As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Criando um relatório de avaliação de vários servidores no AWS Schema Conversion Tool
Para determinar a melhor direção de destino para seu ambiente geral, crie um relatório de avaliação multisservidor.
Um relatório de avaliação multisservidor avalia vários servidores com base na entrada que você fornece para cada definição de esquema que você deseja avaliar. Sua definição de esquema contém parâmetros de conexão do servidor de banco de dados e o nome completo de cada esquema. Depois de avaliar cada esquema, AWS SCT produz um relatório de avaliação resumido e agregado para a migração do banco de dados em seus vários servidores. Esse relatório mostra a complexidade estimada para cada possível destino de migração.
Você pode usar AWS SCT para criar um relatório de avaliação de vários servidores para os seguintes bancos de dados de origem e destino.
| Fonte do banco de dados | Bancos de dados de destino |
|---|---|
|
Amazon Redshift |
Amazon Redshift |
|
Banco de dados do SQL Azure |
Aurora MySQL, Aurora PostgreSQL, MySQL, PostgreSQL |
|
Azure Synapse Analytics |
Amazon Redshift |
|
BigQuery |
Amazon Redshift |
|
Greenplum |
Amazon Redshift |
|
IBM Db2 para z/OS |
Amazon Aurora Edição compatível com MySQL (Aurora MySQL), Amazon Aurora Edição compatível com PostgreSQL (Aurora PostgreSQL), MySQL, PostgreSQL |
|
IBM Db2 LUW |
Aurora MySQL, Aurora PostgreSQL, MariaDB, MySQL, PostgreSQL |
|
Microsoft SQL Server |
Aurora MySQL, Aurora PostgreSQL, Amazon Redshift, Babelfish para Aurora PostgreSQL, MariaDB, Microsoft SQL Server, MySQL, PostgreSQL |
|
MySQL |
Aurora PostgreSQL, MySQL, PostgreSQL |
|
Netezza |
Amazon Redshift |
|
Oracle |
Aurora MySQL, Aurora PostgreSQL, Amazon Redshift, MariaDB, MySQL, Oracle, PostgreSQL |
|
PostgreSQL |
Aurora MySQL, Aurora PostgreSQL, MySQL, PostgreSQL |
|
SAP ASE |
Aurora MySQL, Aurora PostgreSQL, MariaDB, MySQL, PostgreSQL |
|
Snowflake |
Amazon Redshift |
|
Teradata |
Amazon Redshift |
|
Vertica |
Amazon Redshift |
Como realizar uma avaliação multisservidor
Use o procedimento a seguir para realizar uma avaliação de vários servidores com AWS SCT. Você não precisa criar um novo projeto AWS SCT para realizar uma avaliação de vários servidores. Antes de começar, certifique-se de ter preparado um arquivo de valores separados por vírgula (CSV) com parâmetros de conexão do banco de dados. Além disso, verifique se você instalou todos os drivers de banco de dados necessários e defina a localização dos drivers nas configurações da AWS SCT . Para obter mais informações, consulte Instalando drivers JDBC para AWS Schema Conversion Tool.
Para realizar uma avaliação multisservidor e criar um relatório resumido agregado
-
Em AWS SCT, escolha Arquivo, Nova avaliação de vários servidores. A caixa de diálogo Nova avaliação multisservidor é aberta.
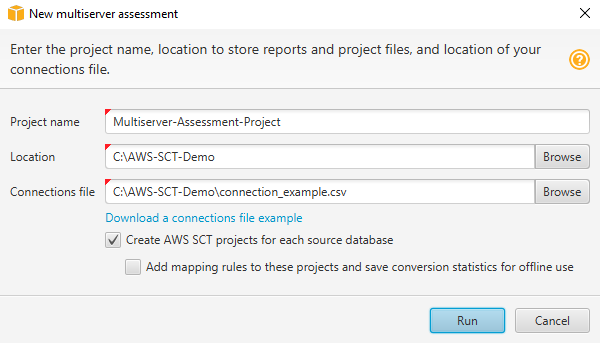
-
Selecione Baixar um exemplo de arquivo de conexões para baixar um modelo vazio de um arquivo CSV com parâmetros de conexão do banco de dados.
-
Insira valores para Nome do projeto, Localização (para armazenar relatórios) e Arquivo de conexões (um arquivo CSV).
