As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Invoque uma AWS Lambda função em um pipeline em CodePipeline
O AWS Lambda é um serviço de computação que permite executar código sem o provisionamento ou gerenciamento de servidores. É possível criar funções do Lambda e adicioná-las como ações em seus pipelines. Como o Lambda permite que você grave funções para executar praticamente qualquer tarefa, é possível personalizar a maneira como seu pipeline funciona.
Importante
Não registre o evento JSON que é CodePipeline enviado para o Lambda, pois isso pode fazer com que as credenciais do usuário sejam registradas no Logs. CloudWatch A CodePipeline função usa um evento JSON para passar credenciais temporárias para o Lambda no campo. artifactCredentials Para obter um evento de exemplo, consulte Exemplo de evento JSON.
Veja a seguir como as funções do Lambda podem ser usadas nos pipelines:
-
Para criar recursos sob demanda em um estágio de um pipeline usando CloudFormation e excluí-los em outro estágio.
-
Para implantar versões de aplicativos com zero tempo de inatividade AWS Elastic Beanstalk com uma função Lambda que troca valores de CNAME.
-
Para implantar instâncias do Docker no Amazon ECS.
-
Para fazer o backup de recursos antes da compilação ou implantação criando um snapshot do AMI.
-
Para adicionar integração de produtos de terceiros a seu pipeline, como postar mensagens para um cliente IRC.
nota
Criar e executar funções do Lambda pode resultar em cobranças em sua AWS conta. Para obter mais informações, consulte Preço
Este tópico pressupõe que você esteja familiarizado AWS CodePipeline AWS Lambda e saiba como criar pipelines, funções e as políticas e funções do IAM das quais eles dependem. Este tópico mostra como:
-
Criar uma função do Lambda que teste se um página da web foi implantada com êxito.
-
Configure as funções de execução CodePipeline e o Lambda e as permissões necessárias para executar a função como parte do pipeline.
-
Editar um pipeline para adicionar a função do Lambda como uma ação.
-
Testa a ação liberando uma alteração manualmente.
nota
Ao usar a ação de invocação Lambda entre regiões CodePipeline em, o status da execução lambda usando o PutJobFailureResulte deve ser enviado para PutJobSuccessResulta AWS região em que a função Lambda está presente e não para a região onde existe. CodePipeline
Este tópico inclui exemplos de funções para demonstrar a flexibilidade de trabalhar com funções Lambda em: CodePipeline
-
-
Criação de uma função Lambda básica para usar com. CodePipeline
-
Retornar resultados de sucesso ou falha CodePipeline no link Detalhes da ação.
-
-
Exemplo de função Python que usa um modelo AWS CloudFormation
-
Uso de parâmetros de usuário codificados com JSON para passar vários valores de configuração para a função (
get_user_params). -
Interação com artefatos .zip em um bucket de artefatos (
get_template). -
Uso de um token de continuação para monitorar um longo processo assíncrono (
continue_job_later). Isso permite que a ação continue e a função tenha êxito mesmo se exceder um runtime de quinze minutos (um limite no Lambda).
-
Cada função de exemplo inclui informações sobre as permissões que você deve adicionar à função. Para obter informações sobre limites em AWS Lambda, consulte Limites no Guia do AWS Lambda desenvolvedor.
Importante
O código de exemplo, as funções, e as políticas incluídos neste tópico servem somente como exemplos e são fornecidos no estado em que encontram.
Tópicos
Etapa 1: Criar um pipeline
Nesta etapa, você cria um pipeline ao qual adicionará a função do Lambda posteriormente. Este é o mesmo pipeline que você criou em CodePipeline tutoriais. Se esse pipeline ainda estiver configurado para sua conta e estiver na mesma região em que você planeja criar a função do Lambda, será possível ignorar esta etapa.
Para criar o pipeline
-
Siga as três primeiras etapas Tutorial: Criar um pipeline simples (bucket do S3) para criar um bucket do Amazon S3, CodeDeploy recursos e um pipeline de dois estágios. Escolha a opção Amazon Linux como tipos de instância. Você pode usar o nome que quiser para o pipeline, mas as etapas neste tópico utilizam MyLambdaTestPipeline.
-
Na página de status do seu funil, na CodeDeploy ação, escolha Detalhes. Na página de detalhes de implantação para o grupo de implantação, escolha uma ID de instância a partir da lista.
