Marcar recursos do Amazon Aurora e do Amazon RDS
Uma tag do Amazon RDS é um par de nome-valor que você define e associa a um recurso do Amazon RDS, como uma instância ou um snapshot de banco de dados. O nome é referido como chave. Opcionalmente, é possível fornecer um valor para a chave.
Você pode usar o AWS Management Console, a AWS CLI ou a API do Amazon RDS para adicionar, listar e excluir tags em recursos do Amazon RDS. Ao usar a CLI ou a API, forneça o nome do recurso da Amazon (ARN) do recurso do RDS com o qual deseja trabalhar. Para obter mais informações sobre a criação de um ARN, consulte Criar um ARN para o Amazon RDS.
É possível usar etiquetas para adicionar metadados aos recursos do Aurora e Amazon RDS. Você pode usar as tags para adicionar suas próprias anotações sobre instâncias de banco de dados, snapshots, Aurora clusters e assim por diante. Fazer isso pode ajudar você a documentar os recursos do Aurora e Amazon RDS. Você também pode usar as tags com procedimentos de manutenção automatizada.
Especificamente, você pode usar essas tags com políticas do IAM. É possível usá-las para gerenciar o acesso aos recursos do Aurora e Amazon RDS e controlar quais ações podem ser aplicadas a esses recursos. Você também pode usar essas tags para monitorar custos agrupando despesas de recursos marcados com tags semelhantes.
É possível marcar os seguintes recursos do Aurora e do Amazon RDS:
Instâncias de banco de dados
clusters de banco de dados
Clusters globais do Aurora
Endpoints do cluster de banco de dados
Réplicas de leitura
DB snapshots
Snapshots de cluster de banco de dados
Instâncias de bancos de dados reservadas
Assinaturas de eventos
Grupos de opções de banco de dados
Grupos de parâmetros do banco de dados
Grupos de parâmetros de cluster de banco de dados
Grupos de sub-redes de banco de dados
RDS Proxies
Endpoint do RDS Proxy
Implantações azuis/verdes
Integrações ETL zero
nota
Atualmente, você não pode etiquetar RDS Proxies e endpoints do RDS Proxy usando o AWS Management Console.
Tópicos
Por que usar tags de recurso do Amazon RDS?
É possível usar tags para fazer o seguinte:
-
Categorize recursos do RDS por aplicação, projeto, departamento, ambiente e assim por diante. Por exemplo, é possível usar uma chave de tag para definir uma categoria, na qual o valor da tag é um item nessa categoria. É possível criar a tag
environment=prod. Ou você pode definir uma chave de tag comoprojecte um valor de tag deSalix, o que indica que um recurso do Amazon RDS está atribuído ao projeto Salix. -
Automatize tarefas de gerenciamento de recursos. Por exemplo, é possível criar uma janela de manutenção para instâncias marcadas com
environment=prodque seja diferente da janela para instâncias marcadas comenvironment=test. Também é possível configurar snapshots de banco de dados automáticos para instâncias marcadas comenvironment=prod. -
Controle o acesso aos recursos do RDS em uma política do IAM. Faça isso usando a chave de condição global
aws:ResourceTag/. Por exemplo, uma política pode permitir que somente usuários do grupotag-keyDBAdminmodifiquem instâncias de banco de dados marcadas comenvironment=prod. Consulte informações sobre como gerenciar o acesso a recursos marcados com políticas do IAM em Gerenciamento de identidade e acesso no Amazon Aurora e em Controlar o acesso aos recursos da AWS no Guia do usuário do AWS Identity and Access Management. -
Monitore recursos com base em uma tag. Por exemplo, é possível criar um painel do Amazon CloudWatch para instâncias de banco de dados marcadas com
environment=prod. -
Monitore custos agrupando despesas de recursos marcados com tags semelhantes. Por exemplo, se marcar os recursos do RDS associados ao projeto Salix com
project=Salix, você poderá gerar relatórios de custos e alocar despesas para esse projeto. Para ter mais informações, consulte Como o faturamento da AWS funciona com tags no Amazon RDS.
Como as tags de recurso do Amazon RDS funcionam
AWSA não aplica nenhum significado semântico às suas tags. Tags são interpretadas estritamente como sequências de caracteres.
Tópicos
Conjuntos de tags no Amazon RDS
Cada recurso do Amazon RDS tem um contêiner chamado conjunto de tags. O contêiner inclui todas as tags atribuídas ao recurso. Um recurso tem exatamente um conjunto de tags.
Um conjunto de tags contém de 0 a 50 tags. Se você adicionar uma tag a um recurso do RDS que tenha a mesma chave que uma tag existente no recurso, o novo valor substituirá o antigo.
