As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Plano de controle EKS
O Amazon Elastic Kubernetes Service (EKS) é um serviço gerenciado de Kubernetes que facilita a execução do Kubernetes na AWS sem precisar instalar, operar e manter seu próprio plano de controle do Kubernetes ou nós de trabalho. Ele executa o Kubernetes upstream e é certificado em conformidade com o Kubernetes. Essa conformidade garante que o EKS ofereça suporte ao KubernetesAPIs, assim como a versão de código aberto da comunidade que você pode instalar no local ou no local. EC2 Os aplicativos existentes em execução no Kubernetes upstream são compatíveis com o Amazon EKS.
O EKS gerencia automaticamente a disponibilidade e a escalabilidade dos nós do plano de controle do Kubernetes e substitui automaticamente os nós não íntegros do plano de controle.
Arquitetura EKS
A arquitetura EKS foi projetada para eliminar qualquer ponto único de falha que possa comprometer a disponibilidade e a durabilidade do plano de controle do Kubernetes.
O plano de controle do Kubernetes gerenciado pelo EKS é executado dentro de uma VPC gerenciada pelo EKS. O plano de controle do EKS compreende os nós do servidor da API Kubernetes, o cluster etcd. Nós de servidor da API Kubernetes que executam componentes como o servidor da API, o agendador e são executados kube-controller-manager em um grupo de auto-scaling. O EKS executa no mínimo dois nós de servidor de API em zonas de disponibilidade distintas (AZs) dentro da região da AWS. Da mesma forma, para maior durabilidade, os nós do servidor etcd também são executados em um grupo de auto-scaling que abrange três. AZs O EKS executa um NAT Gateway em cada AZ, e os servidores API e etcd são executados em uma sub-rede privada. Essa arquitetura garante que um evento em uma única AZ não afete a disponibilidade do cluster EKS.
Quando você cria um novo cluster, o Amazon EKS cria um endpoint altamente disponível para o servidor gerenciado da API Kubernetes que você usa para se comunicar com seu cluster (usando ferramentas como). kubectl O endpoint gerenciado usa o NLB para balancear a carga dos servidores da API Kubernetes. O EKS também provisiona dois ENIs diferentes AZs para facilitar a comunicação com seus nós de trabalho.
Conectividade de rede do plano de dados EKS
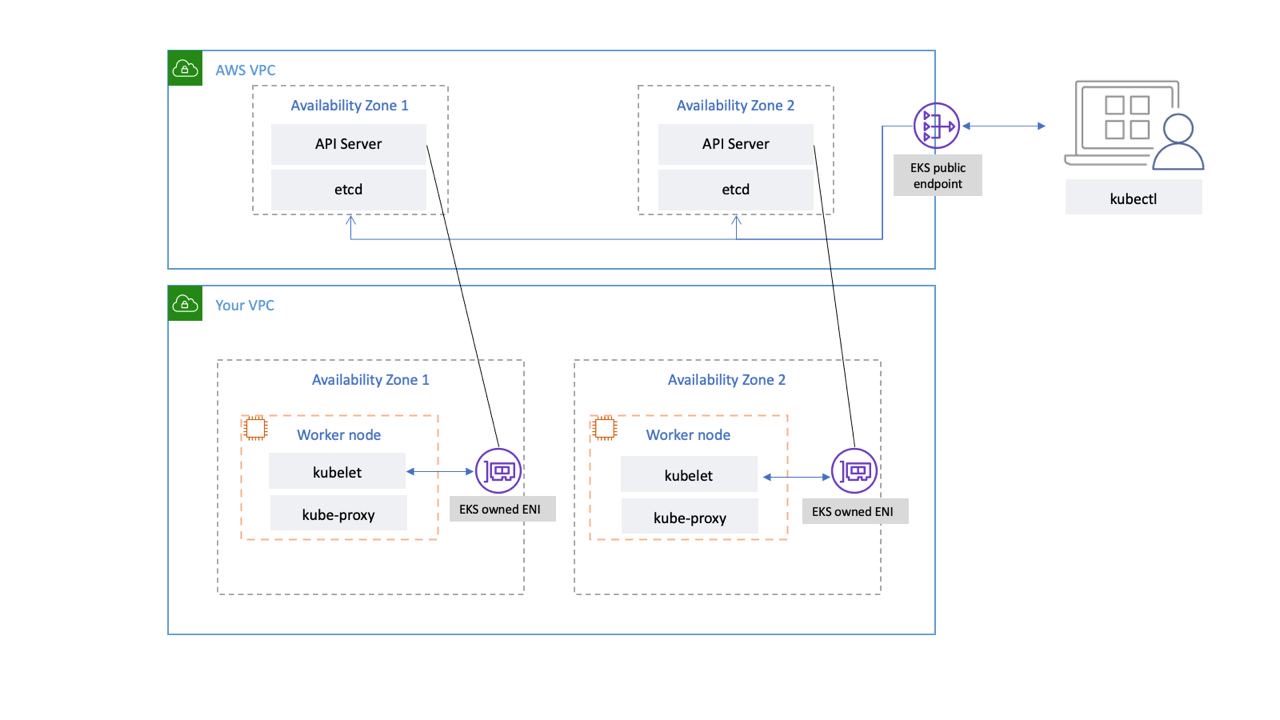
Você pode configurar se o servidor de API do seu cluster Kubernetes pode ser acessado pela Internet pública (usando o endpoint público) ou por meio de sua VPC (usando o EKS gerenciado) ou ambos. ENIs
Independentemente de os usuários e os nós de trabalho se conectarem ao servidor da API usando o endpoint público ou o ENI gerenciado pelo EKS, há caminhos redundantes para conexão.
