Visualize as atividades de serviço e a integridade operacional em detalhes com a página de detalhes do serviço
Ao realizar a instrumentação da aplicação, o Amazon CloudWatch Application Signals mapeia todos os serviços que a aplicação descobre. Use a página de detalhes do serviço para obter uma visão geral dos serviços, das operações, das dependências, dos canários e das solicitações de clientes para um único serviço. Para visualizar a página de detalhes do serviço, faça o seguinte:
-
Escolha Serviços, na seção Application Signals, no painel de navegação esquerdo.
-
Escolha o nome de qualquer serviço nas tabelas de Serviços, de Principais serviços ou de dependências.
Em schedule-visits, você verá o rótulo e o ID da conta abaixo do nome do serviço.
A página de detalhes do serviço está organizada nas seguintes guias:
-
Visão geral: use esta guia para obter uma visão geral de um único serviço, incluindo o número de operações, as dependências, os canários do Synthetics e as páginas de clientes. A guia mostra as principais métricas de todo o seu serviço, as principais operações e as dependências. Essas métricas incluem dados de séries temporais sobre latência, falhas e erros em todas as operações de serviço para esse serviço.
-
Operações de serviço: use esta guia para obter uma lista das operações que seu serviço chama e os gráficos interativos com as principais métricas que medem a integridade de cada operação. É possível selecionar um ponto de dados em um gráfico para obter informações sobre rastreamentos, logs ou métricas associadas a esse ponto de dados.
-
Dependências: use esta guia para obter uma lista das dependências que seu serviço chama e uma lista de métricas para essas dependências.
-
Canários do Synthetics: use esta guia para obter uma lista de canários do Synthetics que simulam chamadas de usuários para o serviço e as principais métricas de desempenho para esses canários.
-
Páginas de clientes: use esta guia para obter uma lista das páginas de clientes que chamam seu serviço e as métricas que medem a qualidade das interações dos clientes com a aplicação.
-
Métricas relacionadas: use esta guia para correlacionar métricas relacionadas, como métricas padrão, métricas de runtime e métricas personalizadas para um serviço, suas operações ou dependências.
Visualizar a visão geral do serviço
Use a página de visão geral do serviço para visualizar um resumo de alto nível das métricas para todas as operações de serviço em um único local. Verifique o desempenho de todas as operações, dependências, páginas de clientes e canários do Synthetics que interagem com a aplicação. Use essas informações para ajudar na determinação do melhor local para concentrar os esforços com a finalidade de identificar problemas, solucionar erros e encontrar oportunidades para a otimização.
Escolha qualquer link em Detalhes do serviço para visualizar informações relacionadas a um serviço específico. Por exemplo, para serviços hospedados no Amazon EKS, a página de detalhes do serviço mostra informações relacionadas ao Cluster, ao Namespace e à Workload. Para serviços hospedados no Amazon ECS ou no Amazon EC2, a página de detalhes do serviço mostra o valor Ambiente.
Em Serviços, a guia Visão geral exibe um resumo do seguinte:
-
Operações: use esta guia para obter a integridade das operações de serviço. O status da integridade é determinado por indicadores de nível de serviço (SLIs) que são definidos como parte de um objetivo de nível de serviço (SLO).
-
Dependências: use essa guia para obter as principais dependências dos serviços chamados por sua aplicação, listadas por taxa de falhas, e para ver a integridade das suas dependências de serviço. O status da integridade é determinado por indicadores de nível de serviço (SLIs) que são definidos como parte de um objetivo de nível de serviço (SLO).
-
Canários do Synthetics: use esta guia para obter o resultado de chamadas simuladas para os endpoints ou para as APIs associados ao serviço e o número de canários com falha.
-
Páginas de clientes: use esta guia para obter as principais páginas chamadas por clientes que apresentam erros assíncronos de JavaScript e de XML (AJAX).
A ilustração a seguir mostra uma visão geral dos serviços:

A guia Visão geral também exibe um gráfico das dependências com maior latência entre todos os serviços. Use as métricas de latência p99, p90 e p50 para avaliar rapidamente quais dependências estão contribuindo para a latência total do serviço, da seguinte forma:

Por exemplo, o gráfico apresentado anteriormente mostra que 99% das solicitações realizadas à dependência de serviço de atendimento ao cliente foram concluídas em aproximadamente 4.950 milissegundos. As outras dependências demoraram menos tempo para serem concluídas.
Os gráficos que exibem as quatro principais operações de serviço por latência mostram o volume de solicitações, a disponibilidade, a taxa de falhas e a taxa de erros desses serviços, conforme mostrado na seguinte imagem:

A seção Detalhes do serviço exibe os detalhes do serviço, incluindo o ID da conta e o Rótulo da conta.
