Usar métricas do AWS Glue Streaming
Essa seção descreve cada uma das métricas e como elas se correlacionam entre si.
Número de registros (métrica: streaming.numRecords)
Essa métrica indica quantos registros estão sendo processados.
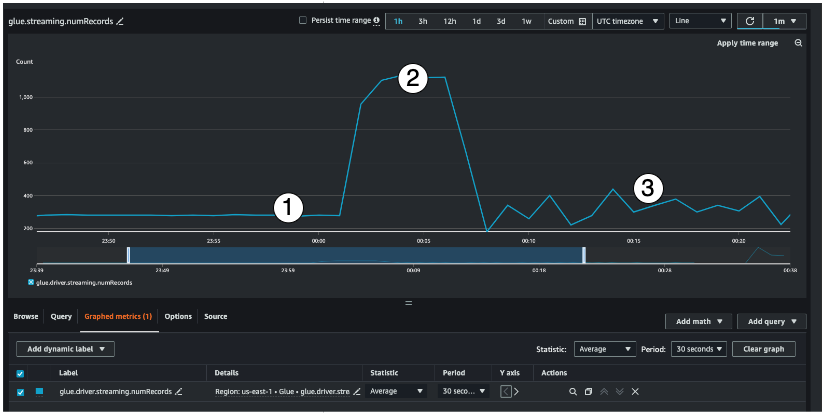
Essa métrica de streaming fornece visibilidade sobre o número de registros que você está processando em uma janela. Além do número de registros que estão sendo processados, ela ajudará você a compreender o comportamento do tráfego de entrada.
O indicador n.º 1 mostra um exemplo de tráfego estável sem aumentos. Normalmente, serão aplicações, como sensores de IoT, que coletam dados em intervalos regulares e os enviam para a fonte de streaming.
O indicador n.º 2 mostra um exemplo de um aumento repentino no tráfego em uma carga estável. Isso pode acontecer em uma aplicação de fluxo de cliques quando há um evento de marketing, como a Black Friday, e ocorre um aumento no número de cliques.
O indicador n.º 3 mostra um exemplo de tráfego imprevisível. O tráfego imprevisível significa que há um problema. É somente a natureza dos dados de entrada. Ao retornarmos ao exemplo do sensor de IoT, é possível imaginar centenas de sensores que enviam eventos de mudanças climáticas para a fonte de streaming. Como a mudança climática não é previsível, os dados também não o são. A compreensão do padrão de tráfego é fundamental para dimensionar seus executores. Se a entrada tiver um amplo aumento, considere usar o ajuste de escala automático (falaremos mais sobre isso posteriormente).
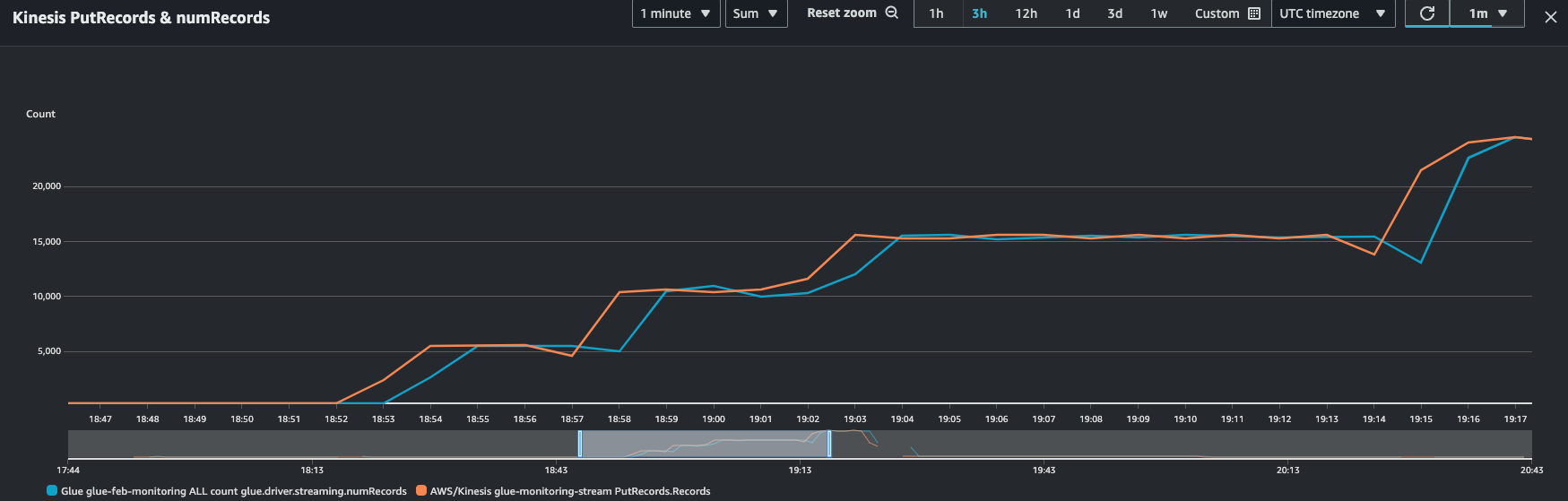
É possível combinar essa métrica com a métrica PutRecords do Kinesis para garantir que o número de eventos que estão sendo ingeridos e o número de registros que estão sendo lidos sejam praticamente semelhantes. Isso é especialmente útil quando você está tentando compreender o atraso. À medida que a taxa de ingestão aumenta, o mesmo acontece com os numRecords lidos pelo AWS Glue.
