Architecture for forecasting freight demand
The following image shows the workflow of the solution, including data ingestion, data preparation, model building, and final output and monitoring.
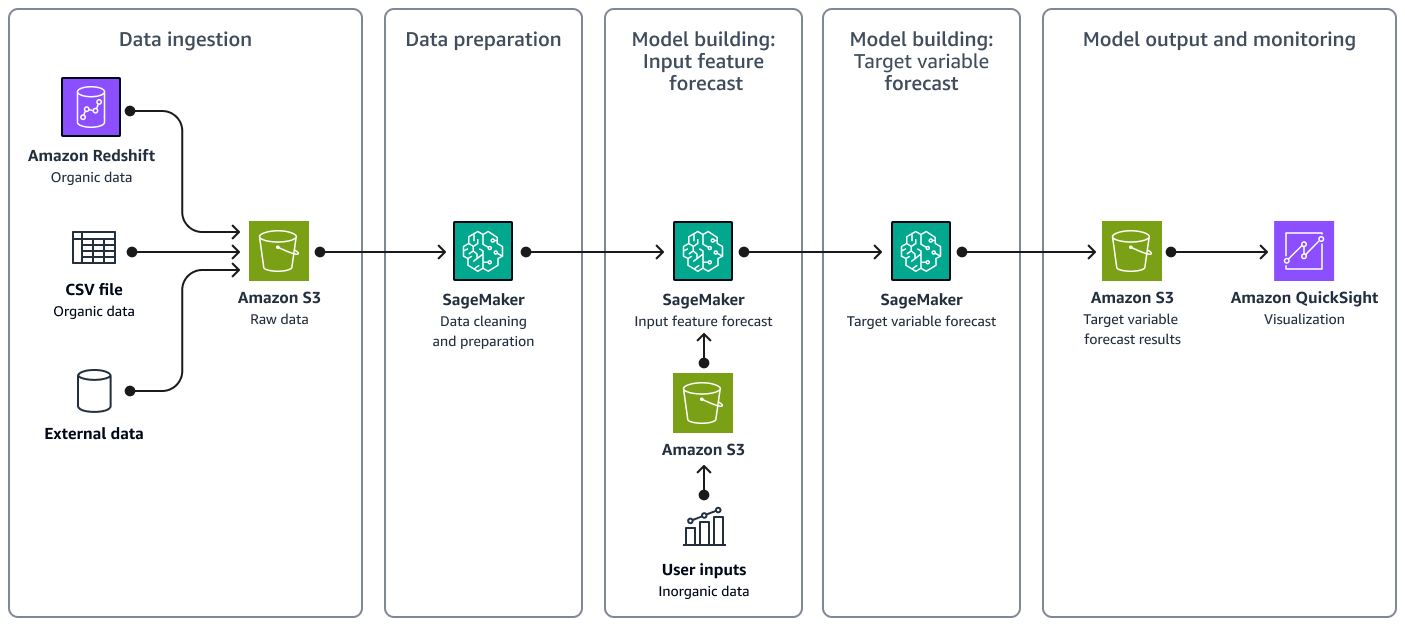
The solution architecture includes the following main components:
-
Data ingestion – You store both organic data and external data in Amazon Simple Storage Service (Amazon S3).
-
Data preparation – Amazon SageMaker AI cleans up the data and prepares it for ML model training. For more information, see Prepare data in the SageMaker AI documentation.
-
Model building: Input feature forecast – SageMaker AI uses Prophet
to generate a time series forecast for each input feature. You examine the forecast results. If needed, you provide user inputs to overwrite the feature's forecast. -
Model building: Target variable forecast – SageMaker AI creates a regression model for inference by using the modified input features.
-
Model output and monitoring – The regression model outputs the forecast results to Amazon S3. You can visualize the forecast in Amazon QuickSight. Analysts can monitor the forecast results and evaluate accuracy by comparing the forecast with actual demand volume.
The entire processing pipeline from data ingestion to final model output can be orchestrated to run automatically. For example, you can set it up to automatically run monthly for a monthly demand forecast. If you need forecasts for more than one product, you can run the pipeline in parallel for multiple products. For more information, see Implement MLOps in the SageMaker AI documentation.