Visualizar as operações de serviço
Ao realizar a instrumentação da aplicação, o Application Signals descobre todas as operações de serviço que a aplicação chama. Use a guia Operações de serviço para visualizar uma tabela que contém as operações de serviço e um conjunto de métricas que medem o desempenho de uma operação selecionada. Essas métricas incluem o status do SLI, o número de dependências, a latência, o volume, as falhas, os erros e a disponibilidade, conforme mostrado na seguinte imagem:

Filtre a tabela para facilitar a localização de uma operação de serviço ao escolher uma ou mais propriedades na caixa de texto do filtro. Ao escolher cada propriedade, você será guiado pelos critérios do filtro e verá o filtro completo abaixo da caixa de texto do filtro. Escolha Limpar filtros a qualquer momento para remover o filtro da tabela.
Escolha o status do SLI para uma operação a fim de exibir um pop-up que contém um link para qualquer SLI não íntegro e um link para a visualização de todos os SLOs para a operação, conforme mostrado na seguinte tabela:

A tabela de operações de serviço lista o status do SLI, o número de SLIs íntegros ou não íntegros e o número total de SLOs para cada operação.
Use os SLIs para monitorar a latência, a disponibilidade e outras métricas de operações que medem a integridade operacional de um serviço. Use um SLO para verificar o desempenho e o status da integridade dos serviços e das operações.
Para criar um SLO, faça o seguinte:
-
Se uma operação não tiver um SLO, escolha o botão Criar SLO na coluna Status do SLI.
-
Se uma operação já tiver um SLO, faça o seguinte:
-
Selecione o botão de opção ao lado do nome da operação.
-
Escolha Criar SLO no ícone de seta para baixo Ações no canto superior direito da tabela.
-
Para obter mas informações, consulte service level objectives (SLOs).
A coluna Dependências mostra o número de dependências que essa operação chama. Escolha esse número para abrir a guia Dependências filtrada para a operação selecionada.
Visualizar métricas de operações de serviço, rastreamentos correlacionados e logs de aplicações
O Application Signals correlaciona as métricas de operação de serviço com os rastreamentos do AWS X-Ray, com o CloudWatch Container Insights e com os logs de aplicações. Use essas métricas para solucionar problemas de integridade operacional. Para visualizar as métricas como informações gráficas, faça o seguinte:
-
Selecione uma operação de serviço na tabela Operações de serviço para visualizar um conjunto de gráficos para a operação selecionada acima da tabela com métricas para Volume e disponibilidade, Latência e Falhas e erros.
-
Passe o cursor sobre um ponto em um gráfico para visualizar mais informações.
-
Selecione um ponto para abrir um painel de diagnóstico que mostra rastreamentos, métricas e logs de aplicações correlacionados para o ponto selecionado no gráfico.
A imagem apresentada a seguir mostra a dica de ferramenta que aparece após passar o cursor sobre um ponto no gráfico e o painel de diagnóstico que é exibido após clicar em um ponto. A dica de ferramenta contém informações sobre o ponto de dados associado no gráfico Falhas e erros. O painel contém Rastreamentos correlacionados, Principais colaboradores e Logs de aplicações associados ao ponto selecionado.
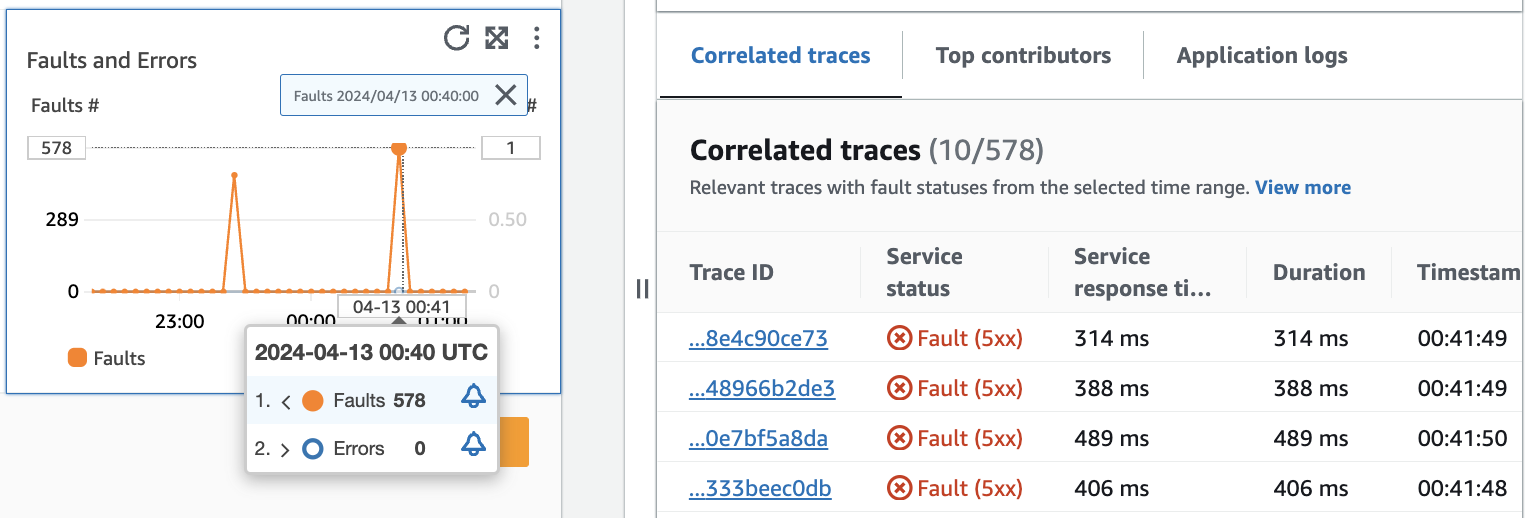
Rastreamentos correlacionados
Considere os rastreamentos relacionados para compreender um problema subjacente com um rastreamento. É possível verificar se os rastreamentos correlacionados ou quaisquer nós de serviço associados a eles se comportam de maneira semelhante. Para examinar os rastreamentos correlacionados, escolha um ID de rastreamento na tabela Rastreamentos correlacionados a fim de abrir a página de detalhes do rastreamento do X-Ray para o rastreamento escolhido. A página de detalhes do rastreamento contém um mapeamento dos nós de serviço associados ao rastreamento selecionado e uma linha do tempo dos segmentos de rastreamento.
