Configurar a simultaneidade provisionada para uma função
No Lambda, simultaneidade corresponde ao número de solicitações em andamento que a função está processando, no momento. Há dois tipos de controle de simultaneidade disponíveis:
-
Simultaneidade reservada: isso define o número máximo e mínimo de instâncias simultâneas alocadas à função. Quando uma função tem simultaneidade reservada, nenhuma outra função pode usar essa simultaneidade. A simultaneidade reservada é útil para garantir que suas funções mais críticas sempre tenham simultaneidade suficiente para lidar com as solicitações recebidas. Além disso, a simultaneidade reservada pode ser usada para limitar a simultaneidade e evitar a sobrecarga dos recursos subsequentes, como as conexões de banco de dados. A simultaneidade reservada atua como limite inferior e superior: ela reserva a capacidade especificada exclusivamente para a função e, ao mesmo tempo, impede que ela ultrapasse esse limite. Configurar a simultaneidade reservada para uma função não acarreta cobranças adicionais.
-
Simultaneidade provisionada: é o número de ambientes de execução inicializados previamente alocados para a função. Esses ambientes de execução estão prontos para responder imediatamente às solicitações de função de entrada. A simultaneidade provisionada é útil para reduzir as latências de inicialização a frio das funções e foi criada para tornar as funções disponíveis com tempos de resposta na ordem das dezenas de milissegundos. Geralmente, as workloads interativas são as que mais se beneficiam do recurso. São aplicações em que os usuários iniciam solicitações, como aplicações móveis e da Web, e que são mais sensíveis à latência. As workloads assíncronas, como pipelines de processamento de dados, costumam ser menos sensíveis à latência e, portanto, geralmente não precisam de simultaneidade provisionada. A configuração da simultaneidade provisionada gera cobranças na sua Conta da AWS.
Este tópico detalha como gerenciar e configurar a simultaneidade provisionada. Para uma visão geral conceitual desses dois tipos de controles de simultaneidade, consulte Simultaneidade reservada e simultaneidade provisionada. Para obter mais informações sobre a configuração de simultaneidade reservada, consulte Configurar a simultaneidade reservada para uma função.
nota
As funções do Lambda vinculadas a um mapeamento da origem do evento do Amazon MQ têm uma simultaneidade máxima padrão. Para o Apache Active MQ, o número máximo de instâncias simultâneas é 5. Para o Rabbit MQ, o número máximo de instâncias simultâneas é 1. Definir a simultaneidade reservada ou provisionada para a função não altera esses limites. Para solicitar um aumento na simultaneidade máxima padrão ao usar o Amazon MQ, entre em contato com Suporte.
Seções
Configurar a simultaneidade provisionada
Você pode definir configurações de simultaneidade provisionada para uma função usando o console do Lambda ou a API do Lambda.
Para alocar simultaneidade provisionada para uma função (console)
Abra a página Funções
do console do Lambda. -
Escolha a função para a qual você deseja alocar a simultaneidade provisionada.
-
Escolha Configuration (Configuração) e escolha (Concurrency (Simultaneidade).
-
Em Provisioned concurrency configurations (Configurações de simultaneidade provisionada), escolha Add configuration (Adicionar configuração).
-
Escolha o tipo de qualificador e o alias ou a versão.
nota
Você não pode usar simultaneidade provisionada com a versão $LATEST de qualquer função.
Se a função tiver uma origem de evento, certifique-se de que a origem de evento aponte para o alias ou a versão correta da função. Caso contrário, a função não usará ambientes de simultaneidade provisionada.
-
Insira um número em Simultaneidade provisionada.
-
Escolha Salvar.
Você pode configurar até a Simultaneidade de conta não reservada na sua conta, menos 100. As 100 unidades restantes de simultaneidade se destinam a funções que não estão usando simultaneidade reservada. Por exemplo, se sua conta tem um limite de simultaneidade de 1 mil e você não atribuiu qualquer simultaneidade reservada ou provisionada a qualquer uma das outras funções, você pode configurar no máximo 900 unidades de simultaneidade provisionada para uma única função.
Configurar simultaneidade provisionada para uma função causa um impacto no grupo de simultaneidades disponíveis para outras funções. Por exemplo, se você configurar 100 unidades de simultaneidade provisionada para a function-a, outras funções da sua conta deverão compartilhar as 900 unidades restantes de simultaneidade. Isso ocorrerá mesmo se a function-a não usar todas as 100 unidades.
É possível alocar tanto a simultaneidade reservada como a provisionada para a mesma função. Nesses casos, a simultaneidade provisionada não pode exceder a simultaneidade reservada.
Essa limitação se estende às versões da função. A simultaneidade máxima provisionada que você pode atribuir a uma versão de função específica é igual à simultaneidade reservada da função menos a simultaneidade provisionada em outras versões da função.
Para configurar a simultaneidade provisionada com a API do Lambda, use as operações da API a seguir.
Por exemplo, para configurar a simultaneidade provisionada com a AWS Command Line Interface (CLI), use o comando put-provisioned-concurrency-config. O comando a seguir aloca 100 unidades de simultaneidade provisionada para o alias BLUE de uma função chamada my-function:
aws lambda put-provisioned-concurrency-config --function-name my-function \ --qualifier BLUE \ --provisioned-concurrent-executions 100
Você observará um resultado parecido com o seguinte:
{ "Requested ProvisionedConcurrentExecutions": 100, "Allocated ProvisionedConcurrentExecutions": 0, "Status": "IN_PROGRESS", "LastModified": "2023-01-21T11:30:00+0000" }
Estimar a simultaneidade provisionada necessária com precisão para uma função
Você pode visualizar as métricas de simultaneidade de qualquer função ativa usando as métricas do CloudWatch. Especificamente, a métrica ConcurrentExecutions apresenta o número de invocações simultâneas para as funções da conta.
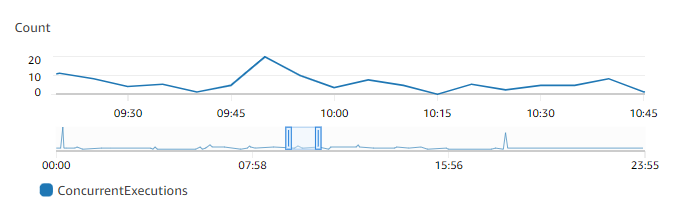
O gráfico anterior sugere que essa função atende a uma média de cinco a dez solicitações simultâneas em qualquer ocasião e atinge o pico de 20 solicitações. Suponha que existam muitas outras funções na sua conta. Se essa função for essencial para sua aplicação e você precisar de uma resposta de baixa latência em cada invocação, configure pelo menos 20 unidades de simultaneidade provisionada.
Lembre-se de que você também pode calcular a simultaneidade usando a seguinte fórmula:
Concurrency = (average requests per second) * (average request duration in seconds)
Para estimar quanto de simultaneidade você precisa, multiplique a média de solicitações por segundo pela duração média das solicitações em segundos. É possível estimar a média de solicitações por segundo usando a métrica Invocation e a duração média da solicitação em segundos usando a métrica Duration.
Quando você configura simultaneidade provisionada, o Lambda sugere a adição de uma reserva de 10% na quantidade de simultaneidade de que a função normalmente precisa. Por exemplo, se a função geralmente atinge o pico de 200 solicitações simultâneas, defina a simultaneidade provisionada como 220 (200 solicitações simultâneas + 10% = 220 de simultaneidade provisionada).
Otimizar o código da função ao usar a simultaneidade provisionada
Se você estiver usando simultaneidade provisionada, considere reestruturar o código da função para otimizar a baixa latência. Para funções que usam simultaneidade provisionada, o Lambda executa qualquer código de inicialização, como o carregamento de bibliotecas e a criação de instâncias de clientes) no momento da alocação. Portanto, é aconselhável mover o máximo de inicialização para fora do manipulador da função principal para evitar afetar a latência durante as invocações reais da função. Por outro lado, a inicialização de bibliotecas ou a criação de instâncias de clientes no código do manipulador principal significa que a função precisará executar isso toda vez que for invocada (isso ocorre independentemente de você estar ou não usando simultaneidade provisionada).