Tempo de processamento em lote (métrica: streaming.batchProcessingTimeInMs)
A métrica de tempo de processamento em lote ajuda a determinar se o cluster está com provisionamento insuficiente ou excessivo.
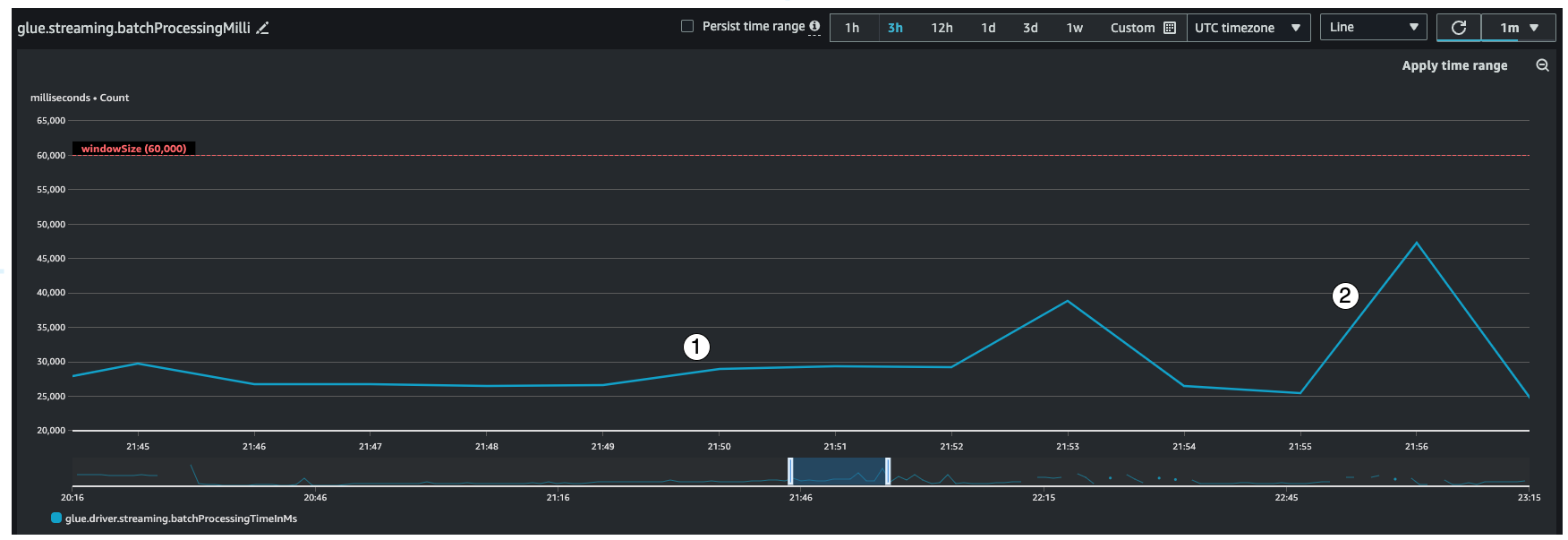
Essa métrica indica o número de milissegundos necessários para processar cada micro lote de registros. Aqui, o principal objetivo é monitorar esse tempo para garantir que seja menor que o intervalo de windowSize. Não há problema se batchProcessingTimeInMs for temporariamente desativado, desde que se recupere no intervalo de janela seguinte. O indicador n.º 1 mostra um tempo mais ou menos estável necessário para o processamento do trabalho. No entanto, se o número de registros de entrada estiver aumentando, o tempo necessário para o processamento do trabalho aumentará, conforme mostrado pelo indicador n.º 2. Se o numRecords não estiver aumentando, mas o tempo de processamento estiver, você precisará examinar o processamento do trabalho nos executores de forma mais aprofundada. É uma boa prática definir um limite e um alarme para garantir que batchProcessingTimeInMs não ultrapasse 120% por mais de dez minutos. Para obter mais informações sobre como configurar alarmes, consulte Usar alarmes do Amazon CloudWatch.