Principais responsáveis
Confira os principais colaboradores para encontrar as origens de entrada preferenciais para uma métrica. Agrupe os colaboradores por diferentes componentes para pesquisar semelhanças dentro do grupo e compreender como o comportamento de rastreamento difere entre eles.
A guia Principais colaboradores fornece as métricas Volume de chamadas, Disponibilidade, Latência média, Erros e Falhas de cada grupo. A seguinte imagem de exemplo mostra os principais colaboradores para um conjunto de métricas de uma aplicação implantada em uma plataforma do Amazon EKS:

Os principais colaboradores contêm as seguintes métricas:
-
Volume de chamadas: use o volume de chamadas para compreender o número de solicitações por intervalo de tempo para um grupo.
-
Disponibilidade: use a disponibilidade para obter a porcentagem de tempo em que nenhuma falha foi detectada para um grupo.
-
Latência média: use a latência para verificar o tempo médio de execução das solicitações para um grupo em um intervalo de tempo que depende de há quanto tempo as solicitações que você está investigando foram realizadas. As solicitações que foram realizadas há menos de 15 dias são avaliadas em intervalos de um minuto. As solicitações que foram realizadas entre 15 e 30 dias, inclusive, são avaliadas em intervalos de cinco minutos. Por exemplo, se você estiver investigando solicitações que causaram uma falha há 15 dias, a métrica de volume de chamadas será semelhante ao número de solicitações por intervalo de cinco minutos.
-
Erros: o número de erros por grupo medido durante um intervalo de tempo.
-
Falhas: o número de falhas por grupo durante um intervalo de tempo.
Principais colaboradores que usam o Amazon EKS ou o Kubernetes
Use as informações sobre os principais colaboradores de aplicações implantadas no Amazon EKS ou no Kubernetes para visualizar métricas de integridade operacional agrupadas por Nó, Pod e Hash do modelo de pod. As seguintes definições se aplicam:
-
Um pod corresponde a um grupo de um ou mais contêineres do Docker que compartilham armazenamento e recursos. Um pod é a menor unidade que pode ser implantada em uma plataforma do Kubernetes. Agrupe por pods para verificar se os erros estão relacionados a limitações específicas do pod.
-
Um nó corresponde a um servidor que executa pods. Agrupe por nós para verificar se os erros estão relacionados a limitações específicas do nó.
-
Um hash de modelo de pod é usado para localizar uma versão específica de uma implantação. Agrupar por hash de modelo de pod para verificar se os erros estão relacionados a uma implantação específica.
Principais colaboradores que usam o Amazon EC2
Use as informações sobre os principais colaboradores de aplicações implantadas no Amazon EKS para visualizar métricas de integridade operacional agrupadas por ID da instância e por grupo do Auto Scaling. As seguintes definições se aplicam:
-
Um ID de instância é um identificador exclusivo para a instância do Amazon EC2 executada pelo seu serviço. Agrupe por ID de instância para verificar se os erros estão relacionados a uma instância específica do Amazon EC2.
-
Um grupo do Auto Scaling é uma coleção de instâncias do Amazon EC2 que permite diminuir ou aumentar a escala verticalmente dos recursos necessários para atender às solicitações da aplicação. Agrupe por grupo do Auto Scaling se desejar verificar se os erros têm um escopo limitado para as instâncias do grupo.
Principais colaboradores que usam uma plataforma personalizada
Use as informações sobre os principais colaboradores para aplicações implantadas usando instrumentação personalizada para visualizar as métricas de integridade operacional agrupadas por Nome do host. As seguintes definições se aplicam:
-
Um nome de host identifica um dispositivo, como um endpoint ou uma instância do Amazon EC2, que está conectado a uma rede. Agrupe por nome do host para verificar se os erros estão relacionados a um dispositivo físico ou virtual específico.
Confira os principais colaboradores no Log Insights e no Container Insights
Visualize e modifique a consulta automática que gerou as métricas para os principais colaboradores no Log Insights. Visualize as métricas de desempenho de infraestrutura por grupos específicos, como pods ou nós, no Container Insights. Você pode classificar clusters, nós ou workloads por consumo de recursos e identificar anomalias com rapidez ou mitigar riscos de forma proativa antes que a experiência do usuário final seja afetada. A seguinte imagem mostra como selecionar essas opções:
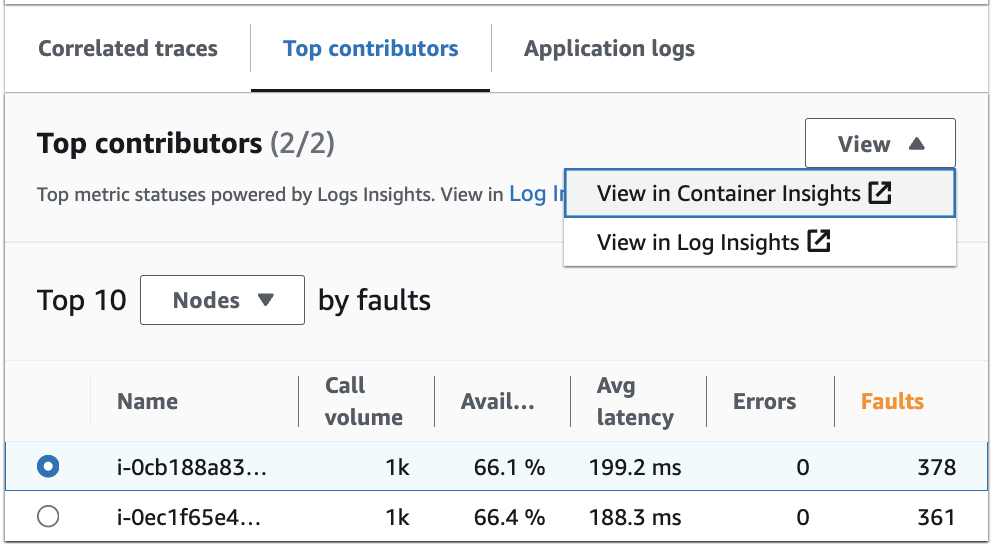
No Container Insights, é possível visualizar métricas para o contêiner do Amazon EKS ou do Amazon ECS que são específicas para o agrupamento dos seus principais colaboradores. Por exemplo, se você realizou o agrupamento por pod para um contêiner do EKS com a finalidade de gerar os principais colaboradores, o Container Insights mostrará métricas e estatísticas filtradas para seu pod.
No Log Insights, é possível modificar a consulta que gerou as métricas em Principais colaboradores ao usar as seguintes etapas:
-
Selecione Visualizar no Log Insights. A página Log Insights aberta contém uma consulta gerada automaticamente e as seguintes informações:
-
O nome do grupo de clusters do log.
-
A operação que estava sendo investigada com o CloudWatch.
-
O agregado da métrica de integridade operacional com a qual você interagiu no gráfico.
Os resultados do log são filtrados automaticamente para mostrar os dados dos últimos cinco minutos antes de você selecionar o ponto de dados no gráfico do serviço.
-
-
Para editar a consulta, substitua o texto gerado pelas suas alterações. Além disso, é possível usar o Gerador de consultas para ajudar na geração de uma nova consulta ou atualizar a consulta existente.
Logs de aplicações
Use a consulta na guia Logs de aplicações para gerar informações registradas em log para seu grupo de logs ou serviço atuais e inserir um carimbo de data/hora. Um grupo de logs é um grupo de fluxos de logs que você pode definir ao configurar a aplicação.
Use um grupo de logs para organizar os logs com características semelhantes, incluindo as seguintes:
-
Captura de logs de uma organização, origem ou função específica.
-
Captura de logs que são acessados por um usuário específico.
-
Captura de logs de um período específico.
Use esses fluxos de log para rastrear grupos ou períodos específicos. Além disso, é possível configurar regras de monitoramento, alarmes e notificações para esses grupos de logs. Para obter mais informações sobre os grupos de logs, consulte Working with log groups and log streams.
A consulta de logs de aplicações retorna os logs, os padrões de texto recorrentes e as visualizações gráficas para os grupos de logs.
Para executar a consulta, selecione Executar consulta no Logs Insights para executar a consulta gerada automaticamente ou modificá-la. Para editar a consulta, substitua o texto gerado automaticamente pelas suas alterações. Além disso, é possível usar o Gerador de consultas para ajudar na geração de uma nova consulta ou atualizar a consulta existente.
A seguinte imagem mostra a consulta de amostra que é gerada automaticamente com base no ponto selecionado no gráfico de operações de serviço:

Na imagem apresentada anteriormente, o CloudWatch detectou automaticamente o grupo de logs associado ao ponto selecionado e o incluiu em uma consulta gerada.
Visualizar as dependências do serviço
Escolha a guia Dependências para exibir a tabela Dependências e um conjunto de métricas para as dependências de todas as operações de serviço ou de uma única operação. A tabela contém uma lista de dependências descobertas pelo Application Signals, incluindo métricas de status de SLI, latência, volume de chamadas, taxa de falhas, taxa de erros e disponibilidade.
Na parte superior da página, escolha uma operação na lista com ícone de seta para baixo para visualizar as dependências ou escolha Todas para obter as dependências para todas as operações.
