As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Conectar-se ao Amazon DocumentDB como um conjunto de réplicas
Ao desenvolver no Amazon DocumentDB (compatível com MongoDB), recomendamos que você se conecte ao cluster como um conjunto de réplicas e distribua leituras para instâncias de réplica usando os recursos integrados de preferência de leitura do seu driver. Esta seção detalha o que isso significa e descreve como é possível se conectar ao seu cluster do Amazon DocumentDB como um conjunto de réplicas usando o SDK for Python como exemplo.
O Amazon DocumentDB tem três endpoints que podem ser usados para se conectar ao cluster:
-
Endpoint do cluster
-
Endpoint de leitor
-
Endpoints da instância
Na maioria dos casos, quando você se conecta ao Amazon DocumentDB, recomendamos o uso do endpoint do cluster. Isso é um CNAME que aponta para a instância principal no cluster, conforme mostrado no diagrama a seguir.
Ao usar um túnel SSH, recomendamos que você se conecte ao cluster usando o endpoint do cluster e não tente se conectar no modo de conjunto de réplicas (ou seja, especificando replicaSet=rs0 em sua string de conexão), pois isso resultará em um erro.
nota
Para obter mais informações sobre endpoints do Amazon DocumentDB, consulte Endpoints do Amazon DocumentDB.
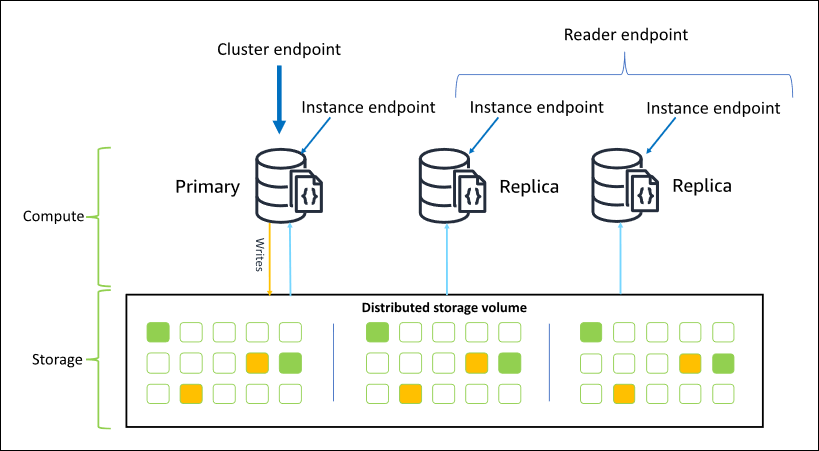
Ao usar o endpoint do cluster, é possível se conectar ao cluster no modo de conjunto de réplicas. Depois, você poderá usar os recursos integrados do driver de preferência de leitura. No exemplo a seguir, especificar /?replicaSet=rs0 significa para o SDK que você deseja se conectar como um conjunto de réplicas. Se você omitir /?replicaSet=rs0', o cliente roteará todas as solicitações para o endpoint do cluster, ou seja, sua instância principal.
## Create a MongoDB client, open a connection to Amazon DocumentDB as a ## replica set and specify the read preference as secondary preferred client = pymongo.MongoClient('mongodb://<user-name>:<password>@mycluster.node.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0')
A vantagem de se conectar como um conjunto de réplicas é que isso permite que o SDK descubra a topografia do cluster automaticamente, incluindo quando as instâncias são adicionadas ou removidas do cluster. Você poderá usar seu cluster de forma mais eficiente roteando solicitações de leitura para suas instâncias de réplica.
Ao se conectar como um conjunto de réplicas, é possível especificar a readPreference para a conexão. Se você especificar uma preferência de leitura de secondaryPreferred, o cliente roteará as consultas de leitura para suas réplicas e as consultas de gravação para sua instância principal (como no diagrama a seguir). Esse é um uso melhor dos recursos do cluster. Para obter mais informações, consulte Opções de preferência de leitura.
## Create a MongoDB client, open a connection to Amazon DocumentDB as a ## replica set and specify the read preference as secondary preferred client = pymongo.MongoClient('mongodb://<user-name>:<password>@mycluster.node.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0&readPreference=secondaryPreferred')
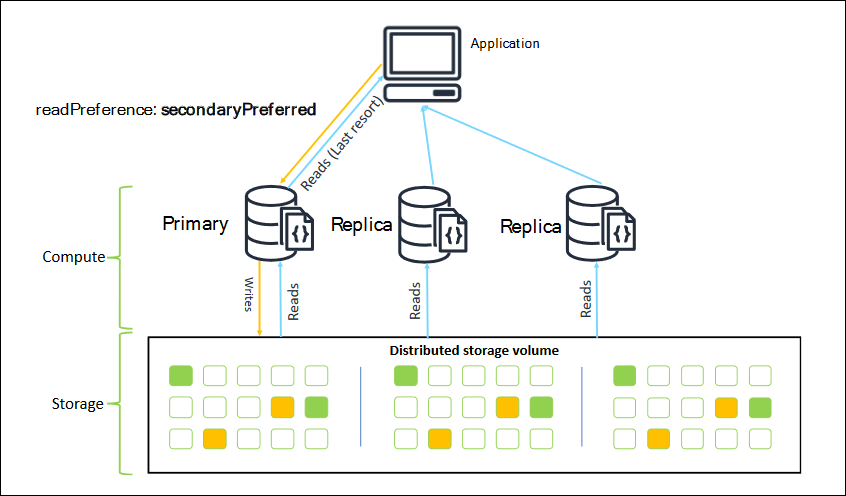
As leituras de réplicas do Amazon DocumentDB são eventualmente consistentes. Elas retornam os dados na mesma ordem em que foram gravados na instância principal, e geralmente há menos de 50 ms de tempo de atraso de replicação. Você pode monitorar o atraso da réplica do seu cluster usando as CloudWatch métricas da Amazon e. DBInstanceReplicaLag DBClusterReplicaLagMaximum Para obter mais informações, consulte Monitorando o Amazon DocumentDB com CloudWatch.
Diferentemente da arquitetura de banco de dados monolítica tradicional, o Amazon DocumentDB separa o armazenamento e a computação. Considerando essa arquitetura moderna, recomendamos que você faça a escalabilidade de leitura nas instâncias de réplica. As leituras nas instâncias de réplica não bloqueiam as gravações que são replicadas a partir da instância principal. É possível adicionar até 15 instâncias de réplica de leitura em um cluster e expandir para milhões de leituras por segundo.
O principal benefício de se conectar como um conjunto de réplicas e distribuir leituras para réplicas é que ele aumenta os recursos gerais em seu cluster que estão disponíveis para trabalhar em sua aplicação. Como uma melhor prática, recomendamos conectar-se como um conjunto de réplicas. Além disso, recomendamos que isso seja feito mais comumente nos seguintes cenários:
-
Você está usando quase 100% de CPU na principal.
-
A proporção de acertos do cache em buffer é próxima de zero.
-
Você atinge os limites de conexão ou de cursor para uma instância individual.
Expandir o tamanho de uma instância de cluster é uma opção e, em alguns casos, essa pode ser a melhor maneira de escalar o cluster. Mas você também deve considerar como usar melhor as réplicas que já tem em seu cluster. Isso permite aumentar a escala sem o aumento do custo de usar um tipo de instância maior. Também recomendamos que você monitore e alerte sobre esses limites (ou seja CPUUtilizationDatabaseConnections, eBufferCacheHitRatio) usando CloudWatch alarmes para saber quando um recurso está sendo muito usado.
Para obter mais informações, consulte os tópicos a seguir.
Usar conexões de cluster
Considere o cenário de uso de todas as conexões em seu cluster. Por exemplo, uma instância r5.2xlarge tem um limite de 4.500 conexões (e 450 cursores abertos). Se você criar um cluster do Amazon DocumentDB de três instâncias e se conectar somente à instância principal usando o endpoint do cluster, os limites do cluster para conexões abertas e cursores serão 4.500 e 450, respectivamente. Talvez você atinja esses limites se estiver criando aplicações que usem muitos operadores que sejam configurados em contêineres. Os contêineres abrem várias conexões de uma só vez e saturam o cluster.
Em vez disso, é possível se conectar ao cluster do Amazon DocumentDB como um conjunto de réplicas e distribuir suas leituras para as instâncias de réplica. Depois, é possível efetivamente triplicar o número de conexões e cursores disponíveis no cluster para 13.500 e 1.350, respectivamente. Adicionar mais instâncias ao cluster só aumentará o número de conexões e cursores para workloads de leitura. Se for necessário aumentar o número de conexões para gravações em seu cluster, recomendamos aumentar o tamanho da instância.
nota
O número de conexões para instâncias large, xlarge e 2xlarge aumenta com o tamanho da instância, chegando até 4.500. O número máximo de conexões por instância para instâncias 4xlarge ou maiores é 4.500. Para obter mais informações sobre limites por tipos de instância, consulte Limites de instâncias.
Normalmente, não recomendamos que você se conecte ao cluster usando a preferência de leitura de secondary. Isso ocorre porque, se não houver instâncias de réplica no cluster, haverá falha nas leituras. Por exemplo, suponha que você tenha um cluster do Amazon DocumentDB de duas instâncias com uma principal e uma de réplica. Se a instância de réplica tiver um problema, haverá falha nas solicitações de leitura de um grupo de conexão que esteja definido como secondary. A vantagem de secondaryPreferred é que, se o cliente não conseguir encontrar uma instância de réplica adequada à qual se conectar, ele voltará para a principal para leituras.
Vários grupos de conexões
Em alguns cenários, as leituras em um aplicativo precisam ter read-after-write consistência, que só pode ser atendida a partir da instância primária no Amazon DocumentDB. Nesses cenários, você pode criar dois pools de conexões de clientes: um para gravações e outro para leituras que precisam de read-after-write consistência. Para fazer isso, seu código deve ser semelhante ao seguinte:
## Create a MongoDB client, ## open a connection to Amazon DocumentDB as a replica set and specify the readPreference as primary clientPrimary = pymongo.MongoClient('mongodb://<user-name>:<password>@mycluster.node.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0&readPreference=primary') ## Create a MongoDB client, ## open a connection to Amazon DocumentDB as a replica set and specify the readPreference as secondaryPreferred secondaryPreferred = pymongo.MongoClient('mongodb://<user-name>:<password>@mycluster.node.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0&readPreference=secondaryPreferred')
Outra opção é criar um único grupo de conexões e substituir a preferência de leitura para uma determinada coleção.
##Specify the collection and set the read preference level for that collection col = db.review.with_options(read_preference=ReadPreference.SECONDARY_PREFERRED)
Resumo
Para usar melhor os recursos em seu cluster, recomendamos que você se conecte ao cluster usando o modo de conjunto de réplicas. Se for adequado para sua aplicação, você poderá fazer a escalabilidade de leitura de sua aplicação distribuindo suas leituras para as instâncias de réplica.
