Usar um metastore externa do Hive
Você pode usar o conector de dados do Amazon Athena para o metastore externo do Hive para consultar conjuntos de dados no Amazon S3 que usam um metastore do Apache Hive. Não é necessária nenhuma migração de metadados para o AWS Glue Data Catalog. No console de gerenciamento do Athena, configure uma função do Lambda para se comunicar com o metastore do Hive que está em sua VPC privada e conectá-la ao metastore. A conexão do Lambda com o metastore do Hive é protegida por um canal privado do Amazon VPC e não usa a Internet pública. Você pode usar seu próprio código de função do Lambda ou a implementação padrão do conector de dados do Athena para o metastore externo do Hive.
Tópicos
Usar o AWS Serverless Application Repository para implementar um conector de fonte de dados do Hive
Conectar o Athena a um metastore do Hive com uso de um perfil de execução do IAM existente
Configurar o Athena para usar um conector de metastore do Hive implantado
Omitir o nome do catálogo em consultas do metastore externo do Hive
Visão geral de recursos
Com o conector de dados do Athena para metastore externo do Hive, você pode executar as seguintes tarefas:
-
Use o console do Athena para registrar catálogos personalizados e usá-los para executar consultas.
-
Defina funções do Lambda para diferentes metastores externos do Hive e adicione-as às consultas do Athena.
-
Use o AWS Glue Data Catalog e os metastores externos do Hive na mesma consulta do Athena.
-
Especifique um catálogo no contexto de execução da consulta como o catálogo padrão atual. Isso remove a necessidade de prefixar nomes de catálogo para nomes de banco de dados em suas consultas. Em vez de usar a sintaxe
catalog.database.tabledatabase.table -
Use uma variedade de ferramentas para executar consultas que fazem referência a metastores externos do Hive. Você pode usar o console do Athena, a AWS CLI, o AWS SDK, as APIs do Athena e os drivers JDBC e ODBC atualizados do Athena. Os drivers atualizados são compatíveis com catálogos personalizados.
Suporte à API
O conector de dados do Athena para metastore externo do Hive permite operações da API de registro de catálogo e da API de metadados.
-
Registro do catálogo: registre catálogos personalizados para metastores externos do Hive e origens de dados federadas.
-
Metadados: use as APIs de metadados para fornecer informações de banco de dados e tabela para o AWS Glue e qualquer catálogo que você registrar no Athena.
-
Cliente JAVA SDK do Athena: use as APIs de registro de catálogo, as APIs de metadados e o suporte para catálogos na operação
StartQueryExecutionno cliente Java SDK atualizado do Athena.
Implementação de referência
O Athena oferece uma implementação de referência para a função do Lambda que se conecta a metastores externos do Hive. A implementação de referência é fornecida no GitHub como um projeto de código aberto no metastore do Athena Hive
A implementação de referência está disponível como os dois aplicativos do AWS SAM a seguir no AWS Serverless Application Repository (SAR). Você pode usar qualquer uma dessas aplicações no SAR para criar as próprias funções do Lambda.
-
AthenaHiveMetastoreFunction: arquivo Uber.jarda função do Lambda. Um "uber" JAR (também conhecido como fat JAR ou JAR com dependências) é um arquivo.jarcom um programa Java e as respectivas dependências em um único arquivo. -
AthenaHiveMetastoreFunctionWithLayer: a camada do Lambda e o arquivo.jarfino da função do Lambda.
Fluxo de trabalho
O diagrama a seguir mostra como o Athena interage com o metastore externo do Hive.
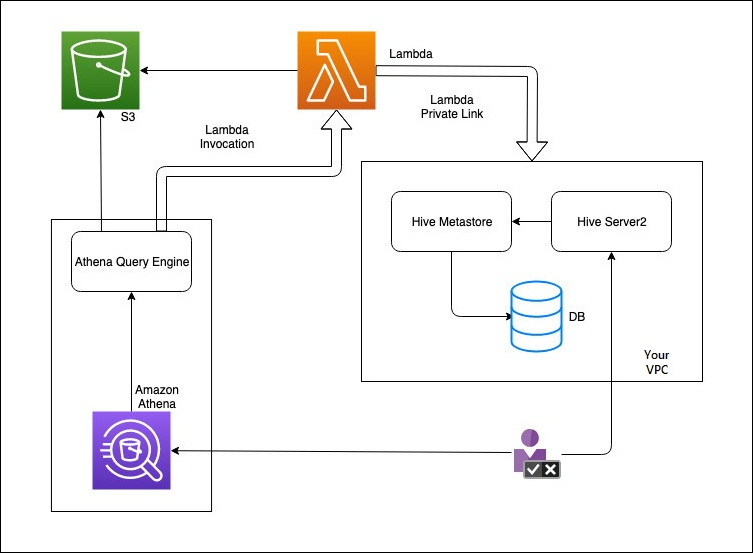
Neste fluxo de trabalho, o metastore do Hive conectado ao banco de dados está dentro da sua VPC. Você usa o Hive Server2 para gerenciar sua metastore do Hive usando a CLI do Hive.
