As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Amazon Keyspaces: como funciona
O Amazon Keyspaces remove a sobrecarga administrativa do gerenciamento do Cassandra. Para entender por que, é útil começar com a arquitetura do Cassandra e depois compará-la com o Amazon Keyspaces.
Tópicos
Arquitetura de alto nível: Apache Cassandra versus Amazon Keyspaces
O Apache Cassandra tradicional é implantado em um cluster composto de um ou mais nós. Você é responsável por gerenciar cada nó e adicionar e remover nós à medida que seu cluster é escalado.
Um programa cliente acessa o Cassandra conectando-se a um dos nós e emitindo instruções Cassandra Query Language (CQL). O CQL é semelhante ao SQL, a linguagem popular usada em bancos de dados relacionais. Embora o Cassandra não seja um banco de dados relacional, o CQL fornece uma interface familiar para consultar e manipular dados no Cassandra.
O diagrama a seguir mostra um cluster Apache Cassandra simples, com quatro nós.
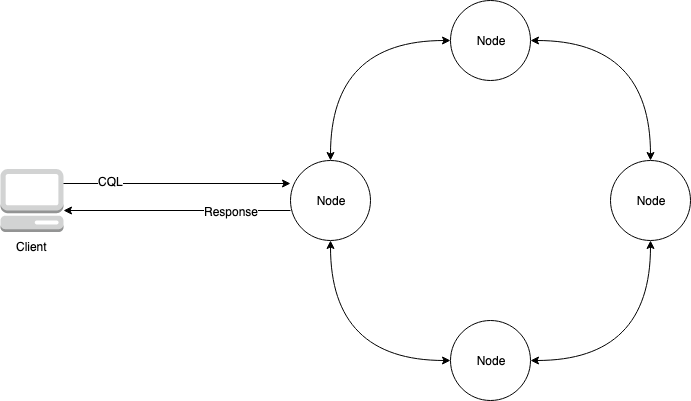
Uma implantação de produção do Cassandra pode consistir em centenas de nós, executados em centenas de computadores físicos em um ou mais datacenters físicos. Isso pode causar uma sobrecarga operacional para os desenvolvedores de aplicativos que precisam provisionar, corrigir e gerenciar servidores, além de instalar, manter e operar o software.
Com o Amazon Keyspaces (para Apache Cassandra), você não precisa provisionar, corrigir ou gerenciar servidores, para que possa se concentrar na criação de aplicativos melhores. O Amazon Keyspaces oferece dois modos de capacidade de throughput para leituras e gravações: sob demanda e provisionada. Você pode escolher o modo de capacidade de throughput da sua tabela para otimizar o preço das leituras e gravações com base na previsibilidade e na variabilidade da sua workload.
Com o modo sob demanda, você paga apenas pelas leituras e gravações que seu aplicativo realmente executa. Você não precisa especificar com antecedência a capacidade de throughput de sua tabela. O Amazon Keyspaces acomoda o tráfego do seu aplicativo quase instantaneamente à medida que aumenta ou diminui, o que o torna uma boa opção para aplicativos com tráfego imprevisível.
O modo de capacidade provisionada ajuda você a otimizar o preço do throughput se você tiver tráfego previsível de aplicativos e puder prever os requisitos de capacidade da sua tabela com antecedência. Com o modo de capacidade provisionada, você especifica o número de leituras e gravações por segundo que espera que seu aplicativo execute. Você pode aumentar e diminuir automaticamente a capacidade provisionada de sua tabela ativando o escalonamento automático.
Você pode alterar o modo de capacidade da sua tabela uma vez por dia à medida que aprende mais sobre os padrões de tráfego da sua workload ou se espera ter um grande aumento no tráfego, como devido a um grande evento que, segundo sua previsão, gerará muito tráfego na tabela. Para obter mais informações sobre unidades de capacidade de leitura e gravação, consulte Configurar modos de capacidade de leitura/gravação no Amazon Keyspaces.
O Amazon Keyspaces (para Apache Cassandra) armazena três cópias dos seus dados em várias Zonas de disponibilidade
O diagrama a seguir mostra a arquitetura do Amazon Keyspaces.