Recomendações
Analise as recomendações a seguir.
Monitore as métricas do plano de controle
O monitoramento das métricas da API Kubernetes pode fornecer informações sobre o desempenho do plano de controle e identificar problemas. Um plano de controle não íntegro pode comprometer a disponibilidade das cargas de trabalho em execução dentro do cluster. Por exemplo, controladores mal escritos podem sobrecarregar os servidores da API, afetando a disponibilidade do seu aplicativo.
O Kubernetes expõe as métricas do plano de controle no endpoint. /metrics
Você pode ver as métricas expostas usandokubectl:
kubectl get --raw /metrics
Essas métricas são representadas em um formato de texto do Prometheus
Você pode usar o Prometheus para coletar e armazenar essas métricas. Em maio de 2020, CloudWatch foi adicionado suporte para monitorar as métricas CloudWatch do Prometheus no Container Insights. Portanto, você também pode usar CloudWatch a Amazon para monitorar o plano de controle do EKS. Você pode usar o Tutorial para adicionar um novo Prometheus Scrape Target: Prometheus KPI Server Metrics para coletar métricas CloudWatch e criar um painel para monitorar o plano de controle do seu cluster.
Você pode encontrar as métricas do servidor da API Kubernetes aqui.apiserver_request_duration_seconds pode indicar quanto tempo as solicitações de API estão demorando para serem executadas.
Considere monitorar essas métricas do plano de controle:
Servidor da API
| Métrica | Descrição |
|---|---|
|
|
Contador de solicitações do apiserver divididas para cada verbo, valor de simulação, grupo, versão, recurso, escopo, componente e código de resposta HTTP. |
|
|
Histograma de latência de resposta em segundos para cada verbo, valor de execução seca, grupo, versão, recurso, sub-recurso, escopo e componente. |
|
|
Histograma de latência do controlador de admissão em segundos, identificado por nome e dividido para cada operação e recurso e tipo de API (validar ou admitir). |
|
|
Contagem de rejeições de webhook de admissão. Identificado por nome, operação, código_de rejeição, tipo (validando ou admitido), tipo_erro (calling_webhook_error, apiserver_internal_error, no_error) |
|
|
Solicite o histograma de latência em segundos. Dividido por verbo e URL. |
|
|
Número de solicitações HTTP, particionadas por código de status, método e host. |
-
As métricas do histograma incluem os sufixos _bucket, _sum e _count.
etc.
| Métrica | Descrição |
|---|---|
|
|
Histograma de latência da solicitação Etcd em segundos para cada operação e tipo de objeto. |
|
|
Tamanho do banco de dados Etcd. |
-
As métricas do histograma incluem os sufixos _bucket, _sum e _count.
