Exemplo de modelagem de dados relacionais no DynamoDB
Esse exemplo descreve como modelar dados relacionais no Amazon DynamoDB. Um design de tabela do DynamoDB corresponde ao esquema relacional de entrada de pedidos que é mostrado em Modelagem relacional. Ele acompanha a Padrão de design da lista de adjacências, que é um modo comum de representar as estruturas de dados relacionais no DynamoDB.
O padrão de design requer que você defina um conjunto de tipos de entidades que se correlacionam geralmente com várias tabelas no esquema relacional. Os itens da entidade são adicionados à tabela usando uma chave primária composta (partição e classificação). A chave de partição desses itens de entidade é o atributo que identifica exclusivamente o item e que é mencionado genericamente em todos os itens como PK. O atributo de chave de classificação contém um valor do atributo que pode ser usado para um índice invertido ou um índice secundário global. Ele é referido genericamente como SK.
Você define as seguintes entidades que são compatíveis com o esquema relacional de entrada de pedidos.
-
HR-Employee - PK: EmployeeID, SK: Employee Name
-
HR-Region - PK: RegionID, SK: Region Name
-
HR-Country - PK: CountryId, SK: Country Name
-
HR-Location - PK: LocationID, SK: Country Name
-
HR-Job - PK: JobID, SK: Job Title
-
HR-Department - PK: DepartmentID, SK: DepartmentName
-
OE-Customer - PK: CustomerID, SK: AccountRepID
-
OE-Order - PK OrderID, SK: CustomerID
-
OE-Product - PK: ProductID, SK: Product Name
-
OE-Warehouse - PK: WarehouseID, SK: Region Name
