As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Otimização de custos - Rede
A arquitetura de sistemas para alta disponibilidade (HA) é uma prática recomendada para obter resiliência e tolerância a falhas. Na prática, isso significa distribuir suas cargas de trabalho e a infraestrutura subjacente em várias zonas de disponibilidade (AZs) em uma determinada região da AWS. Garantir que essas características estejam em vigor em seu ambiente Amazon EKS aumentará a confiabilidade geral do seu sistema. Em conjunto com isso, seus ambientes EKS provavelmente também serão compostos por uma variedade de construções (ou seja, VPCs), componentes (ou seja,) e integrações (ou seja, ECR e outros registros de contêineres ELBs).
A combinação de sistemas altamente disponíveis e outros componentes específicos do caso de uso pode desempenhar um papel significativo na forma como os dados são transferidos e processados. Isso, por sua vez, terá um impacto nos custos incorridos devido à transferência e processamento de dados.
As práticas detalhadas abaixo ajudarão você a projetar e otimizar seus ambientes EKS para obter economia em diferentes domínios e casos de uso.
Comunicação de pod a pod
Dependendo da sua configuração, a comunicação de rede e a transferência de dados entre pods podem ter um impacto significativo no custo geral da execução das cargas de trabalho do Amazon EKS. Esta seção abordará diferentes conceitos e abordagens para mitigar os custos associados à comunicação entre pods, considerando arquiteturas de alta disponibilidade (HA), desempenho e resiliência de aplicativos.
Restringindo o tráfego a uma zona de disponibilidade
Logo no início, o projeto Kubernetes começou a desenvolver construções com reconhecimento de topologia, incluindo rótulos como kubernetes. io/hostname, topology.kubernetes.io/region, and topology.kubernetes.io/zoneatribuído aos nós para permitir recursos como distribuição de carga de trabalho em domínios de falha e provisionadores de volume com reconhecimento de topologia. Depois de se graduar no Kubernetes 1.17, os rótulos também foram utilizados para permitir recursos de roteamento com reconhecimento de topologia para comunicação de pod a pod.
Abaixo estão algumas estratégias sobre como controlar a quantidade de tráfego entre AZ entre pods em seu cluster EKS para reduzir custos e minimizar a latência.
Se você quiser visibilidade granular da quantidade de tráfego cross-AZ entre os pods em seu cluster (como a quantidade de dados transferidos em bytes), consulte
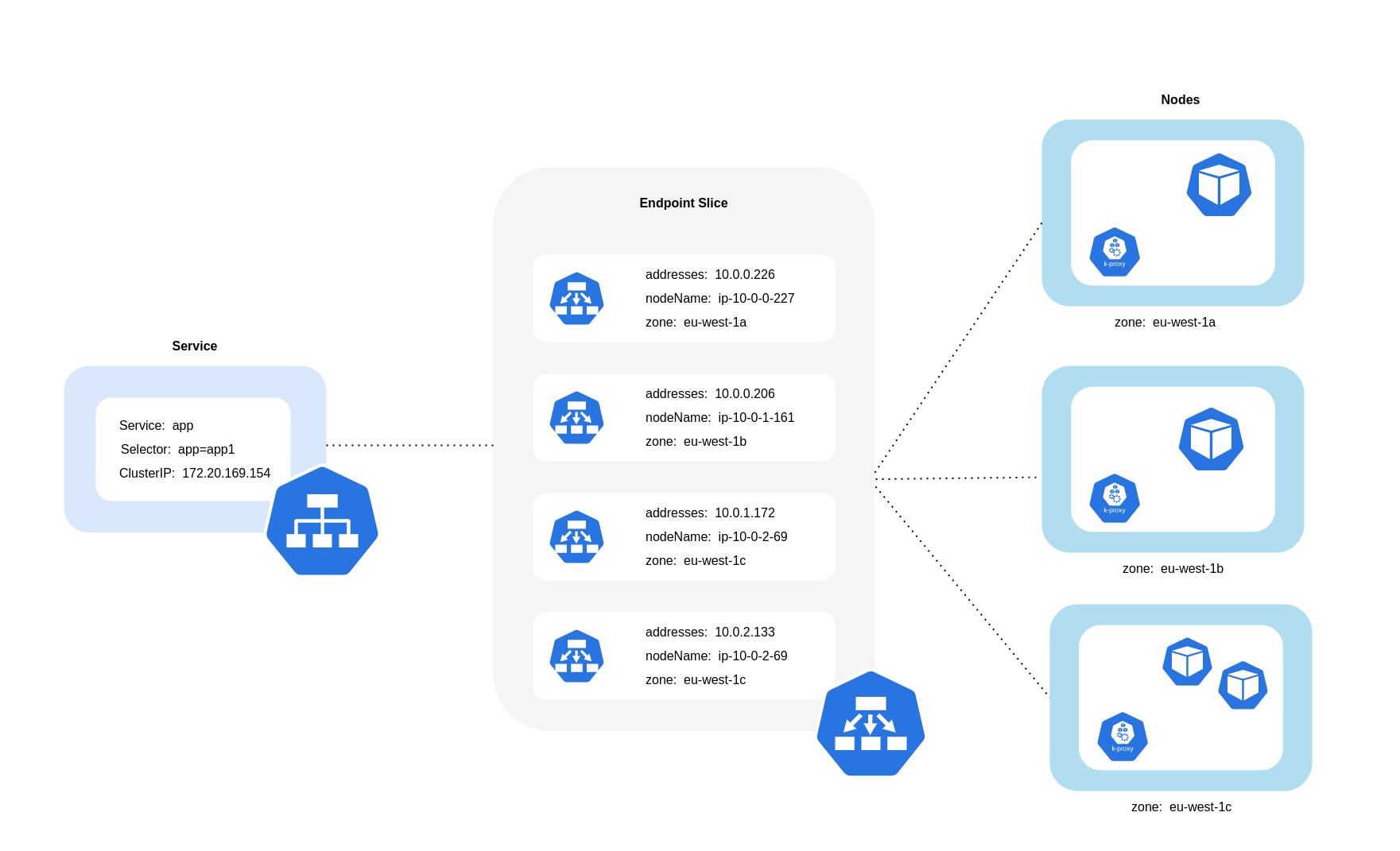
Como mostra o diagrama acima, os serviços são a camada de abstração de rede estável que recebe o tráfego destinado aos seus pods. Quando um serviço é criado, vários EndpointSlices são criados. Cada um EndpointSlice tem uma lista de endpoints contendo um subconjunto de endereços de pod junto com os nós em que estão sendo executados e qualquer informação adicional de topologia. Ao usar a CNI da Amazon VPC, o kube-proxy, um daemonset executado em cada nó, mantém as regras de rede para permitir a comunicação do pod e a descoberta de serviços (uma alternativa baseada em EBPF CNIs pode não usar o kube-proxy, mas fornecer um comportamento equivalente). Ele cumpre o papel de roteamento interno, mas o faz com base no que consome do criado. EndpointSlices
No EKS, o kube-proxy usa principalmente regras NAT iptables (ou IPVS, NFTables
Usando o roteamento com reconhecimento de topologia (anteriormente conhecido como dicas com reconhecimento de topologia)
Quando o roteamento com reconhecimento de topologiakube-proxyem seguida, roteará o tráfego de uma zona para um endpoint com base nas dicas aplicadas.
O diagrama abaixo mostra como EndpointSlices as dicas são organizadas de forma que kube-proxy possam saber para qual destino elas devem ir com base em seu ponto de origem zonal. Sem dicas, essa alocação ou organização não existe e o tráfego será enviado por proxy para diferentes destinos zonais, independentemente de sua origem.
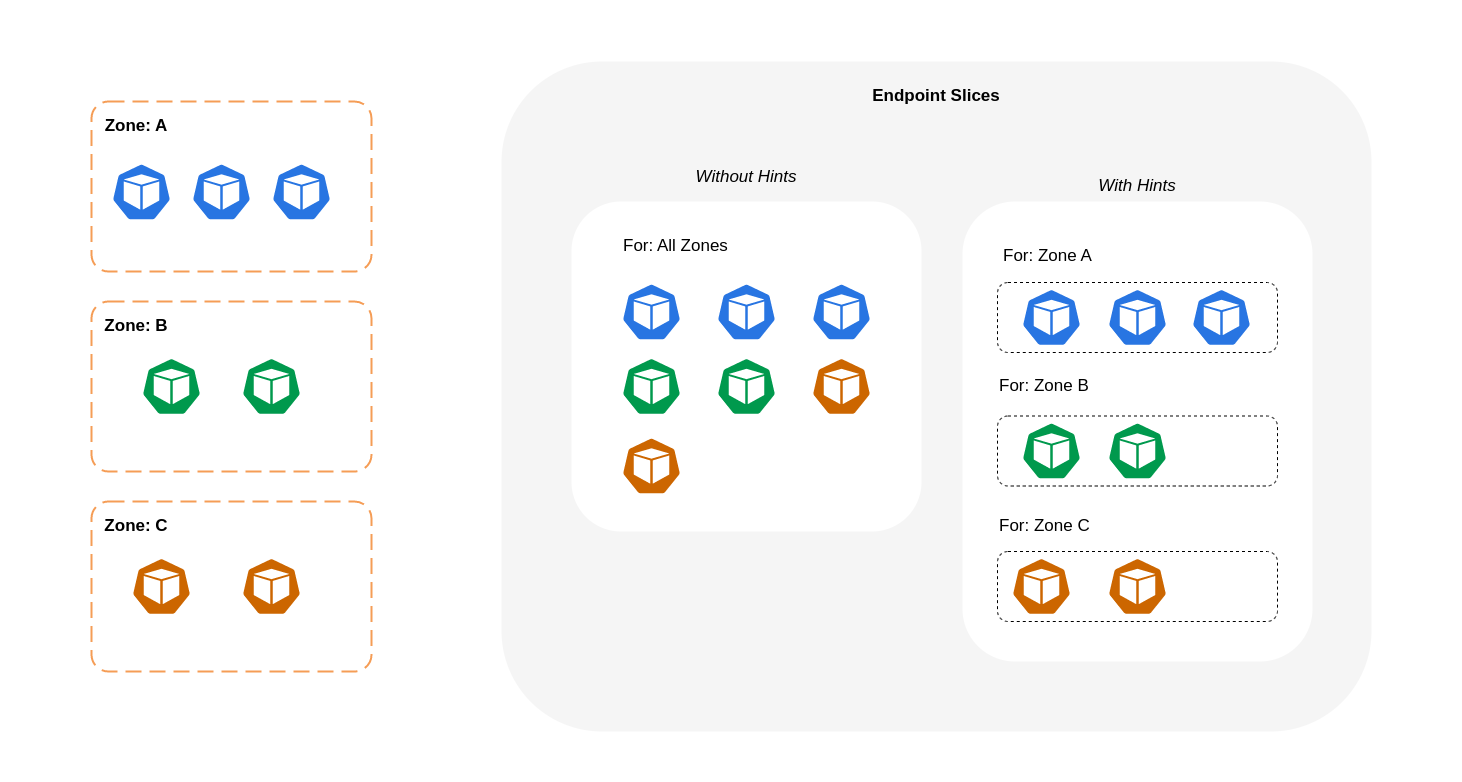
Em alguns casos, o EndpointSlice controlador pode aplicar uma dica para uma zona diferente, o que significa que o endpoint pode acabar servindo tráfego proveniente de uma zona diferente. A razão para isso é tentar manter uma distribuição uniforme do tráfego entre endpoints em diferentes zonas.