Considere usar o Painel de Visão Geral do Monitoramento do Kubernetes
Importante
Quando o limite de tamanho do banco de dados é excedido, o etcd emite um alarme sem espaço e para de receber mais solicitações de gravação. Em outras palavras, o cluster se torna somente para leitura e todas as solicitações para alterar objetos, como criar novos pods, escalar implantações etc., serão rejeitadas pelo servidor de API do cluster.
autenticação de cluster
Atualmente, o EKS oferece suporte a dois tipos de autenticação: tokens de portador/conta de serviço
O usuário ou a função do IAM que cria o EKS Cluster obtém automaticamente acesso total ao cluster. Você pode gerenciar o acesso ao cluster EKS editando o configmap aws-auth.
Se você configurar incorretamente o aws-auth configmap e perder o acesso ao cluster, ainda poderá usar o usuário ou a função do criador do cluster para acessar seu cluster EKS.
No caso improvável de você não poder usar o serviço IAM na região da AWS, você também pode usar o token portador da conta de serviço do Kubernetes para gerenciar o cluster.
Crie uma super-admin conta que tenha permissão para realizar todas as ações no cluster:
kubectl -n kube-system create serviceaccount super-admin
Crie uma associação de função que dê ao superadministrador a função cluster-admin:
kubectl create clusterrolebinding super-admin-rb --clusterrole=cluster-admin --serviceaccount=kube-system:super-admin
Veja o segredo da conta de serviço:
SECRET_NAME=`kubectl -n kube-system get serviceaccount/super-admin -o jsonpath='{.secrets[0].name}'`
Obtenha o token associado ao segredo:
TOKEN=`kubectl -n kube-system get secret $SECRET_NAME -o jsonpath='{.data.token}'| base64 --decode`
Adicione conta de serviço e token akubeconfig:
kubectl config set-credentials super-admin --token=$TOKEN
Defina o contexto atual kubeconfig para usar a conta de superadministrador:
kubectl config set-context --current --user=super-admin
A final kubeconfig deve ficar assim:
apiVersion: v1 clusters: - cluster: certificate-authority-data:<REDACTED> server: https://<CLUSTER>.gr7.us-west-2.eks.amazonaws.com name: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> contexts: - context: cluster: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> user: super-admin name: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> current-context: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> kind: Config preferences: {} users: #- name: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> # user: # exec: # apiVersion: client.authentication.k8s.io/v1beta1 # args: # - --region # - us-west-2 # - eks # - get-token # - --cluster-name # - <<cluster name>> # command: aws # env: null - name: super-admin user: token: <<super-admin sa's secret>>
Webhooks de admissão
O Kubernetes tem dois tipos de webhooks de admissão: webhooks de admissão de validação e webhooks de admissão mutantes
Para evitar o impacto das operações críticas do cluster, evite configurar webhooks “abrangentes”, como os seguintes:
- name: "pod-policy.example.com" rules: - apiGroups: ["*"] apiVersions: ["*"] operations: ["*"] resources: ["*"] scope: "*"
Ou certifique-se de que o webhook tenha uma política de abertura de falhas com um tempo limite inferior a 30 segundos para garantir que, se o webhook não estiver disponível, ele não prejudique as cargas de trabalho críticas do cluster.
Bloqueie pods com opções inseguras sysctls
Sysctlé um utilitário Linux que permite aos usuários modificar os parâmetros do kernel durante o tempo de execução. Esses parâmetros do kernel controlam vários aspectos do comportamento do sistema operacional, como rede, sistema de arquivos, memória virtual e gerenciamento de processos.
O Kubernetes permite atribuir sysctl perfis para pods. O Kubernetes é classificado systcls como seguro e inseguro. Os Safe sysctls têm namespaces no contêiner ou no pod, e configurá-los não afeta outros pods no nó ou no próprio nó. Por outro lado, os sysctls inseguros são desativados por padrão, pois podem potencialmente interromper outros pods ou tornar o nó instável.
