Solution overview
A scalable ML framework
In a business with millions of customers spread across multiple lines of business, ML workflows require the integration of data owned and managed by siloed teams using different tools to unlock business value. Banks are committed to the protection of their customers' data. Similarly, the infrastructure used for the development of ML models is also subject to high security standards. This additional security adds further complexity and impacts the time to value for new ML models. In a scalable ML framework, you can use a modernized, standardized toolset to reduce the effort required for combining different tools and simplify the route-to-live process for new ML models.
Traditionally, the management and support of data science activities in the FS industry is controlled by a central platform team that gathers requirements, provisions resources, and maintains infrastructure for data teams across the organization. To rapidly scale the use of ML in federated teams across the organization, you can use a scalable ML framework to provide self-service capabilities for developers of new models and pipelines. This enables these developers to deploy modern, pre-approved, standardized, and secure infrastructure. Ultimately, these self-service capabilities reduce your organization’s dependency on centralized platform teams and speed up the time to value for ML model development.
The scalable ML framework enables data consumers (for example, data scientists or ML engineers) to unlock business value by giving them the ability to do the following:
Browse and discover pre-approved data that’s required for model training
Gain access to pre-approved data quickly and easily
Use pre-approved data to prove model viability
Release the proven model to production for others to use
The following diagram highlights the end-to-end flow of the framework and the simplified route to live for ML use cases.
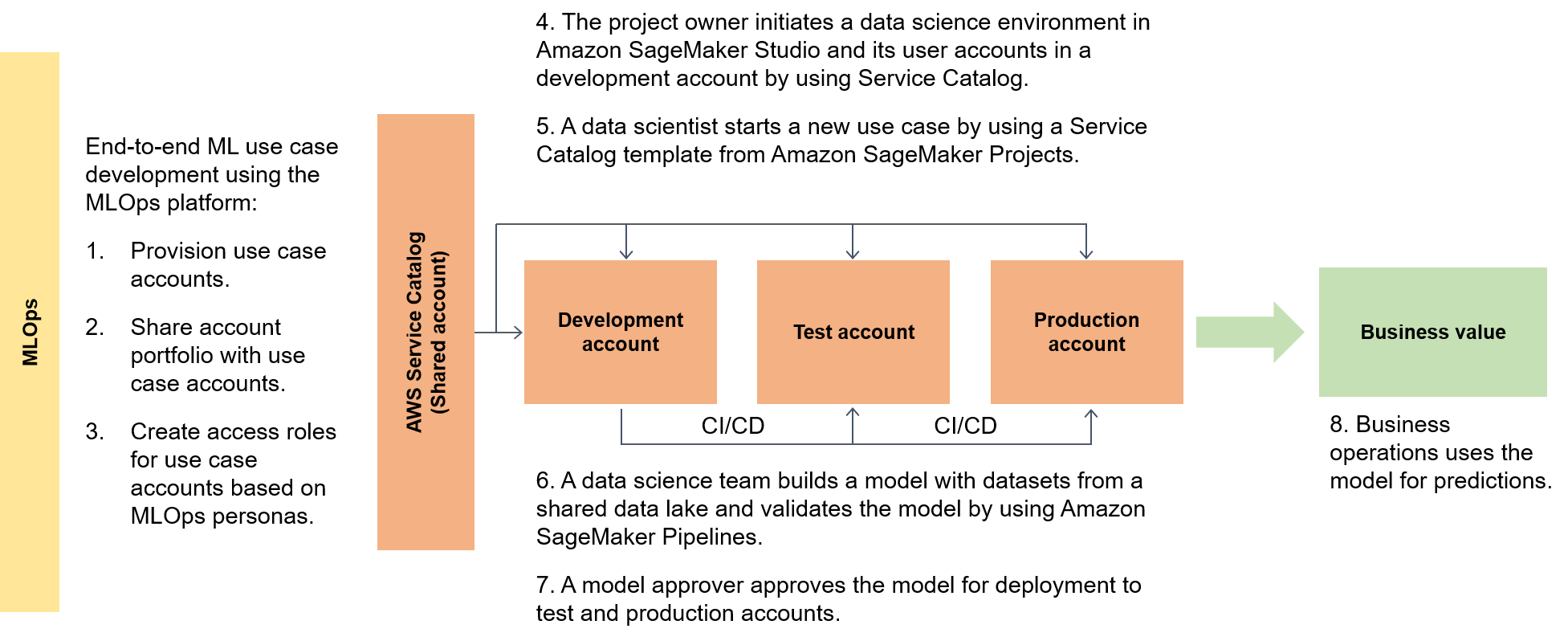
In the wider context, data consumers use a serverless accelerator called data.all to source data across multiple data lakes and then use the data to train their models, as the following diagram illustrates.