Filtre a tabela para facilitar a descoberta do que você está procurando ao escolher uma ou mais propriedades na caixa de texto do filtro. Ao escolher cada propriedade, você será guiado pelos critérios do filtro e verá o filtro completo abaixo da caixa de texto do filtro. Escolha Limpar filtros a qualquer momento para remover o filtro da tabela. Selecione Agrupar por dependência no canto superior direito da tabela para agrupar dependências por nome de serviço e de operação. Quando o agrupamento estiver ativado, expanda ou recolha um grupo de dependências com o ícone + ao lado do nome da dependência.

A coluna Dependência exibe o nome do serviço de dependência, enquanto a coluna Operação remota exibe o nome da operação do serviço. A coluna Status do SLI exibe o número de SLIs íntegros ou não íntegros junto com o número total de SLIs para cada dependência. Ao chamar serviços da AWS, a coluna Destino exibe o recurso da AWS, como uma tabela do DynamoDB ou uma fila do Amazon SNS.
Para selecionar uma dependência, selecione a opção ao lado de uma dependência na tabela Dependências. Isso mostra um conjunto de gráficos que exibem métricas detalhadas para o volume de chamadas, a disponibilidade, as falhas e os erros. Passe o cursor sobre um ponto em um gráfico para visualizar um pop-up que contém informações adicionais. Selecione um ponto em um gráfico para abrir um painel de diagnóstico que mostra rastreamentos correlacionados para o ponto selecionado no gráfico. Escolha um ID de rastreamento na tabela Rastreamentos correlacionados para abrir a página de detalhes do Rastreamento do X-Ray para o rastreamento selecionado.
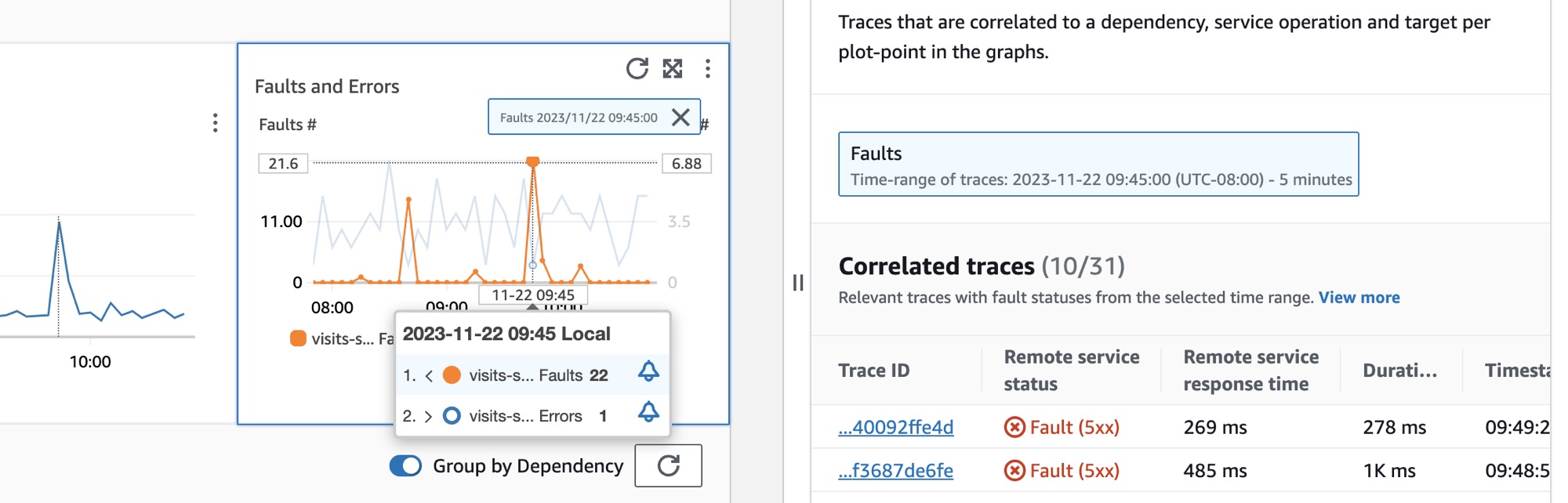
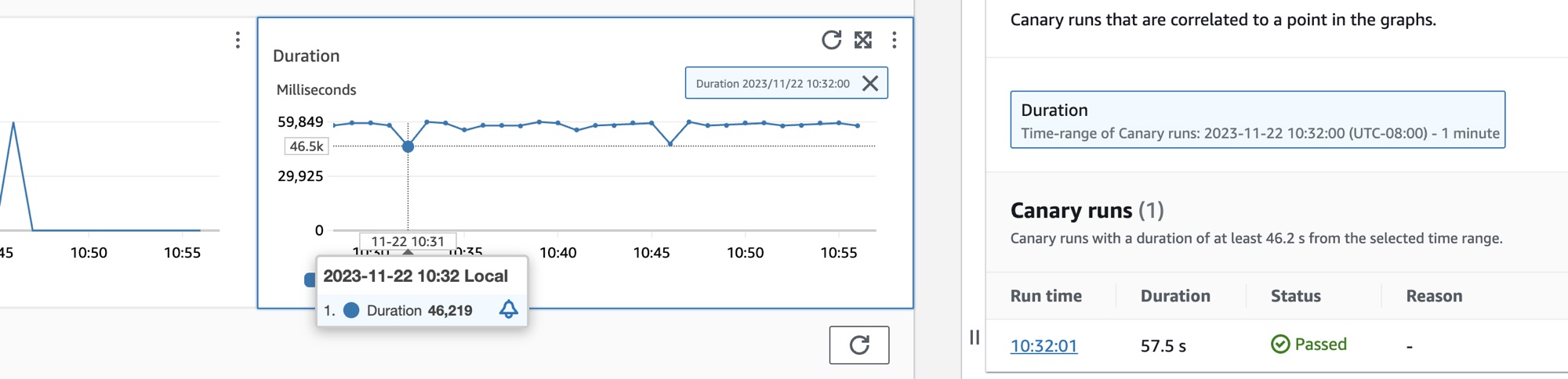
Visualizar os canários do Synthetics
Escolha a guia Canários do Synthetics para exibir a tabela Canários do Synthetics e um conjunto de métricas para cada canário na tabela. A tabela inclui métricas para porcentagem de sucesso, duração média, execuções e taxa de falhas. Somente os canários que estão habilitados para rastreamento no AWS X-Ray são exibidos.
