Trabalhar com tabelas no console do AWS Glue
Uma tabela no AWS Glue Data Catalog é a definição de metadados que representa os dados em um datastore. Você cria tabelas quando executa um crawler ou manualmente no console do AWS Glue. A lista Tables (Tabelas) no console do AWS Glue exibe valores dos metadados da sua tabela. Você usa definições de tabela para especificar fontes e destino ao criar trabalhos de ETL (extração, transformação e carregamento).
nota
Com as mudanças recentes no console de gerenciamento da AWS, pode ser necessário modificar os perfis do IAM existentes para que tenham a permissão de SearchTables. Para a criação de um novo perfil, a permissão da API SearchTables já foi adicionada como padrão.
Para começar, faça login no AWS Management Console e abra o console do AWS Glue em https://console.aws.amazon.com/glue/
Adicionar tabelas ao console
Para usar um crawler para adicionar tabelas, escolha Add tables, Add tables using a crawler. Em seguida, siga as instruções no assistente Add crawler. Quando o crawler for executado, as tabelas serão adicionadas ao AWS Glue Data Catalog. Para ter mais informações, consulte Definir crawlers no AWS Glue.
Se você conhecer os atributos necessários para criar uma definição de tabela do Amazon Simple Storage Service (Amazon S3) no Data Catalog, você poderá criá-la com o assistente de tabela. Escolha Add tables, Add table manually a siga as instruções no assistente Add table.
Ao adicionar uma tabela manualmente usando o console, considere o seguinte:
-
Se você planeja acessar a tabela a partir do Amazon Athena, forneça um nome somente com caracteres alfanuméricos e sublinhados. Para obter mais informações, consulte Nomes do Athena.
-
O local dos seus dados de origem deve ser um caminho do Amazon S3.
-
O formato dos dados deve corresponder a um dos formatos listados no assistente. A classificação correspondente, SerDe e outras propriedades da tabela serão preenchidas automaticamente com base no formato escolhido. Você pode definir tabelas com os seguintes formatos:
- Avro
-
Formato binário JSON do Apache Avro.
- CSV
-
Valores separados por vírgula (CSV). Você também especifica o delimitador como vírgula, pipe, ponto e vírgula, tabulação ou Ctrl+A.
- JSON
-
JavaScript Object Notation.
- XML
-
Formato Extensible Markup Language. Especifique a tag XML que define uma linha nos dados. As colunas são definidas nas tags de linha.
- Parquet
-
Armazenamento em colunas no Apache Parquet.
- ORC
-
Formato Optimized Row Columnar (ORC). Um formato criado para armazenar dados do Hive com eficiência.
-
Você pode definir uma chave de partição para a tabela.
-
Atualmente, as tabelas particionadas que você cria com o console não podem ser usadas em trabalhos de ETL.
Atributos da tabela
Veja a seguir alguns atributos importantes da sua tabela:
- Nome
-
O nome é determinado quando a tabela é criada, e você não pode alterá-la. Você faz referência a um nome de tabela em muitas operações do AWS Glue.
- Banco de dados
-
O objeto do contêiner onde a sua tabela reside. Este objeto contém uma organização das suas tabelas que existe dentro do AWS Glue Data Catalog e pode diferir de uma organização no seu datastore. Quando você exclui um banco de dados, todas as tabelas contidas nele também são excluídas do Data Catalog.
- Descrição
-
A descrição da tabela. Você pode escrever uma descrição para ajudá-lo a entender o conteúdo da tabela.
- Formato da tabela
-
Especifique a criação de uma tabela padrão do AWS Glue ou de uma tabela no formato do Apache Iceberg.
- Habilitar compactação
-
Escolha Habilitar compactação para compactar pequenos objetos do Amazon S3 na tabela em objetos maiores.
- IAM role (Perfil do IAM)
Para executar a compactação, o serviço assume um perfil do IAM em seu nome. Você pode escolher um perfil do IAM usando o menu suspenso. Certifique-se de que o perfil tenha as permissões necessárias para habilitar a compactação.