Após ter adicionado esses itens de entidade à tabela, você pode definir as relações entre eles adicionando itens de borda às partições de item de entidade. A tabela a seguir demonstra essa etapa.
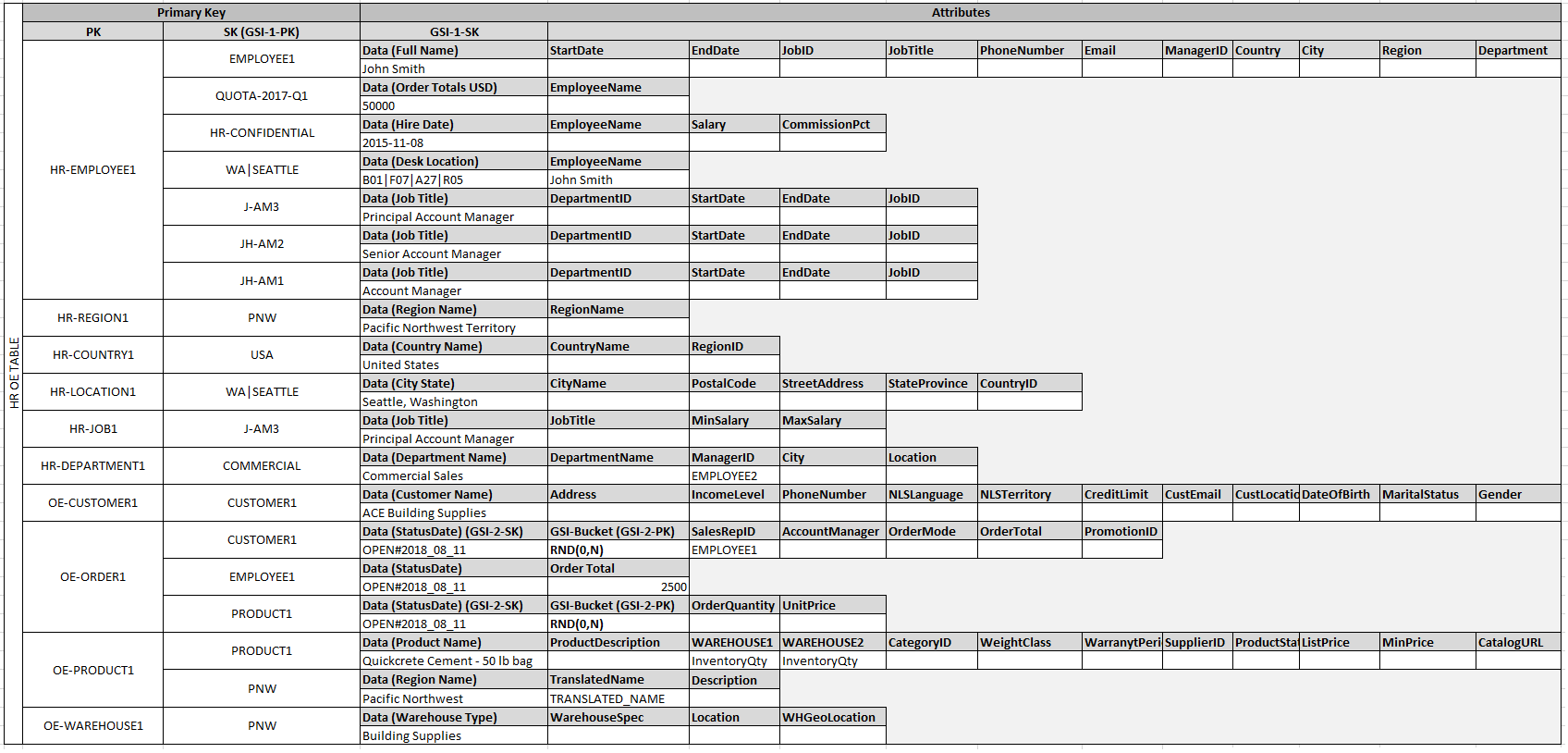
Nesse exemplo, as partições Employee, Order e Product
Entity na tabela têm itens de borda adicionais que contêm indicadores para outros itens de entidade na tabela. Em seguida, defina alguns índices secundários globais (GSIs – Global secondary indexes) para compatibilidade com todos os padrões de acesso definidos anteriormente. Os itens de entidade não usam o mesmo tipo de valor para a chave primária nem o atributo de chave de classificação. Tudo isso é necessário para que os atributos de chave primária e de chave de classificação presentes sejam inseridos na tabela.
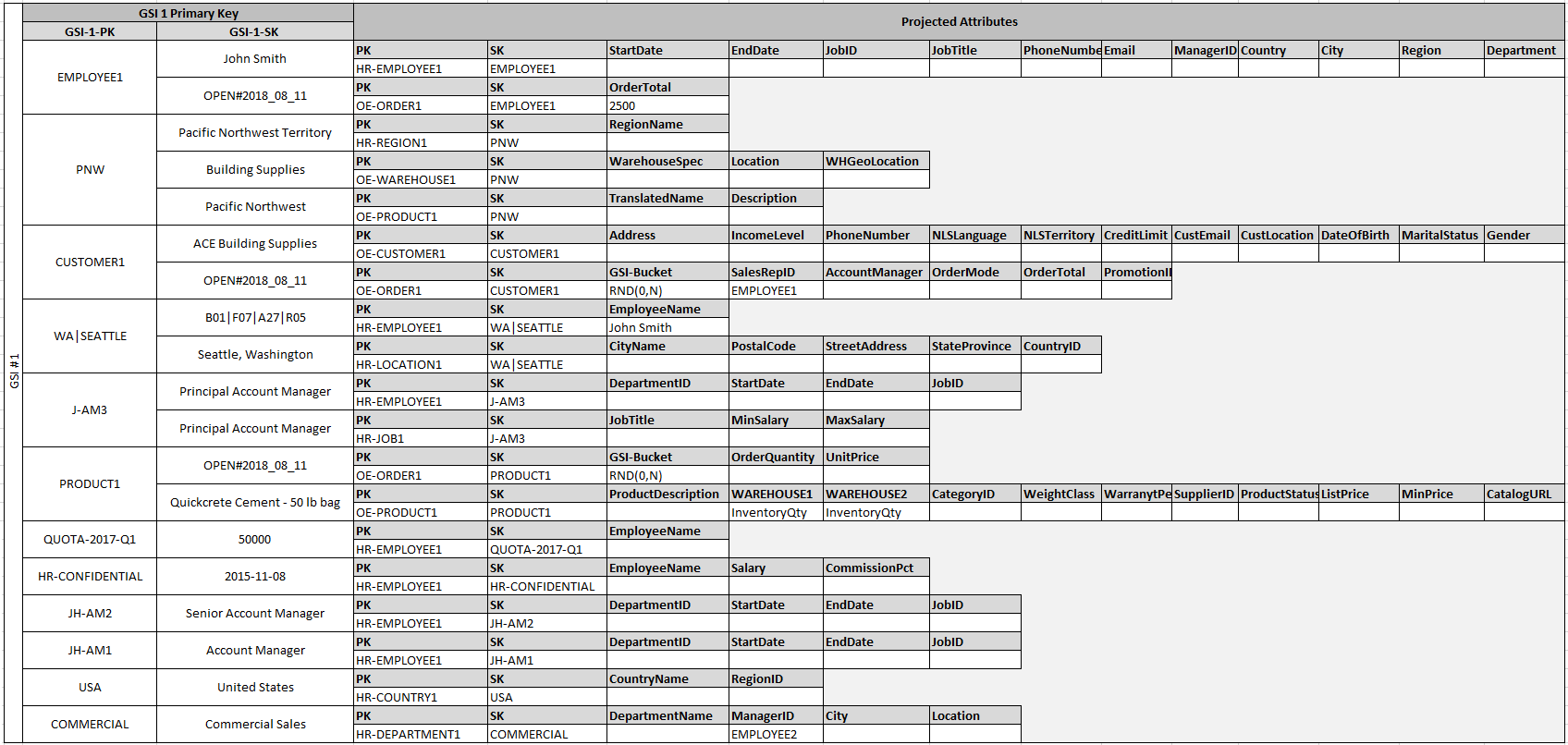
O fato de algumas dessas entidades usarem nomes próprios e outras usarem outros IDs de entidade como os valores da chave de classificação permite que o mesmo índice secundário global seja compatível com vários tipos de consultas. Essa técnica é chamada de sobrecarga de GSI. Ela elimina efetivamente o limite padrão de 20 índices secundários globais para as tabelas que contêm vários tipos de itens. Isso é mostrado no diagrama a seguir como GSI 1.
O GSI 2 foi projetado para compatibilidade com um padrão bastante comum de acesso a aplicativos, que é obter todos os itens na tabela que têm um determinado estado. Para uma tabela grande com uma distribuição desigual de itens entre os estados disponíveis, esse padrão de acesso pode resultar em uma chave dinâmica, a menos que os itens sejam distribuídos em mais de uma partição lógica que pode ser consultada simultaneamente. Esse padrão de design é chamado write sharding.
