Usar grupos de segurança do AD para controle de acesso do Aurora PostgreSQL
Nas versões 14.10 e 15.5 do Aurora PostgreSQL, o controle de acesso do Aurora PostgreSQL pode ser gerenciado utilizando grupos de segurança do AWS Directory Service for Microsoft Active Directory (AD). As versões anteriores do Aurora PostgreSQL são compatíveis com a autenticação baseada em Kerberos com AD somente para usuários individuais. Cada usuário do AD precisava ser provisionado explicitamente no cluster de banco de dados para obter acesso.
Em vez de provisionar explicitamente cada usuário do AD no cluster de banco de dados com base nas necessidades de negócios, é possível utilizar os grupos de segurança do AD, conforme explicado abaixo:
Os usuários do AD são membros de vários grupos de segurança do AD em um Active Directory. Eles não são ditados pelo administrador do cluster de banco de dados, mas são baseados nos requisitos de negócios e são gerenciados por um administrador do AD.
-
Os administradores de clusters de banco de dados criam perfis de banco de dados em instâncias de banco de dados com base nos requisitos de negócios. Esses perfis de banco de dados podem ter permissões ou privilégios diferentes.
-
Os administradores de clusters de banco de dados configuram um mapeamento dos grupos de segurança do AD para os perfis de banco de dados por cluster.
-
Os usuários do banco de dados podem acessar clusters de banco de dados usando as credenciais do AD. O acesso é baseado na associação ao grupo de segurança do AD. Os usuários do AD ganham ou perdem o acesso automaticamente com base nas associações ao grupo do AD.
Pré-requisitos
Verifique se você tem o seguinte antes de configurar a extensão para grupos de segurança do AD:
-
Configurar a autenticação Kerberos para clusters de banco de dados do PostgreSQL. Para ter mais informações, consulte Configurar a autenticação Kerberos para clusters de banco de dados do PostgreSQL.
nota
Para grupos de segurança do AD, ignore a Etapa 7: Criar usuários do PostgreSQL para entidades principais do Kerberos neste procedimento de configuração.
Gerenciar um cluster de banco de dados em um domínio. Para ter mais informações, consulte Gerenciar um cluster de banco de dados em um domínio .
Configurar a extensão pg_ad_mapping
O Aurora PostgreSQL agora está fornecendo uma extensão pg_ad_mapping para gerenciar o mapeamento entre grupos de segurança do AD e perfis de banco de dados no cluster do Aurora PostgreSQL. Para ter mais informações sobre as funções fornecidas pelo pg_ad_mapping, consulte Usar funções da extensão pg_ad_mapping.
Para configurar a extensão pg_ad_mapping no cluster de banco de dados do Aurora PostgreSQL, primeiro adicione pg_ad_mapping às bibliotecas compartilhadas no grupo de parâmetros do cluster de banco de dados personalizado para o cluster de banco de dados do Aurora PostgreSQL. Para ter mais informações sobre como criar um grupo de parâmetros de cluster de banco de dados personalizado, consulte Grupos de parâmetros para Amazon Aurora. Depois, instale a extensão pg_ad_mapping. Os procedimentos nesta seção mostram o procedimento. É possível usar o AWS Management Console ou a AWS CLI.
Você deve ter permissões como a função rds_superuser para realizar todas essas tarefas.
As etapas a seguir pressupõem que o cluster de banco de dados do Aurora PostgreSQL esteja associado a um grupo de parâmetros de cluster de banco de dados personalizado.
Como configurar a extensão pg_ad_mapping
Faça login no AWS Management Console e abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. -
No painel de navegação, selecione a instância de gravador do cluster de banco de dados do Aurora PostgreSQL.
-
Abra a guia Configuração para a instância de gravador do cluster de banco de dados do Aurora PostgreSQL. Entre os detalhes da instância, encontre o link Parameter group (Grupo de parâmetros).