Atraso do consumidor (métrica: streaming.maxConsumerLagInMs)
A métrica de atraso do consumidor ajuda a entender se há um atraso no processamento de eventos. Se o atraso for muito elevado, você poderá perder o SLA de processamento do qual sua empresa depende, mesmo que tenha um windowSize correto. Você deve habilitar explicitamente essas métricas usando a opção de conexão emitConsumerLagMetrics. Para obter mais informações, consulte KinesisStreamingSourceOptions.
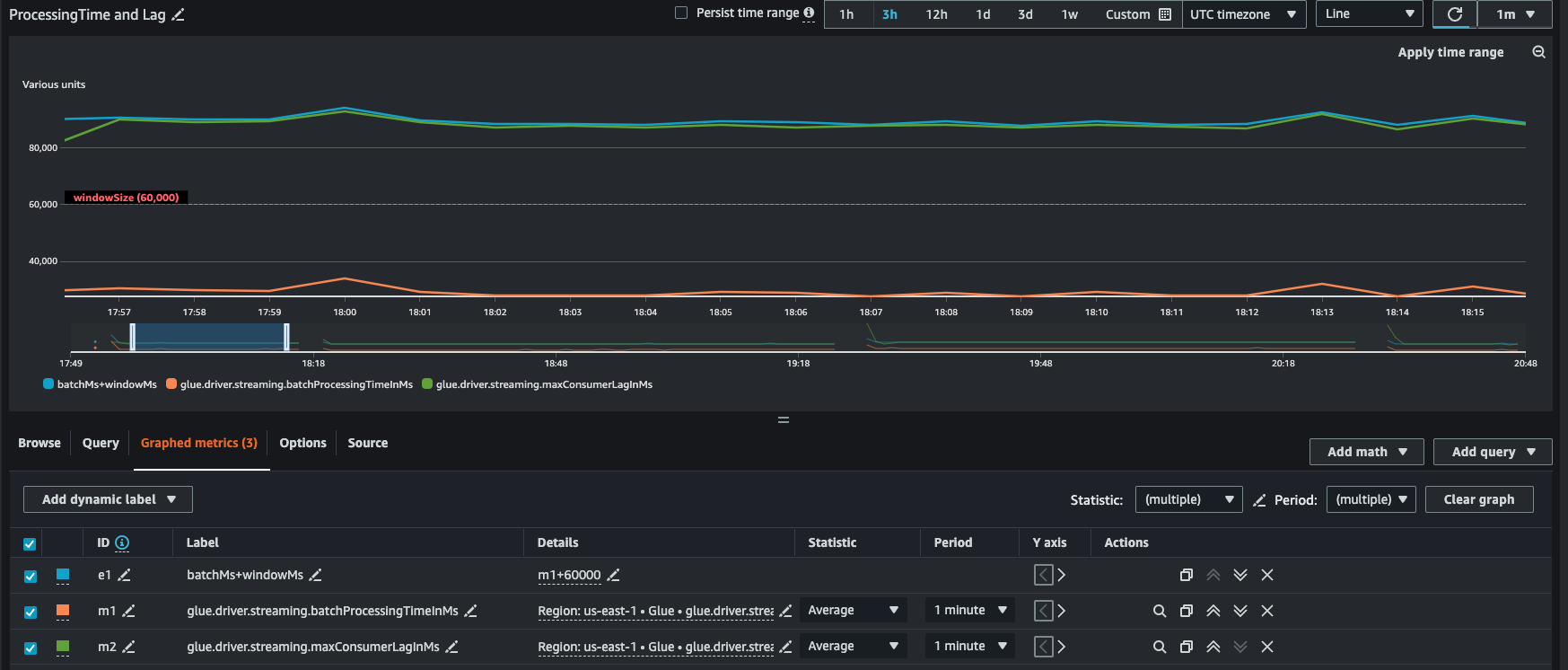
Métricas derivadas
Para obter insights mais aprofundados, é possível criar métricas derivadas para compreender mais sobre os trabalhos de streaming no Amazon CloudWatch.