-
No console do Amazon EC2, na guia Detalhes da instância, copie o endereço IP em IPv4 Endereço público (por exemplo,
192.0.2.4). Você usa esse endereço como o destino da função no AWS Lambda.
nota
A política de função de serviço padrão do CodePipeline inclui as permissões do Lambda necessárias para invocar a função. No entanto, se você alterou a função de serviço padrão ou selecionou uma diferente, certifique-se de que a política para a função comporte as permissões lambda:InvokeFunction e lambda:ListFunctions. Caso contrário, haverá falha nos pipelines que incluem ações do Lambda.
Etapa 2: Criar a função do Lambda
Nesta etapa, você cria uma função do Lambda que faz uma solicitação HTTP e procura uma linha de texto em uma página da web. Como parte desta etapa, você também deve criar uma política do IAM e um perfil de execução do Lambda. Para obter mais informações, consulte Modelo de permissões no Guia do desenvolvedor do AWS Lambda .
Para criar a função de execução
Faça login no Console de gerenciamento da AWS e abra o console do IAM em https://console.aws.amazon.com/iam/
. -
Escolha Policies (Políticas) e depois Create Policy (Criar política). Escolha a guia JSON e depois cole a política a seguir no campo.
-
Selecione Revisar política.
-
Na página Review policy (Revisar política), em Name (Nome), digite um nome para a política (por exemplo,
CodePipelineLambdaExecPolicy). Em Description (Descrição), insiraEnables Lambda to execute code.Escolha Create Policy.
nota
Essas são as permissões mínimas necessárias para que uma função Lambda interopere CodePipeline com a Amazon. CloudWatch Se você quiser expandir essa política para permitir funções que interajam com outros AWS recursos, modifique essa política para permitir as ações exigidas por essas funções do Lambda.
-
Na página do painel da política, selecione Roles (Funções) e, depois, Create role (Criar função).
-
Na página Criar perfil, escolha AWS service (Serviço da AWS). Selecione Lambda, e, então, selecione Next: Permissions (Próximo: permissões).
-
Na página Attach permissions policies (Anexar políticas de permissões), marque a caixa de seleção ao lado de CodePipelineLambdaExecPolicy e, então, selecione Next: Tags (Próximo: tags). Escolha Próximo: revisar.
-
Na página Review (Revisar), em Role name (Nome da função), insira o nome e depois escolha Create role (Criar função).
Para criar a função Lambda de amostra para usar com CodePipeline
Faça login no Console de gerenciamento da AWS e abra o AWS Lambda console em https://console.aws.amazon.com/lambda/
. -
Na página Functions (Funções), escolha Create function (Criar função).
nota
Caso veja uma página de Boas-vindas, em vez da página do Lambda, escolha Comece a usar agora.
-
Na página Create function, selecione Author from scratch. Em Nome da função, insira um nome para a função do Lambda (por exemplo,
MyLambdaFunctionForAWSCodePipeline). Em Runtime, escolha Node.js 20.x. -
Em Role (Função), selecione Choose an existing role (Selecionar uma função existente). Em Existing role (Função existente), escolha sua função, e depois escolha Create function (Criar função).
A página de detalhes da função criada é aberta.
