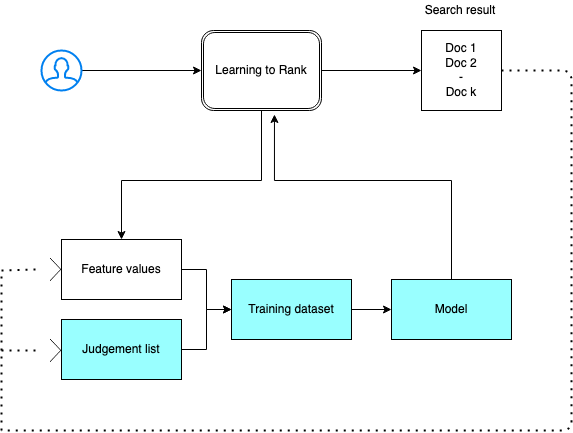
Step 1: Initialize the plugin
To initialize the Learning to Rank plugin, send the following request to your OpenSearch Service domain:
PUT _ltr
{ "acknowledged" : true, "shards_acknowledged" : true, "index" : ".ltrstore" }
This command creates a hidden .ltrstore index that stores metadata
information such as feature sets and models.
Step 2: Create a judgment list
Note
You must perform this step outside of OpenSearch Service.
A judgment list is a collection of examples that a machine learning model learns from. Your judgment list should include keywords that are important to you and a set of graded documents for each keyword.
In this example, we have a judgment list for a movie dataset. A grade of 4 indicates a perfect match. A grade of 0 indicates the worst match.
| Grade | Keyword | Doc ID | Movie name |
|---|---|---|---|
| 4 | rambo | 7555 | Rambo |
| 3 | rambo | 1370 | Rambo III |
| 3 | rambo | 1369 | Rambo: First Blood Part II |
| 3 | rambo | 1368 | First Blood |
Prepare your judgment list in the following format:
4 qid:1 # 7555 Rambo 3 qid:1 # 1370 Rambo III 3 qid:1 # 1369 Rambo: First Blood Part II 3 qid:1 # 1368 First Blood where qid:1 represents "rambo"
For a more complete example of a judgment list, see movie judgments
You can create this judgment list manually with the help of human annotators or infer it programmatically from analytics data.
Step 3: Build a feature set
A feature is a field that corresponds to the relevance of a document—for example,
title, overview, popularity score (number of
views), and so on.
Build a feature set with a Mustache template for each feature. For more information
about features, see Working with Features
In this example, we build a movie_features feature set with the
title and overview fields:
POST _ltr/_featureset/movie_features { "featureset" : { "name" : "movie_features", "features" : [ { "name" : "1", "params" : [ "keywords" ], "template_language" : "mustache", "template" : { "match" : { "title" : "{{keywords}}" } } }, { "name" : "2", "params" : [ "keywords" ], "template_language" : "mustache", "template" : { "match" : { "overview" : "{{keywords}}" } } } ] } }
If you query the original .ltrstore index, you get back your feature
set:
GET _ltr/_featureset
Step 4: Log the feature values
The feature values are the relevance scores calculated by BM-25 for each feature.
Combine the feature set and judgment list to log the feature values. For more
information about logging features, see Logging Feature Scores
In this example, the bool query retrieves the graded documents with the
filter, and then selects the feature set with the sltr query. The
ltr_log query combines the documents and the features to log the
corresponding feature values:
POST tmdb/_search { "_source": { "includes": [ "title", "overview" ] }, "query": { "bool": { "filter": [ { "terms": { "_id": [ "7555", "1370", "1369", "1368" ] } }, { "sltr": { "_name": "logged_featureset", "featureset": "movie_features", "params": { "keywords": "rambo" } } } ] } }, "ext": { "ltr_log": { "log_specs": { "name": "log_entry1", "named_query": "logged_featureset" } } } }
A sample response might look like the following:
{ "took" : 7, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 4, "relation" : "eq" }, "max_score" : 0.0, "hits" : [ { "_index" : "tmdb", "_type" : "movie", "_id" : "1368", "_score" : 0.0, "_source" : { "overview" : "When former Green Beret John Rambo is harassed by local law enforcement and arrested for vagrancy, the Vietnam vet snaps, runs for the hills and rat-a-tat-tats his way into the action-movie hall of fame. Hounded by a relentless sheriff, Rambo employs heavy-handed guerilla tactics to shake the cops off his tail.", "title" : "First Blood" }, "fields" : { "_ltrlog" : [ { "log_entry1" : [ { "name" : "1" }, { "name" : "2", "value" : 10.558305 } ] } ] }, "matched_queries" : [ "logged_featureset" ] }, { "_index" : "tmdb", "_type" : "movie", "_id" : "7555", "_score" : 0.0, "_source" : { "overview" : "When governments fail to act on behalf of captive missionaries, ex-Green Beret John James Rambo sets aside his peaceful existence along the Salween River in a war-torn region of Thailand to take action. Although he's still haunted by violent memories of his time as a U.S. soldier during the Vietnam War, Rambo can hardly turn his back on the aid workers who so desperately need his help.", "title" : "Rambo" }, "fields" : { "_ltrlog" : [ { "log_entry1" : [ { "name" : "1", "value" : 11.2569065 }, { "name" : "2", "value" : 9.936821 } ] } ] }, "matched_queries" : [ "logged_featureset" ] }, { "_index" : "tmdb", "_type" : "movie", "_id" : "1369", "_score" : 0.0, "_source" : { "overview" : "Col. Troutman recruits ex-Green Beret John Rambo for a highly secret and dangerous mission. Teamed with Co Bao, Rambo goes deep into Vietnam to rescue POWs. Deserted by his own team, he's left in a hostile jungle to fight for his life, avenge the death of a woman and bring corrupt officials to justice.", "title" : "Rambo: First Blood Part II" }, "fields" : { "_ltrlog" : [ { "log_entry1" : [ { "name" : "1", "value" : 6.334839 }, { "name" : "2", "value" : 10.558305 } ] } ] }, "matched_queries" : [ "logged_featureset" ] }, { "_index" : "tmdb", "_type" : "movie", "_id" : "1370", "_score" : 0.0, "_source" : { "overview" : "Combat has taken its toll on Rambo, but he's finally begun to find inner peace in a monastery. When Rambo's friend and mentor Col. Trautman asks for his help on a top secret mission to Afghanistan, Rambo declines but must reconsider when Trautman is captured.", "title" : "Rambo III" }, "fields" : { "_ltrlog" : [ { "log_entry1" : [ { "name" : "1", "value" : 9.425955 }, { "name" : "2", "value" : 11.262714 } ] } ] }, "matched_queries" : [ "logged_featureset" ] } ] } }
In the previous example, the first feature doesn’t have a feature value because the keyword “rambo” doesn’t appear in the title field of the document with an ID equal to 1368. This is a missing feature value in the training data.
Step 5: Create a training dataset
Note
You must perform this step outside of OpenSearch Service.
The next step is to combine the judgment list and feature values to create a training dataset. If your original judgment list looks like this:
4 qid:1 # 7555 Rambo 3 qid:1 # 1370 Rambo III 3 qid:1 # 1369 Rambo: First Blood Part II 3 qid:1 # 1368 First Blood
Convert it into the final training dataset, which looks like this:
4 qid:1 1:12.318474 2:10.573917 # 7555 rambo 3 qid:1 1:10.357875 2:11.950391 # 1370 rambo 3 qid:1 1:7.010513 2:11.220095 # 1369 rambo 3 qid:1 1:0.0 2:11.220095 # 1368 rambo
You can perform this step manually or write a program to automate it.
Step 6: Choose an algorithm and build the model
Note
You must perform this step outside of OpenSearch Service.
With the training dataset in place, the next step is to use XGBoost or Ranklib libraries to build a model. XGBoost and Ranklib libraries let you build popular models such as LambdaMART, Random Forests, and so on.
For steps to use XGBoost and Ranklib to build the model, see the XGBoost
Step 7: Deploy the model
After you have built the model, deploy it into the Learning to Rank plugin. For more
information about deploying a model, see Uploading A Trained Model
In this example, we build a my_ranklib_model model using the Ranklib
library:
POST _ltr/_featureset/movie_features/_createmodel?pretty { "model": { "name": "my_ranklib_model", "model": { "type": "model/ranklib", "definition": """## LambdaMART ## No. of trees = 10 ## No. of leaves = 10 ## No. of threshold candidates = 256 ## Learning rate = 0.1 ## Stop early = 100 <ensemble> <tree id="1" weight="0.1"> <split> <feature>1</feature> <threshold>10.357875</threshold> <split pos="left"> <feature>1</feature> <threshold>0.0</threshold> <split pos="left"> <output>-2.0</output> </split> <split pos="right"> <feature>1</feature> <threshold>7.010513</threshold> <split pos="left"> <output>-2.0</output> </split> <split pos="right"> <output>-2.0</output> </split> </split> </split> <split pos="right"> <output>2.0</output> </split> </split> </tree> <tree id="2" weight="0.1"> <split> <feature>1</feature> <threshold>10.357875</threshold> <split pos="left"> <feature>1</feature> <threshold>0.0</threshold> <split pos="left"> <output>-1.67031991481781</output> </split> <split pos="right"> <feature>1</feature> <threshold>7.010513</threshold> <split pos="left"> <output>-1.67031991481781</output> </split> <split pos="right"> <output>-1.6703200340270996</output> </split> </split> </split> <split pos="right"> <output>1.6703201532363892</output> </split> </split> </tree> <tree id="3" weight="0.1"> <split> <feature>2</feature> <threshold>10.573917</threshold> <split pos="left"> <output>1.479954481124878</output> </split> <split pos="right"> <feature>1</feature> <threshold>7.010513</threshold> <split pos="left"> <feature>1</feature> <threshold>0.0</threshold> <split pos="left"> <output>-1.4799546003341675</output> </split> <split pos="right"> <output>-1.479954481124878</output> </split> </split> <split pos="right"> <output>-1.479954481124878</output> </split> </split> </split> </tree> <tree id="4" weight="0.1"> <split> <feature>1</feature> <threshold>10.357875</threshold> <split pos="left"> <feature>1</feature> <threshold>0.0</threshold> <split pos="left"> <output>-1.3569872379302979</output> </split> <split pos="right"> <feature>1</feature> <threshold>7.010513</threshold> <split pos="left"> <output>-1.3569872379302979</output> </split> <split pos="right"> <output>-1.3569872379302979</output> </split> </split> </split> <split pos="right"> <output>1.3569873571395874</output> </split> </split> </tree> <tree id="5" weight="0.1"> <split> <feature>1</feature> <threshold>10.357875</threshold> <split pos="left"> <feature>1</feature> <threshold>0.0</threshold> <split pos="left"> <output>-1.2721362113952637</output> </split> <split pos="right"> <feature>1</feature> <threshold>7.010513</threshold> <split pos="left"> <output>-1.2721363306045532</output> </split> <split pos="right"> <output>-1.2721363306045532</output> </split> </split> </split> <split pos="right"> <output>1.2721362113952637</output> </split> </split> </tree> <tree id="6" weight="0.1"> <split> <feature>1</feature> <threshold>10.357875</threshold> <split pos="left"> <feature>1</feature> <threshold>7.010513</threshold> <split pos="left"> <feature>1</feature> <threshold>0.0</threshold> <split pos="left"> <output>-1.2110036611557007</output> </split> <split pos="right"> <output>-1.2110036611557007</output> </split> </split> <split pos="right"> <output>-1.2110037803649902</output> </split> </split> <split pos="right"> <output>1.2110037803649902</output> </split> </split> </tree> <tree id="7" weight="0.1"> <split> <feature>1</feature> <threshold>10.357875</threshold> <split pos="left"> <feature>1</feature> <threshold>7.010513</threshold> <split pos="left"> <feature>1</feature> <threshold>0.0</threshold> <split pos="left"> <output>-1.165616512298584</output> </split> <split pos="right"> <output>-1.165616512298584</output> </split> </split> <split pos="right"> <output>-1.165616512298584</output> </split> </split> <split pos="right"> <output>1.165616512298584</output> </split> </split> </tree> <tree id="8" weight="0.1"> <split> <feature>1</feature> <threshold>10.357875</threshold> <split pos="left"> <feature>1</feature> <threshold>7.010513</threshold> <split pos="left"> <feature>1</feature> <threshold>0.0</threshold> <split pos="left"> <output>-1.131177544593811</output> </split> <split pos="right"> <output>-1.131177544593811</output> </split> </split> <split pos="right"> <output>-1.131177544593811</output> </split> </split> <split pos="right"> <output>1.131177544593811</output> </split> </split> </tree> <tree id="9" weight="0.1"> <split> <feature>2</feature> <threshold>10.573917</threshold> <split pos="left"> <output>1.1046180725097656</output> </split> <split pos="right"> <feature>1</feature> <threshold>7.010513</threshold> <split pos="left"> <feature>1</feature> <threshold>0.0</threshold> <split pos="left"> <output>-1.1046180725097656</output> </split> <split pos="right"> <output>-1.1046180725097656</output> </split> </split> <split pos="right"> <output>-1.1046180725097656</output> </split> </split> </split> </tree> <tree id="10" weight="0.1"> <split> <feature>1</feature> <threshold>10.357875</threshold> <split pos="left"> <feature>1</feature> <threshold>7.010513</threshold> <split pos="left"> <feature>1</feature> <threshold>0.0</threshold> <split pos="left"> <output>-1.0838804244995117</output> </split> <split pos="right"> <output>-1.0838804244995117</output> </split> </split> <split pos="right"> <output>-1.0838804244995117</output> </split> </split> <split pos="right"> <output>1.0838804244995117</output> </split> </split> </tree> </ensemble> """ } } }
To see the model, send the following request:
GET _ltr/_model/my_ranklib_model
Step 8: Search with learning to rank
After you deploy the model, you’re ready to search.