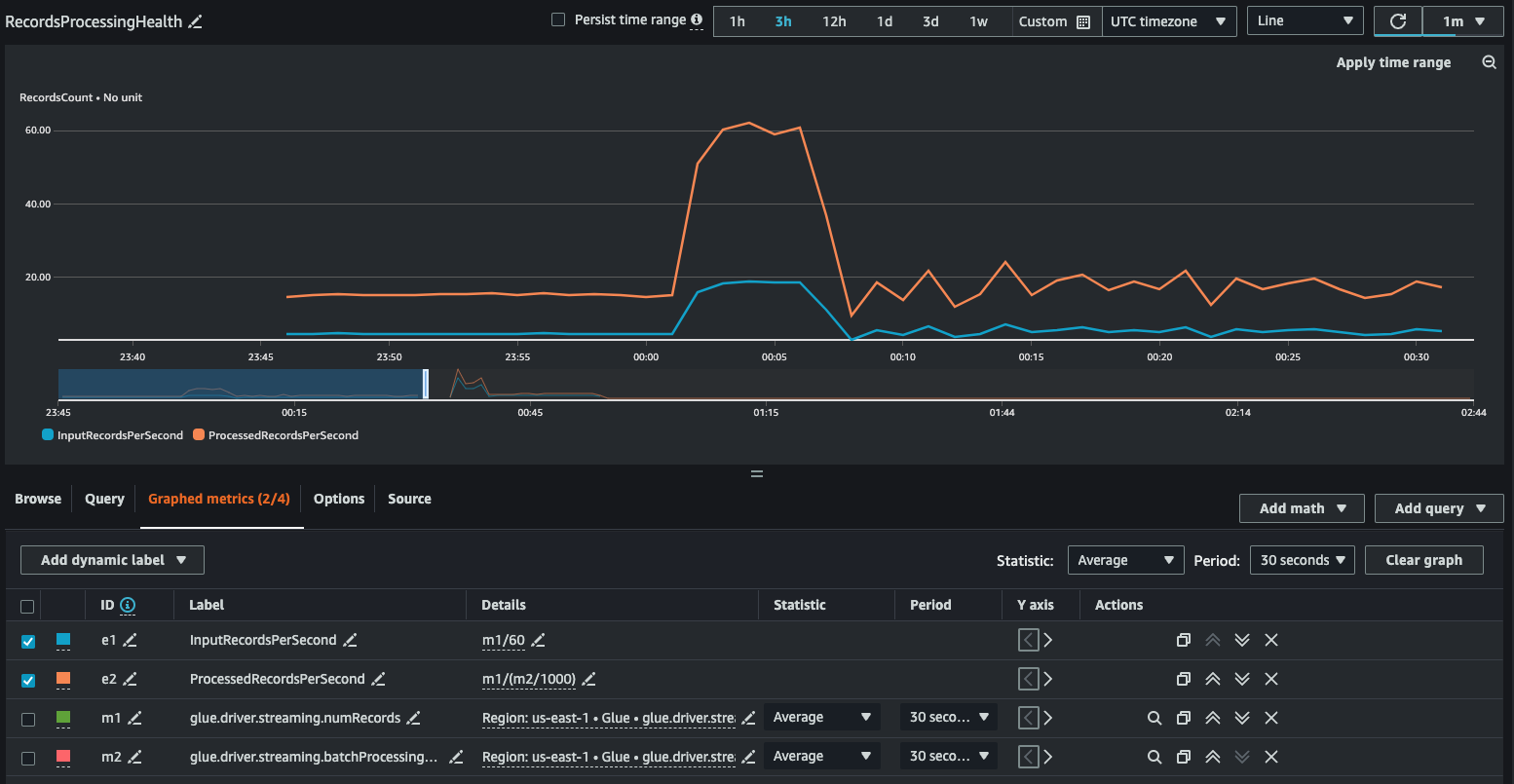
É possível desenvolver uma representação em gráfico com métricas derivadas para decidir se precisa usar mais DPUs. Embora o ajuste de escala automático ajude você a fazer isso automaticamente, é possível usar métricas derivadas para determinar se o ajuste de escala automático está funcionando de maneira eficaz.
InputRecordsPerSecond indica a taxa na qual você está obtendo registros de entrada. A derivação ocorre da seguinte forma: número de registros de entrada (glue.driver.streaming.numRecords)/WindowSize.
ProcessingRecordsPerSecond indica a taxa na qual os registros estão sendo processados. A derivação ocorre da seguinte forma: número de registros de entrada (glue.driver.streaming.numRecords)/batchProcessingTimeInMs.
Se a taxa de entrada for superior à taxa de processamento, talvez seja necessário adicionar mais capacidade para processar os trabalhos ou aumentar o paralelismo.