Para invocações sob demanda, o Lambda pode precisar executar novamente o código de inicialização sempre que a função passar por uma inicialização a frio. Para essas funções, você pode optar por adiar a inicialização de um recurso específico até que a função precise dele. Por exemplo, considere o seguinte fluxo de controle para um manipulador do Lambda:
def handler(event, context): ... if ( some_condition ): // Initialize CLIENT_A to perform a task else: // Do nothing
No exemplo anterior, em vez de inicializar o CLIENT_A fora do manipulador principal, o desenvolvedor realizou a inicialização com a instrução if. Ao fazer isso, o Lambda só executará esse código se some_condition for satisfeito. Se o autor inicializar CLIENT_A fora do manipulador principal, o Lambda executará esse código em cada inicialização a frio. Isso pode aumentar a latência geral.
Você pode medir as inicializações a frio durante o aumento de escala do Lambda adicionando o monitoramento do X-Ray à sua função. Uma função que usa a simultaneidade provisionada não apresenta comportamento de inicialização a frio, pois o ambiente de execução é preparado antes da invocação. No entanto, a simultaneidade provisionada deve ser aplicada a uma versão ou alias específico de uma função, e não à versão $LATEST. Nos casos em que você continuar observando o comportamento de inicialização a frio, certifique-se de invocar a versão do alias com a simultaneidade provisionada configurada.
Usar variáveis de ambiente para visualizar e controlar o comportamento da simultaneidade provisionada
É possível que a função use toda a simultaneidade provisionada. O Lambda usa instâncias sob demanda para lidar com qualquer excesso de tráfego. Para determinar o tipo de inicialização que o Lambda usou para um ambiente específico, verifique o valor da variável de ambiente AWS_LAMBDA_INITIALIZATION_TYPE. Essa variável tem dois valores possíveis: provisioned-concurrency ou on-demand. O valor de AWS_LAMBDA_INITIALIZATION_TYPE é imutável e permanece constante durante toda a vida útil do ambiente. Para verificar o valor de uma variável de ambiente no código da função, consulte Recuperar variáveis de ambiente do Lambda.
Se você estiver usando os runtimes do .NET 8, poderá configurar a variável de ambiente AWS_LAMBDA_DOTNET_PREJIT para melhorar a latência das funções, mesmo se elas não usarem simultaneidade provisionada. O runtime do .NET emprega compilação e inicialização lentas para cada biblioteca que o código chama pela primeira vez. Como resultado, a primeira invocação de uma função do Lambda pode levar mais tempo do que as subsequentes. Para mitigar isso, é possível escolher um dos três valores para AWS_LAMBDA_DOTNET_PREJIT:
-
ProvisionedConcurrency: o Lambda executa a compilação JIT antecipada para todos os ambientes usando simultaneidade provisionada. Este é o valor padrão. -
Always: o Lambda executa a compilação JIT antecipada para cada ambiente, mesmo que a função não use simultaneidade provisionada. -
Never: o Lambda desativa a compilação JIT antecipada para todos os ambientes.
Entender o comportamento de log e cobrança com simultaneidade provisionada
Para instâncias de simultaneidade provisionada, o código de inicialização da função é executado durante a alocação e periodicamente, quando o Lambda recicla as instâncias do ambiente. O Lambda cobra pela inicialização mesmo que a instância de ambiente nunca processe uma solicitação. A simultaneidade provisionada é executada continuamente e gera um faturamento separado dos custos de inicialização e de invocação. Para obter mais detalhes, consulte Preço do AWS Lambda
Quando você configura uma função do Lambda com simultaneidade provisionada, o Lambda pré-inicializa esse ambiente de execução para que ele esteja disponível antes das solicitações de invocação. O Lambda registra o campo Init Duration da função em um evento de logs platform-initReport no formato de registro em log JSON toda vez que o ambiente é inicializado. Para ver esse evento de logs, configure seu nível de log JSON para pelo menos INFO. Você também pode usar a API de telemetria para consumir eventos da plataforma em que o campo Init Duration é relatado.