Perform the sltr query with the features that you’re using and the name of
the model that you want to execute:
POST tmdb/_search { "_source": { "includes": ["title", "overview"] }, "query": { "multi_match": { "query": "rambo", "fields": ["title", "overview"] } }, "rescore": { "query": { "rescore_query": { "sltr": { "params": { "keywords": "rambo" }, "model": "my_ranklib_model" } } } } }
With Learning to Rank, you see “Rambo” as the first result because we have assigned it the highest grade in the judgment list:
{ "took" : 12, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 7, "relation" : "eq" }, "max_score" : 13.096414, "hits" : [ { "_index" : "tmdb", "_type" : "movie", "_id" : "7555", "_score" : 13.096414, "_source" : { "overview" : "When governments fail to act on behalf of captive missionaries, ex-Green Beret John James Rambo sets aside his peaceful existence along the Salween River in a war-torn region of Thailand to take action. Although he's still haunted by violent memories of his time as a U.S. soldier during the Vietnam War, Rambo can hardly turn his back on the aid workers who so desperately need his help.", "title" : "Rambo" } }, { "_index" : "tmdb", "_type" : "movie", "_id" : "1370", "_score" : 11.17245, "_source" : { "overview" : "Combat has taken its toll on Rambo, but he's finally begun to find inner peace in a monastery. When Rambo's friend and mentor Col. Trautman asks for his help on a top secret mission to Afghanistan, Rambo declines but must reconsider when Trautman is captured.", "title" : "Rambo III" } }, { "_index" : "tmdb", "_type" : "movie", "_id" : "1368", "_score" : 10.442155, "_source" : { "overview" : "When former Green Beret John Rambo is harassed by local law enforcement and arrested for vagrancy, the Vietnam vet snaps, runs for the hills and rat-a-tat-tats his way into the action-movie hall of fame. Hounded by a relentless sheriff, Rambo employs heavy-handed guerilla tactics to shake the cops off his tail.", "title" : "First Blood" } }, { "_index" : "tmdb", "_type" : "movie", "_id" : "1369", "_score" : 10.442155, "_source" : { "overview" : "Col. Troutman recruits ex-Green Beret John Rambo for a highly secret and dangerous mission. Teamed with Co Bao, Rambo goes deep into Vietnam to rescue POWs. Deserted by his own team, he's left in a hostile jungle to fight for his life, avenge the death of a woman and bring corrupt officials to justice.", "title" : "Rambo: First Blood Part II" } }, { "_index" : "tmdb", "_type" : "movie", "_id" : "31362", "_score" : 7.424202, "_source" : { "overview" : "It is 1985, and a small, tranquil Florida town is being rocked by a wave of vicious serial murders and bank robberies. Particularly sickening to the authorities is the gratuitous use of violence by two “Rambo” like killers who dress themselves in military garb. Based on actual events taken from FBI files, the movie depicts the Bureau’s efforts to track down these renegades.", "title" : "In the Line of Duty: The F.B.I. Murders" } }, { "_index" : "tmdb", "_type" : "movie", "_id" : "13258", "_score" : 6.43182, "_source" : { "overview" : """Will Proudfoot (Bill Milner) is looking for an escape from his family's stifling home life when he encounters Lee Carter (Will Poulter), the school bully. Armed with a video camera and a copy of "Rambo: First Blood", Lee plans to make cinematic history by filming his own action-packed video epic. Together, these two newfound friends-turned-budding-filmmakers quickly discover that their imaginative ― and sometimes mishap-filled ― cinematic adventure has begun to take on a life of its own!""", "title" : "Son of Rambow" } }, { "_index" : "tmdb", "_type" : "movie", "_id" : "61410", "_score" : 3.9719706, "_source" : { "overview" : "It's South Africa 1990. Two major events are about to happen: The release of Nelson Mandela and, more importantly, it's Spud Milton's first year at an elite boys only private boarding school. John Milton is a boy from an ordinary background who wins a scholarship to a