Para saber mais sobre as permissões necessárias para o perfil do IAM, consulte Pré-requisitos de otimização de tabelas .
- Local
-
O ponteiro para o local dos dados em um datastore que esta definição de tabela representa.
- Classificação
-
Um valor de categorização fornecido quando a tabela foi criada. Normalmente, ele é escrito quando um crawler é executado e especifica o formato dos dados da fonte.
- Última atualização
-
A hora e a data (UTC) em que esta tabela foi atualizada no Data Catalog.
- Data adicionada
-
A hora e a data (UTC) em que esta tabela foi adicionada ao Data Catalog.
- Preterido
-
Se o AWS Glue descobrir que uma tabela do Data Catalog não existe mais no seu datastore original, ele marcará essa tabela como defasada no catálogo de dados. Se você executar um trabalho que faz referência a uma tabela obsoleta, ele falhará. Edite trabalhos que fazem referência a tabelas obsoletas para removê-las como fontes e destinos. Recomendamos que você elimine tabelas obsoletas quando elas não forem mais necessárias.
- Conexão
-
Se o AWS Glue exigir conexão com seu datastore, o nome da conexão será associado à tabela.
Exibir e editar detalhes da tabela
Para ver os detalhes de uma tabela existente, escolha o nome dela na lista e, em seguida, Action, View details.
Esses detalhes incluem propriedades da sua tabela e do seu esquema. Essa exibição mostra o esquema da tabela, incluindo os nomes de colunas na ordem definida para a tabela, os tipos de dados e as colunas de chaves para partições. Se uma coluna for de um tipo complexo, você poderá escolher View properties para exibir detalhes da estrutura desse campo, como mostrado no exemplo a seguir:
{ "StorageDescriptor": { "cols": { "FieldSchema": [ { "name": "primary-1", "type": "CHAR", "comment": "" }, { "name": "second ", "type": "STRING", "comment": "" } ] }, "location": "s3://aws-logs-111122223333-us-east-1", "inputFormat": "", "outputFormat": "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat", "compressed": "false", "numBuckets": "0", "SerDeInfo": { "name": "", "serializationLib": "org.apache.hadoop.hive.serde2.OpenCSVSerde", "parameters": { "separatorChar": "|" } }, "bucketCols": [], "sortCols": [], "parameters": {}, "SkewedInfo": {}, "storedAsSubDirectories": "false" }, "parameters": { "classification": "csv" } }
Para obter mais informações sobre as propriedades de uma tabela, como StorageDescriptor, consulte Estrutura StorageDescriptor.
Para alterar o esquema de uma tabela, escolha Edit schema para adicionar e remover colunas, alterar nomes de colunas e alterar tipos de dados.
Para comparar diferentes versões de uma tabela, incluindo seu esquema, escolha Compare versions para ver uma comparação lado-a-lado de duas versões do esquema para uma tabela. Para ter mais informações, consulte Comparar versões de esquema de tabela .
Para exibir os arquivos que compõem uma partição do Amazon S3, escolha View partition (Visualizar partição). Para tabelas do Amazon S3, a coluna Key (Chave) exibe as teclas de partição usadas para particionar a tabela no datastore de origem. Particionar é uma maneira de separar uma tabela em partes relacionadas com base nos valores de uma coluna de chave, como data, local ou departamento. Para obter mais informações sobre partições, pesquise na Internet informações sobre "particionamento do Hive".
nota
Para obter orientação detalhada para visualizar os detalhes de uma tabela, consulte o tutorial Explore table no console.
Comparar versões de esquema de tabela
Ao comparar duas versões de esquema de tabela, você pode comparar alterações de linhas aninhadas expandindo-as e contraindo-as, comparar esquemas de duas versões lado a lado e visualizar as propriedades da tabela lado a lado.
Para comparar versões
-
No console do AWS Glue, escolha Tabelas, depois Ações e Comparar versões.