Para realizar isso para o GSI 2, o aplicativo adiciona o atributo de chave primária do GSI 2 a cada item de pedidos. Ele preenche o campo com um número aleatório em um intervalo de 0 – N, em que N pode ser genericamente calculado usando a fórmula a seguir, a menos que haja um motivo específico para se fazer de outra maneira.
ItemsPerRCU = 4KB / AvgItemSize PartitionMaxReadRate = 3K * ItemsPerRCU N = MaxRequiredIO / PartitionMaxReadRate
Por exemplo, suponha que você espere o seguinte:
-
Até 2 milhões de pedidos estarão no sistema, aumentando para 3 milhões em 5 anos.
-
Até 20% desses pedidos estarão em um estado ABERTO por um determinar tempo.
-
O registro médio de pedidos é cerca de 100 bytes, com três registros de
OrderItemna partição de pedidos com cerca de 50 bytes cada, oferecendo um tamanho médio de entidade de pedidos de 250 bytes.
Para a tabela, o cálculo do fator N seria semelhante ao seguinte.
ItemsPerRCU = 4KB / 250B = 16 PartitionMaxReadRate = 3K * 16 = 48K N = (0.2 * 3M) / 48K = 13
Nesse caso, você precisa distribuir todos os pedidos em pelo menos 13 partições lógicas em GSI 2 para garantir que uma leitura de todos os itens de Order com um status OPEN não cause uma partição dinâmica na camada de armazenamento físico. É uma boa prática preencher esse número para permitir anomalias no conjunto de dados. Então, um modelo que use N = 15 é provavelmente bom. Como mencionado anteriormente, você faz isso adicionando o valor 0 – N aleatório ao atributo PK GSI 2 de cada registro Order eOrderItem que é inserido na tabela.