Abaixo está um trecho de código sobre como habilitar o roteamento com reconhecimento de topologia para um serviço.
apiVersion: v1 kind: Service metadata: name: orders-service namespace: ecommerce annotations: service.kubernetes.io/topology-mode: Auto spec: selector: app: orders type: ClusterIP ports: * protocol: TCP port: 3003 targetPort: 3003
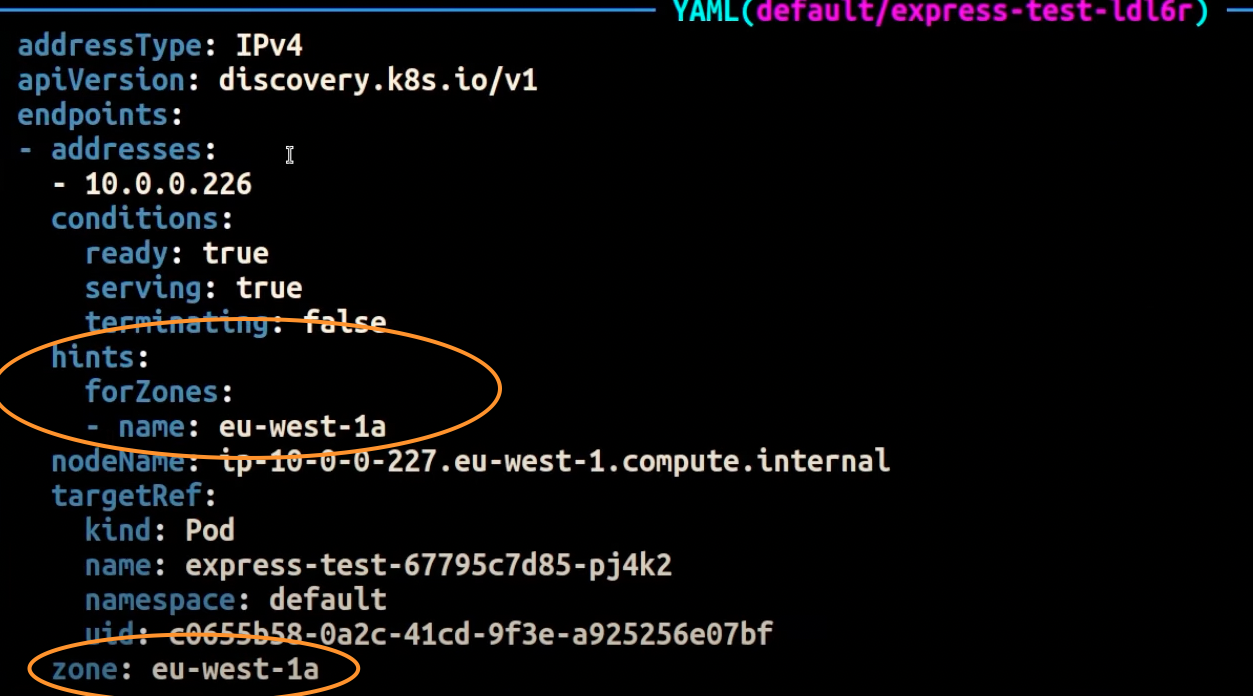
A captura de tela abaixo mostra o resultado da aplicação bem-sucedida pela EndpointSlice controladora de uma dica em um endpoint para uma réplica de pod em execução no AZ. eu-west-1a
nota
É importante observar que o roteamento com reconhecimento de topologia ainda está na versão beta. Esse recurso funciona de forma mais previsível com cargas de trabalho distribuídas uniformemente na topologia do cluster, pois o controlador aloca endpoints proporcionalmente entre as zonas, mas pode ignorar as atribuições de dicas quando os recursos do nó em uma zona estão muito desequilibrados para evitar sobrecarga excessiva. Portanto, é altamente recomendável usá-lo em conjunto com restrições de agendamento que aumentem a disponibilidade de um aplicativo, como restrições de dispersão da topologia do pod
Usando a distribuição de tráfego
Introduzida no Kubernetes 1.30 e disponibilizada em geral na versão 1.33, a distribuição de tráfego
Abaixo está um trecho de código sobre como habilitar a distribuição de tráfego para um serviço.
apiVersion: v1 kind: Service metadata: name: orders-service namespace: ecommerce spec: trafficDistribution: PreferClose selector: app: orders type: ClusterIP ports: * protocol: TCP port: 3003 targetPort: 3003
Ao habilitar a distribuição de tráfego, surge um desafio comum: os endpoints em uma única AZ podem ficar sobrecarregados se a maior parte do tráfego for originada dessa mesma zona. Essa sobrecarga pode criar problemas significativos:
-
Um único escalador automático horizontal de pods (HPA) gerenciando uma implantação Multi-AZ pode responder escalando pods em diferentes. AZs No entanto, essa ação falha em abordar efetivamente o aumento da carga na zona afetada.
-
Essa situação, por sua vez, pode levar à ineficiência de recursos. Quando autoescaladores de cluster, como o Karpenter, detectam a expansão horizontal do pod em diferentes AZs, eles podem provisionar nós adicionais nos não afetados, resultando em alocação AZs desnecessária de recursos.
Para superar esse desafio:
-
Crie implantações separadas por zona, que teriam suas próprias HPAs escalas independentes umas das outras.
-
Aproveite as restrições de dispersão de topologia para garantir a distribuição da carga de trabalho em todo o cluster, o que ajuda a evitar sobrecargas de endpoints em zonas de alto tráfego.
Usando autoescaladores: provisionar nós para uma AZ específica
É altamente recomendável executar suas cargas de trabalho em ambientes altamente disponíveis em vários AZs ambientes. Isso melhora a confiabilidade de seus aplicativos, especialmente quando há um incidente de um problema com uma AZ. Caso esteja disposto a sacrificar a confiabilidade para reduzir os custos relacionados à rede, você pode restringir seus nós a uma única AZ.
Para executar todos os seus pods na mesma AZ, provisione os nós de trabalho na mesma AZ ou programe os pods nos nós de trabalho em execução na mesma AZ. Para provisionar nós em uma única AZ, defina um grupo de nós com sub-redes pertencentes à mesma AZ com o Cluster Autoscalertopology.kubernetes.io/zone e especifique a AZ em que você gostaria de criar os nós de trabalho. Por exemplo, o trecho do provisionador Karpenter abaixo provisiona os nós na AZ us-west-2a.
Karpenter
apiVersion: karpenter.sh/v1 kind: Provisioner metadata: name: single-az spec: requirements: * key: "topology.kubernetes.io/zone"` operator: In values: ["us-west-2a"]
Autoescalador de cluster (CA)
apiVersion: eksctl.io/v1alpha5 kind: ClusterConfig metadata: name: my-ca-cluster region: us-east-1 version: "1.21" availabilityZones: * us-east-1a managedNodeGroups: * name: managed-nodes labels: role: managed-nodes instanceType: t3.medium minSize: 1 maxSize: 10 desiredCapacity: 1 ...
Usando Pod Assignment e Node Affinity
Como alternativa, se você tiver nós de trabalho em execução em vários AZs, cada nó terá o rótulo topology.kubernetes.io/zonenodeSelector ou nodeAffinity programar pods para os nós em um único AZ. Por exemplo, o arquivo de manifesto a seguir agendará o pod dentro de um nó em execução no AZ us-west-2a.
apiVersion: v1 kind: Pod metadata: name: nginx labels: env: test spec: nodeSelector: topology.kubernetes.io/zone: us-west-2a containers: * name: nginx image: nginx imagePullPolicy: IfNotPresent
Restringindo o tráfego a um nó
Há casos em que restringir o tráfego em um nível zonal não é suficiente. Além de reduzir custos, você pode ter a necessidade adicional de reduzir a latência da rede entre determinados aplicativos que têm intercomunicação frequente. Para obter o desempenho ideal da rede e reduzir custos, você precisa de uma forma de restringir o tráfego a um nó específico. Por exemplo, o microsserviço A deve sempre se comunicar com o microsserviço B no nó 1, mesmo em configurações de alta disponibilidade (HA). Ter o Microsserviço A no Nó 1 conversando com o Microsserviço B no Nó 2 pode ter um impacto negativo no desempenho desejado para aplicativos dessa natureza, especialmente se o Nó 2 estiver em uma AZ totalmente separada.
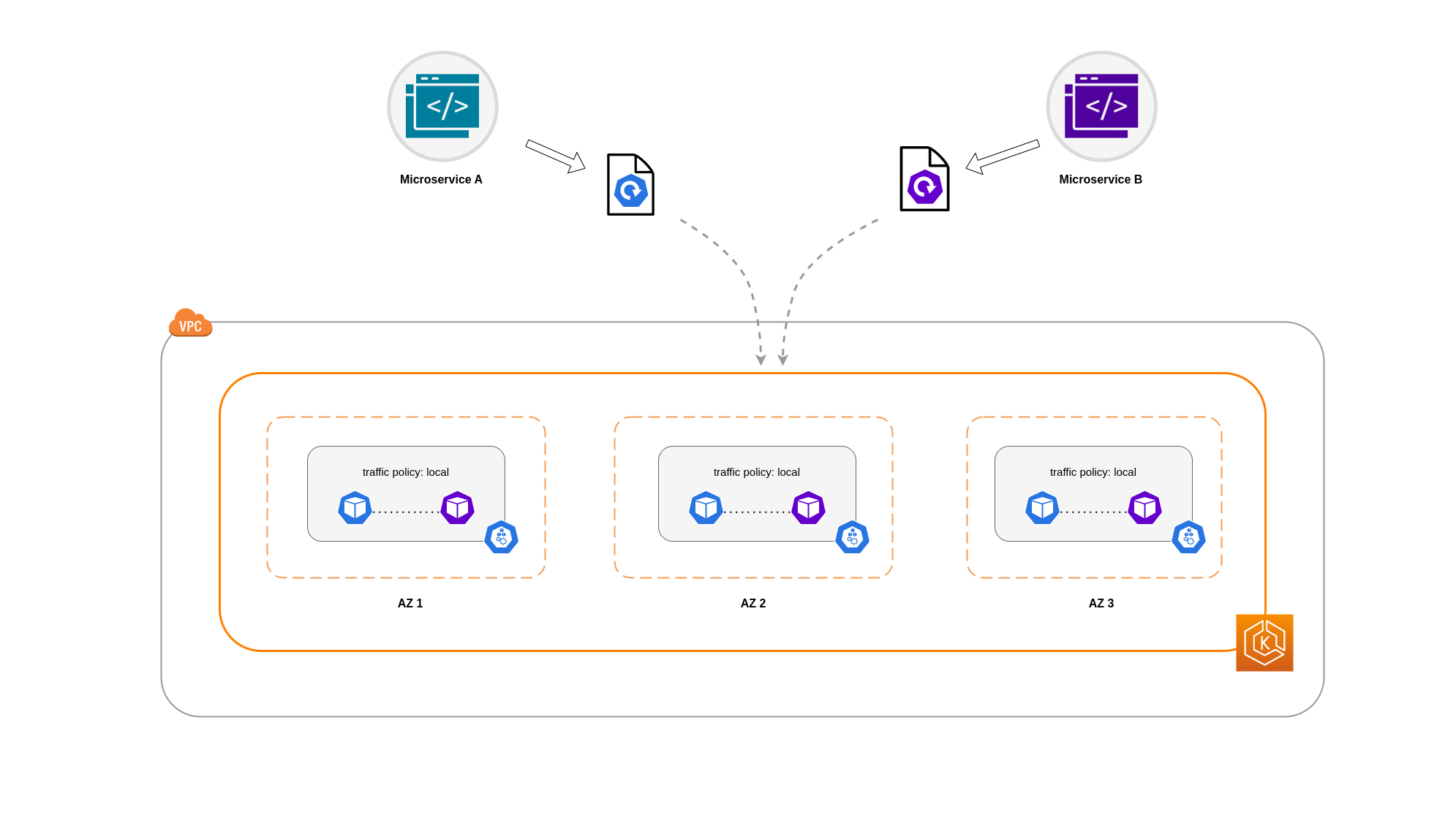
Usando a Política de Tráfego Interno do Serviço
Para restringir o tráfego de rede do Pod a um nó, você pode usar a política de tráfego interno do ServiçoLocal, o tráfego será restrito aos endpoints no nó de onde o tráfego se originou. Essa política determina o uso exclusivo de endpoints locais de nós. Por implicação, seus custos relacionados ao tráfego de rede para essa carga de trabalho serão menores do que se a distribuição fosse em todo o cluster. Além disso, a latência será menor, tornando seu aplicativo mais eficiente.
nota
É importante observar que esse recurso não pode ser combinado com o roteamento com reconhecimento de topologia no Kubernetes.
Abaixo está um trecho de código sobre como definir a política de tráfego interno para um serviço.
apiVersion: v1 kind: Service metadata: name: orders-service namespace: ecommerce spec: selector: app: orders type: ClusterIP ports: * protocol: TCP port: 3003 targetPort: 3003 internalTrafficPolicy: Local
Para evitar um comportamento inesperado do seu aplicativo devido a quedas de tráfego, você deve considerar as seguintes abordagens:
-
Execute réplicas suficientes para cada um dos pods comunicantes
-
Tenha uma distribuição relativamente uniforme de pods usando restrições de distribuição de topologia
-
Faça uso das regras de afinidade de pods para co-localização
de pods comunicantes
Neste exemplo, você tem 2 réplicas do Microsserviço A e 3 réplicas do Microsserviço B. Se o Microsserviço A tiver suas réplicas espalhadas entre os nós 1 e 2, e o Microsserviço B tiver todas as suas 3 réplicas no Nó 3, eles não conseguirão se comunicar por causa da política de tráfego interna. Local Quando não há endpoints locais de nós disponíveis, o tráfego é interrompido.

Se o microsserviço B tiver 2 de suas 3 réplicas nos nós 1 e 2, haverá comunicação entre os aplicativos de mesmo nível. Mas você ainda teria uma réplica isolada do Microservice B sem nenhuma réplica de mesmo nível com a qual se comunicar.
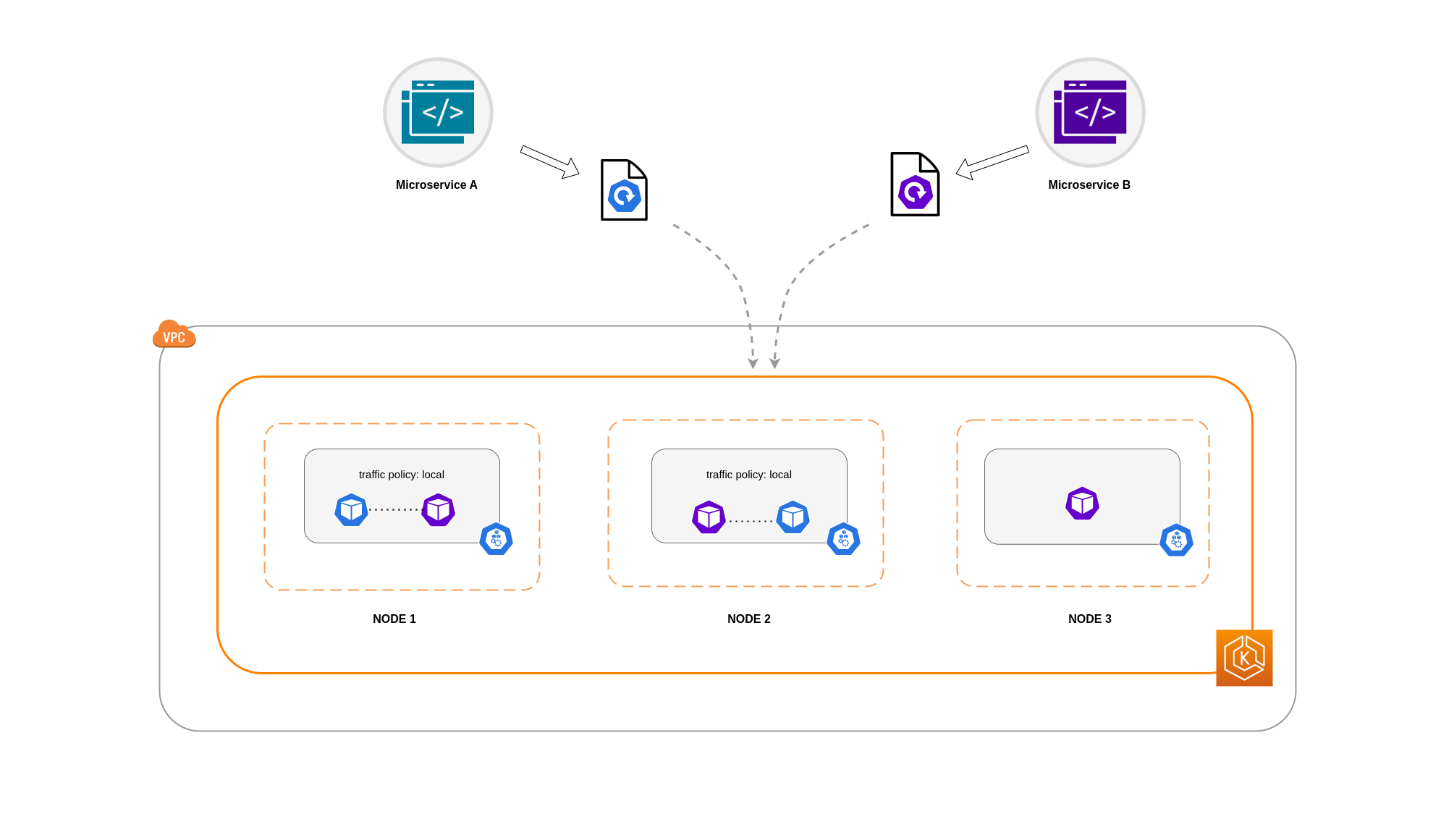
nota
Em alguns cenários, uma réplica isolada como a mostrada no diagrama acima pode não ser motivo de preocupação se ainda servir a um propósito (como atender solicitações de tráfego externo de entrada).
Usando a Política de Tráfego Interno do Serviço com Restrições de Distribuição de Topologia
Usar a política de tráfego interno em conjunto com restrições de dispersão de topologia pode ser útil para garantir que você tenha o número certo de réplicas para comunicação de microsserviços em nós diferentes.
apiVersion: apps/v1 kind: Deployment metadata: name: express-test spec: replicas: 6 selector: matchLabels: app: express-test template: metadata: labels: app: express-test tier: backend spec: topologySpreadConstraints: - maxSkew: 1 topologyKey: "topology.kubernetes.io/zone" whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: app: express-test
Usando a política de tráfego interno do serviço com as regras de afinidade do Pod
Outra abordagem é usar as regras de afinidade do Pod ao usar a política de tráfego interno do Service. Com a afinidade de Pod, você pode influenciar o agendador a co-localizar determinados Pods por causa de sua comunicação frequente. Ao aplicar restrições estritas de agendamento (requiredDuringSchedulingIgnoredDuringExecution) em determinados pods, você obterá melhores resultados para a co-localização de pods quando o programador estiver colocando pods em nós.
apiVersion: apps/v1 kind: Deployment metadata: name: graphql namespace: ecommerce labels: app.kubernetes.io/version: "0.1.6" ... spec: serviceAccountName: graphql-service-account affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - orders topologyKey: "kubernetes.io/hostname"
Comunicação entre o Load Balancer e o pod
As cargas de trabalho do EKS geralmente são gerenciadas por um balanceador de carga que distribui o tráfego para os pods relevantes em seu cluster EKS. Sua arquitetura pode incluir balanceadores de carga internos and/or externos. Dependendo da sua arquitetura e das configurações de tráfego de rede, a comunicação entre balanceadores de carga e pods pode contribuir significativamente para as cobranças de transferência de dados.
Você pode usar o AWS Load Balancer Controller
Ao usar o modo de instância, um NodePort será aberto em cada nó em seu cluster EKS. O balanceador de carga então distribuirá o tráfego uniformemente entre os nós. Se um nó tiver o pod de destino em execução, não haverá custos de transferência de dados. No entanto, se o pod de destino estiver em um nó separado e em um AZ diferente do NodePort receptor do tráfego, haverá um salto de rede extra do kube-proxy para o pod de destino. Nesse cenário, haverá cobranças de transferência de dados entre AZ. Devido à distribuição uniforme do tráfego entre os nós, é altamente provável que haja cobranças adicionais de transferência de dados associadas aos saltos de tráfego de rede entre zonas dos proxies kube para os pods de destino relevantes.
O diagrama abaixo mostra um caminho de rede para o tráfego que flui do balanceador de carga para o e NodePort, posteriormente, do kube-proxy pod de destino em um nó separado em uma AZ diferente. Esse é um exemplo da configuração do modo de instância.

Ao usar o modo IP, o tráfego de rede é enviado por proxy do balanceador de carga diretamente para o pod de destino. Como resultado, não há cobranças de transferência de dados envolvidas nessa abordagem.
nota
É recomendável que você defina seu balanceador de carga para o modo de tráfego IP para reduzir as cobranças de transferência de dados. Para essa configuração, também é importante garantir que seu balanceador de carga seja implantado em todas as sub-redes em sua VPC.
O diagrama abaixo mostra os caminhos de rede para o tráfego que flui do balanceador de carga para os pods no modo IP da rede.
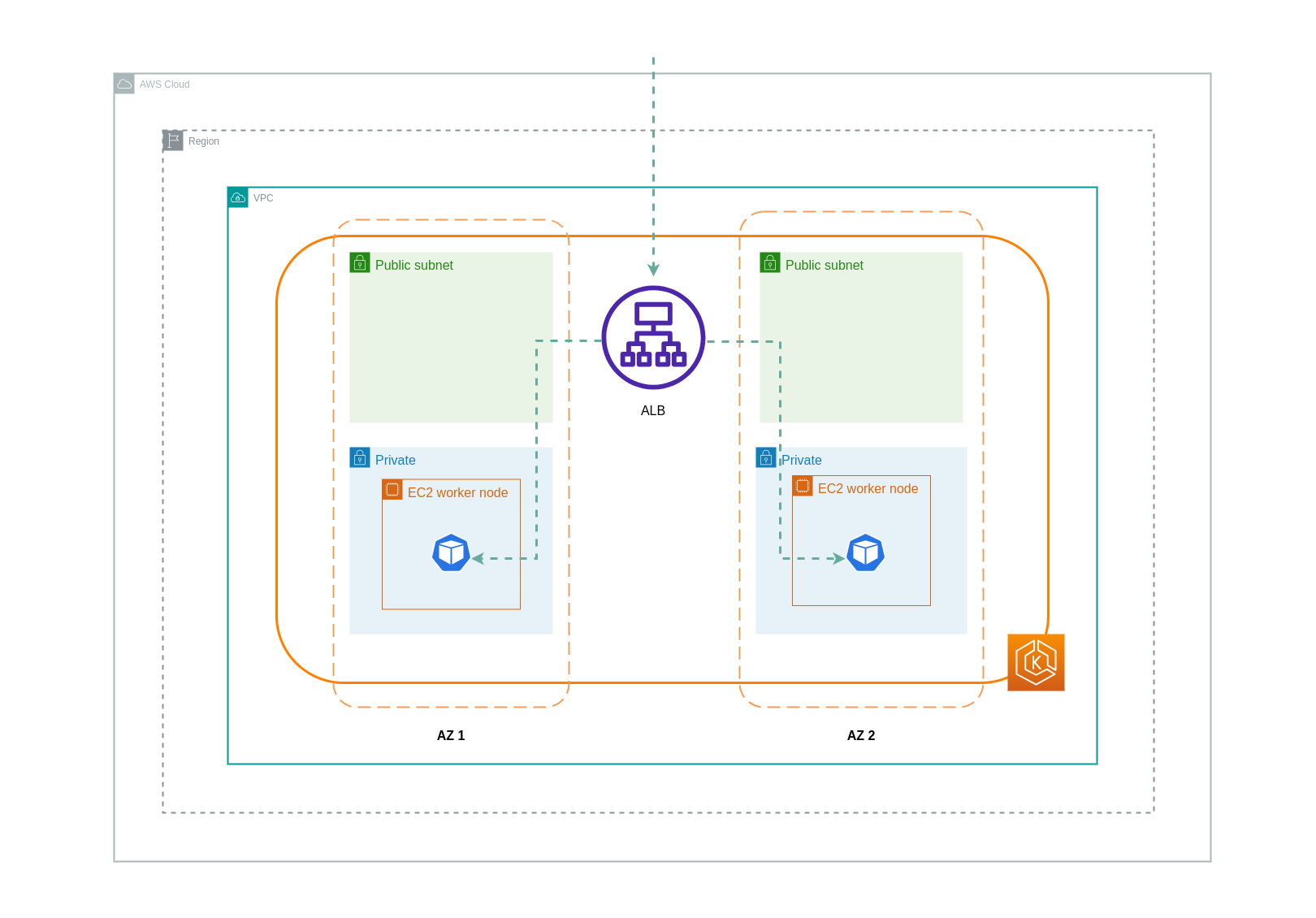
Transferência de dados do Container Registry
Amazon ECR
A transferência de dados para o registro privado do Amazon ECR é gratuita. A transferência de dados na região não tem custo, mas a transferência de dados para a Internet e entre regiões será cobrada de acordo com as taxas de transferência de dados pela Internet em ambos os lados da transferência.
