Práticas recomendadas para gerenciar relações de muitos para muitos no DynamoDB
As listas de adjacências são um padrão de design útil para modelar as relações muitos para muitos no Amazon DynamoDB. De modo mais geral, elas oferecem uma forma de representar os dados gráfico (nós e bordas) no DynamoDB.
Padrão de design da lista de adjacências
Quando entidades diferentes de um aplicativo têm uma relação muitos para muitos entre elas, a relação pode ser modelada como uma lista de adjacências. Nesse padrão, todas as entidades de nível superior (sinônimos para nós no modelo de gráfico) são representadas usando a chave de partição. Qualquer relação com outras entidades (bordas em um gráfico) é representada como um item na partição configurando o valor da chave de classificação como o ID da entidade de destino (nó de destino).
As vantagens desse padrão incluem a duplicação mínima de dados e padrões simplificados de consulta para encontrar todas as entidades (nós) relacionadas a uma entidade de destino (o ponto em um nó de destino).
Como exemplo real, esse padrão foi útil em um sistema de faturamento em que as faturas continham várias contas. Uma conta pode pertencer a várias faturas. A chave de partição nesse exemplo é um InvoiceID ou um BillID. As partições BillID têm todos os atributos específicos para as contas. As partições InvoiceID têm um item que armazena os atributos específicos à fatura e um item para cada BillID implementado para a fatura.
O esquema é semelhante ao seguinte.
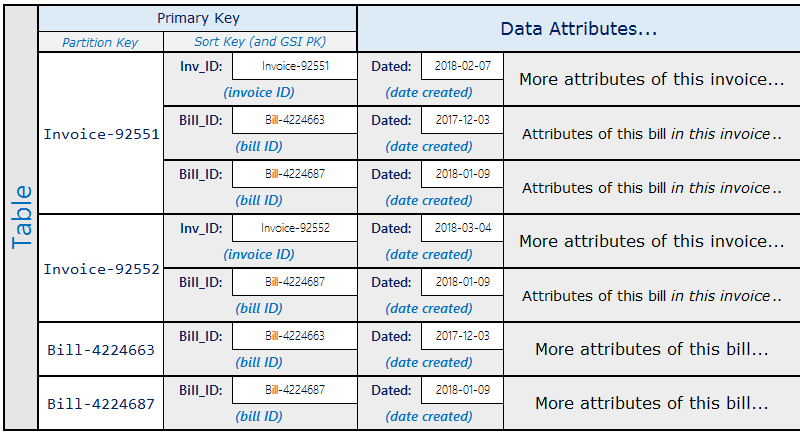
Usando o esquema anterior, você pode ver que todas as contas para uma fatura podem ser consultadas usando a chave primária na tabela. Para pesquisar todas as faturas que contêm uma parte de uma conta, crie um índice secundário global na chave de classificação da tabela.
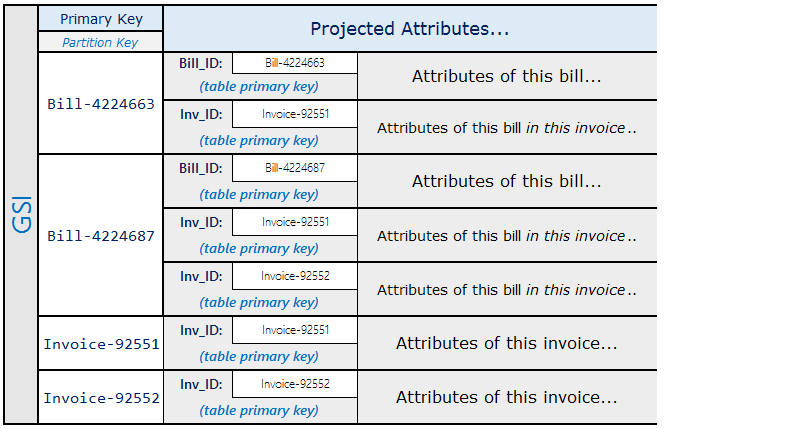
As projeções do índice secundário global são semelhantes ao seguinte.
Padrão de gráficos materializados
Muitos aplicativos são criados com base no entendimento das classificações entre os colegas, nas relações comuns entre entidades, no estado da entidade vizinha e em outros tipos de fluxos de trabalho de estilo de gráficos. Para esses tipos de aplicativos, considere o seguinte padrão de design de esquema.
