As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Amazon DocumentDB: como funciona
O Amazon DocumentDB (compativel com MongoDB) é um serviço de banco de dados totalmente gerenciado compatível com o MongoDB. Com o Amazon DocumentDB, você pode executar o mesmo código de aplicação e usar os mesmos drivers e ferramentas que você usa com o MongoDB. O Amazon DocumentDB é compatível com o MongoDB 3.6, 4.0 e 5.0.
Tópicos
Ao usar o Amazon DocumentDB, você começa criando um cluster. Um cluster consiste em zero ou mais instâncias de banco de dados e em um volume de cluster que gerencia os dados para essas instâncias. Um volume de cluster do Amazon DocumentDB é um volume de armazenamento de banco de dados virtual que abrange várias zonas de disponibilidade. Cada zona de disponibilidade tem uma cópia de dados do cluster.
Um cluster do Amazon DocumentDB consiste em dois componentes:
-
Volume de cluster — Usa um serviço de armazenamento nativo de nuvem para replicar dados de seis maneiras em três zonas de disponibilidade, fornecendo armazenamento resiliente e disponível. Um cluster do Amazon DocumentDB tem exatamente um volume de cluster, que pode armazenar até 128 TiB de dados.
-
Instâncias — Fornecem a potência do processamento para o banco de dados, gravando dados e lendo dados do volume de armazenamento do cluster. Um cluster do Amazon DocumentDB pode ter de 0–16 instâncias.
Instâncias atendem a uma das duas funções:
-
Instância principal — Oferece suporte a operações de leitura e gravação e executa todas as modificações de dados no volume do cluster. Cada cluster do Amazon DocumentDB tem uma instância primária.
-
Instância de réplica — Oferece suporte a operações somente leitura. Um cluster do Amazon DocumentDB pode ter até 15 réplicas, além da instância principal. Ter várias réplicas permite distribuir workloads de leitura. Além disso, ao colocar réplicas em zonas de disponibilidade separadas, você também aumenta a disponibilidade do cluster.
O diagrama a seguir ilustra a relação entre o volume do cluster, a instância principal e as réplicas em um cluster do Amazon DocumentDB:
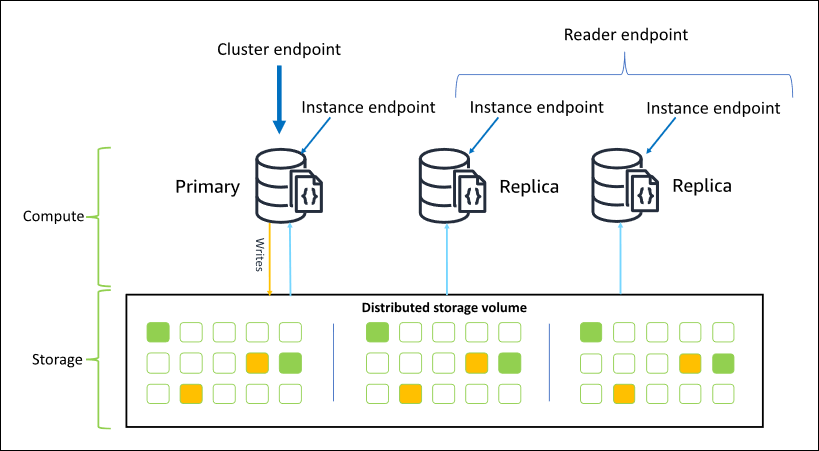
As instâncias de cluster não precisam ser da mesma classe de instância e podem ser provisionadas e encerradas conforme desejado. Essa arquitetura permite escalar a capacidade computacional do cluster, independentemente do armazenamento.
Quando a aplicação grava dados na instância principal, ela executa uma gravação durável no volume do cluster. Em seguida, ele replica o estado dessa gravação (não os dados) em cada réplica ativa. As réplicas do Amazon DocumentDB não participam do processamento de gravações e, portanto, as réplicas do Amazon DocumentDB são vantajosas para a escalabilidade de leitura. As leituras das réplicas do Amazon DocumentDB são eventualmente consistentes com o atraso mínimo da réplica, geralmente menos de 100 milissegundos após a instância principal gravar os dados. É garantido que as leituras das réplicas sejam lidas na ordem em que foram gravadas na instância principal. O atraso de réplica varia dependendo da taxa de alteração de dados, e períodos de alta atividade de gravação podem aumentar o atraso da réplica. Para obter mais informações, consulte as métricas ReplicationLag em Métricas do Amazon DocumentDB.
Endpoints do Amazon DocumentDB
O Amazon DocumentDB fornece várias opções de conexão para atender a uma ampla variedade de casos de uso. Para se conectar a uma instância em um cluster do Amazon DocumentDB, você especifica o endpoint da instância. Um endpoint é um endereço de host e um número de porta, separados por dois-pontos.
Recomendamos que a conexão com o cluster use o endpoint do cluster e o modo de conjunto de réplicas (consulte Conectar-se ao Amazon DocumentDB como um conjunto de réplicas), a menos que você tenha um caso de uso específico para a conexão com o endpoint de leitor ou um endpoint da instância. Para rotear solicitações para suas réplicas, escolha uma configuração de preferência de leitura do driver que maximize a escalabilidade de leitura, sem deixar de atender aos requisitos de consistência de leitura da aplicação. A preferência de leitura secondaryPreferred permite leituras de réplica e libera a instância primária para trabalhar mais.
Os endpoints a seguir estão disponíveis em um cluster do Amazon DocumentDB.
Endpoint do cluster
O endpoint de cluster conecta-se à instância principal atual do cluster. O endpoint do cluster pode ser usado para operações de leitura e gravação. Um cluster do Amazon DocumentDB tem exatamente um endpoint de cluster.
O endpoint de cluster dá suporte a failover para conexões de leitura e gravação para o cluster. Se a instância principal atual do cluster falhar e o cluster tiver pelo menos uma réplica de leitura ativa, o endpoint do cluster redirecionará automaticamente as solicitações de conexão para uma nova instância principal. Ao estabelecer a conexão com o cluster do Amazon DocumentDB, recomendamos que você use o endpoint do cluster e o modo de conjunto de réplicas (consulte Conectar-se ao Amazon DocumentDB como um conjunto de réplicas).
Veja a seguir um exemplo de endpoint do cluster do Amazon DocumentDB:
sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27017
O exemplo a seguir é um exemplo de string de conexão utilizando esse endpoint de cluster:
mongodb://username:password@sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27017
Para obter informações sobre como localizar os endpoints de um cluster, consulte Localizar os endpoints de um cluster.
Endpoint de leitor
O endpoint do leitor balanceia a carga de conexões somente leitura em todas as réplicas disponíveis no cluster. Um endpoint de leitor de cluster funcionará como o endpoint do cluster se você estiver se conectando por meio do modo replicaSet, ou seja, na cadeia de conexão, o parâmetro do conjunto de réplicas é &replicaSet=rs0. Nesse caso, você poderá realizar operações de gravação no primário. No entanto, se você se conectar ao cluster especificando directConnection=true, a tentativa de realizar uma operação de gravação em uma conexão com o endpoint do leitor ocasionará erro. Um cluster do Amazon DocumentDB tem exatamente um endpoint de leitor.
Se o cluster contiver apenas uma instância (principal), o endpoint do leitor se conectará à instância principal. Quando você adicionar uma instância de réplica ao cluster do Amazon DocumentDB, o endpoint do leitor abrirá as conexões somente leitura para a nova réplica depois que ela estiver ativa.
Veja a seguir um exemplo de endpoint de leitor para um cluster do Amazon DocumentDB:
sample-cluster.cluster-ro-123456789012.us-east-1.docdb.amazonaws.com:27017
O exemplo a seguir é um exemplo de string de conexão utilizando um endpoint de leitor:
mongodb://username:password@sample-cluster.cluster-ro-123456789012.us-east-1.docdb.amazonaws.com:27017
O endpoint do leitor balanceia a carga de conexões somente leitura, e não solicitações de leitura. Se algumas conexões do endpoint de leitor forem mais utilizadas do que outras, suas solicitações de leitura poderão não ser igualmente equilibradas entre as instâncias do cluster. É recomendável distribuir solicitações conectando-se ao endpoint do cluster como um conjunto de réplicas e utilizando a opção de preferência de leitura secondaryPreferred.
Para obter informações sobre como localizar os endpoints de um cluster, consulte Localizar os endpoints de um cluster.
Endpoint da instância
Um endpoint da instância se conecta a uma instância específica no cluster. O endpoint da instância para a instância principal atual pode ser usado para operações de leitura e gravação. No entanto, a tentativa de executar operações de gravação em um endpoint da instância para uma réplica de leitura resulta em um erro. Um cluster do Amazon DocumentDB tem um endpoint de instância por instância ativa.
Um endpoint de instância oferece controle direto sobre conexões para uma instância específica, para cenários nos quais o endpoint de cluster ou o endpoint de leitor talvez não seja apropriado. Um exemplo de caso de uso é o provisionamento de uma workload de analytics periódica somente leitura. Você pode provisionar uma instância de larger-than-normal réplica, conectar-se diretamente à nova instância maior com seu endpoint de instância, executar as consultas de análise e, em seguida, encerrar a instância. Usar o endpoint da instância impede que o tráfego de analytics cause impacto em outras instâncias do cluster.
Este é um exemplo de endpoint de instância para uma única instância em um cluster do Amazon DocumentDB:
sample-instance.123456789012.us-east-1.docdb.amazonaws.com:27017
O exemplo a seguir é um exemplo de string de conexão utilizando esse endpoint da instância:
mongodb://username:password@sample-instance.123456789012.us-east-1.docdb.amazonaws.com:27017
nota
A função de uma instância como principal ou de réplica pode mudar devido a um evento de failover. As aplicações nunca devem presumir que um endpoint de instância específico seja a instância principal. Não recomendamos a conexão com endpoints de instância para aplicações de produção. Em vez disso, recomendamos a conexão com o cluster usando o endpoint do cluster e o modo de conjunto de réplicas (consulte Conectar-se ao Amazon DocumentDB como um conjunto de réplicas). Para obter mais controle avançado da prioridade de failover da instância, consulte Entender a tolerância a falhas de cluster do Amazon DocumentDB.
Para obter informações sobre como localizar os endpoints de um cluster, consulte Localizar o endpoint de uma instância.
Modo de conjuntos de réplicas
Você pode se conectar ao endpoint de cluster do Amazon DocumentDB no modo de conjunto de réplicas especificando o nome do conjunto de réplicas rs0. A conexão no modo de conjunto de réplicas fornece a capacidade de especificar as opções Read Concern, Write Concern e Read Preference. Para obter mais informações, consulte Consistência de leituras.
O exemplo a seguir é de uma string de conexão conectando-se no modo de conjunto de réplicas:
mongodb://username:password@sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0
Quando você se conecta no modo de conjunto de réplicas, o cluster do Amazon DocumentDB aparece para os seus drivers e clientes como um conjunto de réplicas. As instâncias adicionadas e removidas do cluster do Amazon DocumentDB são refletidas automaticamente na configuração do conjunto de réplicas.
Cada cluster do Amazon DocumentDB consiste em um único conjunto de réplicas com o nome padrão rs0. O nome do conjunto de réplicas não pode ser modificado.
A conexão ao endpoint do cluster no modo de conjunto de réplicas é o método recomendado para uso geral.
nota
Todas as instâncias em um cluster do Amazon DocumentDB atendem a mesma porta TCP para conexões.
Suporte a TLS
Para obter mais detalhes sobre a conexão ao Amazon DocumentDB usando o Transport Layer Security (TLS), consulte Criptografia de dados em trânsito.
Armazenamento do Amazon DocumentDB
Os dados do Amazon DocumentDB são armazenados em um volume de cluster, que é um único volume virtual que usa unidades de estado sólido ()SSDs. Um volume de cluster consiste em seis cópias dos dados, que são replicados automaticamente em diversas zonas de disponibilidade em uma única região da Região da AWS. Essa replicação ajuda a garantir que seus dados sejam resilientes, com menor possibilidade de perda de dados. Isso também ajuda a garantir que o cluster esteja mais disponível durante um failover, pois as cópias dos dados já existem em outras zonas de disponibilidade. Essas cópias podem continuar a atender às solicitações de dados para as instâncias no cluster do Amazon DocumentDB.
Como o armazenamento de dados do é faturado
O Amazon DocumentDB aumenta automaticamente o tamanho de um volume de cluster à medida que a quantidade de dados aumenta. Um volume de cluster do Amazon DocumentDB pode aumentar para um tamanho máximo de 128 TiB. No entanto, você só será cobrado pelo espaço usado em um volume de cluster do Amazon DocumentDB. A partir do Amazon DocumentDB 4.0, quando os dados são removidos, como ao excluir uma coleção ou índice, o espaço total alocado diminui em uma quantidade equivalente. Assim, é possível reduzir as cobranças de armazenamento excluindo coleções, índices e bancos de dados que não são mais necessários. No Amazon DocumentDB versão 3.6, o volume do cluster pode reutilizar o espaço que é liberado quando você remove dados, mas o volume em si nunca diminui de tamanho. Como resultado, na versão 3.6, você não pode testemunhar nenhuma alteração no armazenamento ao descartar uma coleção ou índice, mesmo que o espaço liberado seja reutilizado.
nota
Com o Amazon DocumentDB 3.6, os custos de armazenamento são baseados no “limite máximo” de armazenamento (o valor máximo que foi alocado para o cluster Amazon DocumentDB a qualquer momento). Você pode gerenciar custos evitando práticas de ETL que criam grandes volumes de informações temporárias ou que carregam grandes volumes de novos dados antes de remover dados antigos desnecessários. Se a remoção de dados de um cluster do Amazon DocumentDB resultar em uma quantidade substancial de espaço alocado mas não utilizado, a redefinição do nível mais alto da marca d'água vai exigir o despejo de dados lógicos e a restauração de um novo cluster usando uma ferramenta como mongodump ou mongorestore. A criação e restauração de um snapshot não reduz o armazenamento alocado, pois o layout físico do armazenamento subjacente permanece o mesmo no snapshot restaurado.
nota
O uso de utilitários como mongodump e mongorestore incorre em I/O cobranças com base no tamanho dos dados que estão sendo lidos e gravados no volume de armazenamento.
Para obter informações sobre o armazenamento de dados e os preços do Amazon DocumentDB, consulte os I/O preços e preços do Amazon DocumentDB (com compatibilidade com o MongoDB
Replicação do Amazon DocumentDB
Em um cluster do Amazon DocumentDB, cada instância de réplica expõe um endpoint independente. Esses endpoints de réplica fornecem acesso somente leitura aos dados no volume do cluster. Eles permitem escalar a workload de leitura para os dados em várias instâncias replicadas. Eles também ajudam a melhorar o desempenho das leituras de dados e a aumentar a disponibilidade dos dados em seu cluster do Amazon DocumentDB. As réplicas do Amazon DocumentDB também são alvos de failover e são promovidas rapidamente se a instância primária do seu cluster do Amazon DocumentDB falhar.
Confiabilidade do Amazon DocumentDB
O Amazon DocumentDB foi projetado para ser confiável, durável e tolerante a falhas. (Para melhorar a disponibilidade, você deve configurar seu cluster Amazon DocumentDB para que ele tenha várias instâncias de réplica em diferentes zonas de disponibilidade.) O Amazon DocumentDB inclui vários recursos automáticos que o tornam uma solução de banco de dados confiável.
Reparo automático de armazenamento
O Amazon DocumentDB mantém várias cópias dos dados em três zonas de disponibilidade, reduzindo bastante a chance de perda de dados devido a uma falha de armazenamento. O Amazon DocumentDB detecta automaticamente as falhas no volume do cluster. Quando um segmento de um volume de cluster falha, o Amazon DocumentDB repara imediatamente o segmento. Ele usa os dados dos outros volumes que compõem o volume do cluster para ajudar a garantir que os dados no segmento reparado sejam atuais. Como resultado, o Amazon DocumentDB evita a perda de dados e reduz a necessidade de realizar uma point-in-time restauração para se recuperar de uma falha na instância.
Aquecimento de cache possível de recuperar
O Amazon DocumentDB gerencia seu cache de páginas em um processo separado do banco de dados, de modo que o cache de páginas possa sobreviver independentemente do banco de dados. No evento improvável de uma falha no banco de dados, o cache da página permanece na memória. Isso garante que o grupo de buffers seja aquecido com o estado mais atual quando o banco de dados é reiniciado.
Recuperação de falha
O Amazon DocumentDB foi projetado para se recuperar de uma falha quase instantaneamente e continuar fornecendo seus dados de aplicações. O Amazon DocumentDB executa a recuperação de falhas de forma assíncrona em threads paralelos, de maneira que o banco de dados seja aberto e fique disponível imediatamente após a falha.
Governança de recursos
O Amazon DocumentDB protege os recursos necessários para executar processos críticos no serviço, como verificações de integridade. Para fazer isso, e quando uma instância estiver com alta pressão de memória, o Amazon DocumentDB limitará as solicitações. Como resultado, algumas operações podem ser colocadas em fila para esperar que a pressão da memória diminua. Se a pressão da memória continuar, as operações em fila poderão atingir o tempo limite. Você pode monitorar se o serviço está limitando ou não as operações devido à falta de memória com as seguintes CloudWatch métricas:LowMemThrottleQueueDepth,,LowMemThrottleMaxQueueDepth,LowMemNumOperationsThrottled. LowMemNumOperationsTimedOut Para obter mais informações, consulte Monitoramento do Amazon DocumentDB com. CloudWatch Se você observar uma pressão de memória sustentada em sua instância como resultado das LowMem CloudWatch métricas, recomendamos que você aumente sua instância para fornecer memória adicional para sua carga de trabalho.
Opções de preferência de leitura
O Amazon DocumentDB usa um serviço de armazenamento compartilhado nativo de nuvem que replica os dados seis vezes em três zonas de disponibilidade para fornecer altos níveis de durabilidade. O Amazon DocumentDB não depende da replicação de dados em várias instâncias para obter durabilidade. Os dados do cluster são duráveis, quer contenham uma única instância ou 15 instâncias.
Tópicos
Durabilidade de gravação
O Amazon DocumentDB usa um sistema de armzenamento exclusivo, distribuído, tolerante a falhas e de recuperação automática. Esse sistema replica seis cópias (V = 6) de seus dados em três zonas de AWS disponibilidade para fornecer alta disponibilidade e durabilidade. Ao gravar dados, o Amazon DocumentDB garante que todas as gravações sejam gravadas de forma durável na maioria dos nós antes de confirmar a gravação para o cliente. Se você estiver executando um conjunto de réplicas do MongoDB de três nós, o uso de uma Write Concern de {w:3, j:true} produzirá a melhor configuração possível em comparação com o Amazon DocumentDB.
As gravações em um cluster do Amazon DocumentDB devem ser processadas pela instância principal do cluster. A tentativa de gravar em um leitor resulta em um erro. Uma gravação confirmada de uma instância primária do Amazon DocumentDB é durável e não pode ser revertida. O Amazon DocumentDB é altamente durável por padrão e não oferece suporte a uma opção de gravação não durável. Você não pode modificar o nível de durabilidade (ou seja, preocupação de gravação). O Amazon DocumentDB ignora w=anything e é efetivamente w: 3 e j: true. Você não pode reduzi-lo.
Devido à separação de armazenamento e computação na arquitetura do Amazon DocumentDB, um cluster com uma única instância é resiliente. A durabilidade é processada na camada de armazenamento. Como resultado, um cluster do Amazon DocumentDB com uma única instância e um com três instâncias alcança o mesmo nível de durabilidade. Você pode configurar o cluster para seu caso de uso específico e, ao mesmo tempo, proporcionar resiliência aos seus dados.
As gravações em um cluster do Amazon DocumentDB são atômicas em um único documento.
O Amazon DocumentDB não oferece suporte à opção wtimeout e não retornará um erro se um valor for especificado. É garantido que as gravações na instância principal do Amazon DocumentDB não sejam bloqueadas indefinidamente.
Isolamento de leitura
As leituras de uma instância do Amazon DocumentDB retornam apenas dados que sejam duráveis antes do início da consulta. As leituras nunca retornam dados modificados depois que a consulta começa a execução, nem as leituras contaminadas são possíveis sob qualquer circunstância.
Consistência de leituras
Os dados lidos em um cluster do Amazon DocumentDB são duráveis e não serão revertidos. Você pode modificar a consistência de leitura para as leituras do Amazon DocumentDB especificando a preferência de leitura para a solicitação ou conexão. O Amazon DocumentDB não oferece suporte a uma opção de leitura não durável.
As leituras da instância primária de um cluster Amazon DocumentDB são altamente consistentes em condições operacionais normais e consistentes read-after-write. Se ocorrer um evento de failover entre a leitura e a gravação subsequentes, o sistema poderá retornar em breve uma leitura que não seja altamente consistente. Todas as leituras a partir de uma réplica de leitura são, por fim, consistentes e retornam os dados na mesma ordem e, geralmente, com atraso de replicação inferior a 100 ms.
Preferências de leitura do Amazon DocumentDB
O Amazon DocumentDB oferece suporte à configuração de uma opção de preferência de leitura apenas ao ler dados do endpoint do cluster no modo de conjunto de réplicas. Definir uma opção de preferência de leitura afeta como o cliente ou o driver do MongoDB encaminha solicitações de leitura para instâncias no cluster do Amazon DocumentDB. Você pode definir opções de preferência de leitura para uma consulta específica ou como uma opção geral no driver do MongoDB. (Consulte a documentação do cliente ou do driver para obter instruções sobre como definir uma opção de preferência de leitura.)
Se o cliente ou o driver não estiver se conectando a um endpoint de cluster do Amazon DocumentDB no modo de conjunto de réplicas, o resultado da especificação de uma preferência de leitura será indefinido.
O Amazon DocumentDB não é compatível com a configuração de conjuntos de tags como uma preferência de leitura.
Opções de preferência de leitura compatíveis
-
primary— A especificação de uma preferência de leituraprimaryajuda a garantir que todas as leituras sejam encaminhadas para a instância principal do cluster. Se a instância principal estiver indisponível, a operação de leitura falhará. Uma preferência deprimaryleitura gera read-after-write consistência e é apropriada para casos de uso que priorizam a read-after-write consistência em vez da alta disponibilidade e da escala de leitura.O exemplo a seguir especifica uma preferência de leitura
primary:db.example.find().readPref('primary') -
primaryPreferred— A especificação de rotas de preferência de leituraprimaryPreferredlê para a instância principal em operação normal. Se houver um failover principal, o cliente encaminhará solicitações para uma réplica. Uma preferência deprimaryPreferredleitura gera read-after-write consistência durante a operação normal e, eventualmente, leituras consistentes durante um evento de failover. Uma preferência deprimaryPreferredleitura é apropriada para casos de uso que priorizam a read-after-write consistência em relação ao escalonamento de leitura, mas ainda exigem alta disponibilidade.O exemplo a seguir especifica uma preferência de leitura
primaryPreferred:db.example.find().readPref('primaryPreferred') -
secondary— A especificação de uma preferência de leiturasecondarygarante que as leituras sejam encaminhadas apenas para uma réplica, nunca para a instância principal. Se não houver instâncias de réplica em um cluster, a solicitação de leitura falhará. Uma preferência desecondaryleitura eventualmente gera leituras consistentes e é apropriada para casos de uso que priorizam a taxa de transferência de gravação da instância primária em detrimento da alta disponibilidade e consistência. read-after-writeO exemplo a seguir especifica uma preferência de leitura
secondary:db.example.find().readPref('secondary') -
secondaryPreferred— A especificação de uma preferência de leiturasecondaryPreferredgarante que as leituras sejam encaminhadas para uma réplica de leitura quando uma ou mais réplicas estiverem ativas. Se não houver instâncias de réplica ativas em um cluster, a solicitação de leitura será encaminhada para a instância principal. Uma preferência de leiturasecondaryPreferredproduz leituras eventualmente consistentes quando a leitura é atendida por uma réplica de leitura. Ela gera read-after-write consistência quando a leitura é atendida pela instância primária (exceto eventos de failover). Uma preferência desecondaryPreferredleitura é apropriada para casos de uso que priorizam a escala de leitura e a alta disponibilidade em vez da consistência. read-after-writeO exemplo a seguir especifica uma preferência de leitura
secondaryPreferred:db.example.find().readPref('secondaryPreferred') -
nearest— A especificação de uma preferência de leituranearestencaminha as leituras baseadas apenas na latência medida entre o cliente e todas as instâncias no cluster do Amazon DocumentDB. Uma preferência de leituranearestproduz leituras eventualmente consistentes quando a leitura é atendida por uma réplica de leitura. Ela gera read-after-write consistência quando a leitura é atendida pela instância primária (exceto eventos de failover). Uma preferência denearestleitura é apropriada para casos de uso que priorizam alcançar a menor latência de leitura possível e alta disponibilidade em vez de read-after-write consistência e escalabilidade de leitura.O exemplo a seguir especifica uma preferência de leitura
nearest:db.example.find().readPref('nearest')
Alta disponibilidade
O Amazon DocumentDB oferece suporte a configurações de cluster altamente disponíveis usando réplicas como destinos de failover para a instância principal. Se a instância principal falhar, uma réplica do Amazon DocumentDB será promovida como a nova principal, com uma breve interrupção durante a qual as solicitações de leitura e gravação feitas na instância principal falham com uma exceção.
Se o cluster do Amazon DocumentDB não incluir réplicas, a instância principal será recriada durante uma falha. No entanto, promover uma réplica do Amazon DocumentDB é muito mais rápido do que recriar a instância primária. Portanto, recomendamos que você crie uma ou mais réplicas do Amazon DocumentDB como destinos de failover.
As réplicas que devem ser usadas como destinos de failover devem ser da mesma classe de instância da instância principal. Elas devem ser provisionadas em zonas de disponibilidade diferentes da principal. Você pode controlar quais réplicas são preferenciais como destinos de failover. Para obter as melhores práticas sobre como configurar o Amazon DocumentDB para alta disponibilidade, consulte Entender a tolerância a falhas de cluster do Amazon DocumentDB.
Leituras de escalabilidade
As réplicas do Amazon DocumentDB são ideais para escalabilidade de leitura. Elas são totalmente dedicadas a operações de leitura no volume de cluster, ou seja, as réplicas não processam gravações. A replicação de dados acontece dentro do volume de cluster e não entre as instâncias. Portanto, os recursos de cada réplica são dedicados ao processamento de consultas, e não às replicações e gravações de dados.
Se a aplicação precisar de mais capacidade de leitura, você poderá adicionar uma réplica ao cluster rapidamente (geralmente em menos de dez minutos). Se os requisitos de capacidade de leitura diminuírem, você poderá remover as réplicas desnecessárias. Com as réplicas do Amazon DocumentDB, você paga apenas pela capacidade de leitura de que precisa.
O Amazon DocumentDB oferece suporte a escalabilidade de leitura do lado do cliente por meio do uso de opções de preferência de leitura. Para obter mais informações, consulte Preferências de leitura do Amazon DocumentDB.
Exclusões de TTL
As exclusões de uma área de índice TTL alcançada por meio de um processo em segundo plano são o melhor esforço e não são garantidas dentro de um período de tempo específico. Fatores como tamanho de instância, utilização de recursos da instância, tamanho do documento e throughput geral podem afetar a sincronização de uma exclusão de TTL.
Quando o monitor TTL exclui seus documentos, cada exclusão resulta em custos de E/S, o que aumentará sua fatura. Se a taxa de transferência e as taxas de exclusão de TTL aumentarem, você deve esperar um aumento em sua fatura devido ao aumento do uso de E/S.
Ao criar um índice TTL em uma coleção existente, você deve excluir todos os documentos expirados antes de criar o índice. A implementação atual do TTL é otimizada para excluir uma pequena fração de documentos na coleção, o que é típico se o TTL foi ativado na coleção desde o início, e pode resultar em IOPS maior do que o necessário se um grande número de documentos precisar ser excluído de uma só vez.
Caso você não queira criar um índice TTL para excluir documentos, é possível segmentar documentos em coleções com base no tempo e simplesmente descartar essas coleções quando os documentos não forem mais necessários. Por exemplo: você pode criar uma coleção por semana e descartá-la sem incorrer em custos de E/S. Isso pode ser significativamente mais econômico do que usar um índice TTL.