Esse detalhamento supõe que o padrão de acesso que requer que a coleta de todas as faturas OPEN ocorra relativamente sem frequência, de modo que você possa usar a capacidade de intermitência para preencher a solicitação. Você pode consultar o seguinte índice secundário global usando uma condição de chave de classificação de State e de Date Range para produzir um subconjunto ou todos os Orders em um determinado estado, conforme necessário.

Neste exemplo, os itens são distribuídos de modo aleatório entre 15 partições lógicas. Essa estrutura funciona, porque o padrão acesso exige a recuperação de um grande número de itens. Portanto, é improvável que alguns dos 15 threads retornarão conjuntos vazios de resultados que poderiam potencialmente representar a capacidade desperdiçada. Uma consulta sempre usa 1 unidade de capacidade de leitura (RCU) ou 1 unidade de capacidade de gravação (WCU), mesmo se nada for retornado ou nenhum dado for gravado.
Se o padrão acesso exigir uma consulta de alta velocidade nesse índice secundário global que retorna um conjunto de resultados esparsos, é provavelmente melhor usar um algoritmo hash para distribuir os itens em vez de um padrão aleatório. Nesse caso, você pode selecionar um atributo que seja conhecido quando a consulta for executada em tempo de execução e aplicar hash a esse atributo em um espaço de chaves de 0 – 14 quando os itens são inseridos. Então, eles podem ser lidos de modo eficiente no índice secundário global.
Por fim, você pode reanalisar os padrões de acesso que foram definidos anteriormente. A seguir está a lista de padrões de acesso e as condições de consulta que serão usadas com a nova versão do DynamoDB da aplicação para acomodá-los.
| S. Não. | Padrões de acesso | Condições de consulta |
|---|---|---|
|
1 |
Procurar os detalhes do funcionário por ID do funcionário |
Chave primária na tabela, ID=“HR-EMPLOYEE” |
|
2 |
Consultar detalhes do funcionário por nome do funcionário |
Use GSI-1, PK=“Nome do funcionário” |
|
3 |
Obter apenas os detalhes do trabalho atual de um funcionário |
Chave primária na tabela, PK=HR-EMPLOYEE-1, SK começa com “JH” |
|
4 |
Obter pedidos de um cliente em um intervalo de datas |
Use GSI-1, PK=CUSTOMER1, SK=“STATUS-DATE”, para cada StatusCode |
|
5 |
Mostrar todos os pedidos no status OPEN para um intervalo de datas de todos os clientes |
Use GSI-2, PK=query em paralelo para o intervalo [0..N], SK entre Open-Date1 e Open-Date2 |
|
6 |
Todos os funcionários contratados recentemente |
Use GSI-1, PK=“HR-CONFIDENTIAL”, SK > date1 |
|
7 |
Encontrar todos os funcionários em um armazém específico |
Usar GSI-1, PK=WAREHOUSE1 |
|
8 |
Obter todos os Orderitems de um produto, incluindo inventários do local do depósito |
Use GSI-1, PK=PRODUCT1 |
|
9 |
Obter clientes por representante da conta |
Use GSI-1, PK=ACCOUNT-REP |
|
10 |
Obter pedidos por representante de conta e data |
Use GSI-1, PK=ACCOUNT-REP, SK=“STATUS-DATE”, para cada StatusCode |
|
11 |
Obter todos os funcionários com um cargo específico |
Use GSI-1, PK=JOBTITLE |
|
12 |
Obter inventário por produto e armazém |
Chave primária na tabela, PK=OE-PRODUCT1,SK=PRODUCT1 |
|
13 |
Obter o inventário total de produtos |
Chave primária na tabela, PK=OE-PRODUCT1,SK=PRODUCT1 |
|
14 |
Obter representantes de conta classificados por total do pedido e período de vendas |
Use GSI-1, PK=YYYY-Q1, scanIndexForward=False |