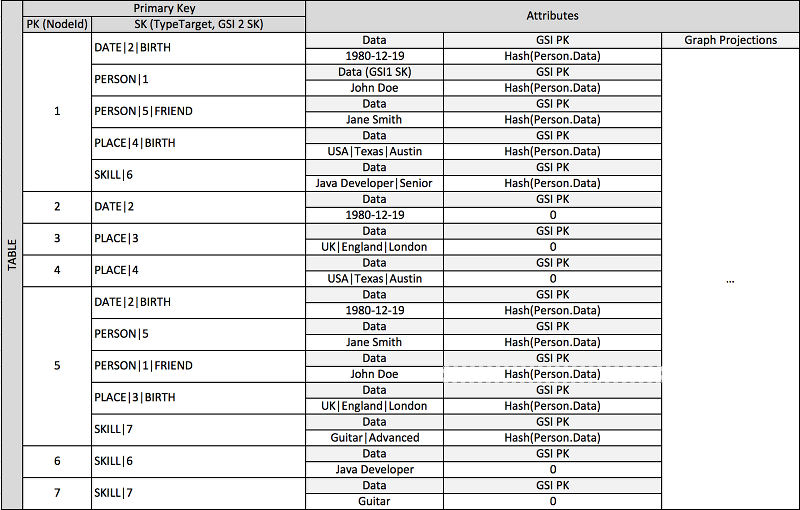
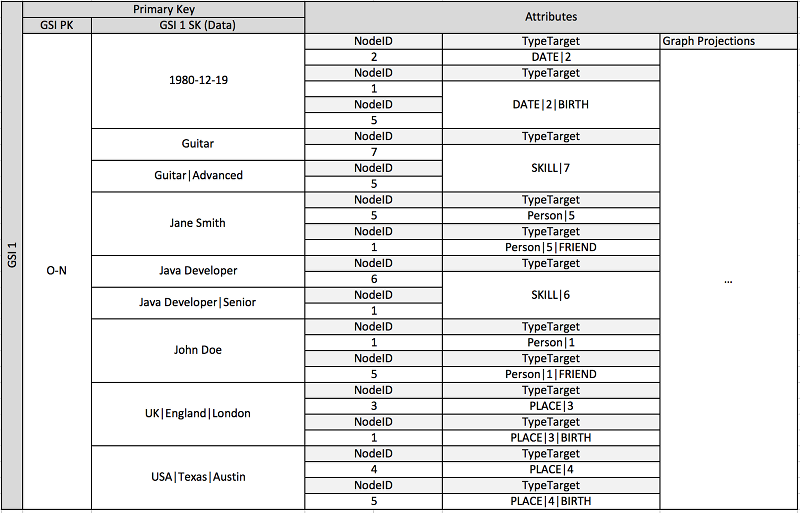
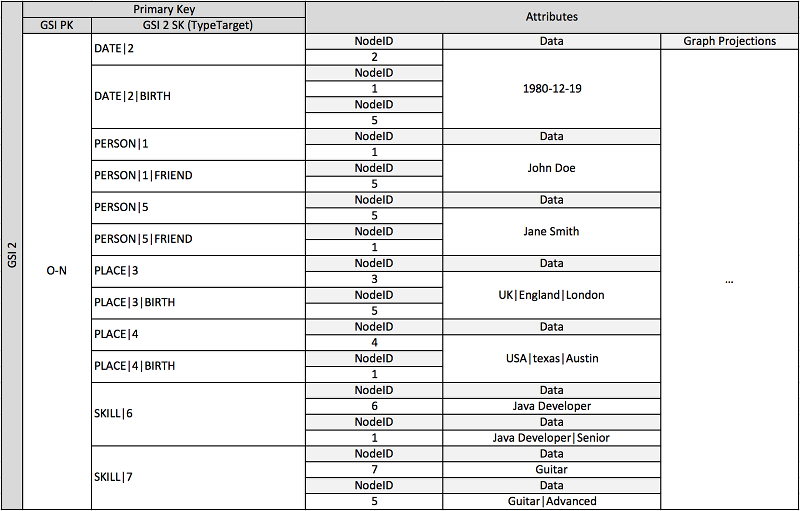
O esquema anterior mostra uma estrutura de dados em gráfico que é definida por um conjunto de partições de dados contendo os itens que definem as bordas e os nós do gráfico. Os itens da borda contêm um atributo Target e um Type. Esses atributos são usados como parte do nome de uma chave composto “TypeTarget” para identificar o item em uma partição na tabela principal ou em outro índice secundário global.