Como os inseguros sysctls estão desativados por padrão, o kubelet não criará um pod com perfil inseguro. sysctl Se você criar um pod desse tipo, o programador atribuirá repetidamente esses pods aos nós, enquanto o nó não conseguirá iniciá-lo. Esse loop infinito acaba sobrecarregando o plano de controle do cluster, tornando o cluster instável.
Considere usar o OPA Gatekeepersysctls
Lidando com atualizações de clusters
Desde abril de 2021, o ciclo de lançamento do Kubernetes foi alterado de quatro lançamentos por ano (uma vez por trimestre) para três lançamentos por ano. Uma nova versão secundária (como 1. 21 ou 1. 22) é lançado aproximadamente a cada quinze semanas.
Conectividade de endpoint de cluster
Ao trabalhar com o Amazon EKS (Elastic Kubernetes Service), você pode encontrar tempos limite de conexão ou erros durante eventos como escalabilidade ou aplicação de patches no plano de controle do Kubernetes. Esses eventos podem fazer com que as instâncias do kube-apiserver sejam substituídas, resultando potencialmente no retorno de endereços IP diferentes ao resolver o FQDN. Este documento descreve as melhores práticas para os consumidores da Kubernetes API manterem uma conectividade confiável.
nota
A implementação dessas melhores práticas pode exigir atualizações nas configurações ou scripts do cliente para lidar com novas estratégias de reresolução e repetição de DNS de forma eficaz.
O principal problema decorre do cache do lado do cliente do DNS e do potencial de endereços IP obsoletos do endpoint EKS - NLB público para endpoint público ou X-ENI para endpoint privado. Quando as instâncias do kube-apiserver são substituídas, o nome de domínio totalmente qualificado (FQDN) pode ser resolvido para novos endereços IP. No entanto, devido às configurações de DNS Time to Live (TTL), que são definidas para 60 segundos na zona do Route 53 gerenciada pela AWS, os clientes podem continuar usando endereços IP desatualizados por um curto período de tempo.
Para mitigar esses problemas, os consumidores da API Kubernetes (como kubectl, CI/CD pipelines e aplicativos personalizados) devem implementar as seguintes práticas recomendadas:
-
Implemente a reresolução de DNS
-
Implemente novas tentativas com Backoff e Jitter. Por exemplo, veja este artigo intitulado Falhas acontecem
-
Implemente tempos limite do cliente. Defina tempos limite apropriados para evitar que solicitações de longa duração bloqueiem seu aplicativo. Lembre-se de que algumas bibliotecas de cliente do Kubernetes, especialmente aquelas geradas por geradores OpenAPI, podem não permitir a configuração fácil de tempos limite personalizados.
-
Exemplo 1 com kubectl:
kubectl get pods --request-timeout 10s # default: no timeout
-
Exemplo 2 com Python: o cliente Kubernetes
fornece um parâmetro _request_timeout
-
Ao implementar essas melhores práticas, você pode melhorar significativamente a confiabilidade e a resiliência de seus aplicativos ao interagir com a API Kubernetes. Lembre-se de testar essas implementações minuciosamente, especialmente sob condições de falha simuladas, para garantir que elas se comportem conforme o esperado durante eventos reais de escalabilidade ou correção.
Executando grandes clusters
O EKS monitora ativamente a carga nas instâncias do plano de controle e as dimensiona automaticamente para garantir alto desempenho. No entanto, você deve considerar possíveis problemas e limites de desempenho no Kubernetes e nas cotas nos serviços da AWS ao executar grandes clusters.
-
Clusters com mais de 1000 serviços podem apresentar latência de rede com o uso
kube-proxynoiptablesmodo de acordo com os testes realizados pela ProjectCalico equipe. A solução é mudar para o ipvsmodo kube-proxy de execução. -
Você também pode enfrentar a limitação de solicitações de EC2 API se a CNI precisar solicitar endereços IP para pods ou se você precisar criar novas instâncias com frequência. EC2 Você pode reduzir a EC2 API de chamadas configurando a CNI para armazenar endereços IP em cache. Você pode usar tipos de EC2 instância maiores para reduzir os eventos EC2 de escalabilidade.
Recursos adicionais:
