Tutorial: escrever um script de ETL no AWS Glue para Ray
O Ray permite escrever e escalar tarefas distribuídas de modo nativo no Python. O AWS Glue para Ray oferece ambientes do Ray sem servidor que você pode acessar tanto em trabalhos quanto em sessões interativas (as sessões interativas do Ray estão em versão prévia). O sistema de trabalhos do AWS Glue fornece uma maneira consistente de gerenciar e executar tarefas, segundo uma agenda, acionadas por um gatilho ou no console do AWS Glue.
A combinação dessas ferramentas do AWS Glue cria um poderoso conjunto de ferramentas que você pode usar para workloads de extração, transformação e carregamento (ETL), um caso de uso popular do AWS Glue. Neste tutorial, você aprenderá o básico sobre como desenvolver essa solução.
Também oferecemos compatibilidade com o uso do AWS Glue for Spark para suas workloads de ETL. Para obter um tutorial sobre escrever scripts do AWS Glue for Spark, consulte Tutorial: gravar um script do AWS Glue para Spark. Para obter mais informações sobre os mecanismos disponíveis, consulte AWS Glue para Spark e AWS Glue para Ray. O Ray é capaz de lidar com vários tipos diferentes de tarefas em analytics, machine learning (ML) e desenvolvimento de aplicações.
Neste tutorial, você extrairá, transformará e carregará um conjunto de dados CSV hospedado no Amazon Simple Storage Service (Amazon S3). Você começará com o conjunto de dados de registro de viagens da Taxi and Limousine Commission (TLC) da cidade de Nova York, que está armazenado em um bucket público do Amazon S3. Para obter mais informações sobre esse conjunto de dados, consulte Dados abertos na AWS
Você transformará os dados com transformações predefinidas que estão disponíveis na biblioteca Ray Data. Ray Data é uma biblioteca de preparação de conjuntos de dados projetada pela Ray e incluída por padrão nos ambientes do AWS Glue para Ray. Para obter mais informações sobre as bibliotecas incluídas por padrão, consulte Módulos fornecidos com trabalhos do Ray. Em seguida, você gravará os dados transformados em um bucket do Amazon S3 que você controla.
Pré-requisitos: para este tutorial, você precisará de uma conta da AWS com acesso ao AWS Glue e ao Amazon S3.
Etapa 1: criar um bucket no Amazon S3 para armazenar os dados de saída
será necessário um bucket do Amazon S3 que você controla para servir como coletor dos dados criados neste tutorial. Você pode criar esse bucket com o procedimento a seguir.
nota
Se quiser gravar os dados em um bucket existente que você controla, pode pular esta etapa. Anote yourBucketName, o nome do bucket existente, para usar em etapas posteriores.
Para criar um bucket para a saída do trabalho do Ray
-
Crie um bucket seguindo as etapas em Criação de um bucket no Guia do usuário do Amazon S3.
-
Ao escolher um nome de bucket, anote
yourBucketName, que você vai referenciar em etapas posteriores. -
Para outras configurações, as configurações sugeridas fornecidas no console do Amazon S3 devem funcionar bem neste tutorial.
Por exemplo, a caixa de diálogo de criação do bucket pode ter essa aparência no console do Amazon S3.
-
Etapa 2: criar uma política e um perfil do IAM para o trabalho do Ray
O trabalho precisará de um perfil do AWS Identity and Access Management (IAM) com o seguinte:
-
Permissões concedidas pela política gerenciada pela
AWSGlueServiceRole. Estas são as permissões básicas necessárias para executar um trabalho do AWS Glue. -
Permissões de nível de acesso de
Readpara o recursonyc-tlc/*do Amazon S3. -
Permissões de nível de acesso de
Writepara o recursoyourBucketName/* -
Uma relação de confiança que permita que a entidade principal do
glue.amazonaws.comassuma o perfil.
Você pode criar esse perfil com o procedimento a seguir.
Para criar um perfil do IAM para o trabalho do AWS Glue para Ray
nota
Você pode criar um perfil do IAM seguindo vários procedimentos diferentes. Para obter mais informações ou opções de como provisionar recursos do IAM, consulte a documentação do AWS Identity and Access Management.
-
Crie uma política que defina as permissões do Amazon S3 descritas anteriormente seguindo as etapas em Criar políticas do IAM (console) com o editor visual no Guia do usuário do IAM.
-
Ao selecionar um serviço, escolha Amazon S3.
-
Ao selecionar permissões para a política, anexe os seguintes conjuntos de ações para os seguintes recursos (mencionados anteriormente):
-
Permissões de nível de acesso de leitura para o recurso
nyc-tlc/*do Amazon S3. -
Permissões de nível de acesso de gravação para o recurso
yourBucketName/*
-
-
Ao escolher um nome de bucket, anote
YourPolicyName, que você vai referenciar uma etapa posterior.
-
-
Crie um perfil parra o trabalho do AWS Glue para Ray seguindo as etapas em Criar um perfil para um serviço da AWS (console) no Guia do usuário do IAM.
-
Ao selecionar uma entidade confiável de serviço da AWS, escolha
Glue. Isso preencherá automaticamente a relação de confiança necessária para o trabalho. -
Ao selecionar políticas para a política de permissões, anexe as seguintes políticas:
-
AWSGlueServiceRole -
YourPolicyName
-
-
Ao selecionar um nome de perfil, anote
YourRoleName, que você vai referenciar em etapas posteriores.
-
Etapa 3: criar e executar um trabalho do AWS Glue para Ray
Nesta etapa, você cria um trabalho do AWS Glue usando o AWS Management Console, fornece a ele um script de amostra e executa o trabalho. Quando você cria um trabalho, ele cria um local no console para você armazenar, configurar e editar seu script do Ray. Para obter mais informações sobre como criar trabalhos, consulte Gerenciar trabalhos do AWS Glue no Console da AWS.
Neste tutorial, abordamos o seguinte cenário de ETL: você deseja ler o conjunto de dados de registro de viagens de janeiro de 2022 da TLC da cidade de Nova York, adicionar uma nova coluna (tip_rate) ao conjunto de dados combinando os dados nas colunas existentes, depois remover várias colunas que não são relevantes para sua análise atual e depois deseja gravar os resultados no yourBucketName. O script Ray a seguir executa essas etapas:
import ray import pandas from ray import data ray.init('auto') ds = ray.data.read_csv("s3://nyc-tlc/opendata_repo/opendata_webconvert/yellow/yellow_tripdata_2022-01.csv") # Add the given new column to the dataset and show the sample record after adding a new column ds = ds.add_column( "tip_rate", lambda df: df["tip_amount"] / df["total_amount"]) # Dropping few columns from the underlying Dataset ds = ds.drop_columns(["payment_type", "fare_amount", "extra", "tolls_amount", "improvement_surcharge"]) ds.write_parquet("s3://yourBucketName/ray/tutorial/output/")
Para criar e executar um trabalho do AWS Glue para Ray
-
No AWS Management Console, navegue até a página inicial do AWS Glue.
-
No painel de navegação lateral, escolha Trabalhos de ETL.
-
Em Criar trabalho, escolha Editor de scripts do Ray e depois Criar, como na ilustração a seguir.
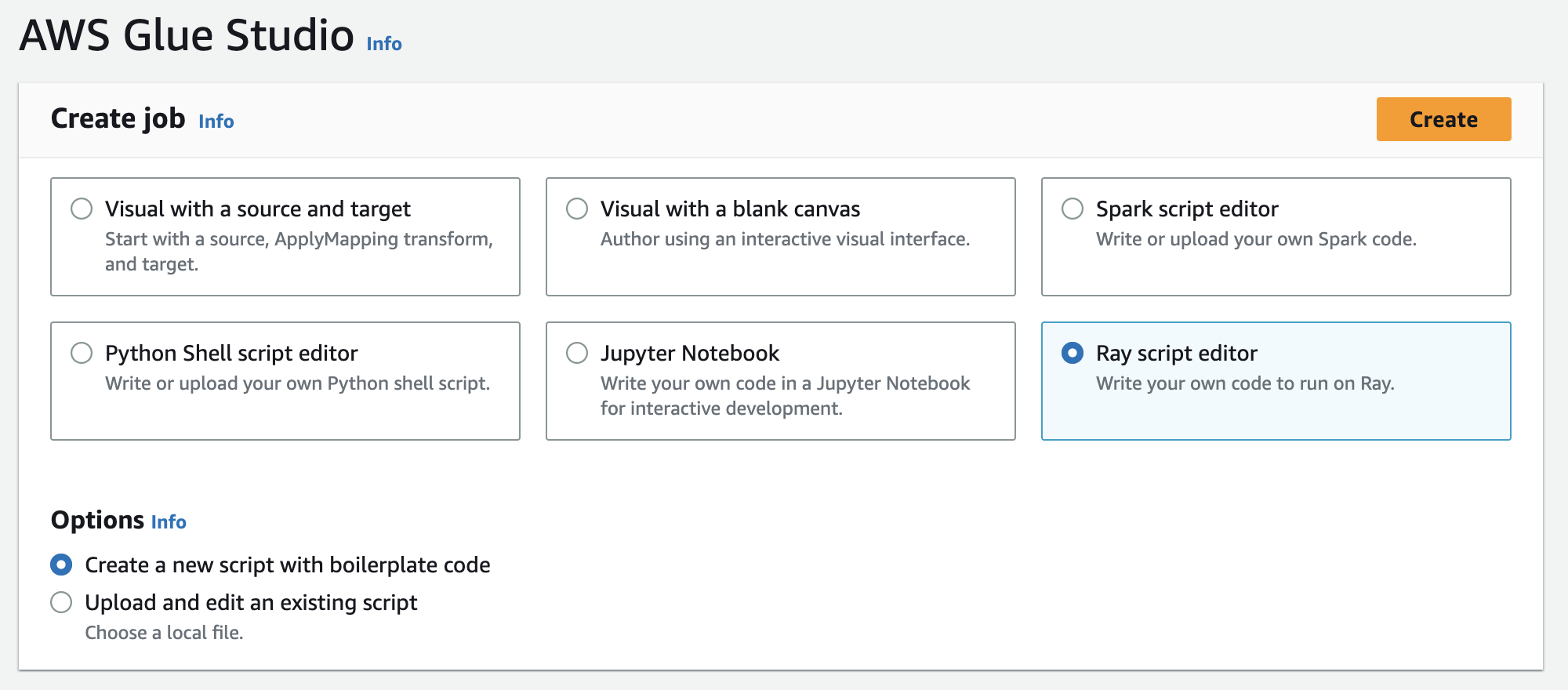
-
Cole o texto completo do script no painel Script e substitua qualquer texto existente.