Use a caixa de texto de filtro na tabela de canários do Synthetics para localizar o canário de seu interesse. Cada filtro criado aparece abaixo da caixa de texto de filtro. Escolha Limpar filtros a qualquer momento para remover o filtro da tabela.
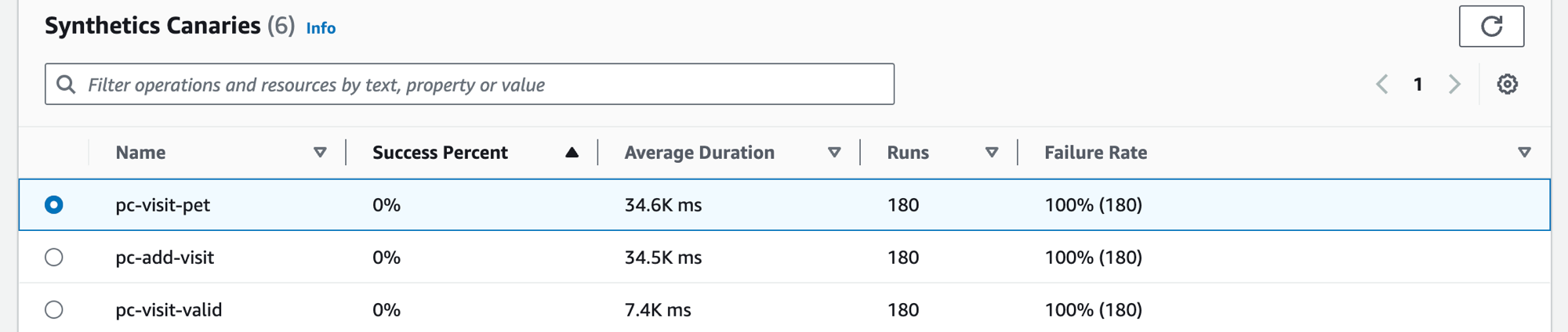
Selecione o botão de opção ao lado do nome do canário para obter um conjunto de guias que contém gráficos detalhados de métricas, incluindo a porcentagem de êxito, os erros e a duração. Passe o cursor sobre um ponto em um gráfico para visualizar um pop-up que contém informações adicionais. Selecione um ponto em um gráfico para abrir um painel de diagnóstico que mostra as execuções do canário que estão correlacionadas ao ponto selecionado. Selecione uma execução do canário e escolha o Runtime para visualizar os artefatos para a execução do canário selecionada, incluindo os logs, os arquivos em HTTP Archive (HAR), as capturas de tela e as etapas sugeridas para ajudar na solução de problemas. Escolha Saiba mais para abrir a página Canários do Cloudwatch Synthetics ao lado de Execuções do canário.
Visualizar as páginas de clientes
Escolha a guia Páginas de clientes para exibir uma lista de páginas da Web de clientes que chamam o serviço. Use o conjunto de métricas para a página de cliente selecionada a fim de medir a qualidade da experiência do cliente na interação com um serviço ou com uma aplicação. Essas métricas incluem carregamentos de páginas, sinais vitais da Web e erros.
Para exibir as páginas de clientes na tabela, é necessário configurar o cliente Web do CloudWatch RUM para o rastreamento do X-Ray e ativar as métricas do Application Signals para as páginas de clientes. Escolha Gerenciar páginas para selecionar quais páginas estão habilitadas para as métricas do Application Signals.
Use a caixa de texto do filtro para localizar a página de cliente ou o monitoramento de aplicações de seu interesse abaixo da caixa de texto do filtro. Escolha Limpar filtros para remover o filtro da tabela. Selecione Agrupar por cliente para agrupar páginas de clientes por cliente. Depois do agrupamento, escolha o ícone + ao lado do nome de um cliente para expandir a linha e ver todas as páginas desse cliente.