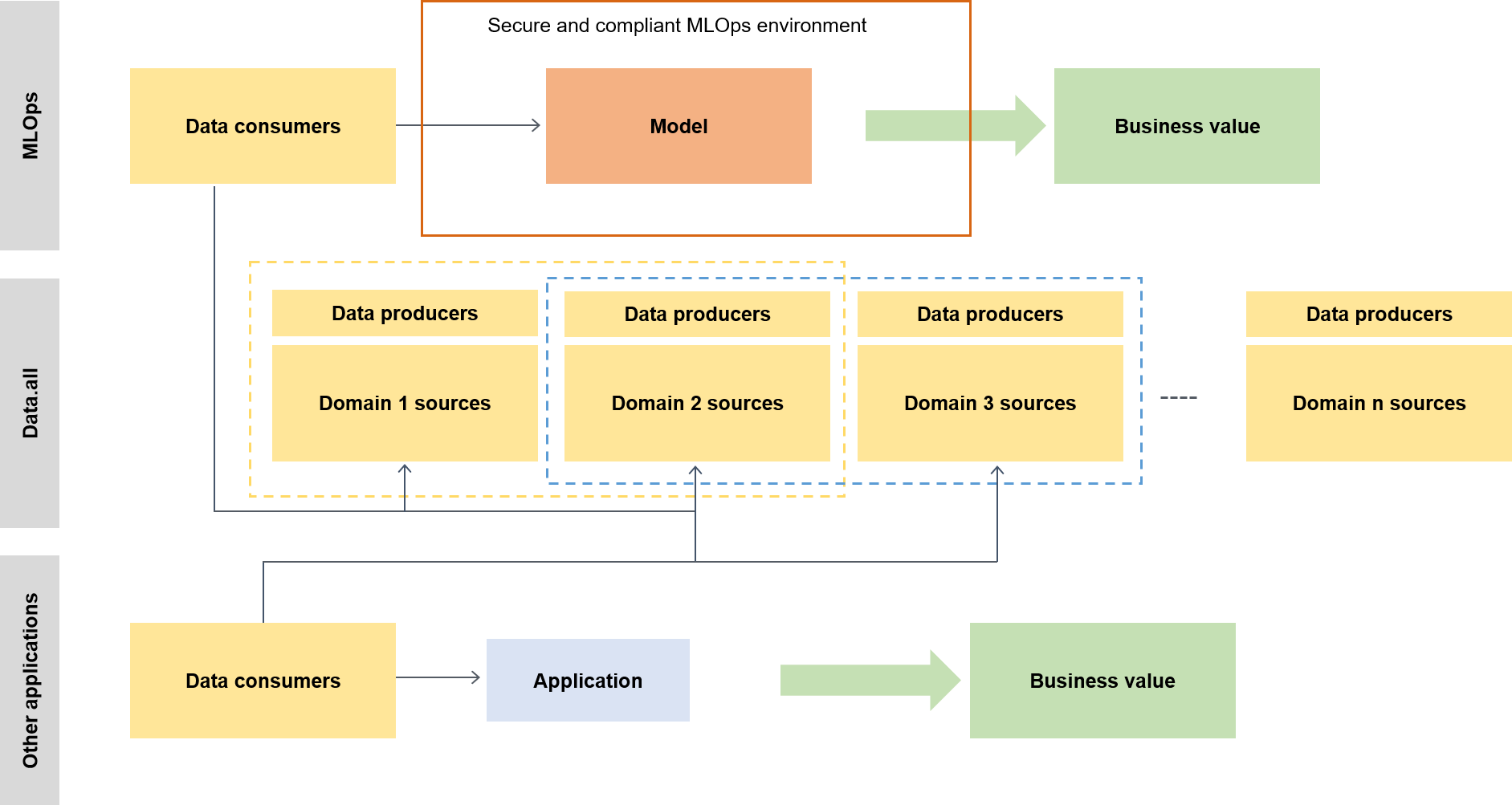
At a lower level, the scalable ML framework contains the following:
Self-service infrastructure deployment – Reduce your dependency on centralized teams.
Central Python package management system – Make pre-approved Python packages available for model development.
CI/CD pipelines for model development and promotion – Decrease time to live by including continuous integration and continuous (CI/CD) pipelines as part of your infrastructure as code (IaC) templates.
Model testing capabilities – Take advantage of unit testing, model testing, integration testing, and end-to-end testing functionalities that are automatically available for new models.
Model decoupling and orchestration – Avoid unnecessary compute and make your deployments more robust by decoupling model steps according to computational resource requirements and orchestration of the different steps by using Amazon SageMaker AI Pipelines
. Code standardization – Improve the quality of your code by using CI/CD pipeline integration for validating Python Enhancement Proposal (PEP 8)
standards. Quick-start generic ML templates – Get Service Catalog templates that instantiate your ML modelling environments (development, pre-production, and production) and associated pipelines with the click of a button by using SageMaker AI Projects for deployment.
Data and model quality monitoring – Make sure that your models perform to operational requirements and within your risk-tolerance level by using Amazon SageMaker AI Model Monitor to automatically monitor drift in your data and model quality.
Bias monitoring – Enable your model owners to make fair and equitable decisions by automatically checking for data imbalances and if changes in the world have introduced bias to your model.
A central hub for metadata
Data.all
SageMaker validation
To prove the capabilities of SageMaker AI across a range of data processing and ML architectures, the team implementing the capabilities selects, together with the banking leadership team, use cases of varying complexity from different divisions of banking customers. The use case data is obfuscated and made available in a local Amazon Simple Storage Service (Amazon S3)
When the model migration from the original training environment to a SageMaker AI architecture is complete, your cloud-hosted data lake makes the data available to be read by the production models. The predictions generated by the production models are then written back to the data lake.
After the candidate use cases have been migrated, the scalable ML framework takes an initial baseline for the target metrics. You can compare the baseline to previous on-premises or other cloud provider timings as evidence of the time improvements enabled by the scalable ML framework.