-
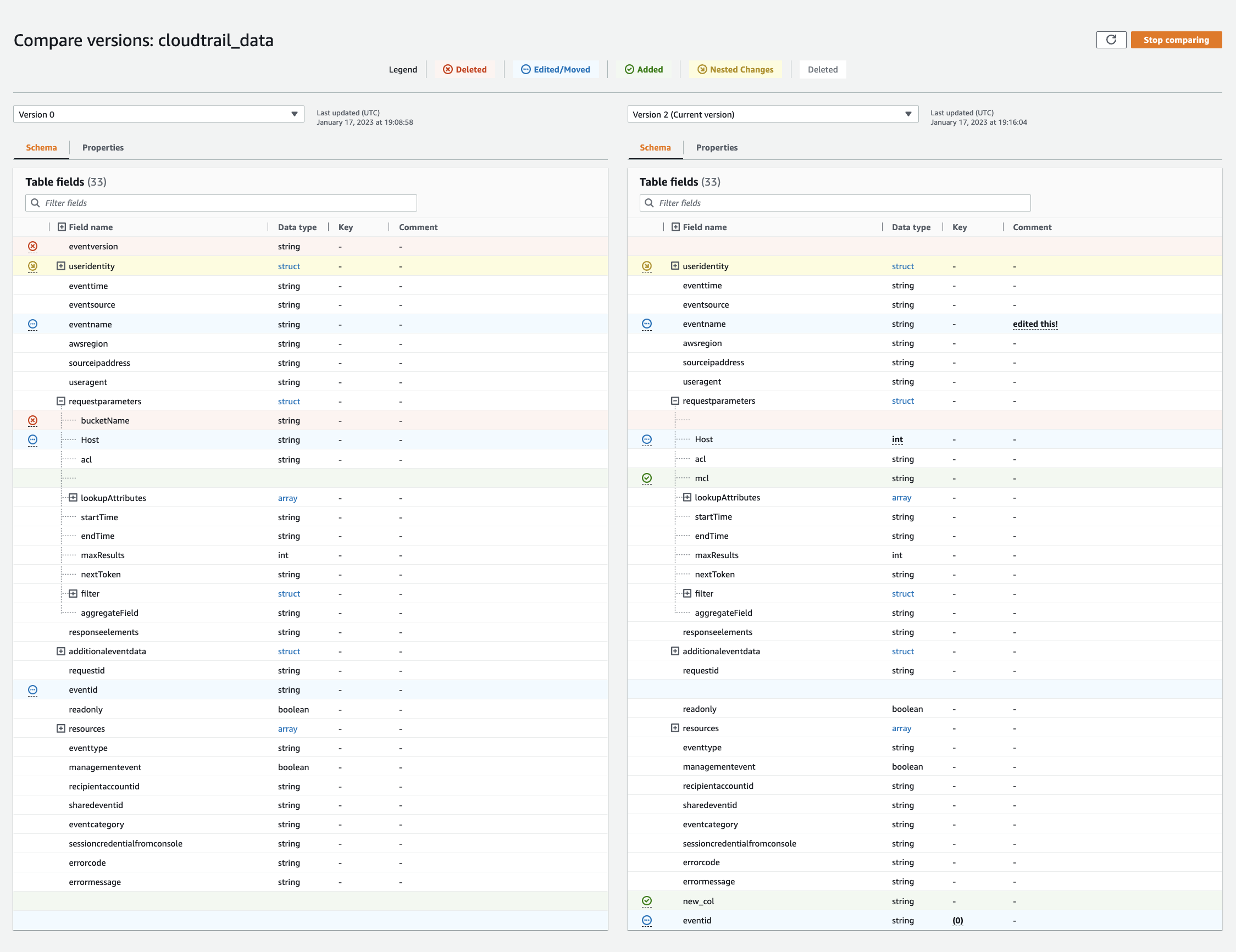
Escolha uma versão para comparar no menu suspenso de versões. Ao comparar esquemas, a guia Esquema fica realçada em laranja.