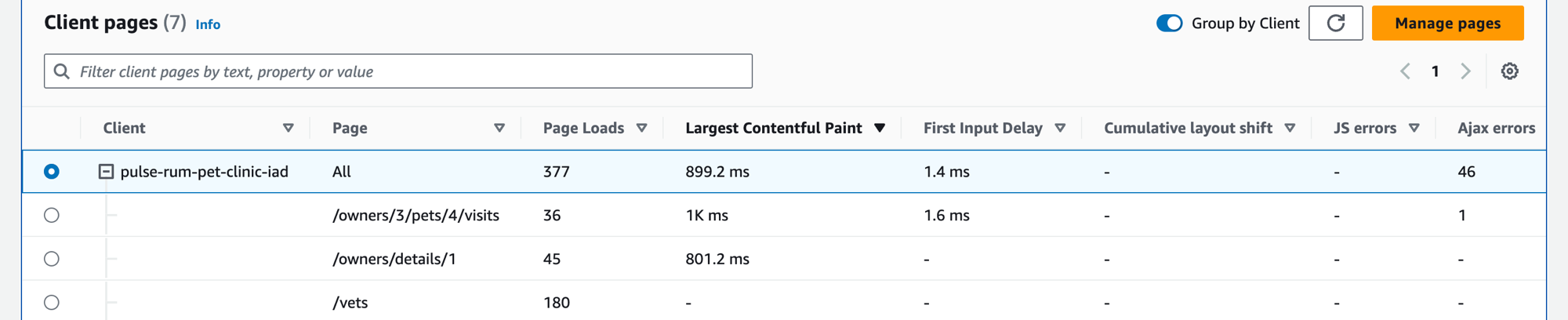
Para selecionar uma página de cliente, selecione a opção ao lado da página de cliente na tabela Páginas de clientes. Você verá um conjunto de gráficos que exibem métricas detalhadas. Passe o cursor sobre um ponto em um gráfico para visualizar um pop-up que contém informações adicionais. Selecione um ponto em um gráfico para abrir um painel de diagnóstico que mostra os eventos correlacionados de navegação de desempenho para o ponto selecionado no gráfico. Escolha um ID de evento na lista de eventos de navegação para abrir a visualização da página do CloudWatch RUM para o evento escolhido.

nota
Para ver erros de Asynchronous JavaScript And XML (AJAX) nas suas páginas de clientes, use a versão 1.15 ou mais recente do cliente Web do CloudWatch RUM.
Podem ser mostradas até cem operações, canários e páginas de clientes, e até 250 dependências, por serviço.
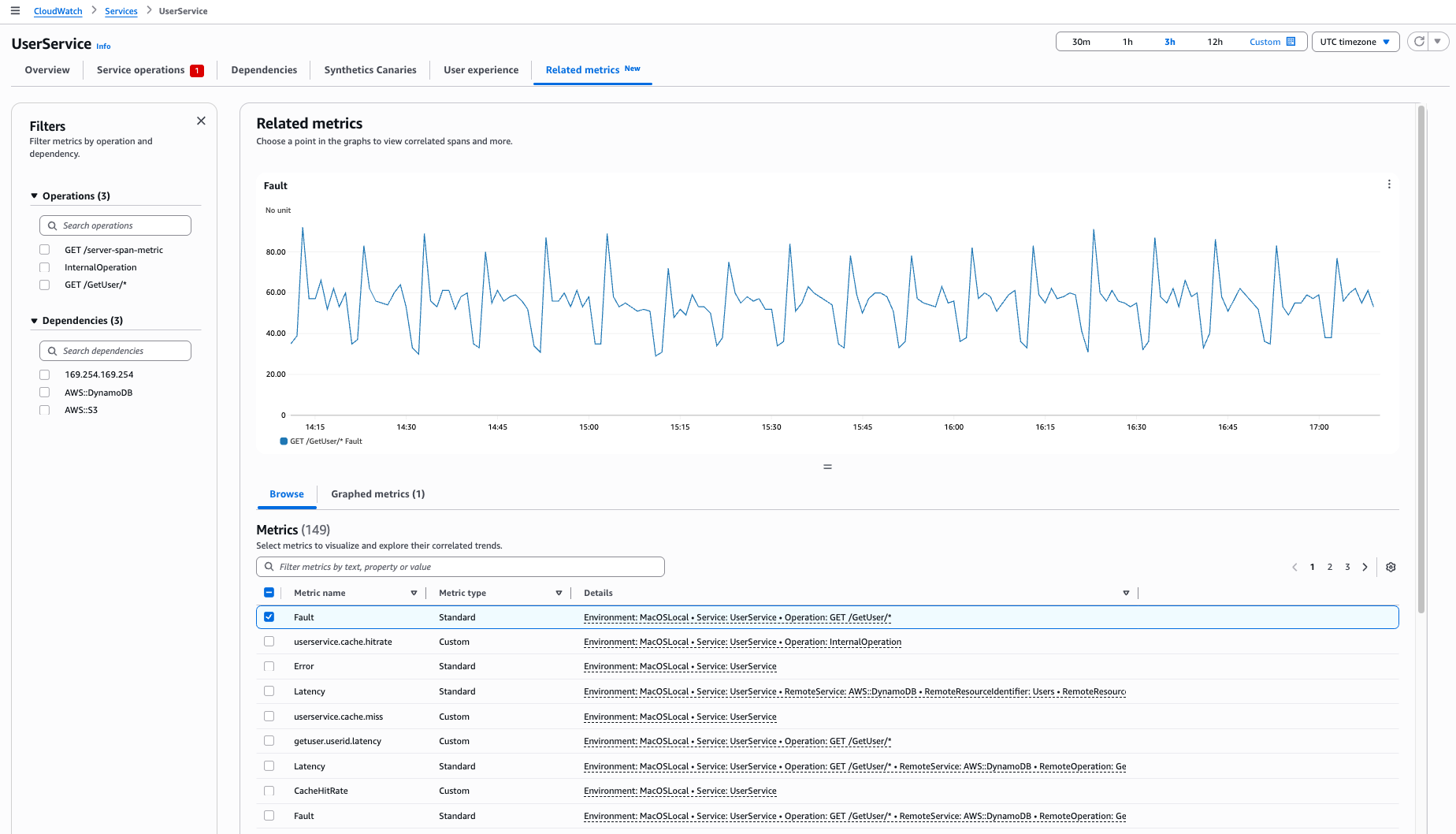
Visualizar métricas relacionadas
Use a guia Métricas relacionadas para visualizar várias métricas, identificar padrões de correlação e determinar as causas raiz dos problemas.
A tabela de métricas mostra três tipos de métricas:
Métricas padrão: o Application Signals coleta métricas de aplicações padrão usando os serviços que descobre. Para obter mais informações, consulte Coleta de métricas de aplicações padrão
Métricas de runtime: o Application Signals usa o SDK do AWS Distro para OpenTelemetry para coletar automaticamente métricas compatíveis com o OpenTelemetry das aplicações Java e Python. Para obter mais informações, consulte Métricas de runtime
Métricas personalizadas: o Application Signals permite que você gere métricas personalizadas da sua aplicação. Para obter mais informações, consulte . Métricas personalizadas com o Application Signals
Você pode acessar a guia Métricas relacionadas nas guias Visão geral do serviço, Operações do serviço, Dependências, Canários sintéticos e RUM.
-
O painel de navegação esquerdo começa com todas as operações e dependências desmarcadas
-
O gráfico mostra inicialmente a métrica de falhas da operação com a maior taxa de falhas
Antes de começar a análise de correlação, verifique se você tem pontos de dados visíveis em Operações do serviço ou Dependências. Para analisar as correlações:
Abra a página Operações do serviço ou Dependências.
Selecione um ponto de dados em qualquer grafo.
No painel direito, escolha Correlacionar com outras métricas.
Na guia Métricas relacionadas que é exibida, você verá:
Sua operação ou dependência selecionada na navegação à esquerda
Sua métrica selecionada em grafos na tabela Procurar métricas
Extensões correlacionadas quando você seleciona um ponto de dados
Para criar grafos de várias métricas, selecione uma ou mais métricas na visualização Procurar na guia Métricas relacionadas. Escolha Métricas em grafos para ver todas as métricas em grafos.
Para filtrar métricas, use os filtros do painel esquerdo para se concentrar em operações ou dependências específicas e use a barra de filtro do cabeçalho da tabela para pesquisar por nome, tipo ou outros atributos. Essas opções de filtragem ajudam você a detectar padrões e solucionar problemas com mais eficiência.
Para analisar as métricas relacionadas em detalhes, selecione um ponto de dados na guia Métricas relacionadas. Você pode então visualizar:
Principais colaboradores: analisa as métricas executando as consultas do CloudWatch Logs Insights. Essas consultas processam registros do Enhanced Metrics Format (EMF) que contêm os principais atributos para uma análise detalhada do seguinte:
Medidas de latência
Ocorrências de falhas
Métricas de disponibilidade de serviços
As seguintes métricas não são compatíveis com os principais colaboradores:
Métricas do OTel
Métricas de extensão do lado do servidor
Você pode ver os principais colaboradores das métricas de RED e de extensão do lado do cliente.
Extensões correlacionadas: a seção Extensões correlacionadas funciona de forma consistente com a guia Operações do serviço. Para ajudar você a identificar rastreamentos e métricas relacionados, o mecanismo de correlação funciona da seguinte forma:
Compara nomes de métricas com atributos de extensão
Identifica padrões de correspondência durante o período selecionado
Exibe informações de rastreamento relevantes
Para analisar com eficácia suas métricas e extensões juntas, você precisa entender como os diferentes tipos de métricas se correlacionam. As principais limitações são:
As métricas do OTel não se correlacionam com extensões porque usam sistemas de nomenclatura independentes
Para correlacionar métricas de extensão do lado do cliente ou do servidor com extensões:
Inclua um campo de dimensão de serviço em sua configuração
Sem essa dimensão de serviço, você não pode correlacionar essas métricas com extensões
Aplicações de logs: para obter informações sobre aplicações de logs, consulte Logs de aplicações
