Stage 2: Implementing a large migration
In stage 2 of a large migration, the goal is to migrate your servers at scale. For example, to migrate 1,000 servers in 6 months, you might start by migrating 5 servers per week and then gradually increase the velocity up to 50–100 servers per week.
Now you use the runbooks that you developed in stage 1 to migrate servers in waves. The first couple of waves are typically small because the migration and portfolio workstreams are adopting and adjusting the processes in their runbooks. Improving the runbooks is key to the success of a large migration. Runbooks are living documents. You must review, revise, and improve your runbooks after each cutover. As the runbooks evolve over time, the velocity should increase with every wave.
In stage 2, you use the following components to operate the migration factory:
-
Project governance rules – You follow the project governance processes to manage waves, communication, timelines, and cutovers. These processes and tools make sure that everyone does the right thing at the right time and in the right order.
-
Portfolio runbooks – You use the portfolio runbooks to prioritize applications, plan waves, and collect the required metadata that supports the migration. This metadata is the equivalent of raw materials in a manufacturing factory.
-
Migration runbooks – You use the migration runbooks to migrate apps and servers, load the metadata to your migration tools, and complete the cutover process at the end of each wave. When following the migration runbooks, you adhere to the wave plan in the portfolio runbooks and use the metadata in the portfolio runbooks or from another single source of truth.
-
Large migration best practices and health-check matrix – You use the health-check matrix to evaluate your current state frequently and regularly to make sure that everything is on track.
The following figure shows a typical migration factory for large migrations.
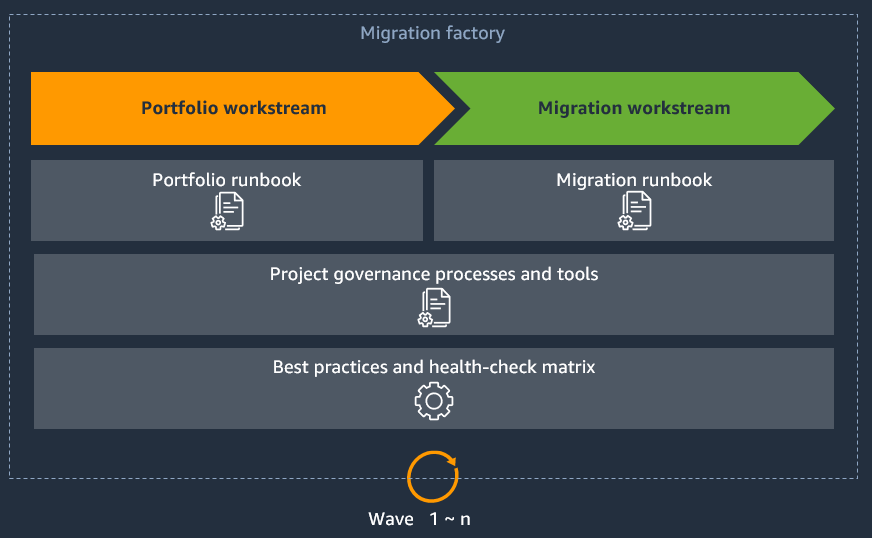
The runbooks are the key components of the migration factory, and they work together to form a data flow through two workstreams, portfolio and migration. For more information about these workstreams, see the Foundation playbook for AWS large migrations. Rather than seeing a wave all the way through the migration factory, teams are usually dedicated to certain parts of the factory, and the waves flow through each workstream. The duration of each workstream varies based on your project timeline, scope, and resource availability. For example, the portfolio workstream might be 3 weeks, and the migration workstream might be 2–5 weeks. Prevent supply chain problems in your migration factory by ensuring that there are sufficient server waves lined up for migration. We recommend that the portfolio workstream is five waves ahead of the migration workstream.
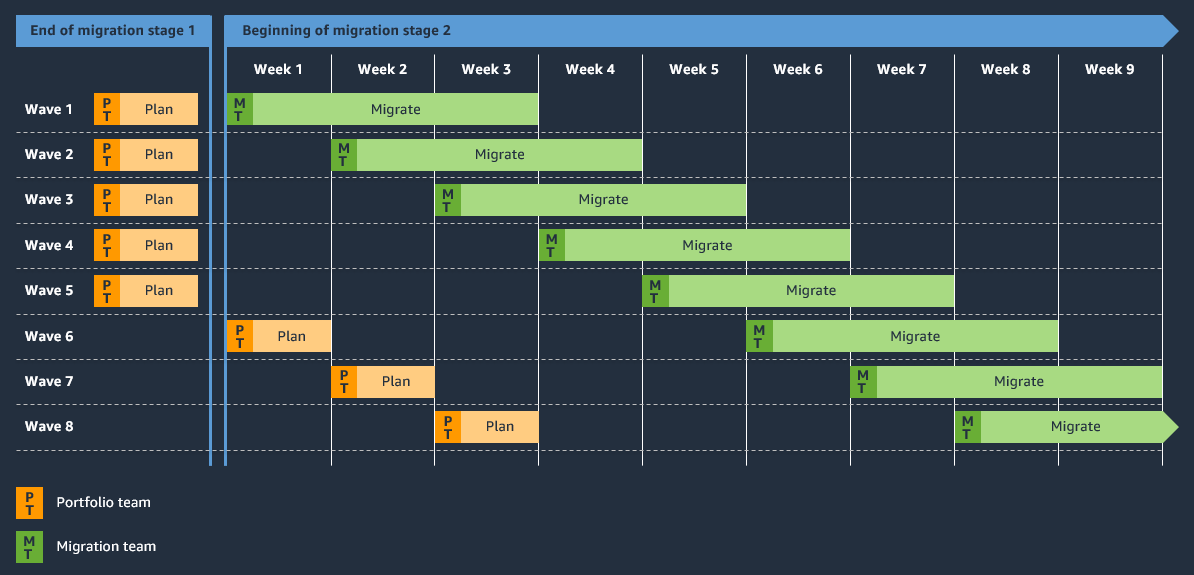
The following figure shows a dynamic view of a typical migration factory. For each wave, the portfolio workstream runs 1–2 weeks, and the migration workstream typically runs 3–4 weeks. The portfolio workstream is five waves ahead of the migration workstream, so there is always a five-wave buffer between the portfolio and migration workstreams. At the end of migration stage 1, initializing, the portfolio workstream completes wave planning for a buffer of five waves. When the migration workstream starts migrating applications, this indicates that you have entered stage 2, implementing. Both the portfolio and the migration workstreams continue to process waves, and the buffer prevents the migration workstream from running out of servers to migrate.