-
Copie o código a seguir na caixa Function code (Código da função):
nota
O objeto de evento, sob a chave CodePipeline .job, contém os detalhes do trabalho. Para ver um exemplo completo do CodePipeline retorno do evento JSON ao Lambda, consulte. Exemplo de evento JSON
import { CodePipelineClient, PutJobSuccessResultCommand, PutJobFailureResultCommand } from "@aws-sdk/client-codepipeline"; import http from 'http'; import assert from 'assert'; export const handler = (event, context) => { const codepipeline = new CodePipelineClient(); // Retrieve the Job ID from the Lambda action const jobId = event["CodePipeline.job"].id; // Retrieve the value of UserParameters from the Lambda action configuration in CodePipeline, in this case a URL which will be // health checked by this function. const url = event["CodePipeline.job"].data.actionConfiguration.configuration.UserParameters; // Notify CodePipeline of a successful job const putJobSuccess = async function(message) { const command = new PutJobSuccessResultCommand({ jobId: jobId }); try { await codepipeline.send(command); context.succeed(message); } catch (err) { context.fail(err); } }; // Notify CodePipeline of a failed job const putJobFailure = async function(message) { const command = new PutJobFailureResultCommand({ jobId: jobId, failureDetails: { message: JSON.stringify(message), type: 'JobFailed', externalExecutionId: context.awsRequestId } }); await codepipeline.send(command); context.fail(message); }; // Validate the URL passed in UserParameters if(!url || url.indexOf('http://') === -1) { putJobFailure('The UserParameters field must contain a valid URL address to test, including http:// or https://'); return; } // Helper function to make a HTTP GET request to the page. // The helper will test the response and succeed or fail the job accordingly const getPage = function(url, callback) { var pageObject = { body: '', statusCode: 0, contains: function(search) { return this.body.indexOf(search) > -1; } }; http.get(url, function(response) { pageObject.body = ''; pageObject.statusCode = response.statusCode; response.on('data', function (chunk) { pageObject.body += chunk; }); response.on('end', function () { callback(pageObject); }); response.resume(); }).on('error', function(error) { // Fail the job if our request failed putJobFailure(error); }); }; getPage(url, function(returnedPage) { try { // Check if the HTTP response has a 200 status assert(returnedPage.statusCode === 200); // Check if the page contains the text "Congratulations" // You can change this to check for different text, or add other tests as required assert(returnedPage.contains('Congratulations')); // Succeed the job putJobSuccess("Tests passed."); } catch (ex) { // If any of the assertions failed then fail the job putJobFailure(ex); } }); }; -
Deixe Handler (Manipulador) como o valor padrão e deixe Role (Função) como padrão
CodePipelineLambdaExecRole. -
Em Basic settings (Configurações básicas), para Timeout (Tempo limite), insira
20segundos. -
Escolha Salvar.
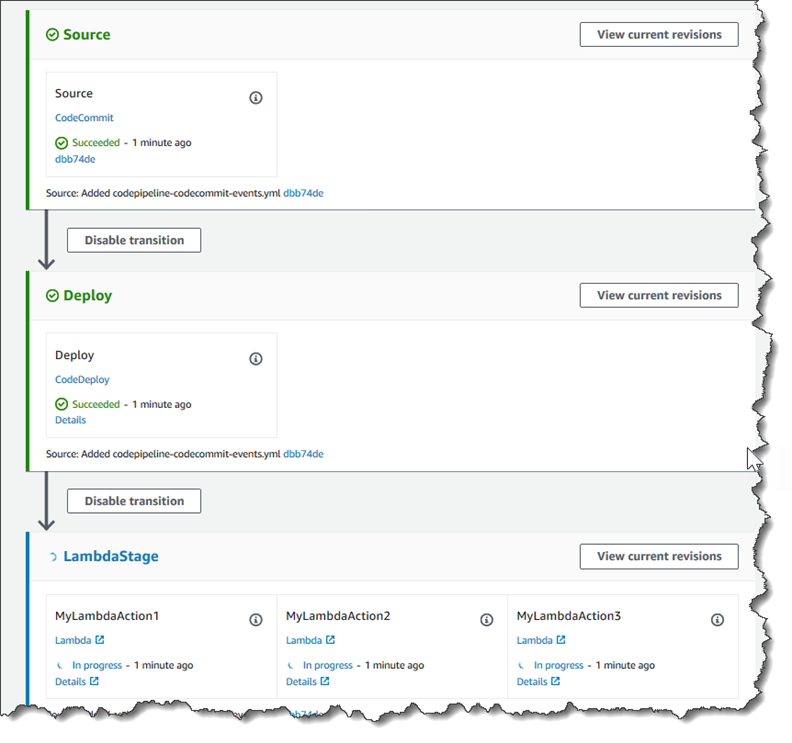
Etapa 3: adicionar a função Lambda a um pipeline no console CodePipeline
Nesta etapa, você adiciona um novo estágio a seu pipeline e, em seguida, adiciona uma ação do Lambda que chama sua função nesse estágio.
Para adicionar um estágio
Faça login no Console de gerenciamento da AWS e abra o CodePipeline console em http://console.aws.amazon. com/codesuite/codepipeline/home
. -
Na página Welcome (Bem-vindo), escolha o pipeline que criou.
-
Na página de visualização do pipeline, selecione Editar.
-
Na página Editar, escolha + Adicionar estágio para adicionar um estágio após o estágio de implantação com a CodeDeploy ação. Insira um nome (por exemplo,
LambdaStage) e escolha o Add stage (Adicionar estágio).nota
Você também pode optar por adicionar a ação do Lambda a um estágio existente. Para fins de demonstração, estamos adicionando a função do Lambda como a única ação em um estágio que permite a você visualizar facilmente seu progresso à medida que os artefatos progridem em um pipeline.
-
Escolha + Add action group (Adicionar grupo de ação). Em Editar ação, em Nome da ação, insira um nome para sua ação do Lambda (por exemplo,
MyLambdaAction). Em Provider (Provedor), selecione AWS Lambda. Em Nome da função, selecione ou insira o nome da sua função do Lambda (por exemplo,MyLambdaFunctionForAWSCodePipeline). Em Parâmetros do usuário, especifique o endereço IP da instância do Amazon EC2 que você copiou anteriormente (por exemplo,http://) e escolha Concluído.192.0.2.4nota
Este tópico usa um endereço IP, mas em um cenário do mundo real, você pode fornecer o nome do site registrado (por exemplo,
http://). Para obter mais informações sobre dados de eventos e manipuladores em AWS Lambda, consulte Modelo de programação no Guia do AWS Lambda desenvolvedor.www.example.com -
Na página Edit action (Editar ação), escolha Save (Salvar).
Etapa 4: Testar o pipeline com a função do Lambda
Para testar a função, libere a alteração mais recente pelo pipeline.
Para usar o console para executar a versão mais recente de um artefato através de um pipeline
-
Na página de detalhes do pipeline, escolha Lançar alteração. Essa ação executa a revisão mais recente disponível em cada local de origem especificado em uma ação de origem do pipeline.
-
Quando a ação do Lambda for concluída, escolha o link Detalhes para visualizar o fluxo de log da função na Amazon CloudWatch, incluindo a duração faturada do evento. Se a função falhar, o CloudWatch registro fornecerá informações sobre a causa.
Etapa 5: Próximas etapas
Agora que você criou uma função do Lambda com êxito e a adicionou como uma ação em um pipeline, tente o seguinte:
-
Adicione mais ações do Lambda ao seu estágio para verificar outras páginas da web.
-
Modifique a função do Lambda para procurar outra string de texto.
-
Explore as funções do Lambda e crie e adicione suas próprias funções do Lambda aos pipelines.
Depois de terminar de experimentar a função Lambda, considere removê-la do pipeline, excluí-la e excluir a função AWS Lambda do IAM para evitar possíveis cobranças. Para obter mais informações, consulte Editar um pipeline no CodePipeline, Excluir um pipeline no CodePipeline. e Exclusão de funções ou de perfis de instância.
Exemplo de evento JSON
O exemplo a seguir mostra um exemplo de evento JSON enviado ao CodePipeline Lambda por. A estrutura deste evento é semelhante à resposta à GetJobDetails API, mas sem os tipos de dados actionTypeId e pipelineContext. Dois detalhes de configuração da ação, FunctionName e UserParameters, estão incluídos no evento JSON e na resposta à API GetJobDetails. Os valores em red italic text são exemplos ou explicações, não valores reais.
{ "CodePipeline.job": { "id": "11111111-abcd-1111-abcd-111111abcdef", "accountId": "111111111111", "data": { "actionConfiguration": { "configuration": { "FunctionName": "MyLambdaFunctionForAWSCodePipeline", "UserParameters": "some-input-such-as-a-URL" } }, "inputArtifacts": [ { "location": { "s3Location": { "bucketName": "the name of the bucket configured as the pipeline artifact store in Amazon S3, for example codepipeline-us-east-2-1234567890", "objectKey": "the name of the application, for example CodePipelineDemoApplication.zip" }, "type": "S3" }, "revision": null, "name": "ArtifactName" } ], "outputArtifacts": [], "artifactCredentials": { "secretAccessKey": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY", "sessionToken": "MIICiTCCAfICCQD6m7oRw0uXOjANBgkqhkiG9w 0BAQUFADCBiDELMAkGA1UEBhMCVVMxCzAJBgNVBAgTAldBMRAwDgYDVQQHEwdTZ WF0dGxlMQ8wDQYDVQQKEwZBbWF6b24xFDASBgNVBAsTC0lBTSBDb25zb2xlMRIw EAYDVQQDEwlUZXN0Q2lsYWMxHzAdBgkqhkiG9w0BCQEWEG5vb25lQGFtYXpvbi5 jb20wHhcNMTEwNDI1MjA0NTIxWhcNMTIwNDI0MjA0NTIxWjCBiDELMAkGA1UEBh MCVVMxCzAJBgNVBAgTAldBMRAwDgYDVQQHEwdTZWF0dGxlMQ8wDQYDVQQKEwZBb WF6b24xFDASBgNVBAsTC0lBTSBDb25zb2xlMRIwEAYDVQQDEwlUZXN0Q2lsYWMx HzAdBgkqhkiG9w0BCQEWEG5vb25lQGFtYXpvbi5jb20wgZ8wDQYJKoZIhvcNAQE BBQADgY0AMIGJAoGBAMaK0dn+a4GmWIWJ21uUSfwfEvySWtC2XADZ4nB+BLYgVI k60CpiwsZ3G93vUEIO3IyNoH/f0wYK8m9TrDHudUZg3qX4waLG5M43q7Wgc/MbQ ITxOUSQv7c7ugFFDzQGBzZswY6786m86gpEIbb3OhjZnzcvQAaRHhdlQWIMm2nr AgMBAAEwDQYJKoZIhvcNAQEFBQADgYEAtCu4nUhVVxYUntneD9+h8Mg9q6q+auN KyExzyLwaxlAoo7TJHidbtS4J5iNmZgXL0FkbFFBjvSfpJIlJ00zbhNYS5f6Guo EDmFJl0ZxBHjJnyp378OD8uTs7fLvjx79LjSTbNYiytVbZPQUQ5Yaxu2jXnimvw 3rrszlaEXAMPLE=", "accessKeyId": "AKIAIOSFODNN7EXAMPLE" }, "continuationToken": "A continuation token if continuing job", "encryptionKey": { "id": "arn:aws:kms:us-west-2:111122223333:key/1234abcd-12ab-34cd-56ef-1234567890ab", "type": "KMS" } } } }
Funções de exemplo adicionais
Os exemplos de funções do Lambda a seguir demonstram funcionalidades adicionais que você pode usar para seus pipelines em. CodePipeline Para usar essas funções, talvez você tenha que modificar a política para a função de execução do Lambda, como observado na introdução de cada exemplo.
Exemplo de função Python que usa um modelo AWS CloudFormation
O exemplo a seguir mostra uma função que cria ou atualiza uma pilha com base em um CloudFormation modelo fornecido. O modelo cria um bucket do Amazon S3. É somente para fins de demonstração, para minimizar custos. O ideal é que você exclua a stack antes de carregar algo no bucket. Se carregar arquivos no bucket, você não poderá excluir o bucket quando excluir a stack. Você deve excluir manualmente tudo no bucket antes que possa excluir o próprio bucket.
Esse exemplo de Python supõe que você tenha um pipeline que use um bucket do Amazon S3 como ação de origem ou que você tenha acesso a um bucket do Amazon S3 com controle de versão que possa ser usado com o pipeline. Você cria o CloudFormation modelo, o compacta e faz o upload para esse bucket como um arquivo.zip. Você deve então adicionar uma ação de origem a seu pipeline que recupere esse arquivo .zip do bucket.
nota
Quando o Amazon S3 é o provedor de origem do pipeline, é possível compactar o(s) arquivo(s) de origem em um único .zip e fazer upload do .zip para o bucket de origem. Também é possível fazer upload de um único arquivo descompactado; no entanto, ocorrerão falha nas ações downstream que aguardam um arquivo .zip.
Esse exemplo demonstra:
-
O uso de parâmetros de usuário codificados com JSON para passar vários valores de configuração para a função (
get_user_params). -
A interação com artefatos .zip em um bucket de artefatos (
get_template). -
O uso de um token de continuação para monitorar um longo processo assíncrono (
continue_job_later). Isso permite que a ação continue e a função tenha êxito mesmo se exceder um runtime de quinze minutos (um limite no Lambda).