Recursos faturáveis
Identificação de recursos faturáveis do Amazon DocumentDB
Como um serviço de banco de dados gerenciado, o Amazon DocumentDB cobra por instâncias, armazenamento, E/Ss, backups e transferência de dados. Para obter mais informações, consulte Preços do Amazon DocumentDB (compatível com MongoDB)
Para descobrir recursos faturáveis em sua conta e potencialmente excluir os recursos, você pode usar o AWS Management Console ou. AWS CLI
Usando o AWS Management Console
Usando o AWS Management Console, você pode descobrir os clusters, instâncias e snapshots do Amazon DocumentDB que você provisionou para um determinado. Região da AWS
Para descobrir clusters, instâncias e snapshots
-
Para descobrir recursos faturáveis em uma região diferente da sua região padrão, no canto superior direito da tela, escolha o Região da AWS que você deseja pesquisar.
-
No painel de navegação, escolha o tipo de recurso faturável de interesse em: Clusters, Instances (Instâncias) ou Snapshots.
-
Todos os seus clusters provisionados, instâncias ou snapshots para a região são listados no painel direito. Você será cobrado por clusters, instâncias e snapshots.
Usando o AWS CLI
Usando o AWS CLI, você pode descobrir os clusters, instâncias e snapshots do Amazon DocumentDB que você provisionou para um determinado. Região da AWS
Para descobrir clusters e instâncias
O código a seguir lista todos os clusters e instâncias para a região especificada. Se você deseja procurar clusters e instâncias em sua região padrão, omita o parâmetro --region.
Para Linux, macOS ou Unix:
aws docdb describe-db-clusters \ --region us-east-1 \ --query 'DBClusters[?Engine==`docdb`]' | \ grep -e "DBClusterIdentifier" -e "DBInstanceIdentifier"
Para Windows:
aws docdb describe-db-clusters ^ --region us-east-1 ^ --query 'DBClusters[?Engine==`docdb`]' | ^ grep -e "DBClusterIdentifier" -e "DBInstanceIdentifier"
A saída dessa operação é semelhante à seguinte.
"DBClusterIdentifier": "docdb-2019-01-09-23-55-38",
"DBInstanceIdentifier": "docdb-2019-01-09-23-55-38",
"DBInstanceIdentifier": "docdb-2019-01-09-23-55-382",
"DBClusterIdentifier": "sample-cluster",
"DBClusterIdentifier": "sample-cluster2",Para descobrir snapshots
O código a seguir lista todos os snapshots para a região especificada. Se você deseja procurar snapshots em sua região padrão, omita o parâmetro --region.
Para Linux, macOS ou Unix:
aws docdb describe-db-cluster-snapshots \ --region us-east-1 \ --query 'DBClusterSnapshots[?Engine==`docdb`].[DBClusterSnapshotIdentifier,SnapshotType]'
Para Windows:
aws docdb describe-db-cluster-snapshots ^ --region us-east-1 ^ --query 'DBClusterSnapshots[?Engine==`docdb`].[DBClusterSnapshotIdentifier,SnapshotType]'
A saída dessa operação é semelhante à seguinte.
[
[
"rds:docdb-2019-01-09-23-55-38-2019-02-13-00-06",
"automated"
],
[
"test-snap",
"manual"
]
]Você só precisa excluir manual snapshots. Os snapshots Automated são excluídos quando você exclui o cluster.
Exclusão de recursos faturáveis indesejados
Para excluir um cluster, primeiro exclua todas as instâncias no cluster.
-
Para excluir instâncias, consulte Excluir uma instância do Amazon DocumentDB.
Importante
Mesmo se você excluir as instâncias em um cluster, você ainda será cobrado pelo uso de armazenamento e backup associado a esse cluster. Para interromper todas as cobranças, você também deverá excluir seu cluster e snapshots manuais.
-
Para excluir clusters, consulte Excluir um cluster do Amazon DocumentDB.
-
Para excluir snapshots manuais, consulte Exclusão de um snapshot de cluster.