Você deve utilizar o recurso ECRs integrado de replicação de imagens para replicar as imagens relevantes do contêiner na mesma região das suas cargas de trabalho. Dessa forma, a replicação seria carregada uma vez e todas as capturas de imagem da mesma região (intrarregião) seriam gratuitas.
Você pode reduzir ainda mais os custos de transferência de dados associados à extração de imagens do ECR (transferência de dados para fora) usando o Interface VPC Endpoints para se conectar aos repositórios ECR da região. A abordagem alternativa de se conectar ao endpoint público da AWS do ECR (por meio de um NAT Gateway e um Internet Gateway) acarretará maiores custos de processamento e transferência de dados. A próxima seção abordará a redução dos custos de transferência de dados entre suas cargas de trabalho e os serviços da AWS com mais detalhes.
Se você estiver executando cargas de trabalho com imagens especialmente grandes, você pode criar suas próprias Amazon Machine Images (AMIs) personalizadas com imagens de contêiner pré-armazenadas em cache. Isso pode reduzir o tempo inicial de extração da imagem e os possíveis custos de transferência de dados de um registro de contêiner para os nós de trabalho do EKS.
Transferência de dados para a Internet e serviços da AWS
É uma prática comum integrar cargas de trabalho do Kubernetes com outros serviços da AWS ou ferramentas e plataformas de terceiros pela Internet. A infraestrutura de rede subjacente usada para rotear o tráfego de e para o destino relevante pode afetar os custos incorridos no processo de transferência de dados.
Usando gateways NAT
Os gateways NAT são componentes de rede que realizam a tradução de endereços de rede (NAT). O diagrama abaixo mostra pods em um cluster EKS se comunicando com outros serviços da AWS (Amazon ECR, DynamoDB e S3) e plataformas de terceiros. Neste exemplo, os pods estão sendo executados em sub-redes privadas separadas. AZs Para enviar e receber tráfego da Internet, um NAT Gateway é implantado na sub-rede pública de uma AZ, permitindo que qualquer recurso com endereços IP privados compartilhe um único endereço IP público para acessar a Internet. Esse NAT Gateway, por sua vez, se comunica com o componente Internet Gateway, permitindo que os pacotes sejam enviados ao seu destino final.
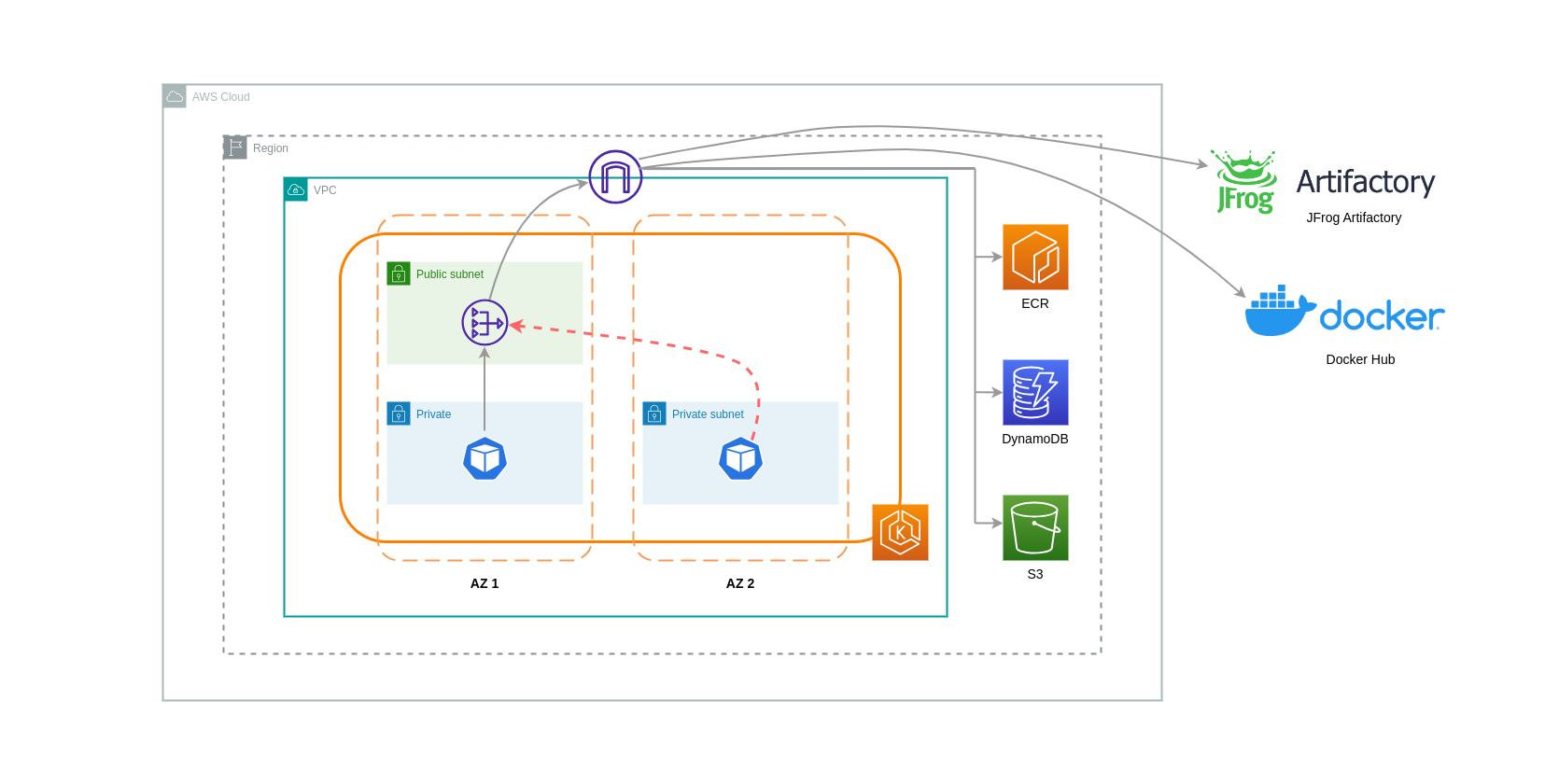
Ao usar gateways NAT para esses casos de uso, você pode minimizar os custos de transferência de dados implantando um gateway NAT em cada AZ. Dessa forma, o tráfego roteado para a Internet passará pelo NAT Gateway na mesma AZ, evitando a transferência de dados entre AZ. No entanto, mesmo que você economize no custo da transferência de dados Inter-AZ, a implicação dessa configuração é que você incorrerá no custo de um NAT Gateway adicional em sua arquitetura.
Essa abordagem recomendada é mostrada no diagrama abaixo.
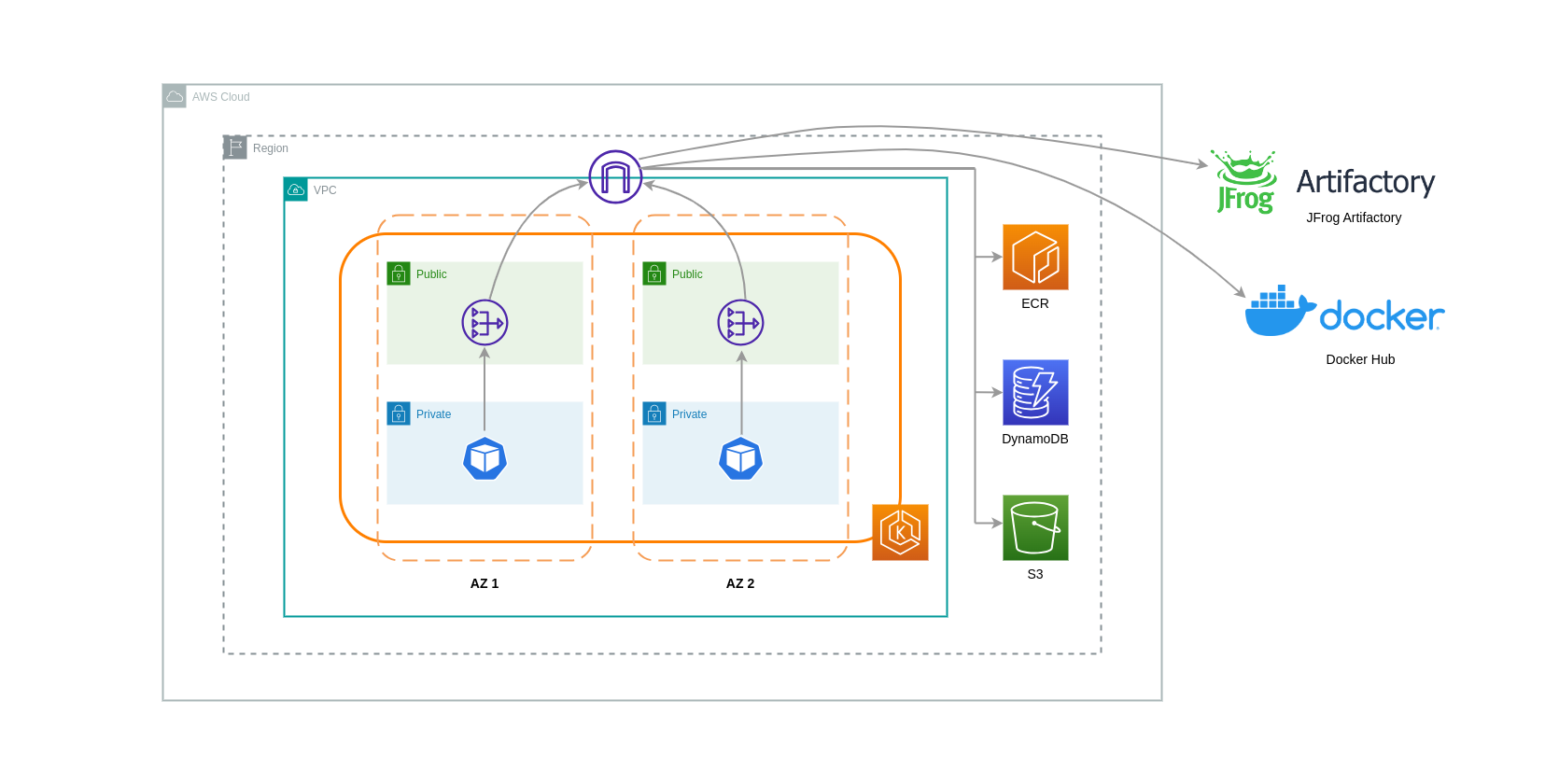
Uso de endpoints da VPC
Para reduzir ainda mais os custos nessas arquiteturas, você deve usar VPC Endpoints para estabelecer conectividade entre suas cargas de trabalho e os serviços da AWS. Os VPC Endpoints permitem que você acesse os serviços da AWS de dentro de uma VPC sem data/network que pacotes atravessem a Internet. Todo o tráfego é interno e permanece dentro da rede da AWS. Há dois tipos de VPC Endpoints: VPC Endpoints de interface (compatíveis com vários serviços da AWS) e VPC Endpoints de gateway (compatíveis somente com S3 e DynamoDB).
Endpoints VPC de gateway
Não há custos horários ou de transferência de dados associados aos Gateway VPC Endpoints. Ao usar os VPC Endpoints do Gateway, é importante observar que eles não podem ser estendidos além dos limites da VPC. Eles não podem ser usados em emparelhamento de VPC, redes VPN ou via Direct Connect.
Interface VPC Endpoints
Os VPC Endpoints têm uma cobrança por hora e uma cobrança
O diagrama abaixo mostra os pods se comunicando com os serviços da AWS por meio de VPC Endpoints.
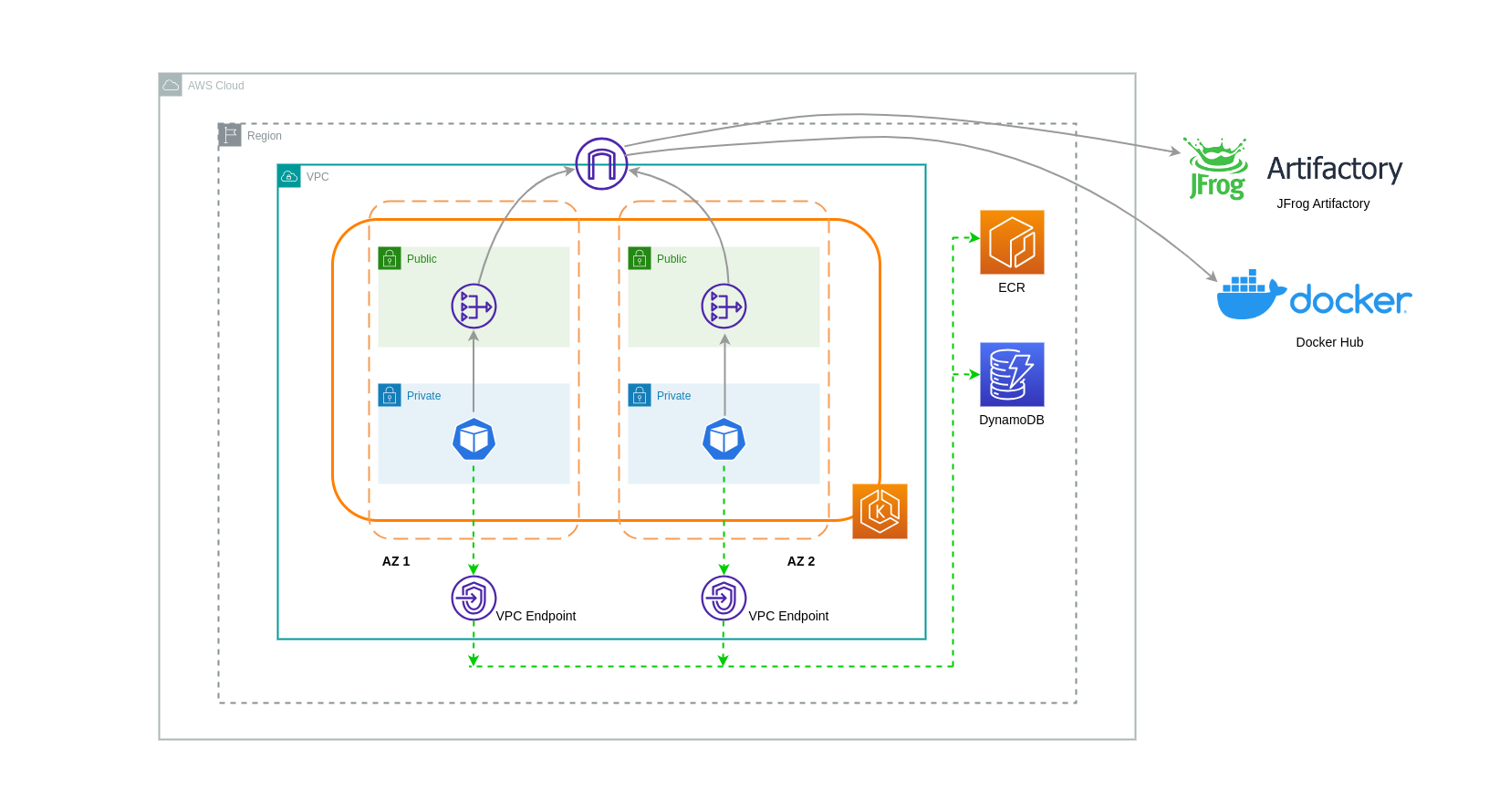
Transferência de dados entre VPCs
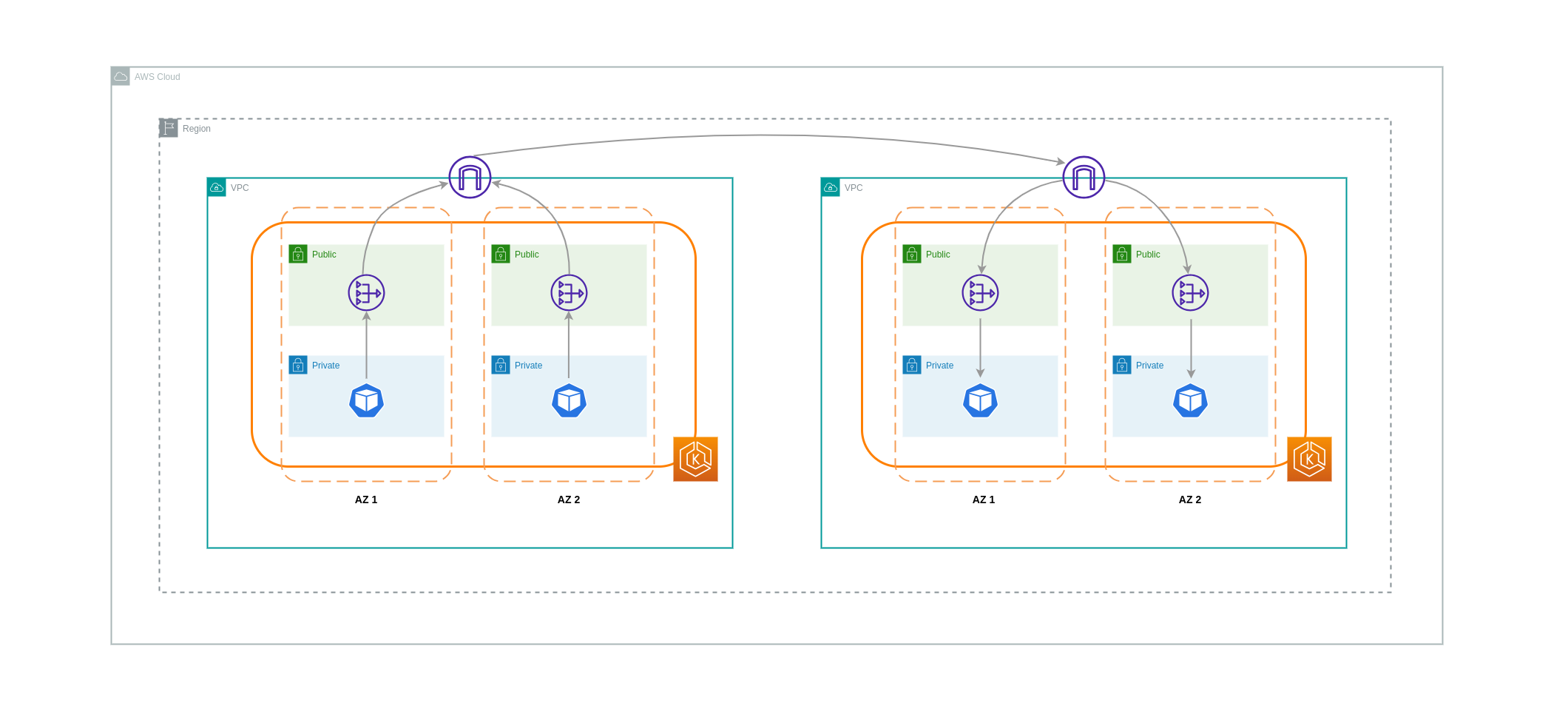
Em alguns casos, você pode ter cargas de trabalho distintas VPCs (dentro da mesma região da AWS) que precisam se comunicar entre si. Isso pode ser feito permitindo que o tráfego atravesse a Internet pública por meio de gateways de Internet conectados aos respectivos. VPCs Essa comunicação pode ser habilitada pela implantação de componentes de infraestrutura como EC2 instâncias, gateways NAT ou instâncias NAT em sub-redes públicas. No entanto, uma configuração incluindo esses componentes incorrerá em cobranças pelos processing/transferring dados que entram e saem do VPCs. Se o tráfego de e para o separado VPCs estiver se movendo AZs, haverá uma cobrança adicional na transferência de dados. O diagrama abaixo mostra uma configuração que usa gateways NAT e gateways de Internet para estabelecer comunicação entre cargas de trabalho em diferentes. VPCs
Conexões de emparelhamento de VPC
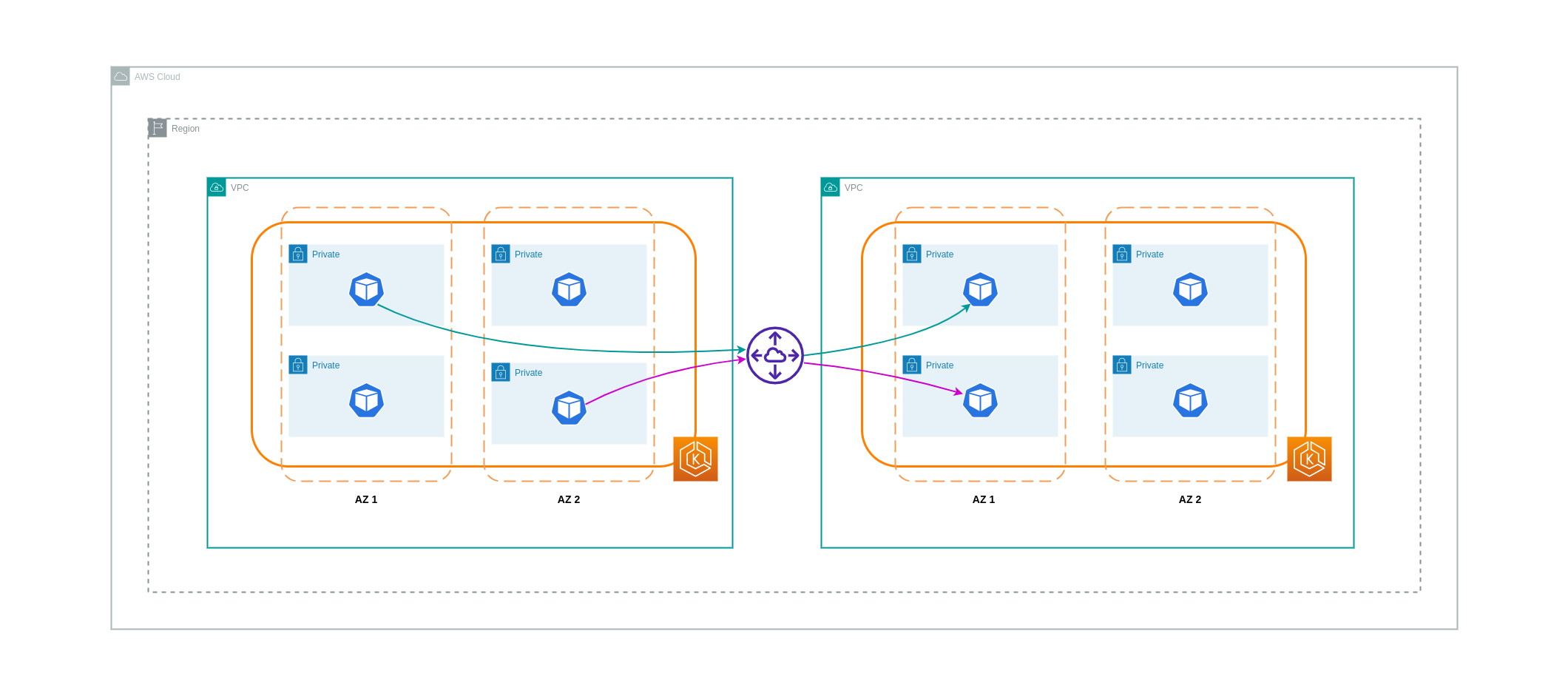
Para reduzir os custos desses casos de uso, você pode usar o VPC Peering. Com uma conexão de emparelhamento VPC, não há cobranças de transferência de dados para o tráfego de rede que permanece dentro da mesma AZ. Se o tráfego cruzar AZs, haverá um custo. No entanto, a abordagem de emparelhamento de VPC é recomendada para uma comunicação econômica entre cargas de trabalho separadas dentro da mesma região da AWS. VPCs No entanto, é importante observar que o emparelhamento de VPC é eficaz principalmente para conectividade VPC 1:1 porque não permite redes transitivas.
O diagrama abaixo é uma representação de alto nível da comunicação de cargas de trabalho por meio de uma conexão de emparelhamento de VPC.
Conexões de rede transitivas
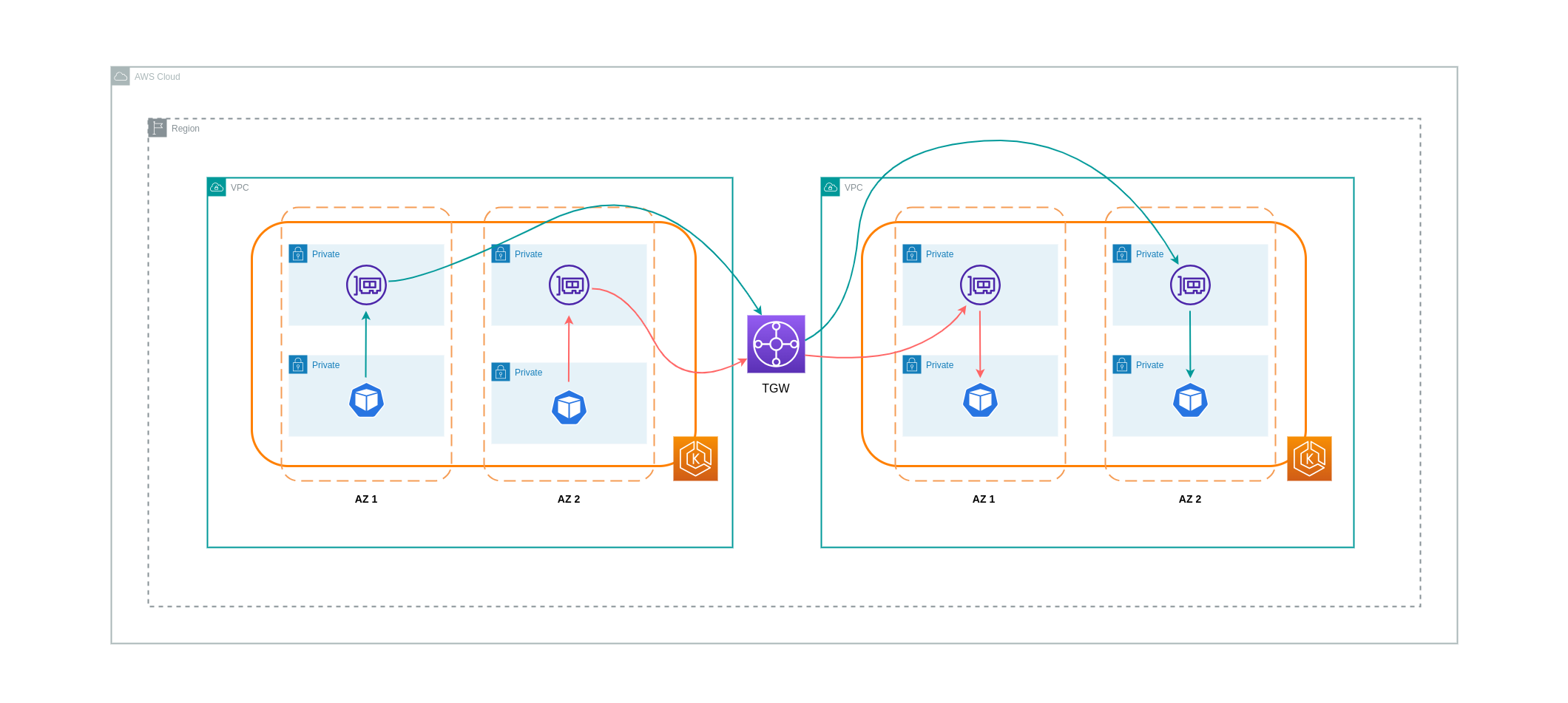
Conforme apontado na seção anterior, as conexões de emparelhamento de VPC não permitem conectividade de rede transitiva. Se você quiser conectar 3 ou mais VPCs com requisitos de rede transitiva, use um Transit Gateway (TGW). Isso permitirá que você supere os limites do emparelhamento de VPC ou qualquer sobrecarga operacional associada a ter várias conexões de emparelhamento de VPC entre várias. VPCs Você é cobrado por hora e pelos
O diagrama abaixo mostra o tráfego Inter-AZ fluindo por meio de um TGW entre cargas de trabalho diferentes, VPCs mas dentro da mesma região da AWS.
Usando um Service Mesh
Os service meshes oferecem recursos de rede poderosos que podem ser usados para reduzir os custos relacionados à rede em seus ambientes de cluster EKS. No entanto, você deve considerar cuidadosamente as tarefas operacionais e a complexidade que uma malha de serviços introduzirá em seu ambiente se você adotar uma.
Restringindo o tráfego às zonas de disponibilidade
Usando a distribuição ponderada por localidade do Istio
O Istio permite que você aplique políticas de rede ao tráfego após a ocorrência do roteamento. Isso é feito usando regras de destino
nota
Antes de implementar a distribuição ponderada por localidade, você deve começar entendendo seus padrões de tráfego de rede e as implicações que a política de regra de destino pode ter no comportamento do seu aplicativo. Dessa forma, é importante ter mecanismos de rastreamento distribuídos implementados com ferramentas como AWS X-Ray
As regras de destino do Istio detalhadas acima também podem ser aplicadas para gerenciar o tráfego de um balanceador de carga para pods em seu cluster EKS. As regras de distribuição ponderada por localidade podem ser aplicadas a um serviço que recebe tráfego de um balanceador de carga altamente disponível (especificamente o Ingress Gateway). Essas regras permitem controlar a quantidade de tráfego que vai para onde, com base em sua origem zonal - o balanceador de carga nesse caso. Se configurado corretamente, ocorrerá menos tráfego de saída entre zonas em comparação com um balanceador de carga que distribui o tráfego de maneira uniforme ou aleatória para réplicas de pod em diferentes áreas. AZs
Abaixo está um exemplo de bloco de código de um recurso de regra de destino no Istio. Como pode ser visto abaixo, esse recurso especifica configurações ponderadas para tráfego de entrada de 3 diferentes AZs na região. eu-west-1 Essas configurações declaram que a maioria do tráfego de entrada (70% nesse caso) de uma determinada AZ deve ser encaminhada por proxy para um destino na mesma AZ de onde se origina.
apiVersion: networking.istio.io/v1beta1 kind: DestinationRule metadata: name: express-test-dr spec: host: express-test.default.svc.cluster.local trafficPolicy: loadBalancer: + localityLbSetting: distribute: - from: eu-west-1/eu-west-1a/ + to: "eu-west-1/eu-west-1a/_": 70 "eu-west-1/eu-west-1b/_": 20 "eu-west-1/eu-west-1c/_": 10 - from: eu-west-1/eu-west-1b/_ + to: "eu-west-1/eu-west-1a/_": 20 "eu-west-1/eu-west-1b/_": 70 "eu-west-1/eu-west-1c/_": 10 - from: eu-west-1/eu-west-1c/_ + to: "eu-west-1/eu-west-1a/_": 20 "eu-west-1/eu-west-1b/_": 10 "eu-west-1/eu-west-1c/*": 70** connectionPool: http: http2MaxRequests: 10 maxRequestsPerConnection: 10 outlierDetection: consecutiveGatewayErrors: 1 interval: 1m baseEjectionTime: 30s
nota
O peso mínimo que pode ser distribuído no destino é 1%. O motivo para isso é manter regiões e zonas de failover no caso de os endpoints no destino principal ficarem insalubres ou indisponíveis.
O diagrama abaixo mostra um cenário em que há um balanceador de carga altamente disponível na região eu-west-1 e a distribuição ponderada por localidade é aplicada. A política de regra de destino desse diagrama está configurada para enviar 60% do tráfego proveniente de eu-west-1a para pods na mesma AZ, enquanto 40% do tráfego de eu-west-1a deve ir para pods em eu-west-1b.
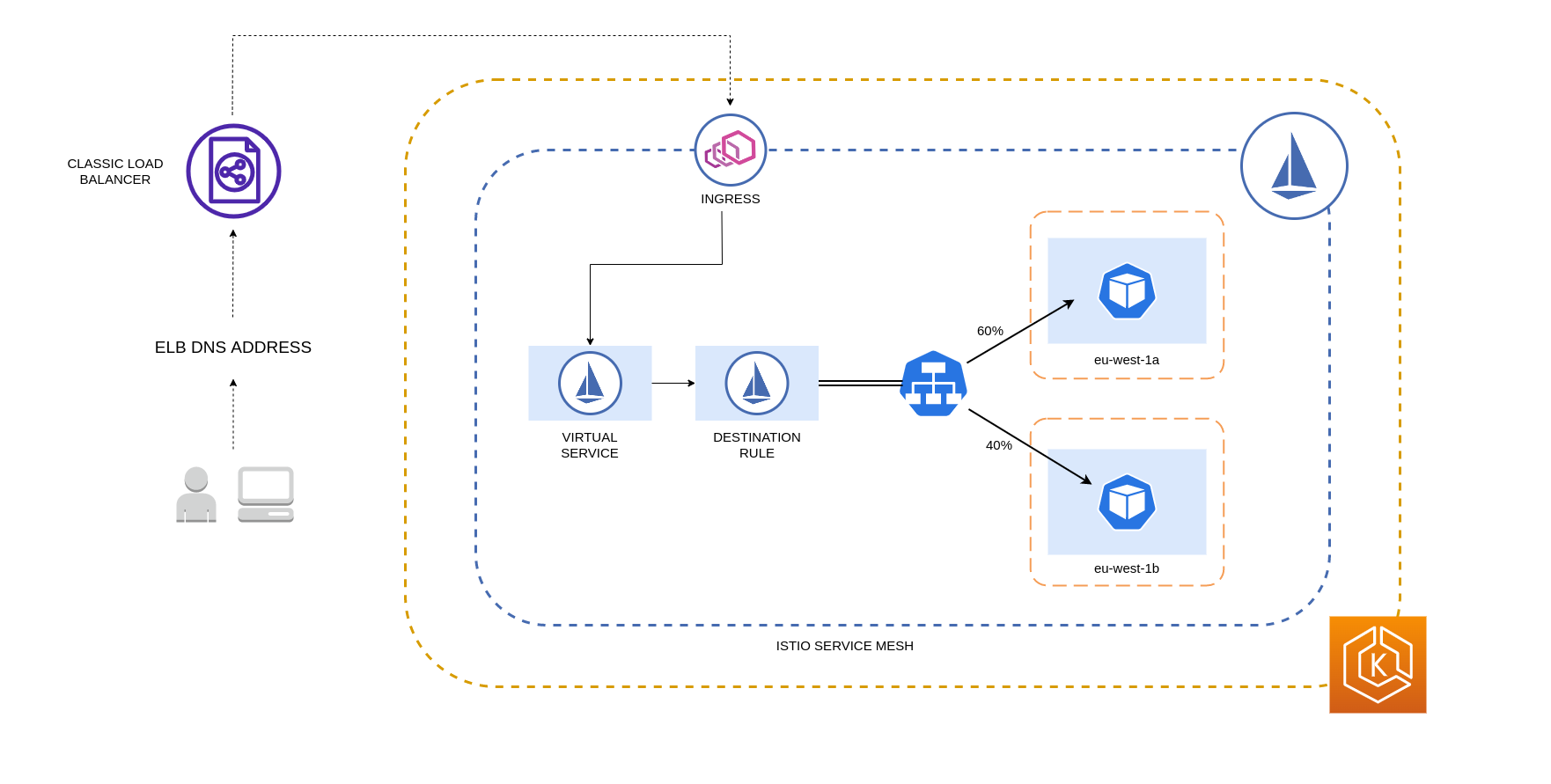
Restringindo o tráfego para zonas e nós de disponibilidade
Usando a política de tráfego interno do serviço com o Istio
Para reduzir os custos de rede associados ao tráfego externo de entrada e ao tráfego interno entre os pods, você pode combinar as regras de destino do Istio e a política de tráfego interno do Kubernetes Service. A maneira de combinar as regras de destino do Istio com a política de tráfego interno do serviço dependerá em grande parte de três coisas:
-
O papel dos microserviços
-
Padrões de tráfego de rede nos microsserviços
-
Como os microsserviços devem ser implantados em toda a topologia de cluster do Kubernetes
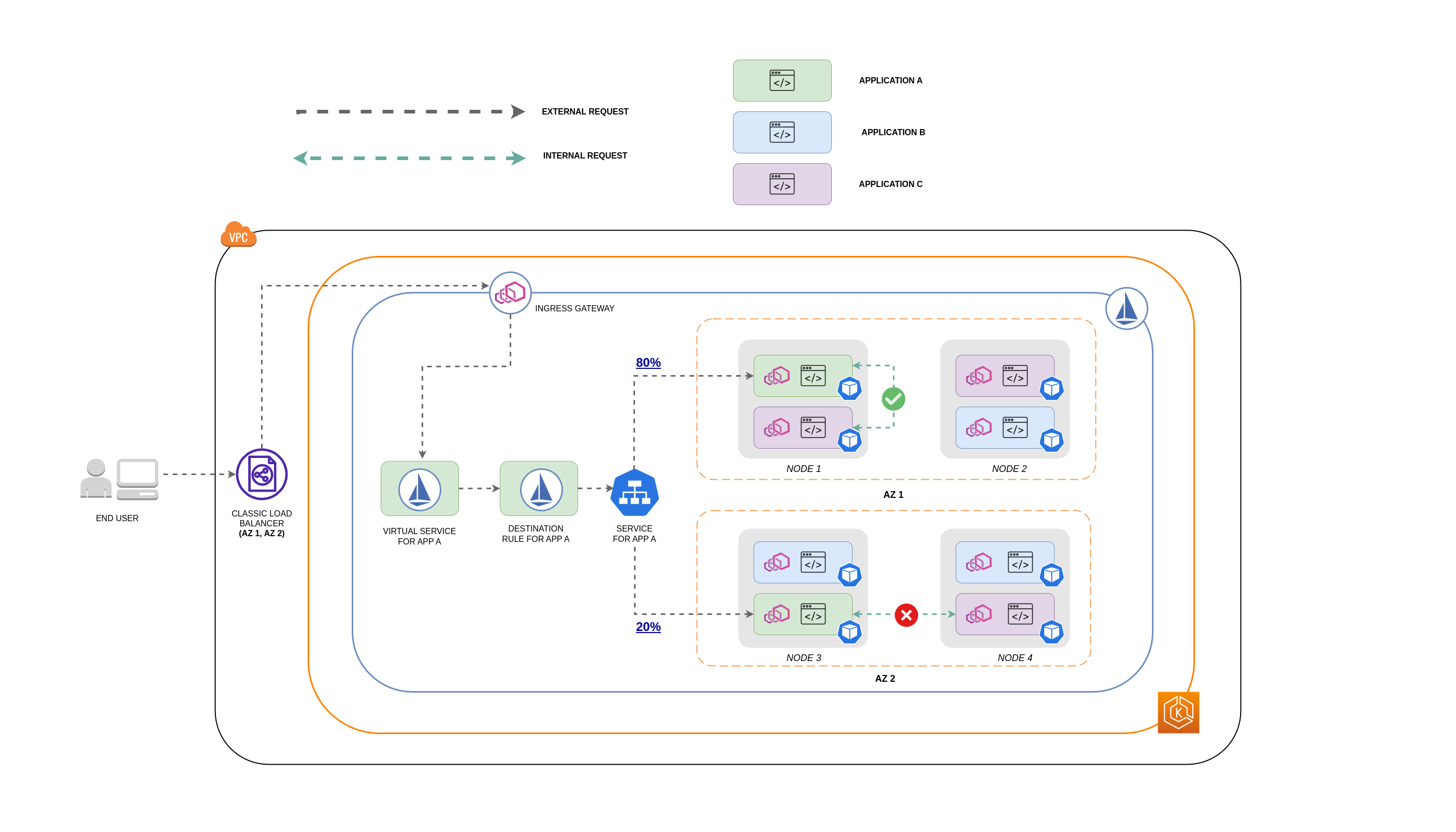
O diagrama abaixo mostra como seria o fluxo de rede no caso de uma solicitação aninhada e como as políticas mencionadas acima controlariam o tráfego.
-
O usuário final faz uma solicitação ao APP A, que por sua vez faz uma solicitação aninhada ao APP C. Essa solicitação é enviada primeiro para um balanceador de carga altamente disponível, que tem instâncias em AZ 1 e AZ 2, conforme mostra o diagrama acima.
-
A solicitação externa de entrada é então encaminhada para o destino correto pelo Istio Virtual Service.
-
Depois que a solicitação é roteada, a regra de destino do Istio controla quanto tráfego vai para o respectivo AZs com base na origem (AZ 1 ou AZ 2).
-
Em seguida, o tráfego vai para o serviço do APP A e, em seguida, é enviado por proxy para os respectivos endpoints do pod. Conforme mostrado no diagrama, 80% do tráfego de entrada é enviado para endpoints do Pod no AZ 1 e 20% do tráfego de entrada é enviado para o AZ 2.
-
O APP A então faz uma solicitação interna ao APP C. O serviço do APP C tem uma política de tráfego interna habilitada (
internalTrafficPolicy`: Local`). -
A solicitação interna do APP A (no NODE 1) para o APP C é bem-sucedida devido ao endpoint local do nó disponível para o APP C.
-
A solicitação interna do APP A (no NODE 3) para o APP C falha porque não há endpoints locais de nó disponíveis para o APP C. Como mostra o diagrama, o APP C não tem réplicas no NODE 3. * *
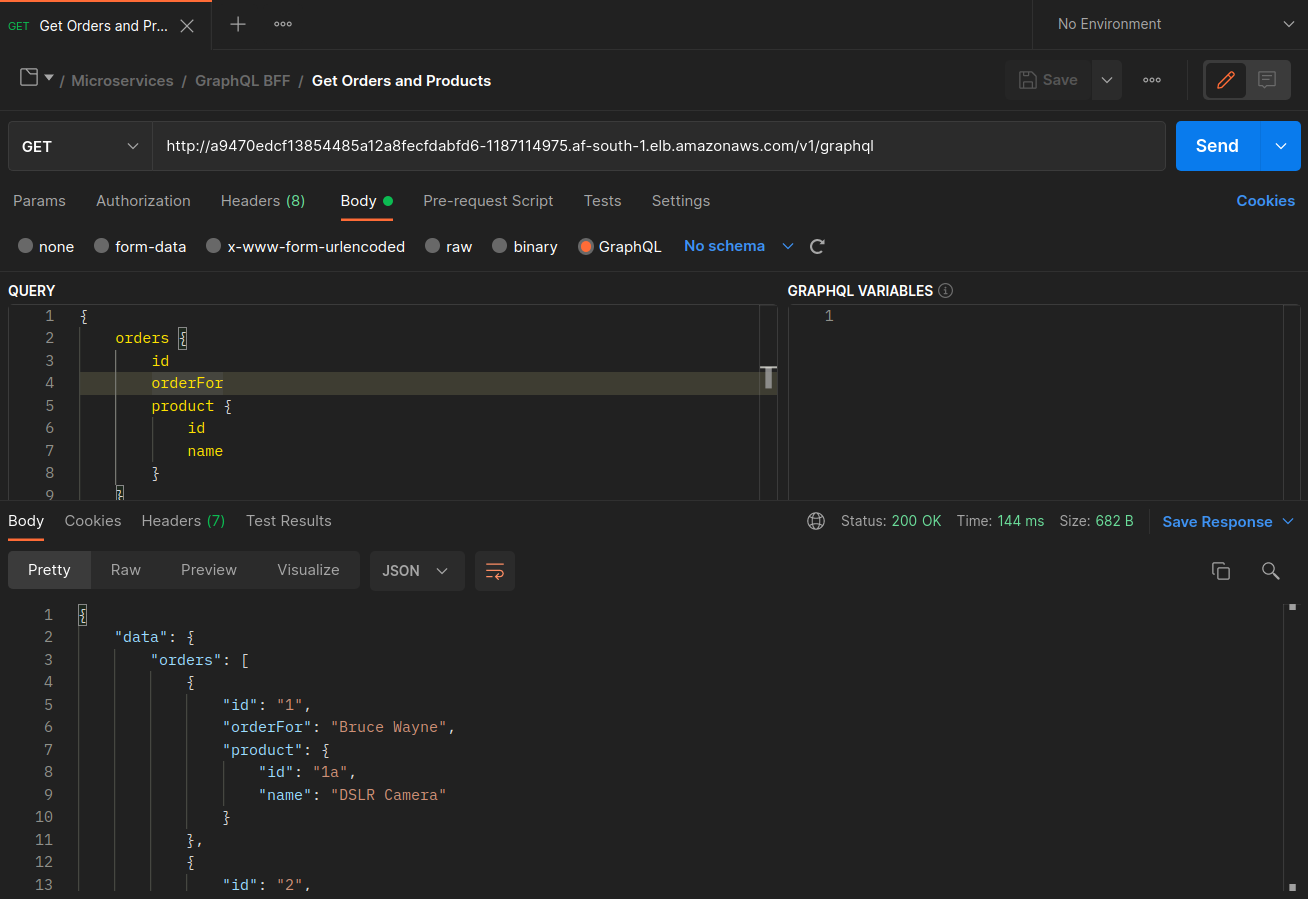
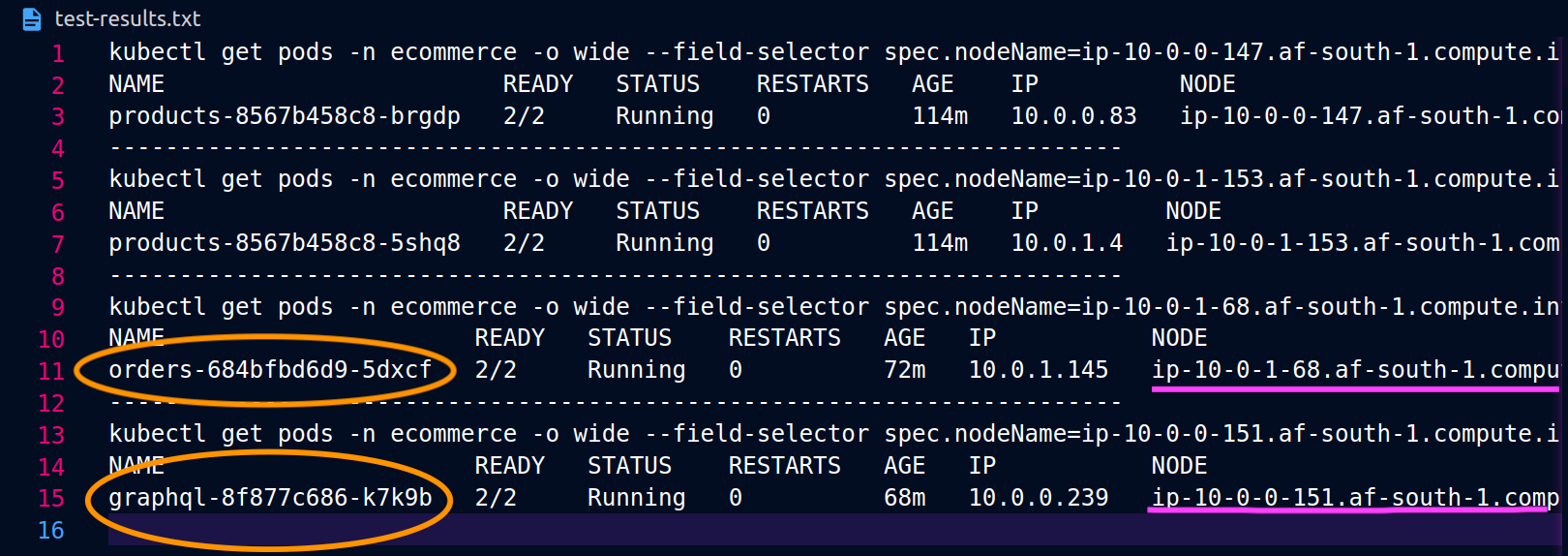
As capturas de tela abaixo foram capturadas de um exemplo ao vivo dessa abordagem. O primeiro conjunto de capturas de tela demonstra uma solicitação externa bem-sucedida para um graphql e uma solicitação aninhada bem-sucedida do graphql para uma orders réplica co-localizada no nó. ip-10-0-0-151.af-south-1.compute.internal
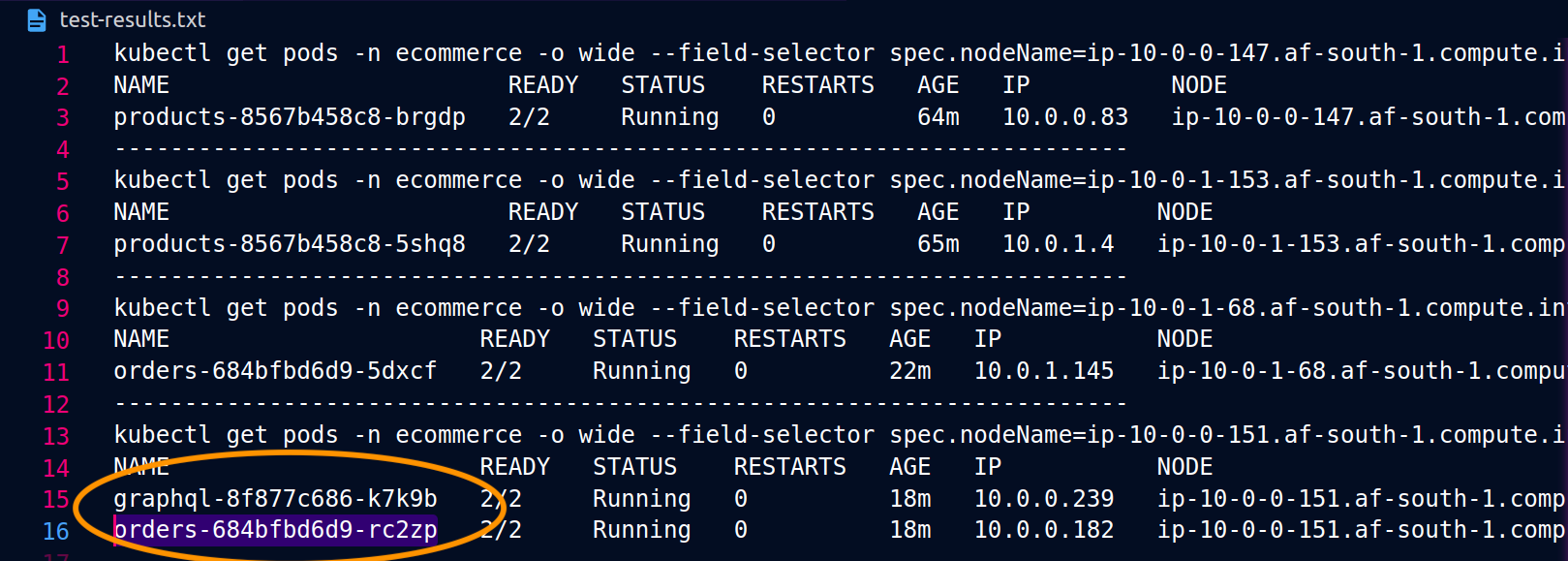
Com o Istio, você pode verificar e exportar as estatísticas de qualquer [cluster upstream] (https://www.envoyproxy. io/docs/envoy/latest/intro/arch_overview/intro/terminologyorders endpoints que o graphql proxy conhece podem ser obtidos usando o seguinte comando:
kubectl exec -it deploy/graphql -n ecommerce -c istio-proxy -- curl localhost:15000/clusters | grep orders
... orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_error::0** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_success::119** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_timeout::0** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_total::119** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**health_flags::healthy** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**region::af-south-1** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**zone::af-south-1b** ...
Nesse caso, o graphql proxy só conhece o orders endpoint da réplica com a qual compartilha um nó. Se você remover a internalTrafficPolicy: Local configuração do serviço de pedidos e executar novamente um comando como o descrito acima, os resultados retornarão todos os endpoints das réplicas espalhados pelos diferentes nós. Além disso, ao examinar os rq_total respectivos endpoints, você notará uma participação relativamente uniforme na distribuição da rede. Consequentemente, se os endpoints estiverem associados a serviços upstream executados de forma diferente AZs, essa distribuição de rede entre zonas resultará em custos mais altos.
Conforme mencionado na seção anterior acima, você pode co-localizar pods que se comunicam com frequência usando a afinidade de pods.
... spec: ... template: metadata: labels: app: graphql role: api workload: ecommerce spec: affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - orders topologyKey: "kubernetes.io/hostname" nodeSelector: managedBy: karpenter billing-team: ecommerce ...
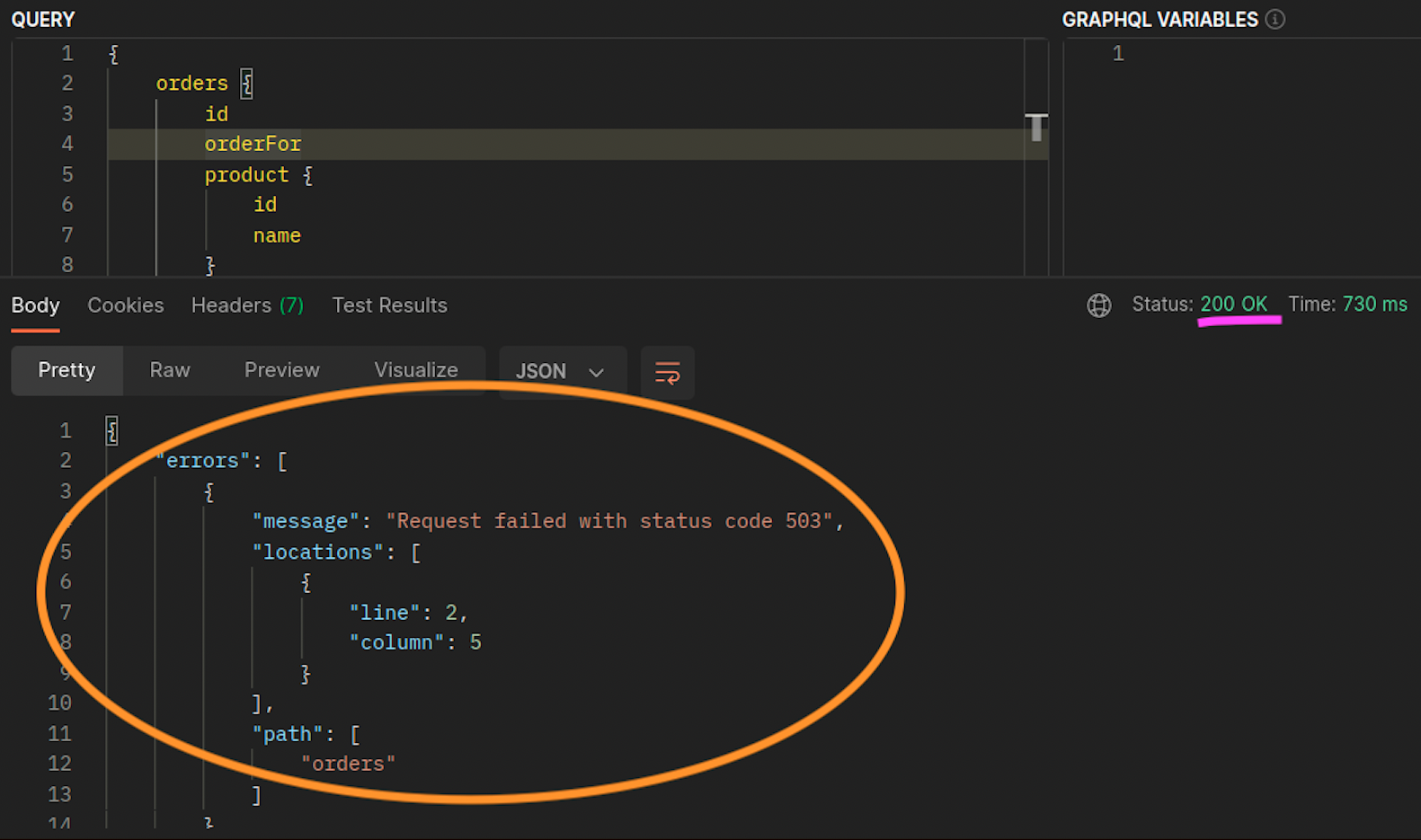
Quando as orders réplicas graphql e não coexistem no mesmo node (ip-10-0-0-151.af-south-1.compute.internal), a primeira solicitação para graphql é bem-sucedida, conforme observado 200 response code na captura de tela do Postman abaixo, enquanto a segunda solicitação aninhada de graphql para falha com a. orders 503 response code
Recursos adicionais
-
Abordando os custos de latência e transferência de dados no EKS usando o Istio
-
Obtendo visibilidade de seus bytes de rede de pod para pod do Amazon EKS Cross-AZ
-
Otimize o tráfego AZ com roteamento com reconhecimento de topologia
-
Otimize o custo e o desempenho do Kubernetes com a política de tráfego interno de serviços
-
Otimize o custo e o desempenho do Kubernetes com a política de tráfego interno do Istio e do Service
-
Visão geral dos custos de transferência de dados para arquiteturas comuns
-
Entendendo os custos de transferência de dados para serviços de contêineres da AWS