Para usar esse exemplo de função do Lambda, a política para a função de execução do Lambda deve ter Allow permissões no Amazon CloudFormation S3 e CodePipeline, conforme mostrado neste exemplo de política:
Para criar o CloudFormation modelo, abra qualquer editor de texto sem formatação e copie e cole o seguinte código:
{ "AWSTemplateFormatVersion" : "2010-09-09", "Description" : "CloudFormation template which creates an S3 bucket", "Resources" : { "MySampleBucket" : { "Type" : "AWS::S3::Bucket", "Properties" : { } } }, "Outputs" : { "BucketName" : { "Value" : { "Ref" : "MySampleBucket" }, "Description" : "The name of the S3 bucket" } } }
Salve isso como um arquivo JSON com o nome template.json em um diretório chamado template-package. Crie um arquivo compactado (.zip) desse diretório e do arquivo chamado template-package.zip e faça upload do arquivo compactado em um bucket do Amazon S3 com controle de versão. Se já tiver um bucket configurado para seu pipeline, você poderá usá-lo. Em seguida, edite o pipeline para adicionar uma ação de origem que recupere o arquivo .zip. Nomeie a saída para essa açãoMyTemplate. Para obter mais informações, consulte Editar um pipeline no CodePipeline.
nota
O exemplo de função do Lambda espera esses nomes de arquivos e estrutura compactada. No entanto, você pode substituir esse exemplo por seu próprio CloudFormation modelo. Se você usar seu próprio modelo, certifique-se de modificar a política da função de execução do Lambda para permitir qualquer funcionalidade adicional exigida pelo seu CloudFormation modelo.
Para adicionar o código a seguir como uma função no Lambda
-
Abra o console do Lambda e escolha Criar função.
-
Na página Create function, selecione Author from scratch. Em Nome da função, insira um nome para a função do Lambda.
-
Em Runtime (Tempo de execução), escolha Python 2.7.
-
Em Escolher ou criar uma função de execução, selecione Usar um perfil existente. Em Existing role (Função existente), escolha sua função, e depois escolha Create function (Criar função).
A página de detalhes da função criada é aberta.
-
Copie o código a seguir na caixa Function code (Código da função):
from __future__ import print_function from boto3.session import Session import json import urllib import boto3 import zipfile import tempfile import botocore import traceback print('Loading function') cf = boto3.client('cloudformation') code_pipeline = boto3.client('codepipeline') def find_artifact(artifacts, name): """Finds the artifact 'name' among the 'artifacts' Args: artifacts: The list of artifacts available to the function name: The artifact we wish to use Returns: The artifact dictionary found Raises: Exception: If no matching artifact is found """ for artifact in artifacts: if artifact['name'] == name: return artifact raise Exception('Input artifact named "{0}" not found in event'.format(name)) def get_template(s3, artifact, file_in_zip): """Gets the template artifact Downloads the artifact from the S3 artifact store to a temporary file then extracts the zip and returns the file containing the CloudFormation template. Args: artifact: The artifact to download file_in_zip: The path to the file within the zip containing the template Returns: The CloudFormation template as a string Raises: Exception: Any exception thrown while downloading the artifact or unzipping it """ tmp_file = tempfile.NamedTemporaryFile() bucket = artifact['location']['s3Location']['bucketName'] key = artifact['location']['s3Location']['objectKey'] with tempfile.NamedTemporaryFile() as tmp_file: s3.download_file(bucket, key, tmp_file.name) with zipfile.ZipFile(tmp_file.name, 'r') as zip: return zip.read(file_in_zip) def update_stack(stack, template): """Start a CloudFormation stack update Args: stack: The stack to update template: The template to apply Returns: True if an update was started, false if there were no changes to the template since the last update. Raises: Exception: Any exception besides "No updates are to be performed." """ try: cf.update_stack(StackName=stack, TemplateBody=template) return True except botocore.exceptions.ClientError as e: if e.response['Error']['Message'] == 'No updates are to be performed.': return False else: raise Exception('Error updating CloudFormation stack "{0}"'.format(stack), e) def stack_exists(stack): """Check if a stack exists or not Args: stack: The stack to check Returns: True or False depending on whether the stack exists Raises: Any exceptions raised .describe_stacks() besides that the stack doesn't exist. """ try: cf.describe_stacks(StackName=stack) return True except botocore.exceptions.ClientError as e: if "does not exist" in e.response['Error']['Message']: return False else: raise e def create_stack(stack, template): """Starts a new CloudFormation stack creation Args: stack: The stack to be created template: The template for the stack to be created with Throws: Exception: Any exception thrown by .create_stack() """ cf.create_stack(StackName=stack, TemplateBody=template) def get_stack_status(stack): """Get the status of an existing CloudFormation stack Args: stack: The name of the stack to check Returns: The CloudFormation status string of the stack such as CREATE_COMPLETE Raises: Exception: Any exception thrown by .describe_stacks() """ stack_description = cf.describe_stacks(StackName=stack) return stack_description['Stacks'][0]['StackStatus'] def put_job_success(job, message): """Notify CodePipeline of a successful job Args: job: The CodePipeline job ID message: A message to be logged relating to the job status Raises: Exception: Any exception thrown by .put_job_success_result() """ print('Putting job success') print(message) code_pipeline.put_job_success_result(jobId=job) def put_job_failure(job, message): """Notify CodePipeline of a failed job Args: job: The CodePipeline job ID message: A message to be logged relating to the job status Raises: Exception: Any exception thrown by .put_job_failure_result() """ print('Putting job failure') print(message) code_pipeline.put_job_failure_result(jobId=job, failureDetails={'message': message, 'type': 'JobFailed'}) def continue_job_later(job, message): """Notify CodePipeline of a continuing job This will cause CodePipeline to invoke the function again with the supplied continuation token. Args: job: The JobID message: A message to be logged relating to the job status continuation_token: The continuation token Raises: Exception: Any exception thrown by .put_job_success_result() """ # Use the continuation token to keep track of any job execution state # This data will be available when a new job is scheduled to continue the current execution continuation_token = json.dumps({'previous_job_id': job}) print('Putting job continuation') print(message) code_pipeline.put_job_success_result(jobId=job, continuationToken=continuation_token) def start_update_or_create(job_id, stack, template): """Starts the stack update or create process If the stack exists then update, otherwise create. Args: job_id: The ID of the CodePipeline job stack: The stack to create or update template: The template to create/update the stack with """ if stack_exists(stack): status = get_stack_status(stack) if status not in ['CREATE_COMPLETE', 'ROLLBACK_COMPLETE', 'UPDATE_COMPLETE']: # If the CloudFormation stack is not in a state where # it can be updated again then fail the job right away. put_job_failure(job_id, 'Stack cannot be updated when status is: ' + status) return were_updates = update_stack(stack, template) if were_updates: # If there were updates then continue the job so it can monitor # the progress of the update. continue_job_later(job_id, 'Stack update started') else: # If there were no updates then succeed the job immediately put_job_success(job_id, 'There were no stack updates') else: # If the stack doesn't already exist then create it instead # of updating it. create_stack(stack, template) # Continue the job so the pipeline will wait for the CloudFormation # stack to be created. continue_job_later(job_id, 'Stack create started') def check_stack_update_status(job_id, stack): """Monitor an already-running CloudFormation update/create Succeeds, fails or continues the job depending on the stack status. Args: job_id: The CodePipeline job ID stack: The stack to monitor """ status = get_stack_status(stack) if status in ['UPDATE_COMPLETE', 'CREATE_COMPLETE']: # If the update/create finished successfully then # succeed the job and don't continue. put_job_success(job_id, 'Stack update complete') elif status in ['UPDATE_IN_PROGRESS', 'UPDATE_ROLLBACK_IN_PROGRESS', 'UPDATE_ROLLBACK_COMPLETE_CLEANUP_IN_PROGRESS', 'CREATE_IN_PROGRESS', 'ROLLBACK_IN_PROGRESS', 'UPDATE_COMPLETE_CLEANUP_IN_PROGRESS']: # If the job isn't finished yet then continue it continue_job_later(job_id, 'Stack update still in progress') else: # If the Stack is a state which isn't "in progress" or "complete" # then the stack update/create has failed so end the job with # a failed result. put_job_failure(job_id, 'Update failed: ' + status) def get_user_params(job_data): """Decodes the JSON user parameters and validates the required properties. Args: job_data: The job data structure containing the UserParameters string which should be a valid JSON structure Returns: The JSON parameters decoded as a dictionary. Raises: Exception: The JSON can't be decoded or a property is missing. """ try: # Get the user parameters which contain the stack, artifact and file settings user_parameters = job_data['actionConfiguration']['configuration']['UserParameters'] decoded_parameters = json.loads(user_parameters) except Exception as e: # We're expecting the user parameters to be encoded as JSON # so we can pass multiple values. If the JSON can't be decoded # then fail the job with a helpful message. raise Exception('UserParameters could not be decoded as JSON') if 'stack' not in decoded_parameters: # Validate that the stack is provided, otherwise fail the job # with a helpful message. raise Exception('Your UserParameters JSON must include the stack name') if 'artifact' not in decoded_parameters: # Validate that the artifact name is provided, otherwise fail the job # with a helpful message. raise Exception('Your UserParameters JSON must include the artifact name') if 'file' not in decoded_parameters: # Validate that the template file is provided, otherwise fail the job # with a helpful message. raise Exception('Your UserParameters JSON must include the template file name') return decoded_parameters def setup_s3_client(job_data): """Creates an S3 client Uses the credentials passed in the event by CodePipeline. These credentials can be used to access the artifact bucket. Args: job_data: The job data structure Returns: An S3 client with the appropriate credentials """ key_id = job_data['artifactCredentials']['accessKeyId'] key_secret = job_data['artifactCredentials']['secretAccessKey'] session_token = job_data['artifactCredentials']['sessionToken'] session = Session(aws_access_key_id=key_id, aws_secret_access_key=key_secret, aws_session_token=session_token) return session.client('s3', config=botocore.client.Config(signature_version='s3v4')) def lambda_handler(event, context): """The Lambda function handler If a continuing job then checks the CloudFormation stack status and updates the job accordingly. If a new job then kick of an update or creation of the target CloudFormation stack. Args: event: The event passed by Lambda context: The context passed by Lambda """ try: # Extract the Job ID job_id = event['CodePipeline.job']['id'] # Extract the Job Data job_data = event['CodePipeline.job']['data'] # Extract the params params = get_user_params(job_data) # Get the list of artifacts passed to the function artifacts = job_data['inputArtifacts'] stack = params['stack'] artifact = params['artifact'] template_file = params['file'] if 'continuationToken' in job_data: # If we're continuing then the create/update has already been triggered # we just need to check if it has finished. check_stack_update_status(job_id, stack) else: # Get the artifact details artifact_data = find_artifact(artifacts, artifact) # Get S3 client to access artifact with s3 = setup_s3_client(job_data) # Get the JSON template file out of the artifact template = get_template(s3, artifact_data, template_file) # Kick off a stack update or create start_update_or_create(job_id, stack, template) except Exception as e: # If any other exceptions which we didn't expect are raised # then fail the job and log the exception message. print('Function failed due to exception.') print(e) traceback.print_exc() put_job_failure(job_id, 'Function exception: ' + str(e)) print('Function complete.') return "Complete." -
Deixe Manipulador com o valor padrão e Perfil com o nome que você selecionou ou criou anteriormente,
CodePipelineLambdaExecRole. -
Em Basic settings (Configurações básicas), para Timeout (Tempo limite), substitua o padrão de 3 segundos por
20. -
Escolha Salvar.
-
No CodePipeline console, edite o pipeline para adicionar a função como uma ação em um estágio do seu pipeline. Escolha Editar para o estágio do pipeline que você deseja alterar e escolha Adicionar grupo de ações. Na página Editar ação, em Nome da ação, insira um nome para a ação. Em Provedor de ação, selecione Lambda.
Em Artefatos de entrada, escolha
MyTemplate. Em UserParameters, você deve fornecer uma string JSON com três parâmetros:-
Nome da pilha
-
CloudFormation nome do modelo e caminho para o arquivo
-
Artefato de entrada
Use chaves ({ }) e separe os parâmetros com vírgulas. Por exemplo, para criar uma pilha chamada
MyTestStack, para um pipeline com o artefatoMyTemplatede entrada, insira: {"stack”:”MyTestStack“UserParameters, "file” :"template-package/template.json”, "artifact”:” “}.MyTemplatenota
Mesmo que você tenha especificado o artefato de entrada em UserParameters, você também deve especificar esse artefato de entrada para a ação em Artefatos de entrada.
-
-
Salve as alterações efetuadas no pipeline e libere manualmente uma alteração para testar a ação e função do Lambda.