-
Escolha Criar AWS SCT projetos para cada banco de dados de origem para criar automaticamente projetos de migração após gerar o relatório de avaliação.
-
Com a opção Criar AWS SCT projetos para cada banco de dados de origem ativada, você pode escolher Adicionar regras de mapeamento a esses projetos e salvar as estatísticas de conversão para uso offline. Nesse caso, AWS SCT adicionará regras de mapeamento a cada projeto e salvará os metadados do banco de dados de origem no projeto. Para obter mais informações, consulte Usando o modo offline em AWS Schema Conversion Tool.
-
Escolha Executar.
Uma barra de progresso aparece indicando o ritmo da avaliação do banco de dados. O número de mecanismos de destino pode afetar o runtime da avaliação.
-
Selecione Sim se a seguinte mensagem for exibida: A análise completa de todos os servidores de banco de dados pode levar algum tempo. Você quer continuar?
Quando o relatório de avaliação multisservidor é concluído, uma tela é exibida indicando isso.
-
Selecione Abrir relatório para ver o relatório de avaliação resumida agregado.
Por padrão, AWS SCT gera um relatório agregado para todos os bancos de dados de origem e um relatório de avaliação detalhado para cada nome de esquema em um banco de dados de origem. Para obter mais informações, consulte Como localizar e visualizar relatórios.
Com a opção Criar AWS SCT projetos para cada banco de dados de origem ativada, AWS SCT cria um projeto vazio para cada banco de dados de origem. AWS SCT também cria relatórios de avaliação conforme descrito anteriormente. Depois de analisar esses relatórios de avaliação e escolher o destino da migração para cada banco de dados de origem, adicione bancos de dados de destino a esses projetos vazios.
Com a opção Adicionar regras de mapeamento a esses projetos e salvar estatísticas de conversão para uso off-line ativada, AWS SCT cria um projeto para cada banco de dados de origem. Esses projetos incluem as seguintes informações:
Seu banco de dados de origem e uma plataforma de banco de dados de destino virtual. Para obter mais informações, consulte Mapeamento para alvos virtuais no AWS Schema Conversion Tool.
Uma regra de mapeamento para esse par de origem e destino. Para obter mais informações, consulte Mapeamento de tipo de dados.
Um relatório de avaliação da migração do banco de dados para esse par de origem e destino.
Metadados do esquema de origem, que permitem que você use esse AWS SCT projeto em um modo off-line. Para obter mais informações, consulte Usando o modo offline em AWS Schema Conversion Tool.
Como preparar um arquivo CSV de entrada
Para fornecer parâmetros de conexão como entrada para o relatório de avaliação multisservidor, use um arquivo CSV conforme exibido no exemplo a seguir.
Name,Description,Secret Manager Key,Server IP,Port,Service Name,Database name,BigQuery path,Source Engine,Schema Names,Use Windows Authentication,Login,Password,Use SSL,Trust store,Key store,SSL authentication,Target Engines Sales,,,192.0.2.0,1521,pdb,,,ORACLE,Q4_2021;FY_2021,,user,password,,,,,POSTGRESQL;AURORA_POSTGRESQL Marketing,,,ec2-a-b-c-d.eu-west-1.compute.amazonaws.com,1433,,target_audience,,MSSQL,customers.dbo,,user,password,,,,,AURORA_MYSQL HR,,,192.0.2.0,1433,,employees,,MSSQL,employees.%,true,,,,,,,AURORA_POSTGRESQL Customers,,secret-name,,,,,,MYSQL,customers,,,,,,,,AURORA_POSTGRESQL Analytics,,,198.51.100.0,8195,,STATISTICS,,DB2LUW,BI_REPORTS,,user,password,,,,,POSTGRESQL Products,,,203.0.113.0,8194,,,,TERADATA,new_products,,user,password,,,,,REDSHIFT
O exemplo anterior usa ponto e vírgula para separar os dois nomes de esquema do banco de dados Sales. Ele também usa um ponto e vírgula para separar as duas plataformas de migração do banco de dados de destino para o banco de dados Sales.
Além disso, o exemplo anterior usa AWS Secrets Manager para se conectar ao Customers banco de dados e a Autenticação do Windows para se conectar ao HR banco de dados.