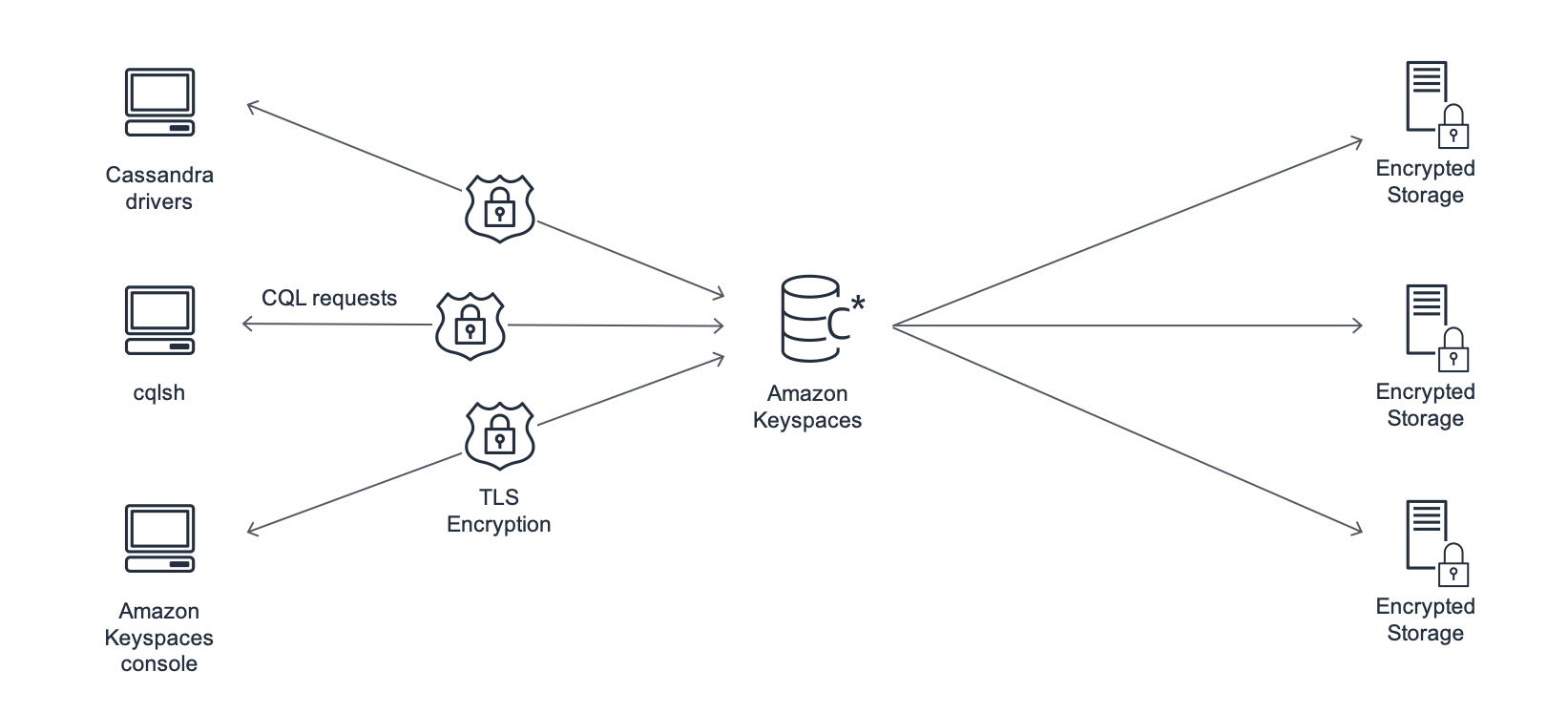
Um programa cliente acessa o Amazon Keyspaces conectando-se a um endpoint predeterminado (nome do host e número da porta) e emitindo instruções CQL. Para obter uma lista de endpoints disponíveis, consulte Endpoints de serviço para Amazon Keyspaces.
Modelo de dados do Cassandra
A forma como você modela seus dados para seu caso de negócios é fundamental para alcançar o desempenho ideal do Amazon Keyspaces. Um modelo de dados ruim pode degradar significativamente o desempenho.
Embora o CQL seja semelhante ao SQL, os backends do Cassandra e dos bancos de dados relacionais são muito diferentes e devem ser abordados de forma diferente. A seguir estão algumas das questões mais importantes a serem consideradas:
- Armazenamento
-
Você pode visualizar seus dados do Cassandra em tabelas, com cada linha representando um registro e cada coluna um campo dentro desse registro.
- Design da tabela: consulta primeiro
-
Não há
JOINs no CQL. Portanto, você deve criar suas tabelas com a forma dos seus dados e como você precisa acessá-los para seus casos de uso comercial. Isso pode resultar em desnormalização com dados duplicados. Você deve projetar cada uma de suas tabelas especificamente para um padrão de acesso específico. - Partições
-
Seus dados são armazenados em partições no disco. O número de partições em que seus dados são armazenados e como eles são distribuídos entre as partições é determinado pela sua chave de partição. A forma como você define sua chave de partição pode ter um impacto significativo no desempenho de suas consultas. Para ver as práticas recomendadas, consulte Como usar chaves de partição de forma eficaz no Amazon Keyspaces.
- Chave primária
-
No Cassandra, os dados são armazenados como um par de chave/valor. Cada tabela do Cassandra deve ter uma chave primária, que é a chave exclusiva para cada linha na tabela. A chave primária é composta por uma chave de partição necessária e uma ou mais colunas de clustering opcionais. Os dados que compõem a chave primária devem ser exclusivos em todos os registros de uma tabela.
-
Chave de partição: a parte da chave de partição da chave primária é necessária e determina em qual partição do cluster os dados são armazenados. A chave de partição pode ser uma única coluna ou um valor composto formado por duas ou mais colunas. Você usaria uma chave de partição composta se uma chave de partição de coluna única resultasse em uma única partição ou em poucas partições com a maioria dos dados e, portanto, suportasse a maioria das I/O operações de disco.
-
Coluna de clustering: a parte opcional da coluna de clustering de sua chave primária determina como os dados são agrupados e classificados em cada partição. Se você incluir uma coluna de clustering em sua chave primária, a coluna de clustering poderá ter uma ou mais colunas. Se houver várias colunas na coluna de clustering, a ordem de classificação será determinada pela ordem em que as colunas são listadas na coluna de clustering, da esquerda para a direita.
-
Para obter mais informações sobre o design do NoSQL e o Amazon Keyspaces, consulte Principais diferenças e princípios de design do NoSQL. Para obter mais informações sobre o Amazon Keyspaces e modelagem de dados, consulte Melhores práticas de modelagem de dados: recomendações para projetar modelos de dados.
Como acessar o Amazon Keyspaces a partir de um aplicativo
O Amazon Keyspaces (para Apache Cassandra) implementa a API Apache Cassandra Query Language (CQL), para que você possa usar os drivers CQL e Cassandra que você já usa. Atualizar seu aplicativo é tão fácil quanto atualizar o driver ou a configuração cqlsh do Cassandra para apontar para o endpoint do serviço Amazon Keyspaces. Para obter mais informações sobre as credenciais necessárias, consulte Crie e configure AWS credenciais para o Amazon Keyspaces.
nota
Para ajudar você a começar, você pode encontrar exemplos de end-to-end código de conexão com o Amazon Keyspaces usando vários drivers de cliente do Cassandra no repositório de exemplos de código do Amazon Keyspaces em. GitHub
Considere o seguinte programa Python, que se conecta a um cluster do Cassandra e consulta uma tabela.
from cassandra.cluster import Cluster #TLS/SSL configuration goes here ksp = 'MyKeyspace' tbl = 'WeatherData' cluster = Cluster(['NNN.NNN.NNN.NNN'], port=NNNN) session = cluster.connect(ksp) session.execute('USE ' + ksp) rows = session.execute('SELECT * FROM ' + tbl) for row in rows: print(row)
Para executar o mesmo programa no Amazon Keyspaces, você precisa:
-
Adicionar o endpoint e a porta do cluster: por exemplo, o host pode ser substituído por um endpoint de serviço, como
cassandra.us-east-2.amazonaws.come o número da porta por:9142. -
Adicione a TLS/SSL configuração: Para obter mais informações sobre como adicionar a TLS/SSL configuração para se conectar ao Amazon Keyspaces usando um driver Python do cliente Cassandra, consulte. Como usar um driver de cliente Cassandra Python para acessar o Amazon Keyspaces programaticamente