O primeiro índice secundário global é criado no atributo Data. Esse atributo usa a sobrecarga do índice secundário global conforme descrito anteriormente para indexar vários tipos diferentes de atributo, a saber Dates, Names. Places e Skills. Aqui, um índice secundário global está indexando efetivamente quatro atributos diferentes.
À medida que você inserir itens na tabela, poderá usar uma estratégia de fragmentação inteligente para distribuir os conjuntos de item com grandes agregações (data de nascimento, habilidade) nas partições lógicas nos índices secundários globais que forem necessárias para evitar problemas de leitura/gravação dinâmicas.
O resultado dessa combinação de padrões de design é um datastore sólido para fluxos de trabalho de gráfico altamente eficientes e em tempo real. Esses fluxos de trabalho podem fornecer consultas de alto desempenho a agregação de borda e ao estado da entidade vizinha para mecanismos de recomendação, aplicativos de rede social, classificações de nós, agregações de subárvore e outros casos de uso comuns de gráficos.
Se seu caso de uso não for sensível a consistência de dados em tempo real, você poderá usar um processo do Amazon EMR programado para preencher as bordas com agregações relevantes de resumo de gráfico para seus fluxos de trabalho de um modo econômico. Se o aplicativo não precisar saber imediatamente quando uma borda é adicionada ao gráfico, será possível usar um processo programado para agregar resultados.
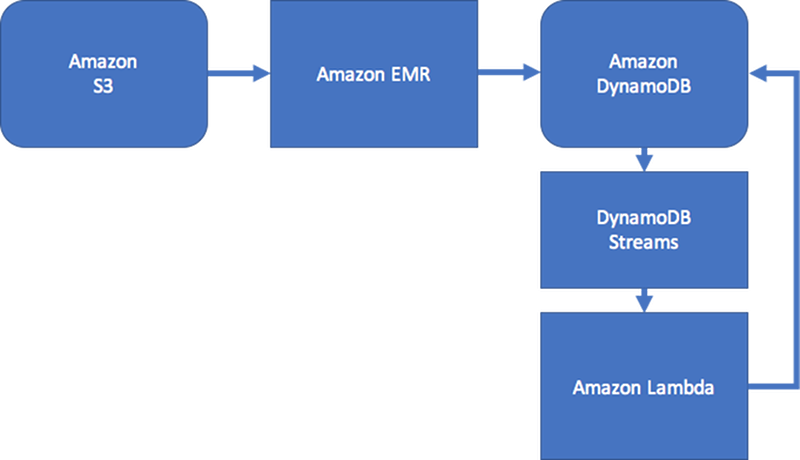
Para manter algum nível de consistência, o design poderia incluir Amazon DynamoDB Streams e AWS Lambdaparar processar atualizações da borda. Ele também poderia usar um trabalho do Amazon EMR para validar os resultados em um intervalo regular. Essa abordagem é ilustrada pelo diagrama a seguir. Ela é usada comumente em aplicativos de rede social, onde o custo de uma consulta em tempo real é alto, e a necessidade de saber imediatamente as atualizações de usuário individual é baixa.
Os aplicativos de segurança e gerenciamento de serviços de TI (ITSM - IT service-management) geralmente precisa responder em tempo real às alterações de estado da entidade compostas de agregações complexas de borda. Esses aplicativos precisam de um sistema que seja compatível com várias agregações de nó em tempo real de relações de segundo e terceiros níveis ou de percursos complexos de borda. Se o seu caso de uso exigir esses tipos de fluxos de trabalho de consulta de gráficos em tempo real, recomendamos que você considere o uso do Amazon Neptune para gerenciar esses fluxos de trabalho.
nota
Se você precisar consultar conjuntos de dados altamente conectados ou executar consultas que precisem passar por vários nós (também conhecidas como consultas multi-hop) com latência de milissegundos, considere a possibilidade de usar o Amazon Neptune. O Amazon Neptune é um mecanismo de banco de dados de grafos com propósito específico e alta performance, otimizado para armazenar bilhões de relacionamentos e consultar grafos com latência de milissegundos.