private school in Kwazulu-Natal, South Africa. Surrounded by boys with nicknames like Gecko, Rambo, Rain Man and Mad Dog, Spud has his hands full trying to adapt to his new home. Along the way Spud takes his first tentative steps along the path to manhood. (The path it seems could be a rather long road). Spud is an only child. He is cursed with parents from well beyond the lunatic fringe and a senile granny. His dad is a fervent anti-communist who is paranoid that the family domestic worker is running a shebeen from her room at the back of the family home. His mom is a free spirit and a teenager's worst nightmare, whether it's shopping for Spud's underwear in the local supermarket", "title" : "Spud" } } ] } }
If you search without using the Learning to Rank plugin, OpenSearch returns different results:
POST tmdb/_search { "_source": { "includes": ["title", "overview"] }, "query": { "multi_match": { "query": "Rambo", "fields": ["title", "overview"] } } }
{ "took" : 5, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 5, "relation" : "eq" }, "max_score" : 11.262714, "hits" : [ { "_index" : "tmdb", "_type" : "movie", "_id" : "1370", "_score" : 11.262714, "_source" : { "overview" : "Combat has taken its toll on Rambo, but he's finally begun to find inner peace in a monastery. When Rambo's friend and mentor Col. Trautman asks for his help on a top secret mission to Afghanistan, Rambo declines but must reconsider when Trautman is captured.", "title" : "Rambo III" } }, { "_index" : "tmdb", "_type" : "movie", "_id" : "7555", "_score" : 11.2569065, "_source" : { "overview" : "When governments fail to act on behalf of captive missionaries, ex-Green Beret John James Rambo sets aside his peaceful existence along the Salween River in a war-torn region of Thailand to take action. Although he's still haunted by violent memories of his time as a U.S. soldier during the Vietnam War, Rambo can hardly turn his back on the aid workers who so desperately need his help.", "title" : "Rambo" } }, { "_index" : "tmdb", "_type" : "movie", "_id" : "1368", "_score" : 10.558305, "_source" : { "overview" : "When former Green Beret John Rambo is harassed by local law enforcement and arrested for vagrancy, the Vietnam vet snaps, runs for the hills and rat-a-tat-tats his way into the action-movie hall of fame. Hounded by a relentless sheriff, Rambo employs heavy-handed guerilla tactics to shake the cops off his tail.", "title" : "First Blood" } }, { "_index" : "tmdb", "_type" : "movie", "_id" : "1369", "_score" : 10.558305, "_source" : { "overview" : "Col. Troutman recruits ex-Green Beret John Rambo for a highly secret and dangerous mission. Teamed with Co Bao, Rambo goes deep into Vietnam to rescue POWs. Deserted by his own team, he's left in a hostile jungle to fight for his life, avenge the death of a woman and bring corrupt officials to justice.", "title" : "Rambo: First Blood Part II" } }, { "_index" : "tmdb", "_type" : "movie", "_id" : "13258", "_score" : 6.4600153, "_source" : { "overview" : """Will Proudfoot (Bill Milner) is looking for an escape from his family's stifling home life when he encounters Lee Carter (Will Poulter), the school bully. Armed with a video camera and a copy of "Rambo: First Blood", Lee plans to make cinematic history by filming his own action-packed video epic. Together, these two newfound friends-turned-budding-filmmakers quickly discover that their imaginative ― and sometimes mishap-filled ― cinematic adventure has begun to take on a life of its own!""", "title" : "Son of Rambow" } } ] } }
Based on how well you think the model is performing, adjust the judgment list and features. Then, repeat steps 2–8 to improve the ranking results over time.
Learning to Rank API
Use the Learning to Rank operations to programmatically work with feature sets and models.
Create store
Creates a hidden .ltrstore index that stores metadata information such as
feature sets and models.
PUT _ltr
Delete store
Deletes the hidden .ltrstore index and resets the plugin.
