Gerenciar dependências do Lambda com camadas
Uma camada do Lambda é um arquivo .zip que pode conter código ou dados adicionais. As camadas geralmente contêm dependências de biblioteca, um runtime personalizado ou arquivos de configuração.
Há vários motivos pelos quais você pode considerar o uso de camadas:
-
Para reduzir o tamanho de seus pacotes de implantação. Em vez de incluir todas as dependências da função junto com o código da função no pacote de implantação, coloque-as em uma camada. Isso mantém os pacotes de implantação pequenos e organizados.
-
Para separar a lógica da função central das dependências. Com camadas, você pode atualizar suas dependências de função independentemente do código da função, e vice-versa. Isso promove a separação de preocupações e ajuda você a se concentrar na lógica da sua função.
-
Para compartilhar dependências em várias funções. Depois de criar uma camada, você pode aplicá-la a qualquer número de funções em sua conta. Sem camadas, você precisa incluir as mesmas dependências em cada pacote de implantação individual.
-
Para usar o editor de código do console do Lambda. O editor de código é uma ferramenta útil para testar rapidamente pequenas atualizações de código de funções. No entanto, você não pode usar o editor se o tamanho do pacote de implantação for muito grande. O uso de camadas reduz o tamanho do pacote e pode desbloquear o uso do editor de código.
-
Para bloquear uma versão do SDK incorporado.Os SDKs incorporados podem ser alterados sem aviso prévio à medida que a AWS lança novos serviços e atributos. Você pode bloquear uma versão do SDK criando uma camada no Lambda com a versão específica necessária. Dessa forma, a função sempre usará a versão na camada, mesmo que a versão incorporada no serviço mude.
Se você estiver trabalhando com funções do Lambda em Go ou Rust, recomendamos não utilizar camadas. Para funções em Go e Rust, você fornece o código da sua função como um executável, que inclui o código da função compilado junto com todas as respectivas dependências. Colocar suas dependências em uma camada força sua função a carregar assemblies adicionais manualmente durante a fase inicial, o que pode aumentar os tempos de inicialização a frio. Para proporcionar a performance ideal para as funções em Go e Rust, inclua suas dependências junto com seu pacote de implantação.
O diagrama a seguir ilustra as diferenças arquitetônicas de alto nível entre duas funções que compartilham dependências. Uma usa camadas do Lambda e a outra, não.
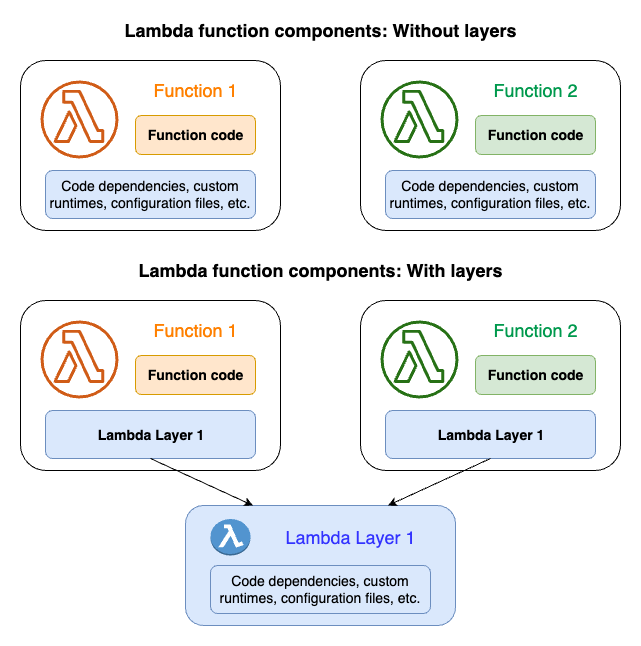
Quando você adiciona uma camada a uma função, o Lambda extrai o conteúdo da camada para o diretório /opt no ambiente de execução da sua função. Todos os runtimes do Lambda com suporte nativo incluem caminhos para diretórios específicos dentro do diretório /opt. Isso dá à sua função acesso ao conteúdo da camada. Para obter mais informações sobre esses caminhos específicos e como empacotar adequadamente suas camadas, consulte Empacotar seu conteúdo de camada.
Você pode incluir até cinco camadas por função. Também é possível usar camadas somente com funções do Lambda implantadas como um arquivo .zip. Para funções definidas como uma imagem de contêiner, empacote seu runtime preferido e todas as dependências de código ao criar a imagem de contêiner. Para obter mais informações, consulte Working with Lambda layers and extensions in container images
Tópicos
Como usar camadas
Para criar uma camada, empacote suas dependências em um arquivo .zip, da mesma forma como você cria um pacote de implantação normal. Mais especificamente, o processo geral de criação e o uso de camadas envolve estas três etapas:
-
Primeiro, empacote o conteúdo da camada. Isso significa criar um arquivo .zip. Para obter mais informações, consulte Empacotar seu conteúdo de camada.
-
Em seguida, crie a camada no Lambda. Para obter mais informações, consulte Criar e excluir camadas no Lambda.
-
Adicione a camada às funções). Para obter mais informações, consulte Adicionar camadas às funções.
Camadas e versões da camada
Uma versão da camada é um snapshot imutável de uma versão específica de uma camada. Quando você cria uma nova camada, o Lambda cria uma nova versão da camada com um número de versão de 1. Sempre que você publica uma atualização na camada, o Lambda incrementa o número da versão e cria uma nova versão da camada.
Cada versão da camada é identificada por um nome do recurso da Amazon (ARN) único. Ao adicionar uma camada à função, você deve especificar a versão exata da camada que deseja usar (por exemplo, arn:aws:lambda:us-east-1:123456789012:layer:my-layer:).1