Estrutura de tags no Amazon RDS
A estrutura de uma tag do RDS é a seguinte:
- Chave de tag
-
A chave é o nome obrigatório da tag. O valor da string deve ter de 1 a 128 caracteres Unicode e não pode ter os prefixos
aws:ourds:. A string pode conter apenas o conjunto de letras, números e espaços em branco Unicode,_,.,:,/,=,+,-e@. O regex Java é"^([\\p{L}\\p{Z}\\p{N}_.:/=+\\-@]*)$". As chaves da tag fazem distinção entre maiúsculas e minúsculas. Assim, as chavesprojecteProjectsão distintas.Uma chave é exclusiva a um conjunto de tags. Por exemplo, não pode haver um par de chaves em um conjunto de tags com a mesma chave mas com valores diferentes, como
project=Trinityeproject=Xanadu. - Valor da tag
-
O valor é um valor de string opcional da tag. O valor da string deve ter de 1 a 256 caracteres Unicode. A string pode conter apenas o conjunto de letras, números e espaços em branco Unicode,
_,.,:,/,=,+,-e@. O regex Java é"^([\\p{L}\\p{Z}\\p{N}_.:/=+\\-@]*)$". Os valores de tags diferenciam maiúsculas de minúsculas. Assim, os valoresprodeProdsão distintos.Os valores não precisam ser exclusivos em um conjunto de tags e podem ser nulos. Por exemplo, você pode ter um par de valor-chave em um conjunto de tag de
project=Trinityecost-center=Trinity.
Recursos do Amazon RDS elegíveis para marcação
Você pode marcar os seguintes recursos do Amazon RDS:
-
Instâncias de banco de dados
-
clusters de banco de dados
-
Endpoints do cluster de banco de dados
-
Réplicas de leitura
-
DB snapshots
-
Snapshots de cluster de banco de dados
-
Instâncias de bancos de dados reservadas
-
Assinaturas de eventos
-
Grupos de opções de banco de dados
-
Grupos de parâmetros do banco de dados
-
Grupos de parâmetros de cluster de banco de dados
-
Grupos de sub-redes de banco de dados
-
RDS Proxies
-
Endpoint do RDS Proxy
nota
Atualmente, você não pode etiquetar RDS Proxies e endpoints do RDS Proxy usando o AWS Management Console.
-
Implantações azuis/verdes
-
Integrações ETL zero (pré-visualização)
Como o faturamento da AWS funciona com tags no Amazon RDS
Também é possível utilizar tags para organizar sua fatura da AWS para refletir sua própria estrutura de custo. Para fazer isso, inscreva-se para obter a fatura da sua Conta da AWS com os valores de chave de tag incluídos. Então, para ver o custo de recursos combinados, organize suas informações de faturamento de acordo com recursos com os mesmos valores de chave de tags. Por exemplo, é possível marcar vários recursos com um nome de aplicação específico, e depois organizar suas informações de faturamento para ver o custo total daquela aplicação em vários serviços. Para obter mais informações, consulte Usar tags de alocação de custos no Guia do usuário do AWS Billing.
Como as tags de alocação de custos funcionam com snapshots de cluster de banco de dados
É possível adicionar uma tag a um snapshot decluster de banco de dados. No entanto, sua conta não refletirá esse agrupamento. Para que tags de alocação de custo sejam aplicadas a snapshots de cluster de banco de dados, as seguintes condições devem ser atendidas:
-
As tags devem ser anexadas à instância de banco de dados principal.
-
A instância de banco de dados principal deve estar na mesma Conta da AWS que o snapshot do cluster de banco de dados.
-
A instância de banco de dados principal deve estar na mesma Região da AWS que o snapshot do cluster de banco de dados.
Os snapshots do cluster de banco de dados serão considerados órfãos se não estiverem na mesma região da instância de banco de dados principal ou se esta for excluída. Os snapshots de banco de dados órfãos não comportam tags de alocação de custos. Os custos de snapshots órfãos são agregados em um único item de linha não marcado. Os snapshots do cluster de banco de dados entre contas não são considerados órfãos quando as seguintes condições são atendidas:
-
Eles estão na mesma região da instância de banco de dados principal.
-
A instância de banco de dados principal pertence à conta de origem.
nota
Se a instância de banco de dados principal pertencer a uma conta diferente, as tags de alocação de custos não se aplicarão aos snapshots de várias contas na conta de destino.
Práticas recomendadas para marcação de recursos do Amazon RDS
Ao usar tags, sugerimos seguir estas práticas recomendadas:
-
Convenções de documentos para uso de tags que são seguidas por todas as equipes da organização. Acima de tudo, os nomes devem ser descritivos e consistentes. Por exemplo, padronize o formato
environment:prodem vez de marcar alguns recursos comenv:production.Importante
Não armazene informações de identificação pessoal (PII) nem outras informações confidenciais ou sigilosas em tags.
