Adicionar uma conexão JDBC usando seus próprios drivers JDBC
Você pode usar seu próprio driver JDBC quando usar uma conexão JDBC. Quando o driver padrão utilizado pelo crawler do AWS Glue não consegue se conectar a um banco de dados, você pode usar seu próprio driver JDBC. Por exemplo, se quiser usar o SHA-256 com seu banco de dados Postgres e os drivers postgres mais antigos não forem compatíveis, você poderá usar seu próprio driver JDBC.
Fontes de dados compatíveis
| Fontes de dados compatíveis | Fontes de dados não compatíveis |
|---|---|
| MySQL | Snowflake |
| Postgres | |
| Oracle | |
| Redshift | |
| SQL Server | |
| Aurora* |
*Compatível se o driver JDBC nativo estiver sendo usado. Nem todos os recursos do driver podem ser aproveitados.
Adicionar um driver JDBC a uma conexão JDBC
nota
Se você optar por trazer suas próprias versões do driver JDBC, os crawlers do AWS Glue consumirão recursos em trabalhos do AWS Glue e buckets do Amazon S3 para garantir que o driver fornecido seja executado em seu ambiente. O uso adicional de recursos será refletido em sua conta. O custo dos crawlers e trabalhos do AWS Glue se enquadram na categoria do AWS Glue para cobrança. Além disso, fornecer seu próprio driver JDBC não significa que o crawler seja capaz de aproveitar todos os atributos do driver.
Para adicionar uma conexão JDBC a uma conexão JDBC:
-
Adicione o arquivo do driver JDBC a um local do Amazon S3. Você pode criar um bucket e/ou uma pasta ou usar os já existentes.
-
No console do AWS Glue, escolha Conexões no menu à esquerda em Catálogo de dados e crie uma nova conexão.
-
Preencha os campos para Propriedades da conexão e escolha JDBC como Tipo de conexão.
-
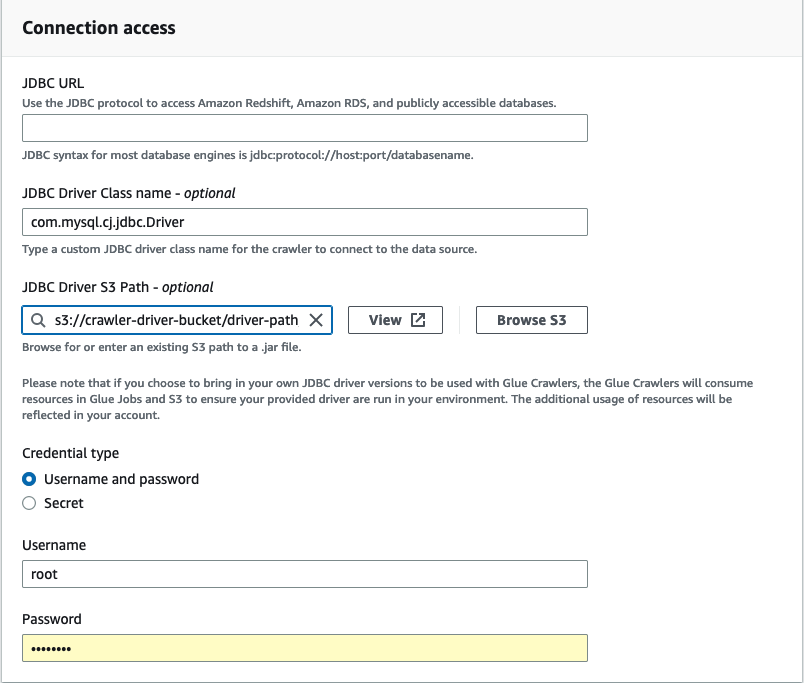
Em Acesso à conexão, insira a URL do JDBC e o Nome da classe do driver JDBC, opcional. O nome da classe do driver deve ser para uma fonte de dados compatível com os crawlers do AWS Glue.