-
Clique no link para abrir os parâmetros personalizados associados ao seu cluster de banco de dados do Aurora PostgreSQL.
-
No campo Parameters (Parâmetros), digite
shared_prepara encontrar o parâmetroshared_preload_libraries. -
Selecione Edit parameters (Editar parâmetros) para acessar os valores das propriedades.
-
Adicione
pg_ad_mappingà lista no campo Values (Valores). Use uma vírgula para separar itens na lista de valores.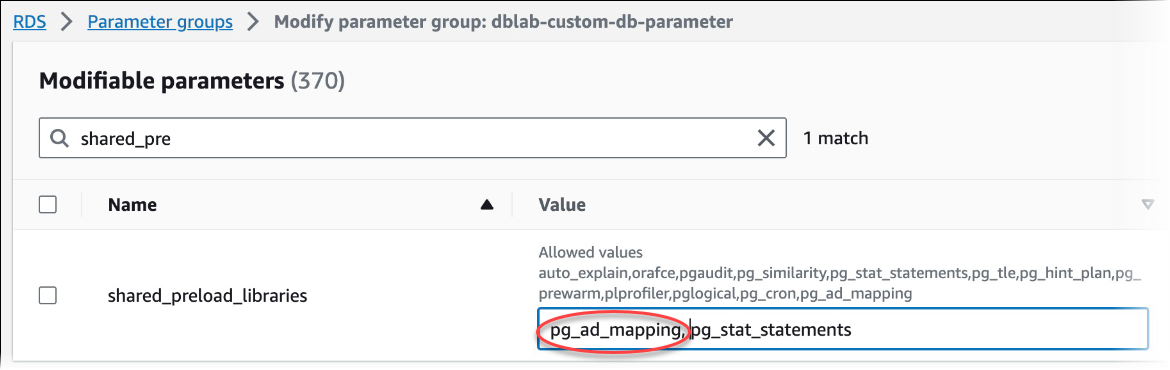
Reinicialize a instância de gravador do cluster de banco de dados do Aurora PostgreSQL para que a alteração no parâmetro
shared_preload_librariestenha efeito.Quando a instância estiver disponível, verifique se
pg_ad_mappingfoi inicializado. Usepsqlpara se conectar à instância de gravador do cluster de banco de dados do Aurora PostgreSQL e depois execute o comando a seguir.SHOW shared_preload_libraries;shared_preload_libraries -------------------------- rdsutils,pg_ad_mapping (1 row)Com
pg_ad_mappinginicializado, agora você pode criar a extensão. É necessário criar a extensão depois de inicializar a biblioteca para começar a usar as funções fornecidas por essa extensão.CREATE EXTENSION pg_ad_mapping;Feche a sessão
psql.labdb=>\q
Como configurar o pg_ad_mapping
Para configurar pg_ad_mapping usando a AWS CLI, chame a operação modify-db-parameter-group para adicionar esse parâmetro ao grupo de parâmetros personalizado, conforme mostrado no procedimento a seguir.
Use o comando AWS CLI a seguir para adicionar
pg_ad_mappingao parâmetroshared_preload_libraries.aws rds modify-db-parameter-group \ --db-parameter-group-namecustom-param-group-name\ --parameters "ParameterName=shared_preload_libraries,ParameterValue=pg_ad_mapping,ApplyMethod=pending-reboot" \ --regionaws-region-
Use o comando AWS CLI a seguir para reinicializar a instância de gravador do cluster de banco de dados do Aurora PostgreSQL para que o pg_ad_mapping seja inicializado.
aws rds reboot-db-instance \ --db-instance-identifierwriter-instance\ --regionaws-region Quando a instância estiver disponível, verifique se a
pg_ad_mappingfoi inicializada. Usepsqlpara se conectar à instância de gravador do cluster de banco de dados do Aurora PostgreSQL e depois execute o comando a seguir.SHOW shared_preload_libraries;shared_preload_libraries -------------------------- rdsutils,pg_ad_mapping (1 row)Com pg_ad_mapping inicializada, agora é possível criar a extensão.