-
Automatize a marcação para garantir a consistência. Por exemplo, é possível usar as seguintes técnicas:
-
Inclua tags em um modelo do AWS CloudFormation. Ao criar recursos com o modelo, eles são marcados automaticamente.
-
Defina e aplique tags usando funções do AWS Lambda.
-
Crie um documento do SSM que inclua etapas para adicionar tags aos recursos do RDS.
-
-
Use tags somente quando necessário. É possível adicionar até 50 tags a um único recurso do RDS, mas a prática recomendada é evitar a proliferação e a complexidade desnecessárias de tags.
-
Revise as tags periodicamente para verificar a relevância e a precisão. Remova ou modifique as tags desatualizadas conforme necessário.
-
Considere criar tags com o Editor de Tags da AWS no AWS Management Console. É possível usar o Editor de Tags para adicionar tags a vários recursos compatíveis da AWS ao mesmo tempo, incluindo os recursos do RDS. Para obter mais informações, consulte o Tag Editor no Guia do usuário dos Grupos de recursos da AWS.
Copiar tags para snapshots de cluster de banco de dados
Ao criar ou restaurar um cluster de banco de dados, você pode especificar que as tags do cluster sejam copiadas para snapshots do cluster de banco de dados. A cópia de tags garante que os metadados dos snapshots de banco de dados correspondam aos do cluster de banco de dados de origem. Também garante que quaisquer políticas de acesso do snapshot de banco de dados também correspondam às do cluster de banco de dados de origem. Tags não são copiadas por padrão.
Você pode especificar que as tags sejam copiados para snapshots de banco de dados para as seguintes ações:
Criar um cluster de banco de dados
Restaurar um cluster de banco de dados
Como criar uma réplica de leitura
Copiar um snapshot de cluster de banco de dados
nota
Em alguns casos, você pode incluir um valor para o parâmetro --tags do comando create-db-snapshot da AWS CLI. Ou pode fornecer pelo menos uma tag à operação da API CreateDBSnapshot. Nesses casos, o RDS não copia tags da instância de banco de dados de origem para o novo snapshot de banco de dados. Essa funcionalidade é aplicável mesmo que a instância de banco de dados de origem tenha a opção --copy-tags-to-snapshot (CopyTagsToSnapshot) ativada.
Se você seguir essa abordagem, poderá criar uma cópia de uma instância de banco de dados de um snapshot de banco de dados. Essa abordagem evita adicionar tags que não se aplicam à nova instância de banco de dados. Você cria o snapshot de banco de dados com o comando create-db-snapshot da AWS CLI (ou a operação CreateDBSnapshot da API do RDS). Depois de criar o snapshot de banco de dados, é possível adicionar etiquetas conforme descrito posteriormente neste tópico.
Adicionar e excluir tags no Amazon RDS
Você pode fazer o seguinte:
-
Crie tags ao criar um recurso, por exemplo, ao executar o comando
create-db-instanceda AWS CLI. -
Adicione tags a um recurso existente usando o comando
add-tags-to-resource. -
Liste as tags associadas a um recurso específico usando o comando
list-tags-for-resource. -
Atualize as tags usando o comando
add-tags-to-resource. -
Remova as tags de um recurso usando o comando
remove-tags-from-resource.
Os procedimentos a seguir mostram como executar operações típicas de marcação em recursos relacionados a instâncias de banco de dados e clusters de bancos de dados do Aurora. Observe que as tags ficam armazenadas em cache para fins de autorização. Por esse motivo, ao adicionar ou atualizar tags nos recursos do Amazon RDS, pode demorar vários minutos para que as modificações sejam disponibilizadas.
O processo para marcar um recurso do Amazon RDS é semelhante para todos os recursos. O procedimento a seguir mostra como marcar uma instância de banco de dados do Amazon RDS.
Para adicionar uma tag a uma instância de banco de dados
-
Faça login no AWS Management Console e abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. -
No painel de navegação, escolha Databases (Bancos de dados).
nota
Para filtrar a lista de instâncias de bancos de dados no painel Databases (Bancos de dados), digite uma string de texto de Filter databases (Filtrar bancos de dados). Somente instâncias de banco de dados que contiverem a string aparecerão.
-
Escolha no nome da instância de banco de dados que você deseja marcar para mostrar os detalhes.
-
Na seção de detalhes, role para baixo até a seção Tags.
-
Escolha Adicionar. A janela Add tags (Adicionar tags) é exibida.
