As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Criação de um fluxo de trabalho
Antes de começar, verifique se você concedeu as permissões de dados e as permissões de localização de dados necessárias para a função LakeFormationWorkflowRole. Isso é para que o fluxo de trabalho possa criar tabelas de metadados no catálogo de dados e gravar dados em locais de destino no Amazon S3. Para obter mais informações, consulte (Opcional) Criar um perfil do IAM para fluxos de trabalho e Visão geral das permissões do Lake Formation .
nota
O Lake Formation usa as operações GetTemplateInstance, GetTemplateInstances e InstantiateTemplate para criar fluxos de trabalho com base em esquemas. Essas operações não estão disponíveis ao público e são usadas apenas internamente para criar recursos em seu nome. Você recebe CloudTrail eventos para criar fluxos de trabalho.
Para criar um fluxo de trabalho a partir de um esquema
-
Abra o AWS Lake Formation console em https://console.aws.amazon.com/lakeformation/
. Faça login como administrador do data lake ou como usuário com permissões de engenheiro de dados. Para obter mais informações, consulte Referência de personas e permissões do IAM do Lake Formation. -
No painel de navegação, selecione esquemas e escolha Usar esquema.
-
Na página Usar um esquema, escolha um quadro para selecionar o tipo de esquema.
-
Em Fonte de importação, especifique a fonte de dados.
Se você estiver importando de uma fonte JDBC, especifique o seguinte:
-
Conexão de banco de dados: escolha uma conexão na lista. Crie conexões adicionais usando o console do AWS Glue. O nome de usuário JDBC e a senha na conexão determinam os objetos do banco de dados aos quais o fluxo de trabalho tem acesso.
-
Caminho dos dados de origem — insira
<database><schema>//<table>ou<database>/<table>, dependendo do produto do banco de dados. Oracle Database e MySQL não oferecem suporte a esquema no caminho. Você pode substituir o caractere de porcentagem (%) por<schema>ou<table>. Por exemplo, para um banco de dados Oracle com um identificador de sistema (SID)orcl, informeorcl/%para importar todas as tabelas às quais o usuário nomeado na conexão tem acesso.Importante
Este campo diferencia letras maiúsculas de minúsculas. O fluxo de trabalho falhará se houver uma incompatibilidade de maiúsculas e minúsculas em qualquer um dos componentes.
Se você especificar um banco de dados MySQL, o AWS Glue ETL usa o driver JDBC Mysql5 por padrão, portanto, My não é suportado nativamente. SQL8 Você pode editar o script de trabalho ETL para usar um
customJdbcDriverS3Pathparâmetro conforme descrito em JDBC ConnectionType Values no Developer Guide para usar um driver AWS Glue JDBC diferente que suporte My. SQL8
Se você estiver importando de um arquivo de log, certifique-se de que a função especificada para o fluxo de trabalho (a “função do fluxo de trabalho”) tenha as permissões necessárias do IAM para acessar a fonte de dados. Por exemplo, para importar AWS CloudTrail registros, o usuário deve ter as
cloudtrail:LookupEventspermissõescloudtrail:DescribeTrailse para ver a lista de CloudTrail registros ao criar o fluxo de trabalho, e a função do fluxo de trabalho deve ter permissões no CloudTrail local no Amazon S3. -
-
Execute um destes procedimentos:
-
Para o tipo de esquema de instantâneo do banco de dados, identifique opcionalmente um subconjunto de dados a serem importados especificando um ou mais padrões de exclusão. Esses padrões de exclusão são padrões
globno estilo Unix. Elas são armazenadas como uma propriedade das tabelas criadas pelo fluxo de trabalho.Para obter detalhes sobre os padrões de exclusão disponíveis, consulte Incluir e excluir padrões no Guia do desenvolvedor do AWS Glue .
-
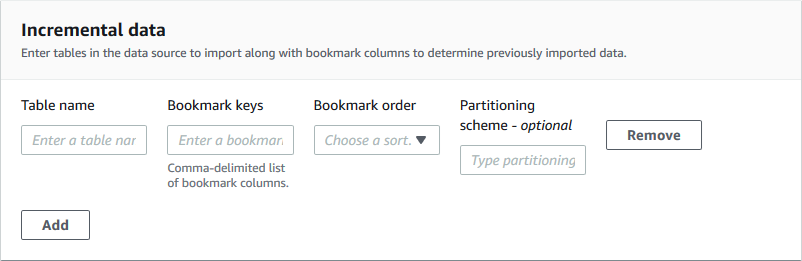
Para o tipo de esquema de banco de dados incremental, especifique os seguintes campos. Adicione uma linha para cada tabela a ser importada.
- Nome da tabela
-
Tabela a ser importada. Deve estar em letras minúsculas.
- Teclas de marcadores
-
Lista delimitada por vírgula dos nomes das colunas que definem as teclas dos favoritos. Se estiver em branco, a chave primária será usada para determinar novos dados. As maiúsculas e minúsculas de cada coluna devem corresponder às maiúsculas e minúsculas, conforme definido na fonte de dados.
nota
A chave primária se qualifica como a chave de bookmark padrão apenas se estiver aumentando ou diminuindo sequencialmente (sem lacunas). Se você quiser usar a chave primária como chave de marcador e ela tiver lacunas, você deverá nomear a coluna da chave primária como chave de marcador.
- Pedido de favoritos
-
Quando você escolhe Ascendente, as linhas com valores maiores que os marcados são identificadas como novas. Quando você escolhe Descendente, as linhas com valores menores que os valores marcados são identificadas como novas.
- Esquema de particionamento
-
(Opcional) Lista de colunas-chave de particionamento, delimitada por barras (/). Exemplo:
year/month/day.
Para obter mais informações, consulte Rastreamento de dados processados usando marcadores de trabalho no Guia do desenvolvedor do AWS Glue .
-
-
Em Importar destino, especifique o banco de dados de destino, a localização de destino do Amazon S3 e o formato dos dados.
Certifique-se de que a função do fluxo de trabalho tenha as permissões necessárias do Lake Formation no banco de dados e no local de destino do Amazon S3.
nota
Atualmente, os esquemas não oferecem suporte à criptografia de dados no destino.
-
Escolha uma frequência de importação.
Você pode especificar uma expressão
croncom a opção Personalizada. -
Em Opções de importação:
-
Insira um nome de fluxo de trabalho.
-
Para a função, escolha a função
LakeFormationWorkflowRole, que você criou em (Opcional) Criar um perfil do IAM para fluxos de trabalho. -
Opcionalmente, especifique um prefixo de tabela. O prefixo é anexado aos nomes das tabelas do catálogo de dados que o fluxo de trabalho cria.
-
-
Selecione Criar e aguarde até que o console informe que o fluxo de trabalho foi criado com sucesso.
dica
Você recebeu a seguinte mensagem de erro?
User: arn:aws:iam::<account-id>:user/<username>is not authorized to perform: iam:PassRole on resource:arn:aws:iam::<account-id>:role/<rolename>...Nesse caso, verifique se você
<account-id>substituiu por um número de AWS conta válido em todas as políticas.
Consulte também:
