Rastreando um armazenamento de dados do Amazon S3 usando um endpoint VPC
Para fins de segurança, auditoria ou controle, você pode querer que seu armazenamento de dados Amazon S3 ou tabelas do Catálogo de Dados com suporte do Amazon S3 sejam acessadas somente por meio de um ambiente Amazon Virtual Private Cloud (Amazon). VPC Este tópico descreve como criar e testar uma conexão com o armazenamento de dados do Amazon S3 ou tabelas do catálogo de dados com suporte do Amazon S3 em VPC um endpoint usando o tipo de conexão. Network
Realize as seguintes tarefas para executar um crawler no armazenamento de dados:
Pré-requisitos
Verifique se você atendeu a esses pré-requisitos para configurar seu armazenamento de dados Amazon S3 ou tabelas do Catálogo de Dados com suporte do Amazon S3 para serem acessadas por meio de um ambiente Amazon Virtual Private Cloud (Amazon). VPC
-
Um configuradoVPC. Por exemplo: vpc-01685961063b0d84b. Para obter mais informações, consulte Introdução à Amazon VPC no Guia do VPC usuário da Amazon.
-
Um endpoint Amazon S3 conectado ao. VPC Por exemplo: vpc-01685961063b0d84b. Para obter mais informações, consulte Endpoints para Amazon S3 no Guia do usuário da VPCAmazon.

-
Uma entrada de rota apontando para o VPC ponto final. Por exemplo, vpce-0ec5da4d265227786 na tabela de rotas usada pelo endpoint (vpce-0ec5da4d265227786). VPC
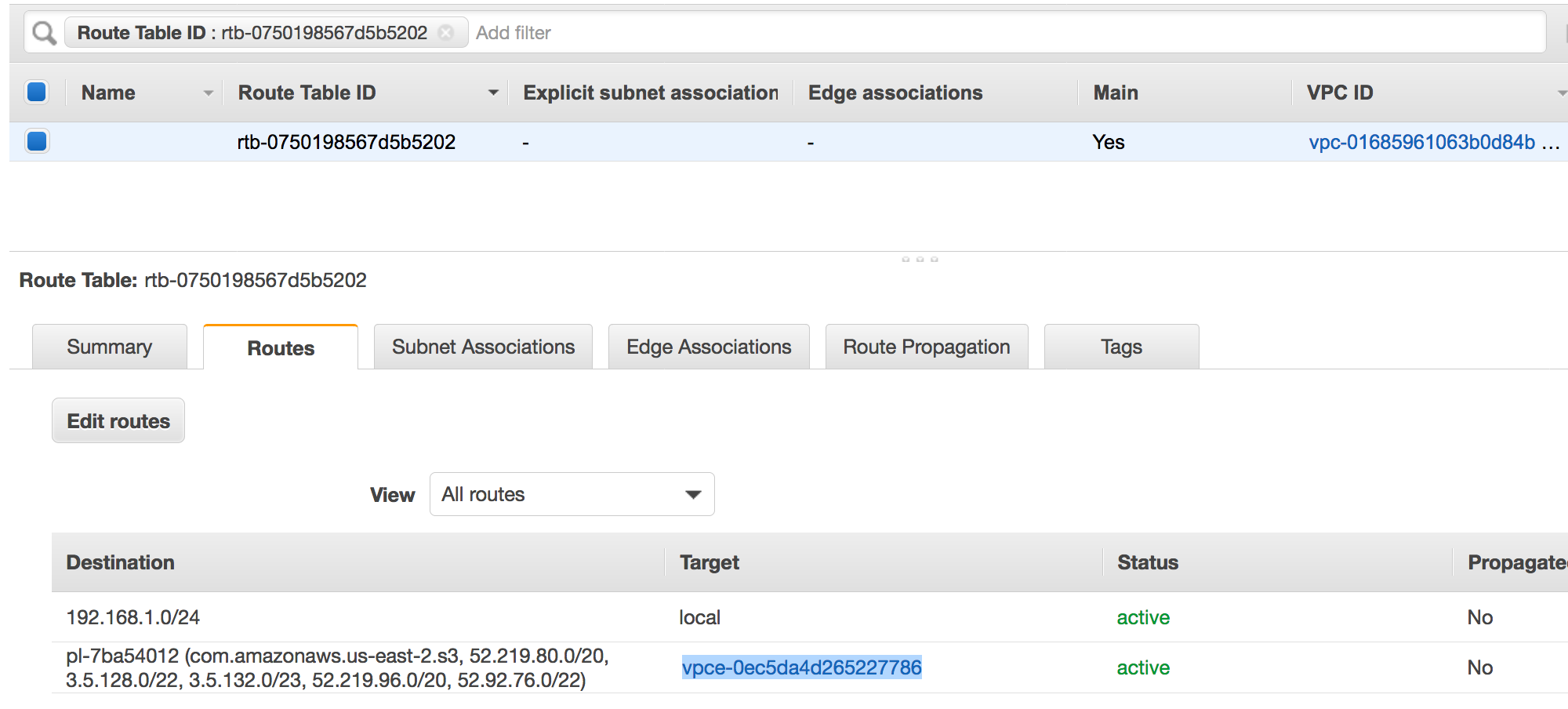
-
Uma rede ACL conectada ao VPC permite o tráfego.
-
Um grupo de segurança anexado ao VPC permite o tráfego.
Criar a conexão com o Amazon S3
Normalmente, você cria recursos dentro da Amazon Virtual Private Cloud (AmazonVPC) para que eles não possam ser acessados pela Internet pública. Por padrão, não é AWS Glue possível acessar recursos dentro de umVPC. AWS Glue Para permitir o acesso a recursos dentro do seuVPC, você deve fornecer informações adicionais de configuração VPC específicas que incluam VPC sub-rede IDs e grupo de segurança. IDs Para criar uma conexão Network, você precisa especificar as seguintes informações:
-
UMA VPC IDENTIFICAÇÃO
-
Uma sub-rede dentro do VPC
-
Um grupo de segurança
Para configurar uma conexão Network:
-
Escolha Add connection (Adicionar conexão) no painel de navegação do console do AWS Glue .
-
Insira o nome da conexão e escolha Network (Rede) como o tipo de conexão. Escolha Próximo.
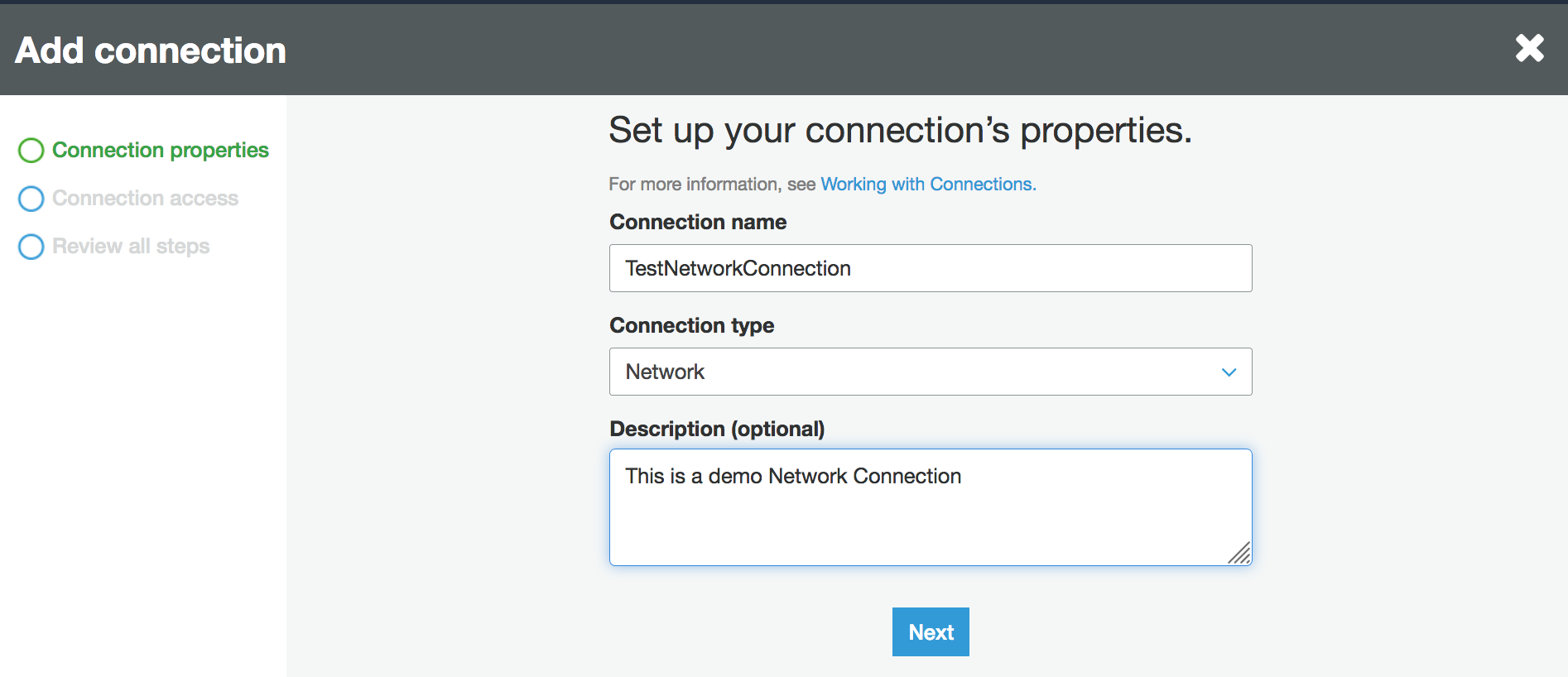
-
Configure as VPC informações dos grupos de sub-rede e segurança.
-
VPC: escolha o VPC nome que contém seu armazenamento de dados.
-
Sub-rede: escolha a sub-rede dentro da sua. VPC
-
Grupos de segurança: escolha um ou mais grupos de segurança que permitam acesso ao armazenamento de dados em seuVPC.
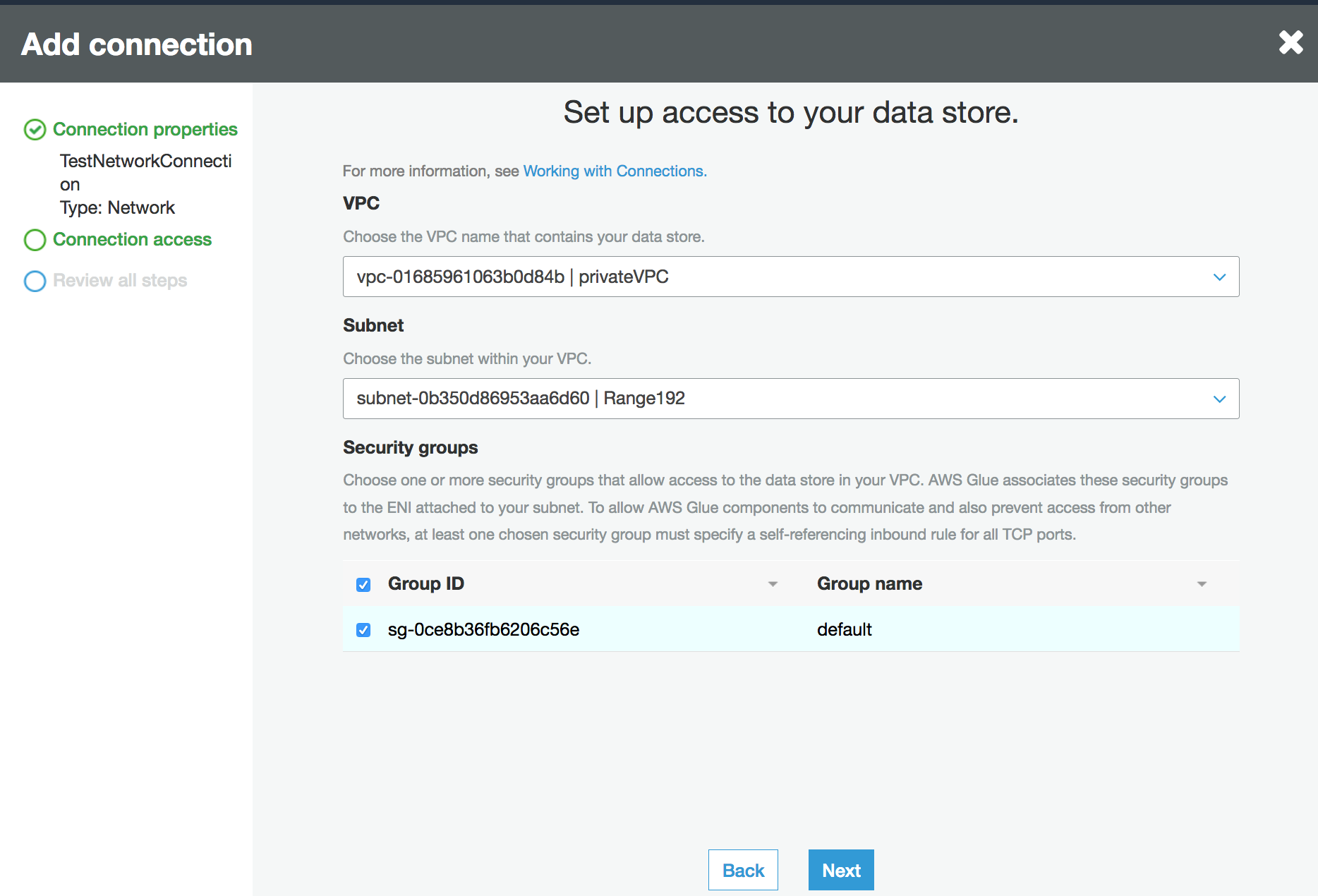
-
-
Escolha Próximo.
-
Verifique as informações de conexão e escolha Finish (Encerrar).
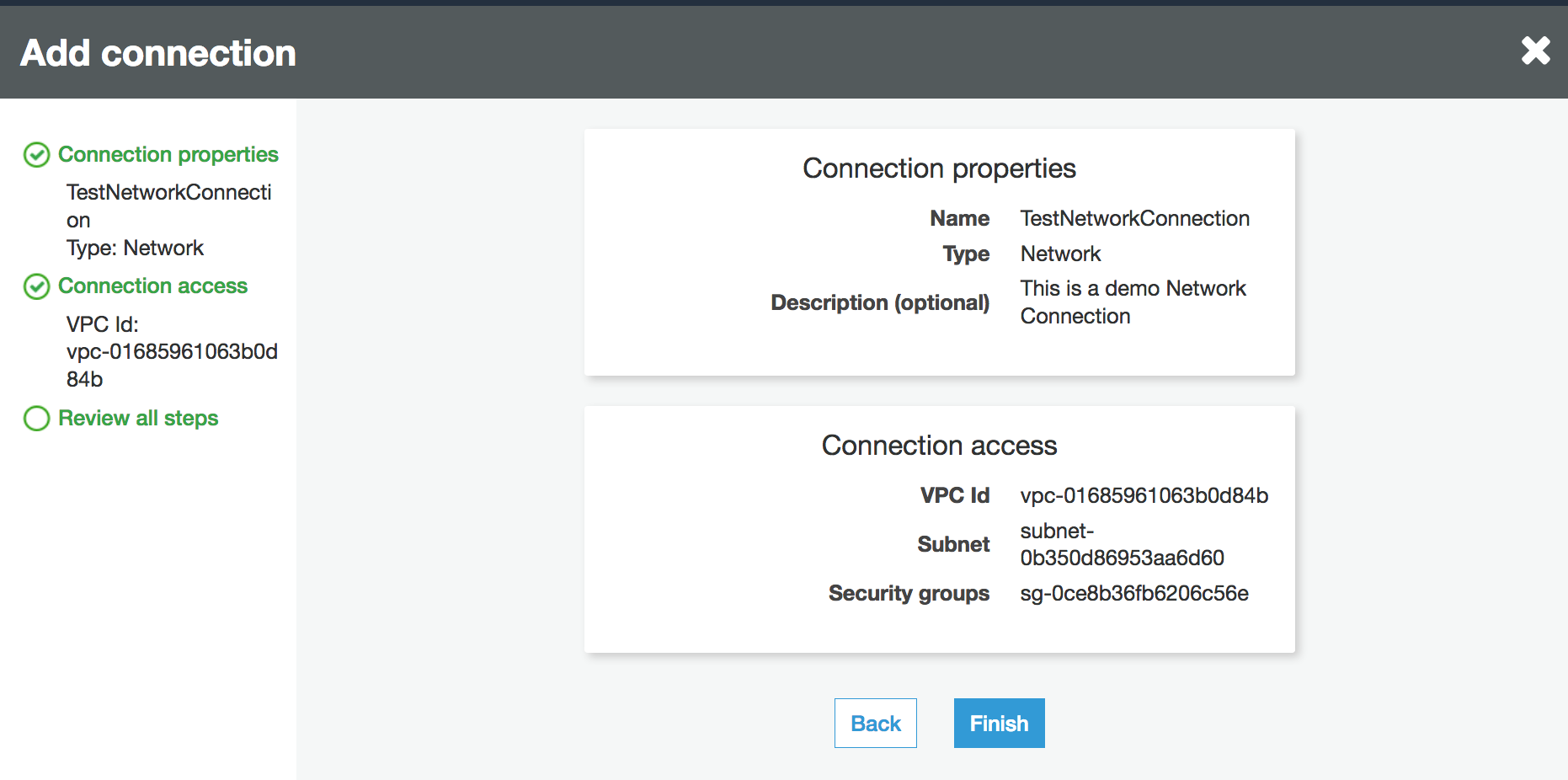
Testar a conexão com o Amazon S3
Depois de criar sua Network conexão, você pode testar a conectividade com seu armazenamento de dados do Amazon S3 em um VPC endpoint.
Os seguintes erros podem ocorrer ao testar uma conexão:
-
INTERNETCONNECTIONERROR: indica um problema de conexão com a Internet
-
INVALIDBUCKETERROR: indica um problema com o bucket do Amazon S3
-
S3 CONNECTIONERROR: indica uma falha na conexão com o Amazon S3
-
INVALIDCONNECTIONTYPE: indica que o tipo de conexão não tem o valor esperado,
NETWORK -
INVALIDCONNECTIONTESTTYPE: indica um problema com o tipo de teste de conexão de rede
-
INVALIDTARGET: indica que o bucket do Amazon S3 não foi especificado corretamente
Para testar uma conexão Network:
-
Selecione a conexão Network (Rede) no console do AWS Glue .
-
Selecione Test connection (Testar conexão).
-
Escolha a IAM função que você criou na etapa anterior e especifique um bucket do Amazon S3.
-
Escolha Test connection (Testar conexão) para iniciar o teste. Pode levar algum tempo para que o resultado seja exibido.
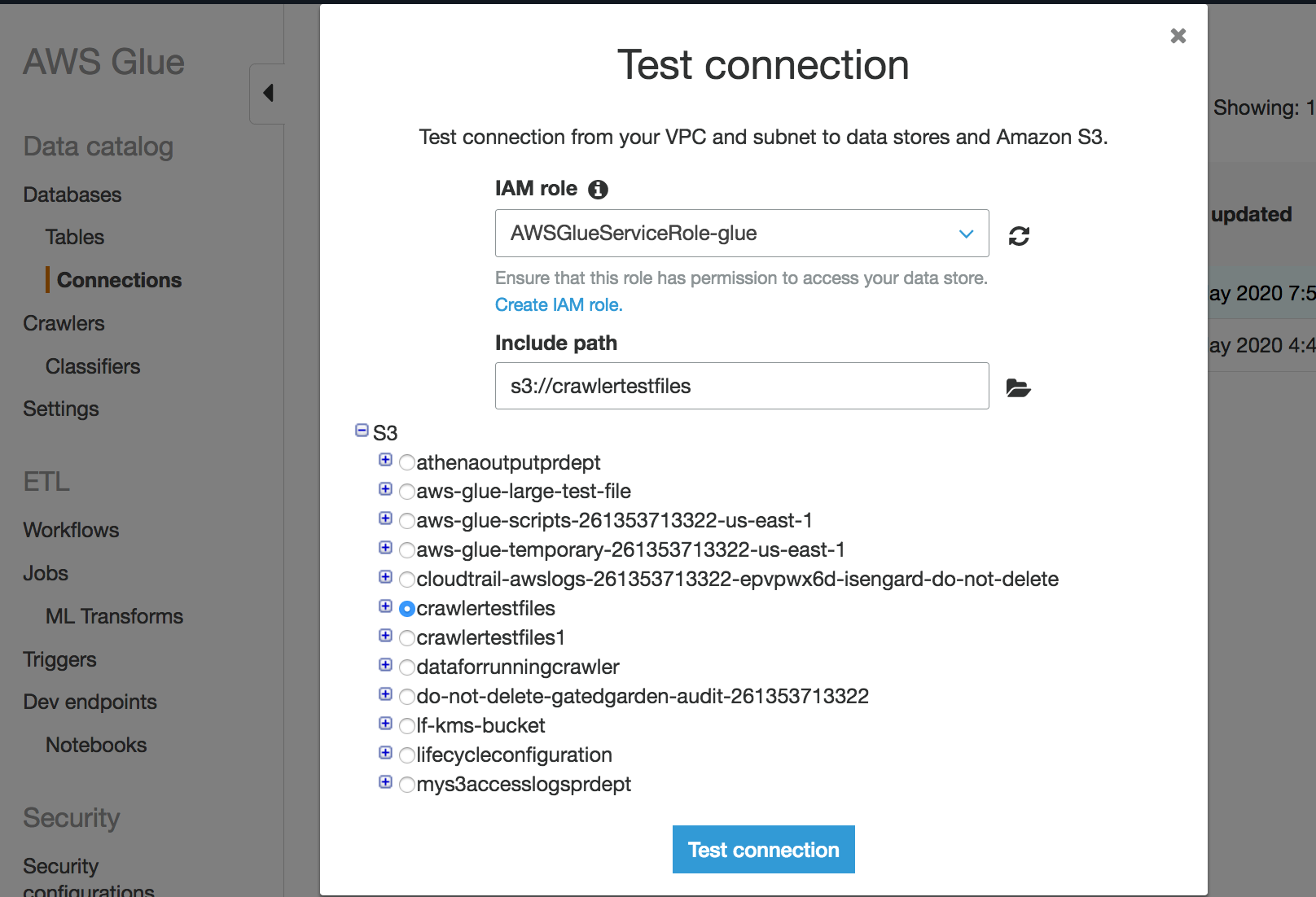
Se você receber um erro, faça o seguinte:
-
Os privilégios corretos foram fornecidos para a função selecionada.
-
O bucket do Amazon S3 correto foi fornecido.
-
Os grupos de segurança e a rede ACL permitem o tráfego de entrada e saída necessário.
-
O VPC que você especificou está conectado a um endpoint do Amazon S3VPC.
Após ter testado com êxito a conexão, você pode criar um crawler.
Criar um crawler para um armazenamento de dados do Amazon S3
Agora é possível criar um crawler que especifica a conexão Network que você criou. Para obter mais detalhes sobre como criar um crawler, consulte Configurar um crawler.
-
Comece escolhendo Crawlers no painel de navegação do console. AWS Glue
-
Escolha Adicionar crawler.
-
Especifique o nome do crawler e escolha Next (Próximo).
-
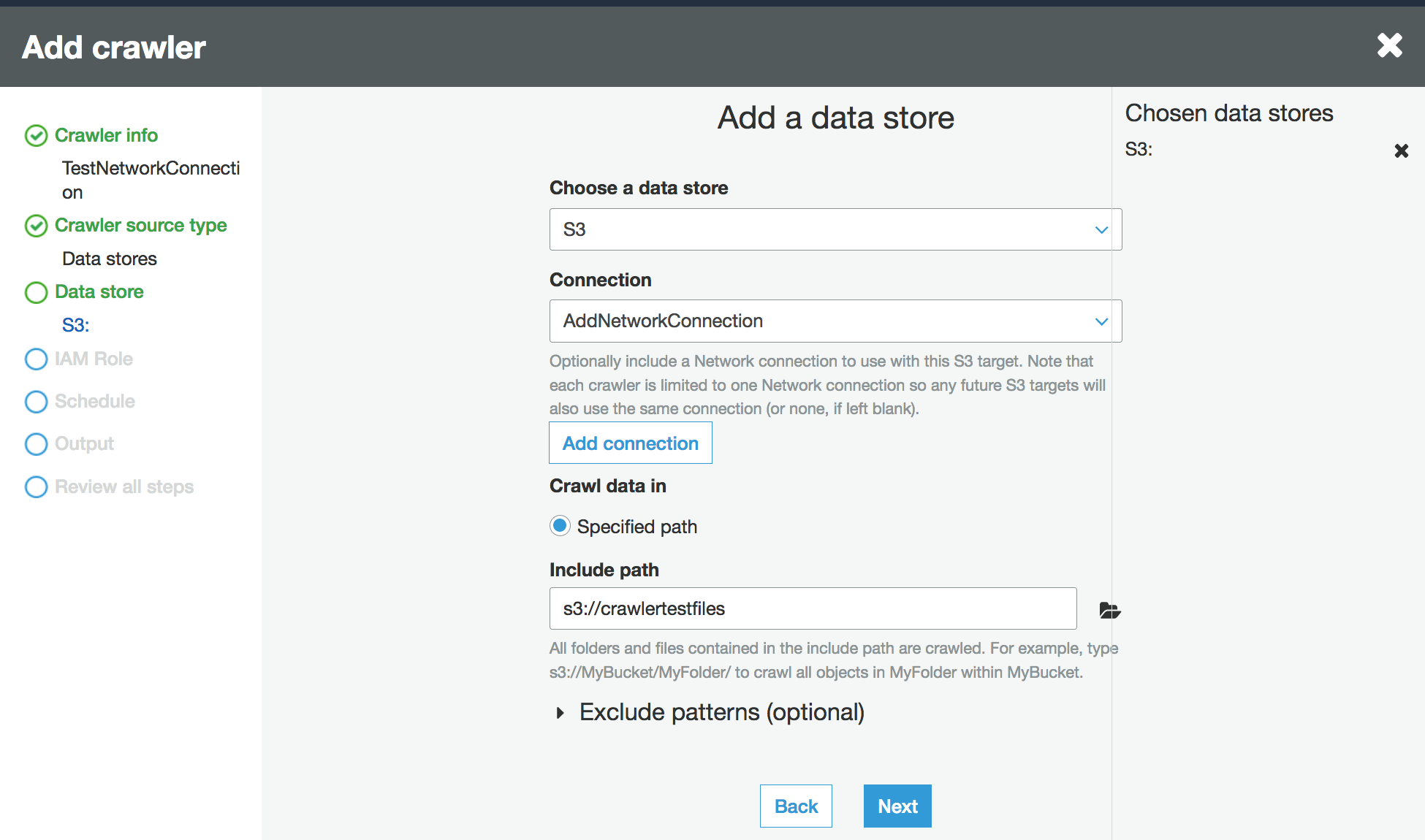
Quando a origem dos dados for solicitada, escolha S3 e especifique o prefixo do bucket do Amazon S3 e a conexão criada anteriormente.
-
Se precisar, adicione outro armazenamento de dados na mesma conexão de rede.
-
Escolha a IAM função. A IAM função deve permitir o acesso ao AWS Glue serviço e ao bucket do Amazon S3. Para obter mais informações, consulte Configurar um crawler.

-
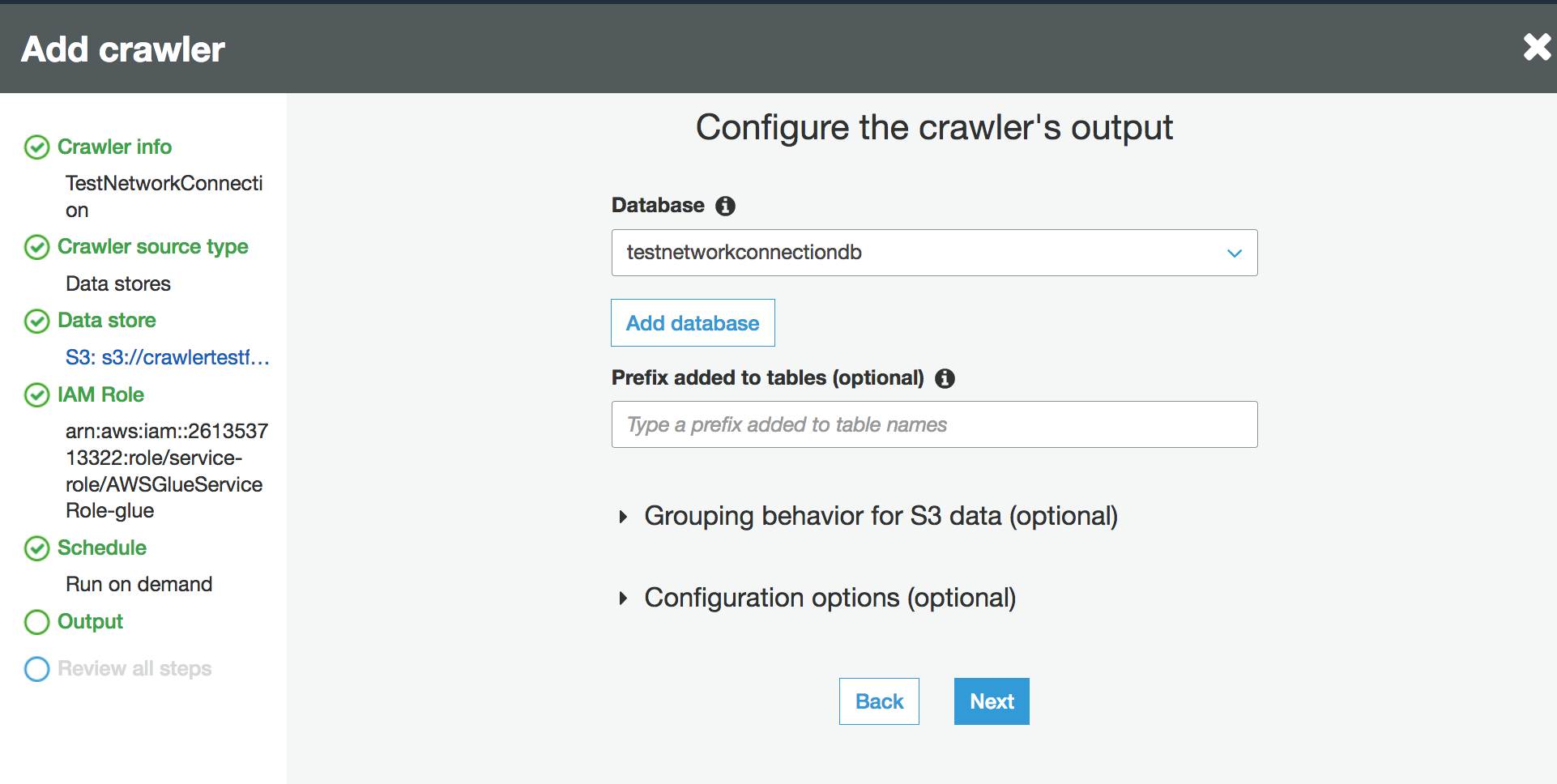
Defina a programação do crawler.
-
Escolha um banco de dados existente no Data Catalog ou crie uma nova entrada de banco de dados.
-
Conclua a configuração restante.
Criação de um crawler para tabelas de catálogo de dados baseadas no Amazon S3
Agora é possível criar um crawler que especifica a conexão de Network que você criou e um tipo de fonte de catálogo. Para obter mais detalhes sobre como criar um crawler, consulte Configurar um crawler.
-
Comece escolhendo Crawlers no painel de navegação do console. AWS Glue
-
Escolha Adicionar crawler.
-
Especifique o nome do crawler e escolha Next (Próximo).
-
Quando o tipo de fonte do crawler for solicitado, escolha Existing catalog tables (Tabelas de catálogo existentes) e especifique as tabelas de catálogo existentes para crawling na lista de tabelas disponíveis.
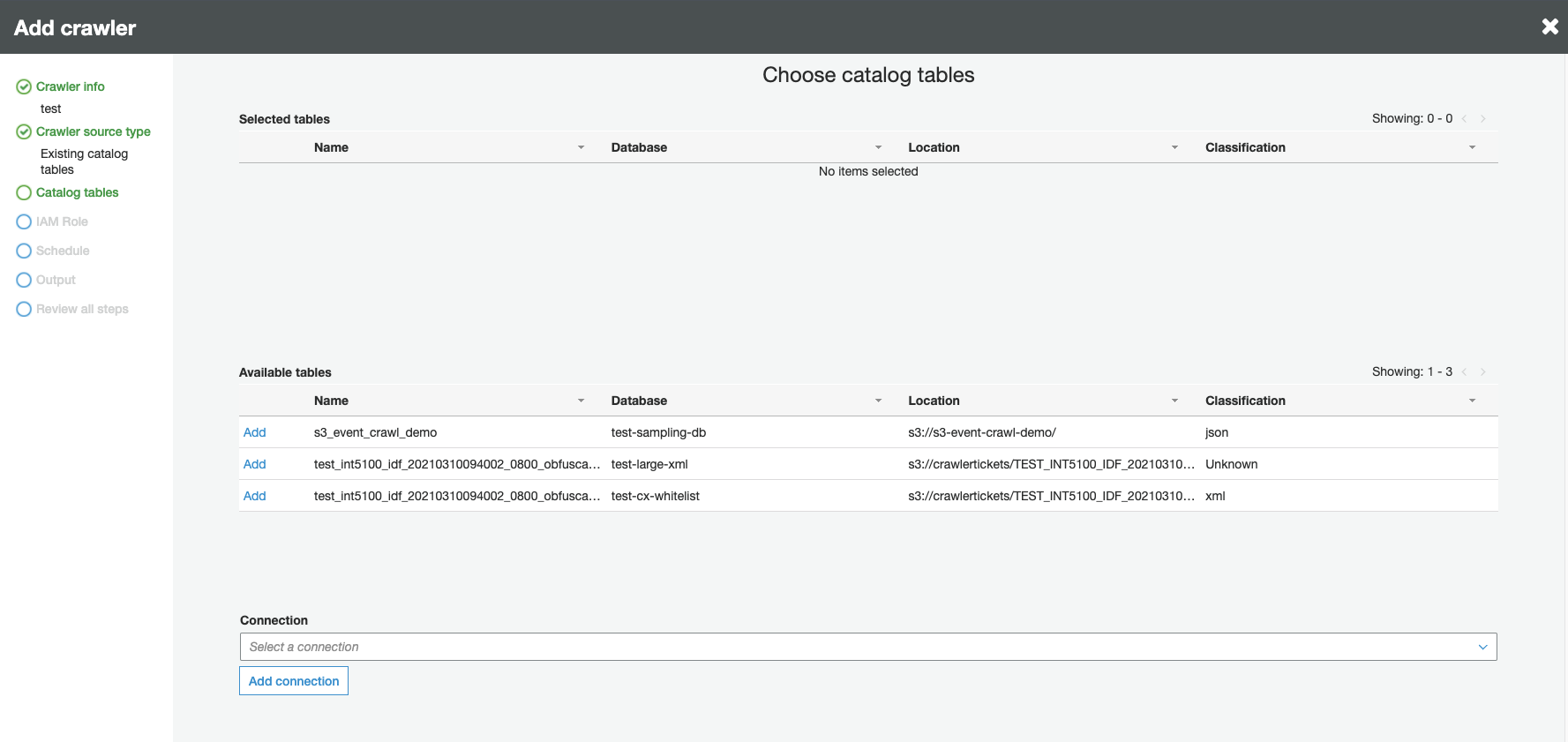
-
Escolha a IAM função. A IAM função deve permitir o acesso ao AWS Glue serviço e ao bucket do Amazon S3. Para obter mais informações, consulte Configurar um crawler.
-
Defina a programação do crawler.
-
Escolha um banco de dados existente no Data Catalog ou crie uma nova entrada de banco de dados.
-
Conclua a configuração restante e revise suas etapas.

Executar um crawler
Execute seu crawler.

Solução de problemas
Para solucionar problemas relacionados aos buckets do Amazon S3 usando um VPC gateway, consulte Por que não consigo me conectar a um bucket do S3 usando um endpoint de