-
Navegue até Detalhes do trabalho e defina a propriedade Perfil do IAM como
YourRoleName. -
Escolha Salvar e depois Executar.
Etapa 4: inspecionar a saída
Depois de executar o trabalho do AWS Glue, você deve validar se a saída corresponde às expectativas desse cenário. Para fazer isso, use o seguinte procedimento.
Para validar se o trabalho do Ray foi executado com êxito
-
Na página de detalhes do trabalho, navegue até Execuções.
-
Depois de alguns minutos, você verá uma execução com o Status de execução Bem-sucedida.
-
Navegue até o console do Amazon S3 em https://console.aws.amazon.com/s3/. Você deve ver os arquivos gravados no bucket de saída.e inspecione yourBucketName -
Leia os arquivos do Parquet e verifique seu conteúdo. Você pode fazer isso com as ferramentas existentes. Se você não tiver um processo para validar arquivos do Parquet, poderá fazer isso no console do AWS Glue com uma sessão interativa do AWS Glue, usando o Spark ou o Ray (em versão prévia).
Em uma sessão interativa, você tem acesso às bibliotecas Ray Data, Spark ou pandas, que são fornecidas por padrão (com base no mecanismo de sua escolha). Para verificar o conteúdo do arquivo, você pode usar métodos de inspeção comuns que estão disponíveis nessas bibliotecas, métodos como
count,schemaeshow. Para obter mais informações sobre sessões interativas no console, consulte Using notebooks with AWS Glue Studio and AWS Glue.Como você confirmou que os arquivos foram gravados no bucket, pode dizer com relativa certeza que, se a saída tiver problemas, eles não serão relacionados à configuração do IAM. Configure a sessão com
yourRoleNamepara ter acesso aos arquivos relevantes.
Se você não encontrar os resultados esperados, examine o conteúdo de solução de problemas neste guia para identificar e corrigir a causa do erro. Você pode encontrar o conteúdo da solução de problemas no capítulo Solução de problemas do AWS Glue. Para erros específicos relacionados aos trabalhos do Ray, consulte Solucionar problemas do AWS Glue para erros do Ray a partir de logs no capítulo de solução de problemas.
Próximas etapas
Agora você viu e executou um processo de ETL usando o AWS Glue para Ray do início ao fim. Você pode usar os recursos a seguir para entender quais ferramentas o AWS Glue para Ray fornece para transformar e interpretar dados em grande escala.
-
Para ter mais informações sobre o modelo de tarefa do Ray, consulte Usar o Ray Core e o Ray Data no AWS Glue para Ray. Para ganhar mais experiência no uso de tarefas do Ray, siga os exemplos na documentação do Ray Core. Consulte Ray Core: Ray Tutorials and Examples (2.4.0)
na documentação do Ray. -
Para obter orientação sobre as bibliotecas de gerenciamento de dados disponíveis no AWS Glue para Ray, consulte Conectar a dados em trabalhos do Ray. Para obter mais experiência no uso do Ray Data para transformar e gravar conjuntos de dados, siga os exemplos na documentação do Ray Data. Consulte Ray Data: Examples (2.4.0)
. -
Para obter mais informações sobre configuração e gerenciamento de trabalhos do AWS Glue para Ray, consulte Trabalhar com trabalhos do Ray no AWS Glue.
-
Para obter mais informações sobre escrever scripts do AWS Glue para Ray, continue lendo a documentação nesta seção.