Você pode criar um novo arquivo CSV ou baixar um modelo para um arquivo CSV da AWS SCT e preencher as informações necessárias. Certifique-se de que a primeira linha do seu arquivo CSV inclua os mesmos nomes de coluna mostrados no exemplo anterior.
Para baixar um modelo do arquivo CSV de entrada
Começar AWS SCT.
Selecione Arquivo, depois selecione Nova avaliação multisservidor.
Selecione Baixar um exemplo de arquivo de conexões.
Certifique-se de que seu arquivo CSV inclua os seguintes valores, fornecidos pelo modelo:
-
Nome: O rótulo de texto que ajuda a identificar seu banco de dados. A AWS SCT exibe esse rótulo de texto no relatório de avaliação.
-
Descrição: Um valor opcional, no qual você pode fornecer informações adicionais sobre o banco de dados.
-
Chave do Secrets Manager: O nome do segredo que armazena suas credenciais de banco de dados na AWS Secrets Manager. Para usar o Secrets Manager, certifique-se de armazenar AWS perfis em AWS SCT. Para obter mais informações, consulte Configurando AWS Secrets Manager no AWS Schema Conversion Tool.
Importante
AWS SCT ignorará o parâmetro Secret Manager Key se você incluir os parâmetros IP, porta, login e senha do servidor no arquivo de entrada.
-
Servidor IP: Digite o Serviço de Nome de Domínio (DNS) ou o endereço IP do servidor de banco de dados de origem.
-
Porta: A porta usada para se conectar ao servidor de banco de dados de origem.
-
Nome do serviço: Se você usar um nome de serviço para se conectar ao seu banco de dados Oracle, o nome do serviço Oracle ao qual se conectar.
-
Nome do banco de dados: O nome do banco de dados. Para bancos de dados Oracle, use o Oracle System ID (SID).
-
BigQuery path — o caminho para o arquivo de chave da conta de serviço do seu BigQuery banco de dados de origem. Para obter mais informações sobre a criação desse arquivo, consulte a Privilégios BigQuery como fonte.
-
Mecanismo de origem: O tipo do seu banco de dados de origem. Use um dos seguintes valores:
AZURE_MSSQL para um banco de dados SQL do Azure.
AZURE_SYNAPSE para um banco de dados do Azure Synapse Analytics.
GOOGLE_BIGQUERY para um banco de dados. BigQuery
DB2ZOS para um banco de dados IBM Db2 for z/OS.
DB2LUW para um banco de dados IBM Db2 LUW.
GREENPLUM para um banco de dados Greenplum.
MSSQL para um banco de dados Microsoft SQL Server.
MYSQL para um banco de dados MySQL.
NETEZZA para um banco de dados Netezza.
ORACLE para um banco de dados Oracle.
POSTGRESQL para um banco de dados PostgreSQL.
REDSHIFT para um banco de dados do Amazon Redshift.
SNOWFLAKE para um banco de dados Snowflake.
SYBASE_ASE para um banco de dados SAP ASE.
TERADATA para um banco de dados Teradata.
VERTICA para um banco de dados Vertica.
-
Nomes do esquema: Os nomes dos esquemas do banco de dados a serem incluídos no relatório de avaliação.
Para o Banco de Dados SQL do Azure, o Azure Synapse Analytics BigQuery, o Netezza, o SAP ASE, o Snowflake e o SQL Server, use o seguinte formato do nome do esquema:
db_name.schema_nameSubstitua
db_nameSubstitua
schema_nameInclua nomes de bancos de dados ou esquemas que incluam um ponto entre aspas duplas, conforme mostrado a seguir:
"database.name"."schema.name".Separe vários nomes de esquemas usando ponto e vírgula, conforme mostrado a seguir:
Schema1;Schema2.Os nomes do banco de dados e do esquema diferenciam maiúsculas de minúsculas.
Utilize a porcentagem (
%) como curinga para substituir qualquer número de quaisquer símbolos no nome do banco de dados ou esquema. O exemplo anterior usa a porcentagem (%) como curinga para incluir todos os esquemas do banco de dadosemployeesno relatório de avaliação. -
Use a Autenticação do Windows: Se você usa a Autenticação do Windows para se conectar ao banco de dados do Microsoft SQL Server, digite verdadeiro. Para obter mais informações, consulte Usando a autenticação do Windows ao usar o Microsoft SQL Server como origem.
-
Login: O nome de usuário para se conectar ao servidor do banco de dados de origem.
-
Senha: A senha para se conectar ao servidor de banco de dados de origem.
-
Use SSL: Se você usar Secure Sockets Layer (SSL) para se conectar ao seu banco de dados de origem, digite verdadeiro.
-
Armazenamento confiável: O armazenamento confiável a ser usado para sua conexão SSL.
-
Armazenamento de chaves: O armazenamento de chaves a ser usado para sua conexão SSL.
-
Autenticação SSL: Se você usar a autenticação SSL por certificado, digite verdadeiro.
-
Mecanismos de destino: As plataformas de banco de dados de destino. Use os valores a seguir para especificar um ou mais destinos no relatório de avaliação:
AURORA_MYSQL para um banco de dados compatível com o Aurora MySQL.
AURORA_POSTGRESQL para um banco de dados compatível com o Aurora PostgreSQL.
BABELFISH para um banco de dados Babelfish para Aurora PostgreSQL.
MARIA_DB para um banco de dados MariaDB.
MSSQL para um banco de dados Microsoft SQL Server.
MYSQL para um banco de dados MySQL.
ORACLE para um banco de dados Oracle.
POSTGRESQL para um banco de dados PostgreSQL.
REDSHIFT para um banco de dados do Amazon Redshift.
Separe vários destinos usando ponto e vírgula como este:
MYSQL;MARIA_DB. O número de destinos afeta o tempo necessário para executar a avaliação.
Como localizar e visualizar relatórios
A avaliação multisservidor gera dois tipos de relatórios:
-
Um relatório agregado de todos os bancos de dados de origem.
-
Um relatório de avaliação detalhado dos bancos de dados de destino para cada nome de esquema em um banco de dados de origem.
Os relatórios são armazenados no diretório que você escolheu para Localização na caixa de diálogo Nova avaliação multisservidor.
Para acessar os relatórios detalhados, você pode navegar pelos subdiretórios, que são organizados por banco de dados de origem, nome do esquema e mecanismo de banco de dados de destino.
Os relatórios agregados mostram informações em quatro colunas sobre a complexidade da conversão de um banco de dados de destino. As colunas incluem informações sobre conversão de objetos de código, objetos de armazenamento, elementos de sintaxe e complexidade de conversão.
O exemplo a seguir mostra informações para conversão de dois esquemas de banco de dados Oracle para Amazon RDS para PostgreSQL.

As mesmas quatro colunas são anexadas aos relatórios para cada mecanismo de banco de dados de destino adicional especificado.
Para obter detalhes sobre como ler essas informações, consulte a seguir.
Saída para um relatório de avaliação agregado
O relatório agregado de avaliação da migração de banco de dados multiservidor em AWS Schema Conversion Tool é um arquivo CSV com as seguintes colunas:
-
Server IP address and port -
Secret Manager key -
Name -
Description -
Database name -
Schema name -
Code object conversion % fortarget_database -
Storage object conversion % fortarget_database -
Syntax elements conversion % fortarget_database -
Conversion complexity fortarget_database
Para coletar informações, AWS SCT executa relatórios de avaliação completos e, em seguida, agrega relatórios por esquemas.
No relatório, os três campos a seguir mostram a porcentagem de conversão automática possível com base na avaliação:
- % de conversão de objeto de código
-
A porcentagem de objetos de código no esquema que AWS SCT podem ser convertidos automaticamente ou com alterações mínimas. Objetos de código incluem procedimentos, perfis, visualizações e similares.
- % de conversão de objeto de armazenamento
-
A porcentagem de objetos de armazenamento que a SCT pode converter automaticamente ou com alterações mínimas. Os objetos de armazenamento incluem tabelas, índices, restrições e similares.
- % de conversão de elementos de sintaxe
-
A porcentagem de elementos de sintaxe que a SCT pode converter automaticamente. Os elementos de sintaxe incluem as cláusulas
SELECT,FROM,DELETEeJOINe similares.
O cálculo da complexidade de conversão é baseado na noção de itens de ação. Um item de ação reflete um tipo de problema encontrado no código fonte que você precisa corrigir manualmente durante a migração para um destino específico. Um item de ação pode ter várias ocorrências.
Uma escala ponderada identifica o nível de complexidade para realizar uma migração. O número 1 representa o nível mais baixo de complexidade e o número 10 representa o nível mais alto.