-
Quando você compara tabelas entre duas versões, os esquemas de tabela são apresentados a você no lado esquerdo e no lado direito da tela. Isso permite que você determine visualmente as alterações comparando os campos de nome da coluna, tipo de dados, chave e comentários lado a lado. Quando há uma alteração, um ícone colorido exibe o tipo de alteração que foi feita.
-
Excluído: exibido por um ícone vermelho indica onde a coluna foi removida de uma versão anterior do esquema da tabela.
-
Editado ou movido: exibido por um ícone azul indica onde a coluna foi modificada ou movida em uma versão mais recente do esquema da tabela.
-
Adicionado: exibido por um ícone verde indica onde a coluna foi adicionada a uma versão mais recente do esquema da tabela.
-
Alterações aninhadas: exibido por um ícone amarelo indica onde a coluna aninhada contém as alterações. Escolha a coluna a ser expandida e visualize as colunas que foram excluídas, editadas, movidas ou adicionadas.
-
-
Use a barra de pesquisa de campos de filtro para exibir campos com base nos caracteres que você inserir aqui. Se você inserir um nome de coluna em qualquer uma das versões da tabela, os campos filtrados serão exibidos nas duas versões da tabela para mostrar onde as alterações ocorreram.
-
Para comparar propriedades, escolha a guia Propriedades.
-
Para parar de comparar versões, escolha Interromper comparação para retornar à lista de tabelas.
Otimizar tabelas Iceberg
Os data lakes do Amazon S3 usando formatos de tabela aberta, como o Apache Iceberg, armazenam os dados como objetos do Amazon S3. Ter milhares de pequenos objetos Amazon S3 em uma tabela de data lake aumenta a sobrecarga de metadados nas tabelas Iceberg e afeta o desempenho de leitura. Para obter uma melhor performance de leitura por serviços de análise da AWS, como o Amazon Athena ou o Amazon EMR e trabalhos do AWS Glue ETL, o AWS Glue Data Catalog oferece compactação gerenciada (um processo que compacta pequenos objetos do Amazon S3 em objetos maiores) para tabelas do Iceberg no Catálogo de Dados. Você pode usar o console do AWS Glue, o console do Lake Formation, a AWS CLI ou a API da AWS para habilitar ou desabilitar a compactação de tabelas individuais do Iceberg que estão no Catálogo de Dados.
O otimizador de tabelas monitora constantemente as partições da tabela e inicia o processo de compactação quando o limite é excedido para o número de arquivos e tamanhos de arquivo. No Catálogo de dados, o valor limite padrão para iniciar a compactação é definido como 384 MB, enquanto na biblioteca Iceberg o limite para compactação é de aproximadamente 75% do tamanho do arquivo de destino. O Catálogo de dados executa a compactação sem interferir nas consultas simultâneas. O Catálogo de dados oferece suporte à compactação de dados somente para tabelas no formato Parquet.
Tópicos
Pré-requisitos de otimização de tabelas
O otimizador de tabela assume as permissões do perfil do (IAM) AWS Identity and Access Management que você especificou ao habilitar a compactação para uma tabela. O perfil do IAM deve ter as permissões para ler dados e atualizar metadados no Catálogo de dados. Você pode criar um perfil do IAM e anexar as políticas em linha a seguir:
-
Adicione a seguinte política em linha que concede ao Amazon S3 permissões de leitura/gravação no local para dados que não estão registrados no Lake Formation. Essa política também inclui permissões para atualizar a tabela no Catálogo de dados e permitir que AWS Glue adicione logs em logs Amazon CloudWatch e a publicação de métricas. Para dados de origem no Amazon S3 que não estão registrados no Lake Formation, o acesso é determinado pelas políticas de permissões do IAM para o Amazon S3 e ações AWS Glue.
