Usar métricas do Amazon CloudWatch para analisar o uso de recursos do Aurora PostgreSQL
O Aurora envia dados de métrica automaticamente para o CloudWatch em períodos de um minuto. Você pode analisar o uso de recursos do Aurora PostgreSQL usando métricas do CloudWatch. Você pode avaliar o throughput e o uso da rede com as métricas.
Avaliar o throughput da rede com o CloudWatch
Quando o uso do sistema se aproxima dos limites de recursos do seu tipo de instância, o processamento pode ficar lento. Você pode usar o CloudWatch Logs Insights para monitorar o uso dos recursos de armazenamento e garantir que recursos suficientes estejam disponíveis. Quando necessário, você pode modificar a instância de banco de dados para uma classe de instância maior.
O processamento do armazenamento do Aurora pode ser lento devido a:
-
Largura de banda da rede insuficiente entre o cliente e a instância de banco de dados.
-
Largura de banda da rede insuficiente para o subsistema de armazenamento.
-
Uma workload grande para seu tipo de instância.
Você pode consultar o CloudWatch Logs Insights para gerar um gráfico do uso dos recursos de armazenamento do Aurora para monitorar os recursos. O gráfico mostra a utilização e as métricas da CPU para ajudar você a decidir se deseja aumentar a escala verticalmente para um tamanho de instância maior. Para obter mais informações sobre a sintaxe de consulta do CloudWatch Logs Insights, consulte Sintaxe de consulta do CloudWatch Logs Insights.
Para usar o CloudWatch, você precisa exportar seus arquivos de log do Aurora PostgreSQL para o CloudWatch. Você também pode modificar o cluster existente para exportar logs para o CloudWatch. Para obter informações sobre como exportar logs para o CloudWatch, consulte Ativar a opção de publicação de logs no Amazon CloudWatch.
Você precisa do Resource ID (ID do recurso) da sua instância de banco de dados para consultar o CloudWatch Logs Insights. O Resource ID (ID do recurso) está disponível na guia Configuration (Configuração) em seu console:
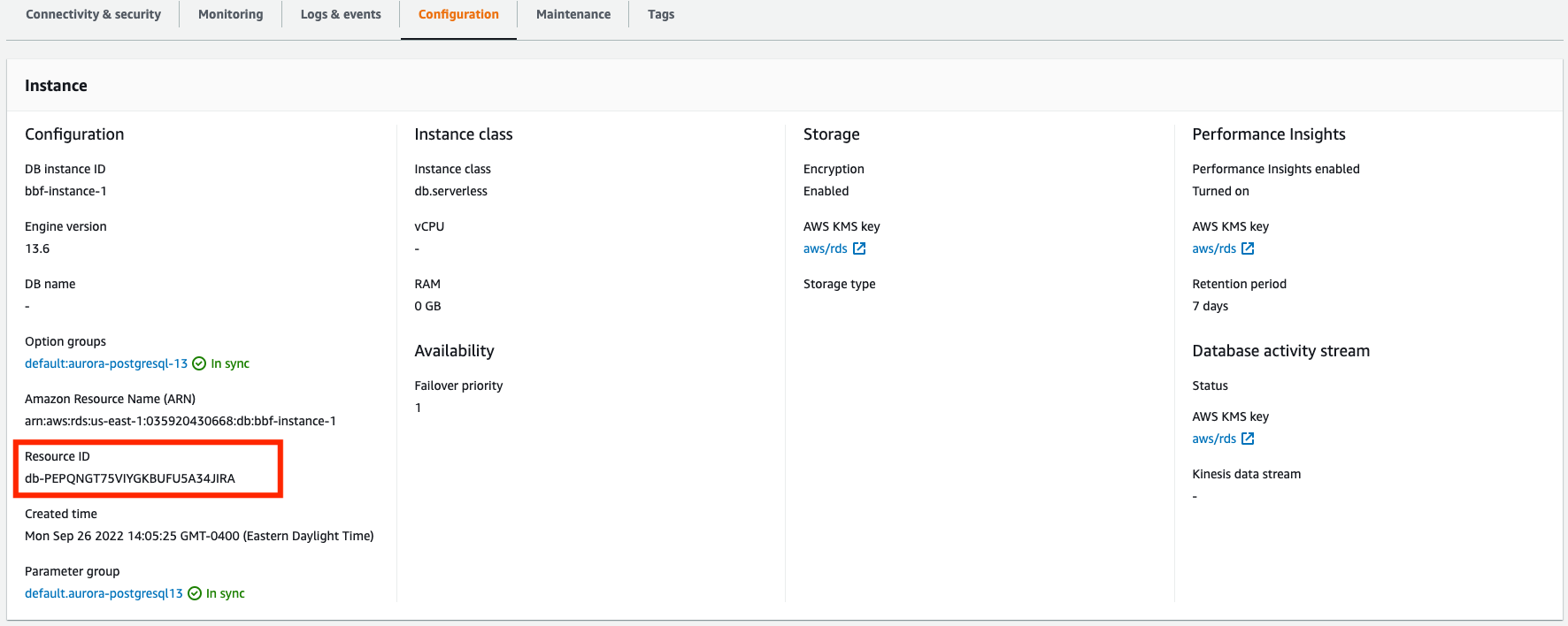
Para consultar seus arquivos de log a fim de obter métricas de armazenamento de recursos:
Abra o console do CloudWatch, em https://console.aws.amazon.com/cloudwatch/
. A página inicial de visão geral do CloudWatch é exibida.
-
Se necessário, altere a Região da AWS. Na barra de navegação, selecione a Região da AWS na qual seus recursos da AWS estão localizados. Para obter mais informações, consulte Regiões e endpoints.
-
No painel de navegação, escolha Logs e selecione Logs Insights.
A página Logs Insights é exibida.
-
Selecione os arquivos de log na lista suspensa para analisar.
-
Insira a seguinte consulta no campo, substituindo
<resource ID>pelo ID do recurso do seu cluster de banco de dados:filter @logStream = <resource ID> | parse @message "\"Aurora Storage Daemon\"*memoryUsedPc\":*,\"cpuUsedPc\":*," as a,memoryUsedPc,cpuUsedPc | display memoryUsedPc,cpuUsedPc #| stats avg(xcpu) as avgCpu by bin(5m) | limit 10000 -
Clique em Run query (Executar consulta).
O gráfico de utilização do armazenamento é exibido.
A imagem a seguir fornece a página Logs Insights e a exibição do gráfico.

Avaliação do uso de instâncias de banco de dados para Aurora PostgreSQL com métricas do CloudWatch
Você pode usar as métricas do CloudWatch para monitorar o throughput de sua instância e descobrir se sua classe de instância fornece recursos suficientes para suas aplicações. Para obter informações sobre os limites da classe da sua instância de banco de dados, acesse Especificações de hardware para classes de instância de banco de dados para o Aurora e localize as especificações da sua classe de instância de banco de dados para descobrir a performance da sua rede.
Se o uso da sua instância de banco de dados estiver próximo do limite da classe da instância, a performance poderá começar a diminuir. As métricas do CloudWatch podem confirmar essa situação para que você possa planejar o aumento vertical manual da escala para uma classe de instância maior.
Combine os seguintes valores de métricas do CloudWatch para descobrir se você está se aproximando do limite da classe da instância:
-
NetworkThroughput: o throughput de rede recebido e transmitido pelos clientes para cada instância no cluster de bancos de dados do Aurora. Esse valor de throughput não inclui o tráfego de rede entre instâncias no cluster de banco de dados e o volume do cluster.
-
StorageNetworkThroughput: o throughput da rede recebido e enviado ao subsistema de armazenamento do Aurora por cada instância no cluster de banco de dados do Aurora.
Adicione NetworkThroughput a StorageNetworkThroughput para encontrar o throughput da rede recebido e enviado ao subsistema de armazenamento do Aurora por cada instância no cluster de banco de dados do Aurora. O limite da classe de instância para sua instância deve ser maior do que a soma dessas duas métricas combinadas.
Você pode usar as seguintes métricas para analisar detalhes adicionais do tráfego de rede das aplicações clientes ao enviar e receber:
-
NetworkReceiveThroughput: a quantidade de throughput de rede recebida dos clientes por cada instância no cluster de banco de dados do Aurora PostgreSQL. Essa taxa de transferência não inclui o tráfego de rede entre instâncias no cluster de banco de dados do e o volume do cluster.
-
NetworkTransmitThroughput: a quantidade de throughput de rede enviada aos clientes por cada instância no cluster de bancos de dados do Aurora. Essa taxa de transferência não inclui o tráfego de rede entre instâncias no cluster de banco de dados do e o volume do cluster.
-
StorageNetworkReceiveThroughput: a quantidade de throughput de rede recebida do subsistema de armazenamento do Aurora por cada instância no cluster de banco de dados.
-
StorageNetworkTransmitThroughput: a quantidade de throughput de rede enviada ao subsistema de armazenamento do Aurora por cada instância no cluster de banco de dados.
Adicione todas essas métricas para avaliar como o uso da rede se compara ao limite da classe da instância. O limite da classe de instância deve ser maior do que a soma dessas métricas combinadas.
Os limites de rede e a utilização da CPU para armazenamento são mútuos. Quando o throughput de rede aumenta, a utilização da CPU também aumenta. O monitoramento do uso da CPU e da rede fornece informações sobre como e por que os recursos estão sendo esgotados.
Para ajudar a minimizar o uso da rede, você pode considerar:
-
Usar uma classe de instância maior.
-
Usar estratégias de particionamento
pg_partman. -
Dividir as solicitações de gravação em lotes para reduzir o total de transações.
-
Direcionar a workload somente leitura para uma instância somente leitura.
-
Excluir todos os índices não utilizados.
-
Verificar se há objetos inchados e VACUUM. Em caso de inchaço severo, use a extensão
pg_repackpara PostgreSQL. Para obter mais informações sobrepg_repack, consulte Reorganize tables in PostgreSQL databases with minimal locks(Reorganizar tabelas em bancos de dados PostgreSQL com bloqueios mínimos).