DELETE _ltr
Create feature set
Creates a feature set.
POST _ltr/_featureset/<name_of_features>
Delete feature set
Deletes a feature set.
DELETE _ltr/_featureset/<name_of_feature_set>
Get feature set
Retrieves a feature set.
GET _ltr/_featureset/<name_of_feature_set>
Create model
Creates a model.
POST _ltr/_featureset/<name_of_feature_set>/_createmodel
Delete model
Deletes a model.
DELETE _ltr/_model/<name_of_model>
Get model
Retrieves a model.
GET _ltr/_model/<name_of_model>
Get stats
Provides information about how the plugin is behaving.
GET _ltr/_stats
You can also use filters to retrieve a single stat:
GET _ltr/_stats/<stat>
Futthermore, you can limit the information to a single node in the cluster:
GET _ltr/_stats/<stat>/nodes/<nodeId> { "_nodes" : { "total" : 1, "successful" : 1, "failed" : 0 }, "cluster_name" : "873043598401:ltr-77", "stores" : { ".ltrstore" : { "model_count" : 1, "featureset_count" : 1, "feature_count" : 2, "status" : "green" } }, "status" : "green", "nodes" : { "DjelK-_ZSfyzstO5dhGGQA" : { "cache" : { "feature" : { "eviction_count" : 0, "miss_count" : 0, "entry_count" : 0, "memory_usage_in_bytes" : 0, "hit_count" : 0 }, "featureset" : { "eviction_count" : 2, "miss_count" : 2, "entry_count" : 0, "memory_usage_in_bytes" : 0, "hit_count" : 0 }, "model" : { "eviction_count" : 2, "miss_count" : 3, "entry_count" : 1, "memory_usage_in_bytes" : 3204, "hit_count" : 1 } }, "request_total_count" : 6, "request_error_count" : 0 } } }
The statistics are provided at two levels, node and cluster, as specified in the following tables:
| Field name | Description |
|---|---|
| request_total_count | Total count of ranking requests. |
| request_error_count | Total count of unsuccessful requests. |
| cache | Statistics across all caches (features, featuresets, models). A cache hit occurs when a user queries the plugin and the model is already loaded into memory. |
| cache.eviction_count | Number of cache evictions. |
| cache.hit_count | Number of cache hits. |
| cache.miss_count | Number of cache misses. A cache miss occurs when a user queries the plugin and the model has not yet been loaded into memory. |
| cache.entry_count | Number of entries in the cache. |
| cache.memory_usage_in_bytes | Total memory used in bytes. |
| cache.cache_capacity_reached | Indicates if the cache limit is reached. |
| Field name | Description |
|---|---|
| stores | Indicates where the feature sets and model metadata are stored. (The default is “.ltrstore”. Otherwise, it's prefixed with “.ltrstore_”, with a user supplied name). |
| stores.status | Status of the index. |
| stores.feature_sets | Number of feature sets. |
| stores.features_count | Number of features. |
| stores.model_count | Number of models. |
| status | The plugin status based on the status of the feature store indices (red, yellow, or green) and circuit breaker state (open or closed). |
| cache.cache_capacity_reached | Indicates if the cache limit is reached. |
Get cache stats
Returns statistics about the cache and memory usage.
GET _ltr/_cachestats { "_nodes": { "total": 2, "successful": 2, "failed": 0 }, "cluster_name": "opensearch-cluster", "all": { "total": { "ram": 612, "count": 1 }, "features": { "ram": 0, "count": 0 }, "featuresets": { "ram": 612, "count": 1 }, "models": { "ram": 0, "count": 0 } }, "stores": { ".ltrstore": { "total": { "ram": 612, "count": 1 }, "features": { "ram": 0, "count": 0 }, "featuresets": { "ram": 612, "count": 1 }, "models": { "ram": 0, "count": 0 } } }, "nodes": { "ejF6uutERF20wOFNOXB61A": { "name": "opensearch1", "hostname": "172.18.0.4", "stats": { "total": { "ram": 612, "count": 1 }, "features": { "ram": 0, "count": 0 }, "featuresets": { "ram": 612, "count": 1 }, "models": { "ram": 0, "count": 0 } } }, "Z2RZNWRLSveVcz2c6lHf5A": { "name": "opensearch2", "hostname": "172.18.0.2", "stats": { ... } } } }
Clear cache
Clears the plugin cache. Use this to refresh the model.
POST _ltr/_clearcache