-
Escolha o caminho do Amazon S3 em que o driver JDBC está localizado em Caminho do Amazon S3 do driver JDBC, campo opcional.
-
Preencha os campos de Tipo de credencial se estiver inserindo um nome de usuário e senha ou segredo. Ao concluir, escolha Criar conexão.
nota
O teste de conexão não é compatível atualmente. Ao fazer crawling na fonte de dados com um driver JDBC que você forneceu, o crawler pula essa etapa.
-
Adicione a conexão recém-criada a um crawler. No console do AWS Glue, escolha Crawlers no menu esquerdo em Catálogo de dados e crie um novo crawler.
-
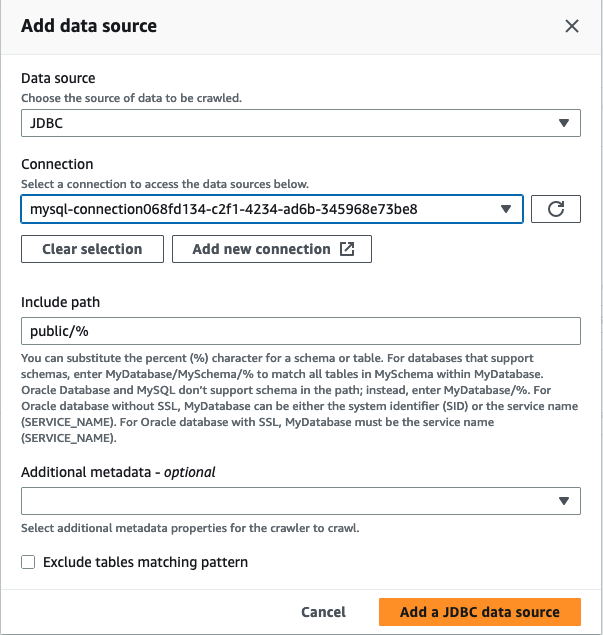
No assistente Adicionar crawler, na etapa 2, escolha Adicionar uma fonte de dados.
-
Escolha JDBC como fonte de dados e escolha a conexão que foi criada nas etapas anteriores. Concluído
-
Para usar seu próprio driver JDBC com um crawler do AWS Glue, adicione as seguintes permissões ao perfil usado pelo crawler:
-
Conceda permissões para as seguintes ações:
CreateJob,DeleteJob,GetJob,GetJobRun,StartJobRun. -
Conceda permissões para as ações do IAM:
iam:PassRole -
Conceda permissões para as ações do Amazon S3:
s3:DeleteObjects,s3:GetObject,s3:ListBucket,s3:PutObject. -
Conceda acesso de entidade principal de serviço a bucket/pasta na política do IAM.
Exemplo de política do IAM:
O crawler do AWS Glue cria duas pastas: _glue_job_crawler e _crawler.
Se o arquivo jar do driver estiver localizado na pasta
s3://amzn-s3-demo-bucket/driver.jar", adicione os seguintes recursos:"Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket/_glue_job_crawler/*", "arn:aws:s3:::amzn-s3-demo-bucket/_crawler/*" ]Se o arquivo jar do driver estiver localizado na pasta
s3://amzn-s3-demo-bucket/tmp/driver/subfolder/driver.jar", adicione os seguintes recursos:"Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket/tmp/_glue_job_crawler/*", "arn:aws:s3:::amzn-s3-demo-bucket/tmp/_crawler/*" ] -
-
Se você estiver usando uma VPC, deverá permitir o acesso ao endpoint do AWS Glue criando o endpoint de interface e adicionando-o à sua tabela de rotas. Para obter mais informações, consulte Creating an interface VPC endpoint for AWS Glue
-
Ao usar a criptografia no catálogo de dados, crie o endpoint de interface do AWS KMS e adicione-o à tabela de rotas. Para obter mais informações, consulte Creating a VPC endpoint for AWS KMS.