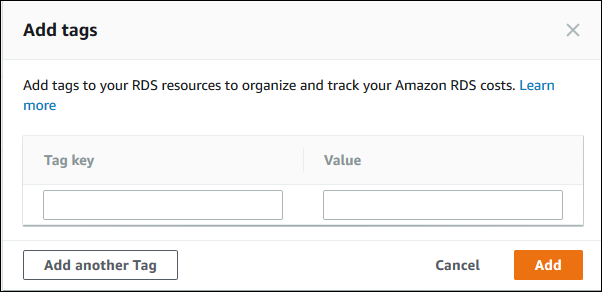
-
Digite um valor para Tag key (Chave de tag) e Value (Valor).
-
Para adicionar outra tag, escolha Add another Tag (Adicionar outra tag) e digite um valor para Tag key (Chave de tag) e Value (Valor).
Repita esta etapa quantas vezes for necessário.
-
Escolha Adicionar.
Para excluir uma tag de uma instância de banco de dados
-
Faça login no AWS Management Console e abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. -
No painel de navegação, escolha Databases (Bancos de dados).
nota
Para filtrar a lista de instâncias de bancos de dados no painel Databases (Bancos de dados), digite uma string de texto na caixa Filter databases (Filtrar bancos de dados). Somente instâncias de banco de dados que contiverem a string aparecerão.
-
Escolha o nome da instância de banco de dados para mostrar os detalhes.
-
Na seção de detalhes, role para baixo até a seção Tags.
Escolha a tag que você deseja excluir.
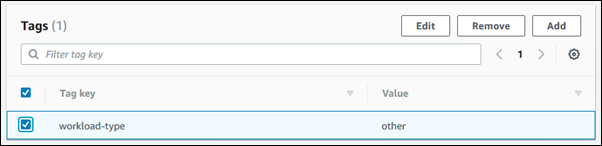
-
Selecione Delete (Excluir) e escolha Delete (Excluir) na janela Delete tags (Excluir tags).
É possível adicionar, listar ou remover tags de uma instância de banco de dados usando a AWS CLI.
Para adicionar uma ou mais etiquetas a um recurso do Amazon RDS, use o comando da AWS CLI
add-tags-to-resource.Para listar as etiquetas em um recurso do Amazon RDS, use o comando da AWS CLI
list-tags-for-resource.Para remover uma ou mais etiquetas de um recurso do Amazon RDS, use o comando da AWS CLI
remove-tags-from-resource.
Para saber mais sobre como criar o ARN necessário, consulte Criar um ARN para o Amazon RDS.
É possível adicionar, listar ou remover tags de uma instância de banco de dados usando a API do Amazon RDS.
Para adicionar uma tag a um recurso do Amazon RDS, use a operação
AddTagsToResource.Para listar tags atribuídas a um recurso do Amazon RDS, use
ListTagsForResource.Para remover tags de um recurso do Amazon RDS, use a operação
RemoveTagsFromResource.
Para saber mais sobre como criar o ARN necessário, consulte Criar um ARN para o Amazon RDS.
As tags usam o seguinte esquema ao trabalhar com o XML usando a API do Amazon RDS:
<Tagging> <TagSet> <Tag> <Key>Project</Key> <Value>Trinity</Value> </Tag> <Tag> <Key>User</Key> <Value>Jones</Value> </Tag> </TagSet> </Tagging>
A tabela a seguir fornece uma lista das tags XML permitidas e suas características. Os valores de Key e Value diferenciam letras maiúsculas de minúsculas. Por exemplo, project=Trinity e PROJECT=Trinity são tags distintas.
| Elemento de marcação por tag | Descrição |
|---|---|
| TagSet | Um conjunto de tags é um contêiner de todas as tags atribuídas a um recurso do Amazon RDS. Só pode haver um conjunto de tags por recurso. Você trabalha com um TagSet somente por meio da API do Amazon RDS. |
| Tag | Uma tag é um par de chave-valor definido pelo usuário. Pode haver de 1 a 50 tags em um conjunto de tags. |
| Chave |
Uma chave é o nome obrigatório da tag. Consulte as restrições em Estrutura de tags no Amazon RDS. O valor da string pode ter de 1 a 128 caracteres Unicode e não pode ter os prefixos As chaves devem ser exclusivas a um conjunto de tags. Por exemplo, não pode haver um par de chaves em um conjunto de tags com a mesma chave mas com valores diferentes, como projeto/Trinity e projeto/Xanadu. |
| Valor |
Um valor é o valor opcional da tag. Consulte as restrições em Estrutura de tags no Amazon RDS. O valor da string pode ter de 1 a 256 caracteres Unicode e não pode ter os prefixos Os valores não têm que ser exclusivos em um conjunto de tags e podem ser nulos. Por exemplo, você pode ter um par de chave-valor em um conjunto de tags definido como projeto/Trinity e centro-custos/Trinity. |