CREATE EXTENSION pg_ad_mapping;Feche a sessão
psqlpara que você possa usar a AWS CLI.labdb=>\q
Recuperar o SID do grupo do Active Directory no PowerShell
Um identificador de segurança (SID) é usado para identificar de forma exclusiva uma entidade principal ou um grupo de segurança. Sempre que uma conta ou um grupo de segurança é criado no Active Directory, um SID é atribuído a ele. Para obter o SID do grupo de segurança do AD no Active Directory, é possível usar o cmdlet Get-ADGroup da máquina cliente Windows que está associada a esse domínio do Active Directory. O parâmetro Identity especifica o nome do grupo do Active Directory para obter o SID correspondente.
O exemplo a seguir exibe o SID do grupo do AD adgroup1.
C:\Users\Admin>Get-ADGroup -Identity adgroup1 | select SIDSID ----------------------------------------------- S-1-5-21-3168537779-1985441202-1799118680-1612
Associar o perfil de banco de dados ao grupo de segurança do AD
É necessário provisionar explicitamente os grupos de segurança do AD no banco de dados como um perfil de banco de dados do PostgreSQL. Um usuário do AD, que faz parte de pelo menos um grupo de segurança do AD provisionado, terá acesso ao banco de dados. Não conceda o rds_ad role ao perfil de banco de dados baseado em segurança do grupo do AD. A autenticação Kerberos para o grupo de segurança será acionada usando o sufixo do nome de domínio, como user1@example.com. Esse perfil de banco de dados não pode usar autenticação por senha ou do IAM para obter acesso ao banco de dados.
nota
Os usuários do AD que têm um perfil de banco de dados correspondente no banco de dados com o perfil rds_ad concedido a eles não podem fazer login como parte do grupo de segurança do AD. Eles obterão acesso por meio do perfil de banco de dados como usuários individuais.
Por exemplo, accounts-group é um grupo de segurança no AD em que você gostaria de provisionar esse grupo de segurança no Aurora PostgreSQL como accounts-role.
| Grupo de segurança do AD | Perfil de banco de dados do PosgreSQL |
|---|---|
| accounts-group | accounts-role |
Ao associar o perfil de banco de dados ao grupo de segurança do AD, é necessário garantir que o perfil de banco de dados tenha o atributo LOGIN definido e tenha o privilégio CONNECT para o banco de dados de login necessário.
postgres =>alter roleaccounts-rolelogin;ALTER ROLEpostgres =>grant connect on databaseaccounts-dbtoaccounts-role;
Agora, o administrador pode continuar criando o mapeamento entre o grupo de segurança do AD e o perfil de banco de dados do PostgreSQL.
admin=>select pgadmap_set_mapping('accounts-group','accounts-role',<SID>,<Weight>);
Para ter informações sobre como recuperar o SID do grupo de segurança do AD, consulte Recuperar o SID do grupo do Active Directory no PowerShell.
Pode haver casos em que um usuário do AD pertença a vários grupos; nesse caso, o usuário do AD herdará os privilégios do perfil de banco de dados, que foi provisionado com o maior peso. Se os dois perfis tiverem o mesmo peso, o usuário do AD herdará os privilégios do perfil de banco de dados correspondentes ao mapeamento que foi adicionado recentemente. A recomendação é especificar pesos que reflitam as permissões/privilégios relativos dos perfis individuais do banco de dados. Quanto maiores as permissões ou os privilégios de um perfil de banco de dados, maior o peso que deve ser associado à entrada de mapeamento. Isso evitará a ambiguidade de dois mapeamentos com o mesmo peso.
A tabela a seguir mostra um exemplo de mapeamento dos grupos de segurança do AD para perfis de banco de dados do Aurora PostgreSQL.
| Grupo de segurança do AD | Perfil de banco de dados do PosgreSQL | Weight |
|---|---|---|
| accounts-group | accounts-role | 7 |
| sales-group | sales-role | 10 |
| dev-group | dev-role | 7 |
No exemplo a seguir, o user1 herdará os privilégios de sales-role, pois ele tem o maior peso, enquanto o user2 herdará os privilégios de dev-role, pois o mapeamento desse perfil foi criado depois de accounts-role, que compartilha o mesmo peso de accounts-role.
| Nome de usuário | Associação a grupos de segurança |
|---|---|
| user1 | accounts-group sales-group |
| user2 | accounts-group dev-group |
Os comandos psql para estabelecer, listar e limpar os mapeamentos são mostrados abaixo. No momento, não é possível modificar uma única entrada de mapeamento. A entrada existente precisa ser excluída e o mapeamento recriado.
admin=>select pgadmap_set_mapping('accounts-group', 'accounts-role', 'S-1-5-67-890', 7);admin=>select pgadmap_set_mapping('sales-group', 'sales-role', 'S-1-2-34-560', 10);admin=>select pgadmap_set_mapping('dev-group', 'dev-role', 'S-1-8-43-612', 7);admin=>select * from pgadmap_read_mapping();ad_sid | pg_role | weight | ad_grp -------------+----------------+--------+--------------- S-1-5-67-890 | accounts-role | 7 | accounts-group S-1-2-34-560 | sales-role | 10 | sales-group S-1-8-43-612 | dev-role | 7 | dev-group (3 rows)
Registro em log e auditoria de identidade de usuário do AD
Use o comando a seguir para determinar o perfil de banco de dados herdado pelo usuário atual ou da sessão:
postgres=>select session_user, current_user;session_user | current_user -------------+-------------- dev-role | dev-role (1 row)
Para determinar a identidade principal de segurança do AD, use o seguinte comando:
postgres=>select principal from pg_stat_gssapi where pid = pg_backend_pid();principal ------------------------- user1@example.com (1 row)
No momento, a identidade do usuário do AD não está visível nos logs de auditoria. O parâmetro log_connections pode ser habilitado para registrar o estabelecimento da sessão de banco de dados. Para ter mais informações, consulte log_connections. A saída para isso inclui a identidade do usuário do AD, conforme mostrado abaixo. O PID de back-end associado a essa saída pode então ajudar a atribuir ações de volta ao usuário real do AD.
pgrole1@postgres:[615]:LOG: connection authorized: user=pgrole1 database=postgres application_name=psql GSS (authenticated=yes, encrypted=yes, principal=Admin@EXAMPLE.COM)
Limitações
O Microsoft Entra ID conhecido como Azure Active Directory não é aceito.
Usar funções da extensão pg_ad_mapping
A extensão pg_ad_mapping oferecia compatibilidade com as seguintes funções:
pgadmap_set_mapping
Essa função estabelece o mapeamento entre o grupo de segurança do AD e o perfil de banco de dados com um peso associado.
Sintaxe
pgadmap_set_mapping(
ad_group,
db_role,
ad_group_sid,
weight)
Argumentos
| Parâmetro | Descrição |
|---|---|
| ad_group | Nome do grupo do AD. O valor não pode ser uma string nula ou vazia. |
| db_role | Perfil do banco de dados a ser associado ao grupo do AD especificado. O valor não pode ser uma string nula ou vazia. |
| ad_group_sid | Identificador de segurança usado para identificar exclusivamente o grupo do AD. O valor começa com “S-1-” e não pode ser uma string nula ou vazia. Para ter mais informações, consulte Recuperar o SID do grupo do Active Directory no PowerShell. |
| weight | Peso associado ao perfil de banco de dados. O perfil com o maior peso tem precedência quando o usuário é membro de vários grupos. O valor padrão do peso é 1. |
Tipo de retorno
None
Observações de uso
Essa função adiciona um novo mapeamento do grupo de segurança do AD para o perfil de banco de dados. Ela só pode ser executada na instância de banco de dados principal do cluster de banco de dados por um usuário com o privilégio de rds_superuser.