Nas políticas em linha a seguir, substitua
bucket-namepelo nome do bucket do Amazon S3,aws-account-ideregionpor um número de conta da AWS e por uma região do catálogo de dados válidos,database_namepelo nome do seu banco de dados etable_namepelo nome da tabela.{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject", "s3:DeleteObject" ], "Resource": [ "arn:aws:s3:::<bucket-name>/*" ] }, { "Effect": "Allow", "Action": [ "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::<bucket-name>" ] }, { "Effect": "Allow", "Action": [ "glue:UpdateTable", "glue:GetTable" ], "Resource": [ "arn:aws:glue:<region>:<aws-account-id>:table/<database-name>/<table-name>", "arn:aws:glue:<region>:<aws-account-id>:database/<database-name>", "arn:aws:glue:<region>:<aws-account-id>:catalog" ] }, { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:<region>:<aws-account-id>:log-group:/aws-glue/iceberg-compaction/logs:*" } ] } -
Use a política a seguir para habilitar a compactação de dados registrados no Lake Formation.
Para obter mais informações sobre o registro de um bucket do Amazon S3 no Lake Formation, consulte Requisitos para perfis usados para registrar locais.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "lakeformation:GetDataAccess" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "glue:UpdateTable", "glue:GetTable" ], "Resource": [ "arn:aws:glue:<region>:<aws-account-id>:table/<databaseName>/<tableName>", "arn:aws:glue:<region>:<aws-account-id>:database/<database-name>", "arn:aws:glue:<region>:<aws-account-id>:catalog" ] }, { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:<region>:<aws-account-id>:log-group:/aws-glue/iceberg-compaction/logs:*" } ] }Se o perfil de compactação não tiver permissões de grupo
IAM_ALLOWED_PRINCIPALSconcedidas na tabela, o perfil exigirá as permissões ALTER, DESCRIBE, INSERT e DELETE do Lake Formation na tabela. -
(Opcional) Para compactar tabelas Iceberg com dados em buckets do Amazon S3 criptografados usando criptografia do lado do servidor, a função de compactação exige permissões para descriptografar objetos do Amazon S3 e gerar uma nova chave de dados para gravar objetos nos buckets criptografados. Adicione a seguinte política à chave desejada AWS KMS. Oferecemos suporte somente à criptografia em nível de bucket.
{ "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::<aws-account-id>:role/<compaction-role-name>" }, "Action": [ "kms:Decrypt", "kms:GenerateDataKey" ], "Resource": "*" } -
(Opcional) Para locais de dados registrados no Lake Formation, o perfil usado para registrar a localização exige permissões para descriptografar objetos do Amazon S3 e gerar uma nova chave de dados para gravar objetos nos buckets criptografados. Para obter mais informações, consulte Registrar um local do Amazon S3.
-
(Opcional) Se a chave do AWS KMS estiver armazenada em uma conta da AWS diferente, você precisará incluir as permissões a seguir no perfil de compactação.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "kms:Decrypt", "kms:GenerateDataKey" ], "Resource": ["arn:aws:kms:<REGION>:<KEY_OWNER_ACCOUNT_ID>:key/<KEY_ID>"] } ] } -
A função que você usa para executar a compactação deve ter a permissão
iam:PassRoleda função.{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "iam:PassRole" ], "Resource": [ "arn:aws:iam::<account-id>:role/<compaction-role-name>" ] } ] } -
Adicione a política de confiança a seguir à função para que o serviço AWS Glue assuma o perfil do IAM para executar o processo de compactação.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Principal": { "Service": "glue.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }
Habilitar a compactação
Você pode usar o console do AWS Glue, o console do Lake Formation, a AWS CLI ou a API da AWS para habilitar a compactação de tabelas do Apache Iceberg que estão no Catálogo de Dados. Para novas tabelas, é possível escolher o Apache Iceberg como formato de tabela e habilitar a compactação ao criar a tabela. A compactação está desabilitada por padrão para novas tabelas.