Usar o ajuste de escala automático de aplicações para automatizar o gerenciamento da simultaneidade provisionada
Você pode usar o Application Auto Scaling para gerenciar a simultaneidade provisionada em uma programação ou com base na utilização. Se a função receber padrões previsíveis de tráfego, use ajuste de escala programado. Se você deseja que a função mantenha uma porcentagem de utilização específica, use uma política de ajuste de escala de rastreamento de destino.
nota
Se você usar o Application Auto Scaling para gerenciar a simultaneidade provisionada da sua função, certifique-se primeiro de configurar um valor inicial de simultaneidade provisionada. Se sua função não tiver um valor inicial de simultaneidade provisionada, o Application Auto Scaling pode não lidar adequadamente com a escalabilidade de funções.
Escalabilidade programada
Com o Application Auto Scaling, você pode definir sua própria programação de ajuste de escala de acordo com alterações de carga previsíveis. Para obter mais informações e exemplos, consulte Ajuste de escala programado para o Application Auto Scaling no Guia do usuário do Application Auto Scaling e Programar simultaneidade provisionada do AWS Lambda para picos recorrentes de uso
Monitoramento do objetivo
Com o rastreamento de destino, o Application Auto Scaling cria e gerencia um conjunto de alarmes do CloudWatch com base na maneira como você define sua política de ajuste de escala. Quando esses alarmes são ativados, o Application Auto Scaling ajusta automaticamente a quantidade de ambientes alocados usando simultaneidade provisionada. Use rastreamento de destino para aplicações que não têm padrões de tráfego previsíveis.
Para ajustar a escala da simultaneidade provisionada usando o rastreamento de destino, use as operações da API do Application Auto Scaling RegisterScalableTarget e PutScalingPolicy. Por exemplo, se você estiver usando a AWS Command Line Interface (CLI), siga estas etapas:
-
Registre o alias de uma função como um destino de escalabilidade. O exemplo a seguir registra o alias BLUE de uma função denominada
my-function:aws application-autoscaling register-scalable-target --service-namespace lambda \ --resource-id function:my-function:BLUE --min-capacity 1 --max-capacity 100 \ --scalable-dimension lambda:function:ProvisionedConcurrency -
Aplique uma política de escalabilidade ao destino. O exemplo a seguir configura o Application Auto Scaling para ajustar a configuração de simultaneidade provisionada para um alias a fim de manter a utilização próxima de 70%, mas é possível aplicar qualquer valor entre 10% e 90%.
aws application-autoscaling put-scaling-policy \ --service-namespace lambda \ --scalable-dimension lambda:function:ProvisionedConcurrency \ --resource-id function:my-function:BLUE \ --policy-name my-policy \ --policy-type TargetTrackingScaling \ --target-tracking-scaling-policy-configuration '{ "TargetValue": 0.7, "PredefinedMetricSpecification": { "PredefinedMetricType": "LambdaProvisionedConcurrencyUtilization" }}'
Você deve ver uma saída semelhante a:
{ "PolicyARN": "arn:aws:autoscaling:us-east-2:123456789012:scalingPolicy:12266dbb-1524-xmpl-a64e-9a0a34b996fa:resource/lambda/function:my-function:BLUE:policyName/my-policy", "Alarms": [ { "AlarmName": "TargetTracking-function:my-function:BLUE-AlarmHigh-aed0e274-xmpl-40fe-8cba-2e78f000c0a7", "AlarmARN": "arn:aws:cloudwatch:us-east-2:123456789012:alarm:TargetTracking-function:my-function:BLUE-AlarmHigh-aed0e274-xmpl-40fe-8cba-2e78f000c0a7" }, { "AlarmName": "TargetTracking-function:my-function:BLUE-AlarmLow-7e1a928e-xmpl-4d2b-8c01-782321bc6f66", "AlarmARN": "arn:aws:cloudwatch:us-east-2:123456789012:alarm:TargetTracking-function:my-function:BLUE-AlarmLow-7e1a928e-xmpl-4d2b-8c01-782321bc6f66" } ] }
O Application Auto Scaling cria dois alarmes no CloudWatch. O primeiro alarme será acionado quando a utilização da simultaneidade provisionada exceder consistentemente 70%. Quando isso acontecer, o Application Auto Scaling alocará mais simultaneidade provisionada para reduzir a utilização. O segundo alarme será acionado quando a utilização for consistentemente inferior a 63% (90% da meta de 70%). Quando isso acontecer, o Application Auto Scaling reduzirá a simultaneidade provisionada do alias.
nota
O Lambda emite a métrica ProvisionedConcurrencyUtilization apenas quando sua função está ativa e recebendo solicitações. Durante períodos de inatividade, nenhuma métrica é emitida e seus alarmes de ajuste de escala automático entram no estado INSUFFICIENT_DATA. Como resultado, o ajuste de escala automático da aplicação não será capaz de ajustar a simultaneidade provisionada da sua função. Isso pode gerar cobranças inesperadas.
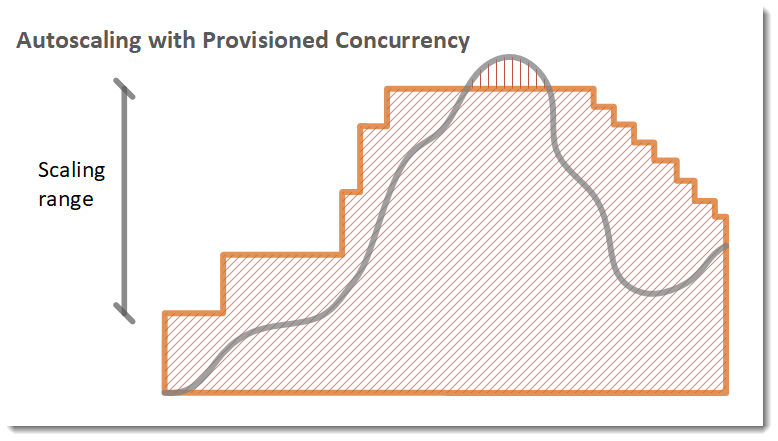
No exemplo a seguir, uma função é dimensionada entre uma quantidade mínima e máxima de simultaneidade provisionada com base na utilização.
Legenda
-
 Instâncias de função
Instâncias de função -
 Solicitações abertas
Solicitações abertas -
 Simultaneidade provisionada
Simultaneidade provisionada -
 Simultaneidade padrão
Simultaneidade padrão
Quando o número de solicitações abertas aumenta, o Application Auto Scaling aumenta a simultaneidade provisionada em grandes etapas até atingir o máximo configurado. Depois disso, a função poderá continuar a ajustar a escala com base na simultaneidade padrão não reservada se você não tiver atingido o limite de simultaneidade da conta. Quando a utilização diminui e permanece baixa, o Application Auto Scaling diminui a simultaneidade provisionada em etapas periódicas menores.
Os dois alarmes do Application Auto Scaling usam a estatística média por padrão. Funções que sofrem intermitências rápidas de tráfego podem não acionar esses alarmes. Por exemplo, suponha que a função do Lambda seja executada rapidamente (ou seja, entre 20 e 100 ms) e o tráfego ocorra em intermitências rápidas. Nesse caso, o número de solicitações excede a simultaneidade provisionada alocada durante a intermitência. No entanto, o Application Auto Scaling exige que a carga de intermitência seja mantida por pelo menos três minutos para provisionar ambientes adicionais. Além disso, os dois alarmes do CloudWatch exigem três pontos de dados que atinjam a média de destino para ativar a política de ajuste de escala automático. Se sua função apresentar picos rápidos de tráfego, o uso da estatística Máxima em vez da estatística Média pode ser mais eficaz no escalonamento da simultaneidade provisionada a fim de minimizar as inicializações a frio.
Para obter mais informações sobre políticas de ajuste de escala de rastreamento de destino, consulte Políticas de ajuste de escala de rastreamento de destino para o Application Auto Scaling.