Exemplos
postgres=>select pgadmap_set_mapping('accounts-group','accounts-role','S-1-2-33-12345-67890-12345-678',10);pgadmap_set_mapping (1 row)
pgadmap_read_mapping
Essa função lista os mapeamentos entre o grupo de segurança do AD e o perfil de banco de dados definidos com a função pgadmap_set_mapping.
Sintaxe
pgadmap_read_mapping()
Argumentos
None
Tipo de retorno
| Parâmetro | Descrição |
|---|---|
| ad_group_sid | Identificador de segurança usado para identificar exclusivamente o grupo do AD. O valor começa com “S-1-” e não pode ser uma string nula ou vazia. Para ter mais informações, consulte Recuperar o SID do grupo do Active Directory no PowerShell.accounts-role@example.com |
| db_role | Perfil do banco de dados a ser associado ao grupo do AD especificado. O valor não pode ser uma string nula ou vazia. |
| weight | Peso associado ao perfil de banco de dados. O perfil com o maior peso tem precedência quando o usuário é membro de vários grupos. O valor padrão do peso é 1. |
| ad_group | Nome do grupo do AD. O valor não pode ser uma string nula ou vazia. |
Observações de uso
Chame essa função para listar todos os mapeamentos disponíveis entre o grupo de segurança do AD e o perfil de banco de dados.
Exemplos
postgres=>select * from pgadmap_read_mapping();ad_sid | pg_role | weight | ad_grp ------------------------------------+---------------+--------+------------------ S-1-2-33-12345-67890-12345-678 | accounts-role | 10 | accounts-group (1 row) (1 row)
pgadmap_reset_mapping
Essa função redefine um ou todos os mapeamentos definidos com a função pgadmap_set_mapping.
Sintaxe
pgadmap_reset_mapping(
ad_group_sid,
db_role,
weight)
Argumentos
| Parâmetro | Descrição |
|---|---|
| ad_group_sid | Identificador de segurança usado para identificar exclusivamente o grupo do AD. |
| db_role | Perfil do banco de dados a ser associado ao grupo do AD especificado. |
| weight | Peso associado ao perfil de banco de dados. |
Se nenhum argumento for fornecido, todos os mapeamentos entre grupos do AD e perfis de banco de dados serão redefinidos. Todos os argumentos precisam ser fornecidos ou nenhum.
Tipo de retorno
None
Observações de uso
Chame essa função para excluir um mapeamento entre um grupo específico do AD e um perfil de banco de dados ou para redefinir todos os mapeamentos. Essa função só pode ser executada na instância de banco de dados principal do cluster de banco de dados por um usuário com o privilégio de rds_superuser.
Exemplos
postgres=>select * from pgadmap_read_mapping();ad_sid | pg_role | weight | ad_grp --------------------------------+--------------+-------------+------------------- S-1-2-33-12345-67890-12345-678 | accounts-role| 10 | accounts-group S-1-2-33-12345-67890-12345-666 | sales-role | 10 | sales-group (2 rows)postgres=>select pgadmap_reset_mapping('S-1-2-33-12345-67890-12345-678', 'accounts-role', 10);pgadmap_reset_mapping (1 row)postgres=>select * from pgadmap_read_mapping();ad_sid | pg_role | weight | ad_grp --------------------------------+--------------+-------------+--------------- S-1-2-33-12345-67890-12345-666 | sales-role | 10 | sales-group (1 row)postgres=>select pgadmap_reset_mapping();pgadmap_reset_mapping (1 row)postgres=>select * from pgadmap_read_mapping();ad_sid | pg_role | weight | ad_grp --------------------------------+--------------+-------------+-------------- (0 rows)