O fluxo de trabalho para uso de metastores externos do Hive do Athena inclui as etapas a seguir.
-
Crie uma função do Lambda que conecte o Athena ao metastore do Hive que reside em sua VPC.
-
Registre um nome de catálogo exclusivo para seu metastore do Hive e um nome de função correspondente em sua conta.
-
Ao executar uma consulta DML ou DDL do Athena que usa o nome do catálogo, o mecanismo de consulta do Athena chama o nome da função do Lambda que você associou ao nome do catálogo.
-
Ao usar AWS PrivateLink, a função do Lambda se comunica com o metastore externo do Hive em sua VPC e recebe respostas às solicitações de metadados. O Athena usa os metadados do metastore externo do Hive da mesma forma que usa os metadados do AWS Glue Data Catalog padrão.
Considerações e limitações
Ao usar o conector de dados do Athena para metastore externo do Hive, considere os seguintes pontos:
-
É possível usar CTAS para criar uma tabela em um metastore do Hive externo.
-
É possível usar INSERT INTO para inserir dados em um metastore do Hive externo.
-
O suporte de DDL para metastore externo do Hive está limitado às instruções a seguir.
-
ALTER DATABASE SET DBPROPERTIES
-
ALTER TABLE ADD COLUMNS
-
ALTER TABLE ADD PARTITION
-
ALTER TABLE DROP PARTITION
-
ALTER TABLE RENAME PARTITION
-
ALTER TABLE REPLACE COLUMNS
-
ALTER TABLE SET LOCATION
-
ALTER TABLE SET TBLPROPERTIES
-
CREATE DATABASE
-
CRIAR TABELA
-
CREATE TABLE AS
-
DESCRIBE TABLE
-
DROP DATABASE
-
DESCARTAR TABELA
-
SHOW COLUMNS
-
SHOW CREATE TABLE
-
SHOW PARTITIONS
-
SHOW SCHEMAS
-
SHOW TABLES
-
SHOW TBLPROPERTIES
-
-
O número máximo de catálogos registrados que é possível ter é 1.000.
-
A autenticação Kerberos para o metastore do Hive não é compatível.
-
Para usar o driver JDBC com um metastore externo do Hive ou com consultas federadas, inclua
MetadataRetrievalMethod=ProxyAPIna string de conexão do JDBC. Para obter informações sobre o driver JDBC, consulte Conectar ao Amazon Athena com JDBC. -
As colunas ocultas do Hive
$path,$bucket,$file_size,$file_modified_time,$partitione$row_idnão podem ser usadas para filtragem de controle de acesso detalhada. -
Não há suporte para o controle de acesso detalhado para tabelas de sistema ocultas do Hive, como
example_table$partitionsexample_table$properties
Permissões
Conectores de dados predefinidos e personalizados podem exigir acesso aos recursos a seguir para funcionar corretamente. Verifique as informações do conector que você usa para confirmar se você configurou a VPC corretamente. Para obter informações sobre as permissões do IAM necessárias para executar consultas e criar um conector de origem dos dados no Athena, consulte Permitir a um metastore do Hive externo acesso a um conector de dados do Athena e Permitir acesso da função do Lambda aos metastores externos do Hive.
-
Amazon S3: além de gravar os resultados das consultas no local específico do Athena no Amazon S3, os conectores de dados gravam em um bucket de vazamento no Amazon S3. São necessárias conectividade e permissões para esse local do Amazon S3. Para obter mais informações, consulte Local de vazamento no Amazon S3 mais adiante neste tópico.
-
Athena: o acesso é necessário para conferir o status da consulta e evitar verificação em excesso.
-
AWS Glue: o acesso será necessário se o conector usar AWS Glue para metadados complementares ou primários.
-
AWS Key Management Service
-
Políticas: o metastore do Hive, o Athena Query Federation e as UDFs exigem políticas além da Política gerenciada pela AWS: AmazonAthenaFullAccess. Para ter mais informações, consulte Gerenciamento de identidade e acesso no Athena.
Local de vazamento no Amazon S3
Devido ao limite de tamanho de resposta da função do Lambda, as respostas que o ultrapassam são vazadas para um local no Amazon S3 especificado quando você cria a função do Lambda. O Athena lê essas respostas diretamente do Amazon S3.
nota
O Athena não remove os arquivos de resposta do Amazon S3. Recomendamos configurar uma política de retenção para excluir arquivos de resposta automaticamente.
