As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Tutorial: conceitos básicos do Amazon EMR
Examine um fluxo de trabalho para configurar rapidamente um cluster do Amazon EMR e executar uma aplicação do Spark.
Configuração do cluster do Amazon EMR
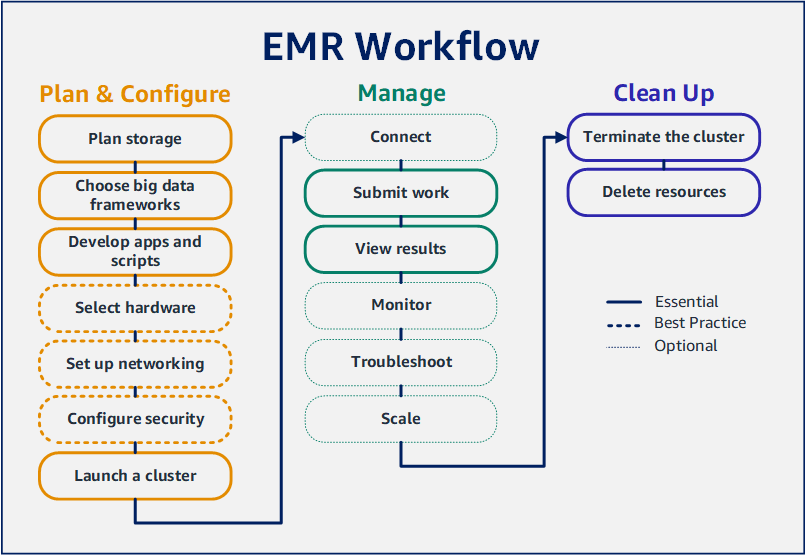
Com o Amazon EMR, é possível configurar um cluster para processar e analisar dados com estruturas de big data em apenas alguns minutos. Este tutorial mostra como iniciar um cluster de amostra usando o Spark e como executar um PySpark script simples armazenado em um bucket do Amazon S3. Ele abrange tarefas essenciais do Amazon EMR em três categorias principais de fluxo de trabalho: planejar e configurar, gerenciar e limpar.
Você encontrará links para tópicos mais detalhados à medida que avança no tutorial e obterá ideias para etapas adicionais na seção Próximas etapas. Se você tiver perguntas ou dúvidas, entre em contato com a equipe do Amazon EMR em nosso fórum de discussão
Pré-requisitos
-
Antes de iniciar um cluster do Amazon EMR, certifique-se de concluir as tarefas em Antes de configurar o Amazon EMR.
Custo
-
O exemplo de cluster que você criar será executado em um ambiente dinâmico. O cluster acumula cobranças mínimas. Para evitar cobranças adicionais, certifique-se de concluir as tarefas de limpeza na última etapa deste tutorial. As cobranças são acumuladas à taxa por segundo, de acordo com os preços do Amazon EMR. As cobranças também variam com base na região. Para obter mais informações, consulte Preço do Amazon EMR
. -
Cobranças mínimas podem ser acumuladas para arquivos pequenos armazenados no Amazon S3. Algumas ou todas as cobranças do Amazon S3 podem ser dispensadas se você estiver dentro dos limites de uso do AWS nível gratuito. Para obter mais informações, consulte Preço do Amazon S3
e nível gratuito da AWS .
Etapa 1: configurar recursos de dados e iniciar um cluster do Amazon EMR
Preparação do armazenamento para o Amazon EMR
Ao usar o Amazon EMR, é possível escolher entre uma variedade de sistemas de arquivos para armazenar dados de entrada, dados de saída e arquivos de log. Neste tutorial, você usa o EMRFS para armazenar dados em um bucket do S3. O EMRFS é uma implementação do sistema de arquivos do Hadoop que permite a leitura e a gravação de arquivos regulares no Amazon S3. Para obter mais informações, consulte Como trabalhar com armazenamento e sistemas de arquivos com o Amazon EMR.
Para criar um bucket para este tutorial, siga as instruções em How do I create an S3 bucket? no Guia do usuário do console do Amazon Simple Storage Service. Crie o bucket na mesma AWS região em que você planeja lançar seu cluster do Amazon EMR. Por exemplo, Oeste dos EUA (Oregon) us-west-2.
Os buckets e as pastas usados com o Amazon EMR têm as seguintes limitações:
-
Os nomes podem consistir em letras minúsculas, números, pontos (.) e hifens (-).
-
Os nomes não podem terminar em números.
-
O nome do bucket deve ser exclusivo em todas as contas da AWS .
-
Uma pasta de saída deve estar vazia.
Preparação de uma aplicação com dados de entrada para o Amazon EMR
A maneira mais comum de preparar uma aplicação para o Amazon EMR é fazer o upload da aplicação e de seus dados de entrada para o Amazon S3. Em seguida, ao enviar o trabalho para o cluster, você especifica os locais do Amazon S3 para o script e para os dados.
Nesta etapa, você carrega um PySpark script de amostra no seu bucket do Amazon S3. Fornecemos um PySpark script para você usar. O script processa os dados de inspeção de estabelecimentos alimentícios e retorna um arquivo de resultados em seu bucket do S3. O arquivo de resultados lista os dez principais estabelecimentos com mais violações do tipo “vermelho”.
Você também carrega dados de entrada de amostra para o Amazon S3 para que o PySpark script seja processado. Os dados de entrada correspondem a uma versão modificada dos resultados de inspeções do Departamento de Saúde no Condado de King, em Washington, de 2006 a 2020. Para obter mais informações, consulte King County Open Data: Food Establishment Inspection Data
name,inspection_result,inspection_closed_business,violation_type,violation_points 100 LB CLAM,Unsatisfactory,FALSE,BLUE,5 100 PERCENT NUTRICION,Unsatisfactory,FALSE,BLUE,5 7-ELEVEN #2361-39423A,Complete,FALSE,,0
Para preparar o PySpark script de exemplo para o EMR
-
Copie o código de exemplo abaixo em um novo arquivo no editor de sua preferência.
import argparse from pyspark.sql import SparkSession def calculate_red_violations(data_source, output_uri): """ Processes sample food establishment inspection data and queries the data to find the top 10 establishments with the most Red violations from 2006 to 2020. :param data_source: The URI of your food establishment data CSV, such as 's3://amzn-s3-demo-bucket/food-establishment-data.csv'. :param output_uri: The URI where output is written, such as 's3://amzn-s3-demo-bucket/restaurant_violation_results'. """ with SparkSession.builder.appName("Calculate Red Health Violations").getOrCreate() as spark: # Load the restaurant violation CSV data if data_source is not None: restaurants_df = spark.read.option("header", "true").csv(data_source) # Create an in-memory DataFrame to query restaurants_df.createOrReplaceTempView("restaurant_violations") # Create a DataFrame of the top 10 restaurants with the most Red violations top_red_violation_restaurants = spark.sql("""SELECT name, count(*) AS total_red_violations FROM restaurant_violations WHERE violation_type = 'RED' GROUP BY name ORDER BY total_red_violations DESC LIMIT 10""") # Write the results to the specified output URI top_red_violation_restaurants.write.option("header", "true").mode("overwrite").csv(output_uri) if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument( '--data_source', help="The URI for you CSV restaurant data, like an S3 bucket location.") parser.add_argument( '--output_uri', help="The URI where output is saved, like an S3 bucket location.") args = parser.parse_args() calculate_red_violations(args.data_source, args.output_uri) -
Salve o arquivo como
health_violations.py. -
Faça o upload de
health_violations.pypara o Amazon S3 no bucket criado para este tutorial. Para obter instruções, consulte Fazer upload de um objeto para o bucket no Guia de conceitos básicos do Amazon Simple Storage Service.
Preparar os dados de entrada de exemplo para o EMR
-
Faça o download do arquivo zip food_establishment_data.zip.
-
Descompacte e salve
food_establishment_data.zipcomofood_establishment_data.csvem sua máquina. -
Faça o upload do arquivo CSV para o bucket do S3 criado para este tutorial. Para obter instruções, consulte Fazer upload de um objeto para o bucket no Guia de conceitos básicos do Amazon Simple Storage Service.
Para obter mais informações sobre como configurar dados para o EMR, consulte Preparo dos dados de entrada para processamento com o Amazon EMR.
Inicialização de um cluster do Amazon EMR
Após preparar um local de armazenamento e a aplicação, você poderá iniciar um cluster do Amazon EMR de exemplo. Nesta etapa, você inicia um cluster do Apache Spark usando a versão mais recente do Amazon EMR.
Etapa 2: enviar o trabalho ao cluster do Amazon EMR
Enviar o trabalho e exibir os resultados
Após iniciar um cluster, você poderá enviar trabalhos ao cluster em execução para processar e analisar dados. Você envia os trabalhos para um cluster do Amazon EMR como uma etapa. Uma etapa é uma unidade de trabalho composta por uma ou mais ações. Por exemplo, você pode enviar uma etapa para calcular valores ou para transferir e processar dados. É possível enviar etapas ao criar um cluster ou para um cluster em execução. Nesta parte do tutorial, você envia health_violations.py como uma etapa para o cluster em execução. Para saber mais sobre as etapas, consulte Envio de trabalhos para um cluster do Amazon EMR.
Para obter mais informações sobre o ciclo de vida da etapa, consulte Execução de etapas para processar dados.
Visualização dos resultados
Após a execução com êxito de uma etapa, você poderá visualizar os resultados de saída na pasta de saída do Amazon S3.
Visualizar os resultados de health_violations.py
Abra o console do Amazon S3 em https://console.aws.amazon.com/s3/
. -
Escolha o nome do bucket e, em seguida, a pasta de saída que você especificou ao enviar a etapa. Por exemplo,
amzn-s3-demo-buckete depoismyOutputFolder. -
Verifique se os seguintes itens aparecem na sua pasta de saída:
-
Um objeto de tamanho pequeno chamado
_SUCCESS. -
Um arquivo CSV que começa com o prefixo
part-, que contém seus resultados.
-
-
Escolha o objeto com seus resultados e, em seguida, escolha Fazer download para salvar os resultados em seu sistema de arquivos local.
-
Abra os resultados no editor de sua preferência. O arquivo de saída lista os dez principais estabelecimentos de alimentação com o maior número de violações vermelhas. O arquivo de saída também mostra o número total de violações vermelhas para cada estabelecimento.
Confira a seguir um exemplo de resultados para
health_violations.py.name, total_red_violations SUBWAY, 322 T-MOBILE PARK, 315 WHOLE FOODS MARKET, 299 PCC COMMUNITY MARKETS, 251 TACO TIME, 240 MCDONALD'S, 177 THAI GINGER, 153 SAFEWAY INC #1508, 143 TAQUERIA EL RINCONSITO, 134 HIMITSU TERIYAKI, 128
Para obter mais informações sobre a saída do cluster do Amazon EMR, consulte Configurar um local para a saída do cluster do Amazon EMR.
Ao usar o Amazon EMR, você pode desejar se conectar a um cluster em execução para ler arquivos de log, depurar o cluster ou usar ferramentas da CLI, como o shell do Spark. O Amazon EMR permite que você se conecte a um cluster usando o protocolo Secure Shell (SSH). Esta seção abrange como configurar o SSH, conectar-se ao cluster e visualizar arquivos de log do Spark. Para obter mais informações sobre como se conectar a um cluster, consulte Autenticação em nós de cluster do Amazon EMR.
Autorização de conexões SSH para o cluster
Antes de se conectar ao cluster, é necessário modificar os grupos de segurança do cluster para autorizar conexões SSH de entrada. Os grupos EC2 de segurança da Amazon atuam como firewalls virtuais para controlar o tráfego de entrada e saída do seu cluster. Quando você criou o cluster para este tutorial, o Amazon EMR criou os seguintes grupos de segurança em seu nome:
- ElasticMapReduce-mestre
-
O grupo de segurança gerenciado padrão do Amazon EMR associado ao nó primário. Em um cluster do Amazon EMR, o nó principal é uma EC2 instância da Amazon que gerencia o cluster.
- ElasticMapReduce-escravo
-
O grupo de segurança padrão associado aos nós centrais e de tarefa.
Conecte-se ao seu cluster usando o AWS CLI
Independentemente do seu sistema operacional, é possível criar uma conexão SSH com o cluster usando a AWS CLI.
Para se conectar ao seu cluster e visualizar os arquivos de log usando o AWS CLI
-
Use o comando a seguir para abrir uma conexão SSH com o cluster.
<mykeypair.key>Substitua pelo caminho completo e pelo nome do arquivo do seu arquivo de key pair. Por exemplo, .C:\Users\<username>\.ssh\mykeypair.pemaws emr ssh --cluster-id<j-2AL4XXXXXX5T9>--key-pair-file<~/mykeypair.key> -
Navegue até
/mnt/var/log/sparkpara acessar os logs do Spark no nó principal do cluster. Em seguida, visualize os arquivos nesse local. Para obter uma lista de arquivos de log adicionais no nó principal, consulte Visualizar arquivos de log no nó primário.cd /mnt/var/log/spark ls
O Amazon EMR on também EC2 é um tipo de computação compatível com o Unified Studio. Amazon SageMaker AI Consulte Gerenciando o Amazon EMR em EC2 para saber como usar e gerenciar o EMR em EC2 recursos no Unified Studio. Amazon SageMaker AI
Etapa 3: limpar os recursos do Amazon EMR
Encerramento do cluster
Agora que você enviou o trabalho para seu cluster e visualizou os resultados do seu PySpark aplicativo, você pode encerrar o cluster. O encerramento de um cluster interrompe todas as cobranças do Amazon EMR e instâncias da Amazon associadas ao cluster. EC2
Ao encerrar um cluster, o Amazon EMR retém os metadados relacionados ao cluster por dois meses gratuitamente. Os metadados arquivados ajudam a clonar o cluster para um novo trabalho ou a revisitar a configuração do cluster para finalidades de referência. Os metadados não incluem os dados que o cluster grava no S3 ou os dados armazenados no HDFS no cluster.
nota
O console do Amazon EMR não permite que você exclua um cluster da visualização de lista após o encerramento do cluster. Um cluster encerrado desaparecerá do console quando o Amazon EMR limpar os metadados.
Exclusão de recursos do S3
Para evitar cobranças adicionais, você deve excluir o bucket do Amazon S3. Excluir o bucket remove todos os recursos do Amazon S3 deste tutorial. O bucket deve conter:
-
O PySpark roteiro
-
O conjunto de dados de entrada.
-
Sua pasta de resultados de saída.
-
Sua pasta de arquivos de log.
Talvez seja necessário tomar medidas adicionais para excluir os arquivos armazenados se você salvou o PySpark script ou a saída em um local diferente.
nota
O cluster deve ser encerrado antes de você excluir o bucket. Caso contrário, pode não ser possível esvaziar o bucket.
Para excluir seu bucket, siga as instruções apresentadas em How do I delete an S3 bucket? no Guia do usuário do Amazon Simple Storage Service.
Próximas etapas
Você iniciou seu primeiro cluster do Amazon EMR do início ao fim. Você também concluiu tarefas essenciais do EMR, como preparar e enviar aplicações de big data, visualizar os resultados e encerrar um cluster.
Use os tópicos apresentados a seguir para saber mais sobre como personalizar seu fluxo de trabalho do Amazon EMR.
Exploração de aplicações de big data para o Amazon EMR
Descubra e compare as aplicações de big data que podem ser instaladas em um cluster no Guia de versão do Amazon EMR. O guia de lançamento detalha cada versão lançada do EMR e inclui dicas para usar estruturas como o Spark e o Hadoop no Amazon EMR.
Planejamento do hardware, das redes e da segurança do cluster
Neste tutorial, você criou um cluster do EMR simples, sem configurar as opções avançadas. As opções avançadas permitem que você especifique os tipos de EC2 instância, a rede e a segurança do cluster da Amazon. Para obter mais informações sobre como planejar e iniciar um cluster que atenda aos seus requisitos, consulte Planejamento, configuração e inicialização de clusters do Amazon EMR e Segurança no Amazon EMR.
Gerenciar clusters
Aprofunde-se no trabalho com clusters em execução em Gerenciamento de clusters do Amazon EMR. Para gerenciar um cluster, é possível se conectar ao cluster, depurar etapas e rastrear as atividades e a integridade do cluster. Você também pode ajustar os recursos do cluster em resposta às demandas da workload com o ajuste de escala gerenciado do EMR.
Uso de uma interface diferente
Além do console do Amazon EMR, você pode gerenciar o Amazon EMR usando a API do AWS Command Line Interface serviço web ou uma das muitas suportadas. AWS SDKs Para obter mais informações, consulte Interfaces de gerenciamento.
Você também pode interagir com aplicações instaladas em clusters do Amazon EMR de diversas maneiras. Algumas aplicações, como o Apache Hadoop, publicam interfaces da Web que você pode visualizar. Para obter mais informações, consulte Visualizar interfaces Web hospedadas em clusters do Amazon EMR.
Navegação pelo blog técnico do EMR
Para obter exemplos de orientações e discussões técnicas aprofundadas sobre os novos recursos do Amazon EMR, consulte o blog de big data da AWS