Após a habilitação da compactação, a guia Otimização da tabela mostrará os seguintes detalhes da compactação (após aproximadamente 15 a 20 minutos):
-
Hora de início: a hora em que o processo de compactação começou no Lake Formation. O valor é uma marca de data e hora no horário UTC.
-
Hora de término: a hora em que o processo de compactação terminou no Lake Formation. O valor é uma marca de data e hora no horário UTC.
-
Status: o status da execução de compactação. Os valores possíveis são êxito ou falha.
-
Arquivos compactados: número total de arquivos compactados.
-
Bytes compactados: número total de bytes compactados.
Desabilitar a compactação
Você pode desativar a compactação automática para uma tabela específica do Apache Iceberg usando o console AWS Glue ou AWS CLI.
Visualizar detalhes da compactação
É possível visualizar o status de compactação do Apache Iceberg usando o console do AWS Glue, a AWS CLI ou as operações da API da AWS.
Visualizar métricas do Amazon CloudWatch
Depois de executar a compactação com sucesso, o serviço cria métricas do Amazon CloudWatch para a performance do trabalho de compactação. É possível acessar o console do CloudWatch e escolher Métricas, Todas as métricas. Você pode filtrar métricas pelo espaço de nome específico (por exemplo AWS Glue), nome da tabela ou nome do banco de dados.
Para obter mais informações, consulte Visualizar métricas disponíveis no Guia do usuário Amazon CloudWatch.
-
Número de bytes compactados
-
Número de arquivos compactados
-
Número de DPU alocadas para trabalhos
-
Duração do trabalho (horas)
Excluindo um otimizador
Você pode excluir um otimizador e os metadados associados à tabela usando nossa operação de API AWS CLI ou AWS.
Execute o comando AWS CLI a seguir para excluir o histórico de compactação de uma tabela.
aws glue delete-table-optimizer \ --catalog-id123456789012\ --database-nameiceberg_db\ --table-nameiceberg_table\ --type compaction
Use a operação DeleteTableOptimizer para excluir um otimizador para uma tabela.
Considerações e limitações
A compactação de dados suporta:
Tipos de dados: Booleano, Inteiro, Longo, Flutuante, Duplo, String, Decimal, Data, Hora, Timestamp, String, UUID, Binário
Compressão: zstd, gzip, snappy, não compactado
-
Criptografia: a compactação de dados suporta somente a criptografia padrão do Amazon S3 (SSE-S3) e a criptografia KMS do lado do servidor (SSE-SKMS).
-
Compactação do compartimento
Evolução do esquema
Tabelas com tamanho de arquivo de destino (propriedade write.target-file-size-bytes na configuração iceberg) dentro do intervalo inclusivo de 128 MB a 512 MB.
Regiões
Ásia-Pacífico (Tóquio)
Ásia-Pacífico (Seul)
Ásia-Pacífico (Mumbai)
Europa (Irlanda)
Europa (Frankfurt)
Leste dos EUA (Norte da Virgínia)
Leste dos EUA (Ohio)
Oeste dos EUA (N. da Califórnia)
-
Você pode executar a compactação a partir da conta em que o catálogo de dados reside quando o bucket do Amazon S3 que armazena os dados subjacentes estiver em outra conta. Para fazer isso, a função de compactação exige acesso ao bucket do Amazon S3.
Atualmente, a compactação de dados não oferece suporte a:
Tipos de dados: Fixo
Compressão: brotli, lz4
Compactação de arquivos enquanto a especificação da partição evolui.
Classificação regular ou classificação por ordem z
Mesclar ou excluir arquivos: o processo de compactação ignora os arquivos de dados que têm arquivos excluídos associados a eles.
-
Compactação em tabelas de contas cruzadas: você não pode executar a compactação em tabelas de contas cruzadas.
-
Compactação em tabelas entre contas: não é possível executar a compactação em tabelas entre contas.
Habilitando a compactação em links de recursos
Endpoints da VPC para o Amazon S3