Métricas do ajuste de escala automático
Quando o tráfego de entrada tiver um amplo aumento, considere habilitar o ajuste de escala automático e especificar o número máximo de trabalhadores. Com isso você obtém duas métricas adicionais, numberAllExecutors e numberMaxNeededExecutors.
numberAllExecutors corresponde ao número de executores de trabalhos em execução ativa.
numberMaxNeededExecutors corresponde ao número máximo de executores de trabalhos (em execução ativa e pendentes) necessários para satisfazer a carga atual.
Essas duas métricas ajudarão você a entender se o ajuste de escala automático está funcionando corretamente.
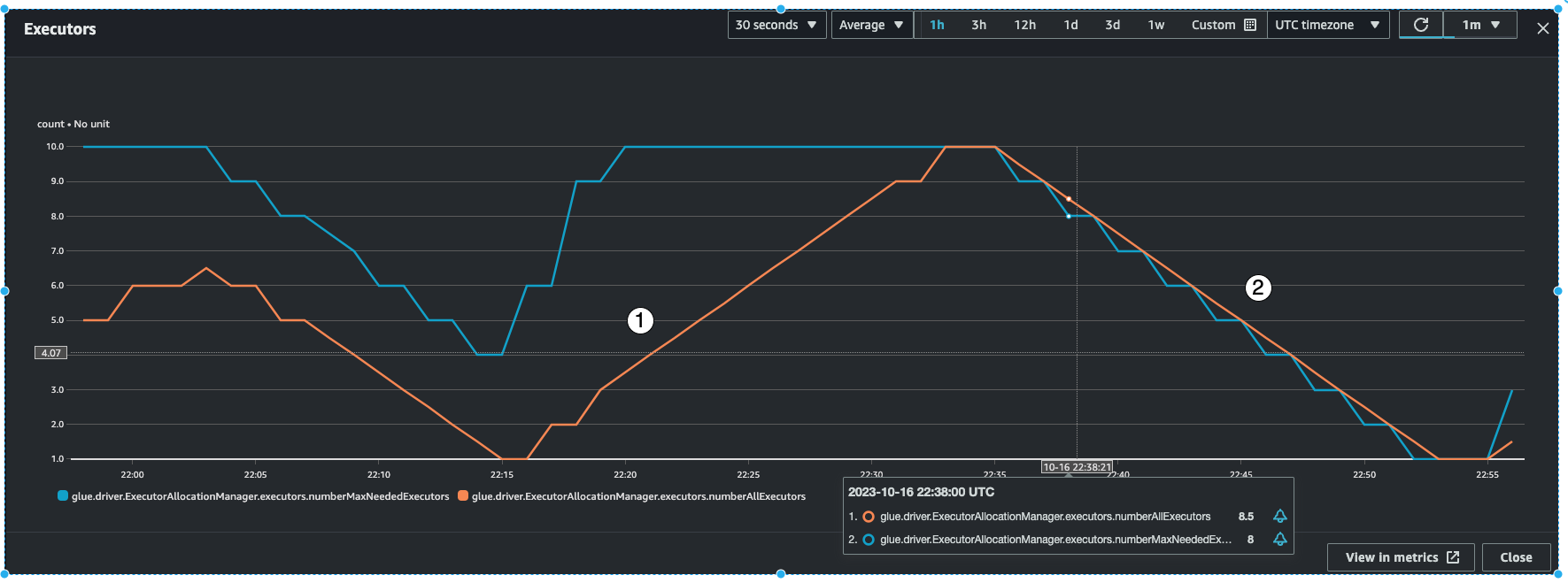
O AWS Glue monitorará a métrica batchProcessingTimeInMs em alguns micro lotes e fará uma entre duas coisas. Ele aumentará a escala horizontalmente dos executores, se batchProcessingTimeInMs estiver mais próximo de windowSize, ou reduzirá a escala horizontalmente dos executores, se batchProcessingTimeInMs for comparativamente menor que windowSize. Além disso, ele usará um algoritmo para escalar os executores em etapas.
O indicador n.º 1 mostra como os executores ativos aumentaram a escala verticalmente para alcançar o número máximo de executores necessários para o processamento da carga.
O indicador n.º 2 mostra como os executores ativos reduziram a escala horizontalmente desde que
batchProcessingTimeInMsestava baixo.
É possível usar essas métricas para monitorar o paralelismo atual no nível do executor e ajustar, adequadamente, o número máximo de trabalhadores em sua configuração de ajuste de escala automático.
