As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Pontos de verificação
Os pontos de verificação são o mecanismo do Flink para garantir que o estado de um aplicativo seja tolerante a falhas. O mecanismo permite que o Flink recupere o estado dos operadores se a tarefa falhar e fornece ao aplicativo a mesma semântica da execução sem falhas. Com o Managed Service for Apache Flink, o estado de um aplicativo é armazenado no RocksDB, um key/value armazenamento incorporado que mantém seu estado de funcionamento em disco. Quando um ponto de verificação é usado, o estado também é carregado no Amazon S3. Portanto, mesmo que o disco seja perdido, o ponto de verificação pode ser usado para restaurar o estado do aplicativo.
Para obter mais informações, consulte Como o snapshot de estado funciona?
Estágios do ponto de verificação
Para uma subtarefa de operador de ponto de verificação no Flink, há 5 estágios principais:
Aguardando [Atraso inicial]: o Flink usa barreiras de ponto de verificação que são inseridas no fluxo, então o tempo neste estágio é o tempo em que o operador espera que a barreira do ponto de verificação chegue até ela.
Alinhamento [Duração do alinhamento]: nesse estágio, a subtarefa atingiu uma barreira, mas está aguardando barreiras de outros fluxos de entrada.
Ponto de verificação de sincronização [Duração da sincronização]: esse estágio é quando a subtarefa realmente captura o estado do operador e bloqueia todas as outras atividades na subtarefa.
Ponto de verificação de assincronia [Duração da assincronia]: a maior parte desse estágio é a subtarefa de fazer o upload do estado para o Amazon S3. Durante esse estágio, a subtarefa não está mais bloqueada e pode processar registros.
Reconhecer — Geralmente é um estágio curto e é simplesmente a subtarefa de enviar uma confirmação para o JobManager e também realizar qualquer mensagem de confirmação (por exemplo, com coletores Kafka).
Cada um desses estágios (exceto Confirmação) é mapeado para uma métrica de duração para pontos de verificação que está disponível no Flink WebUI, o que pode ajudar a isolar a causa do longo ponto de verificação.
Para ver uma definição exata de cada uma das métricas disponíveis nos pontos de verificação, acesse a guia Histórico
Investigar
Ao investigar a duração longa do ponto de verificação, a coisa mais importante a determinar é o gargalo do ponto de verificação, ou seja, qual operador e subtarefa estão demorando mais até o ponto de verificação e qual estágio dessa subtarefa está levando um período de tempo longo. Isso pode ser determinado usando o Flink WebUI na tarefa de ponto de verificação das tarefas. A interface web do Flink fornece dados e informações que ajudam a investigar problemas de ponto de verificação. Para obter uma análise completa, consulte Monitoramento de pontos de verificação.
A primeira coisa a observar é a duração de ponta a ponta de cada operador no gráfico de tarefas para determinar qual operador está demorando até o ponto de verificação e merece uma investigação mais aprofundada. De acordo com a documentação do Flink, a definição da duração é:
A duração do timestamp do acionador até a confirmação mais recente (ou n/a se nenhuma confirmação foi recebida ainda). Essa duração de ponta a ponta para um ponto de verificação completo é determinada pela última subtarefa que reconhece o ponto de verificação. Esse tempo geralmente é maior do que as subtarefas individuais necessárias para realmente verificar o estado.
As outras durações do ponto de verificação também fornecem informações mais detalhadas sobre onde o tempo está sendo gasto.
Se a Duração da sincronização for alta, isso indica que algo está acontecendo durante o instantâneo. Durante esse estágio, snapshotState() é chamado para classes que implementam a interface SnapshotState; isso pode ser um código de usuário, portanto, os despejos de thread podem ser úteis para investigar isso.
Uma Duração da assincronia longa sugere que muito tempo está sendo gasto no upload do estado para o Amazon S3. Isso pode ocorrer se o estado for grande ou se houver muitos arquivos de estado sendo carregados. Se esse for o caso, vale a pena investigar como o estado está sendo usado pelo aplicativo e garantir que as estruturas de dados nativas do Flink estejam sendo usadas sempre que possível (Uso do estado com chave
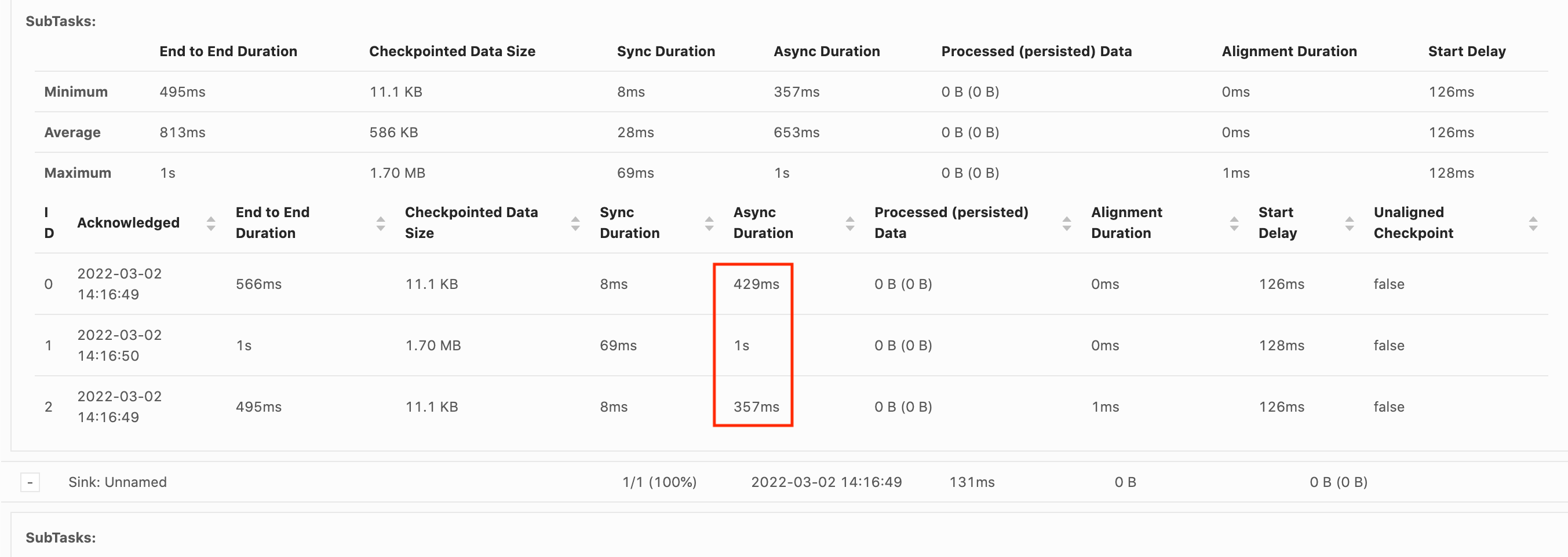
O Atraso inicial alto mostra que a maior parte do tempo está sendo gasta esperando que a barreira do ponto de verificação chegue ao operador. Isso indica que o aplicativo está demorando um pouco para processar os registros, o que significa que a barreira está fluindo lentamente pelo gráfico de tarefas. Geralmente, esse é o caso se a tarefa estiver sob contrapressão ou se um ou mais operadores estiverem constantemente ocupados. Veja a seguir um exemplo de um JobGraph em que o segundo KeyedProcess operador está ocupado.
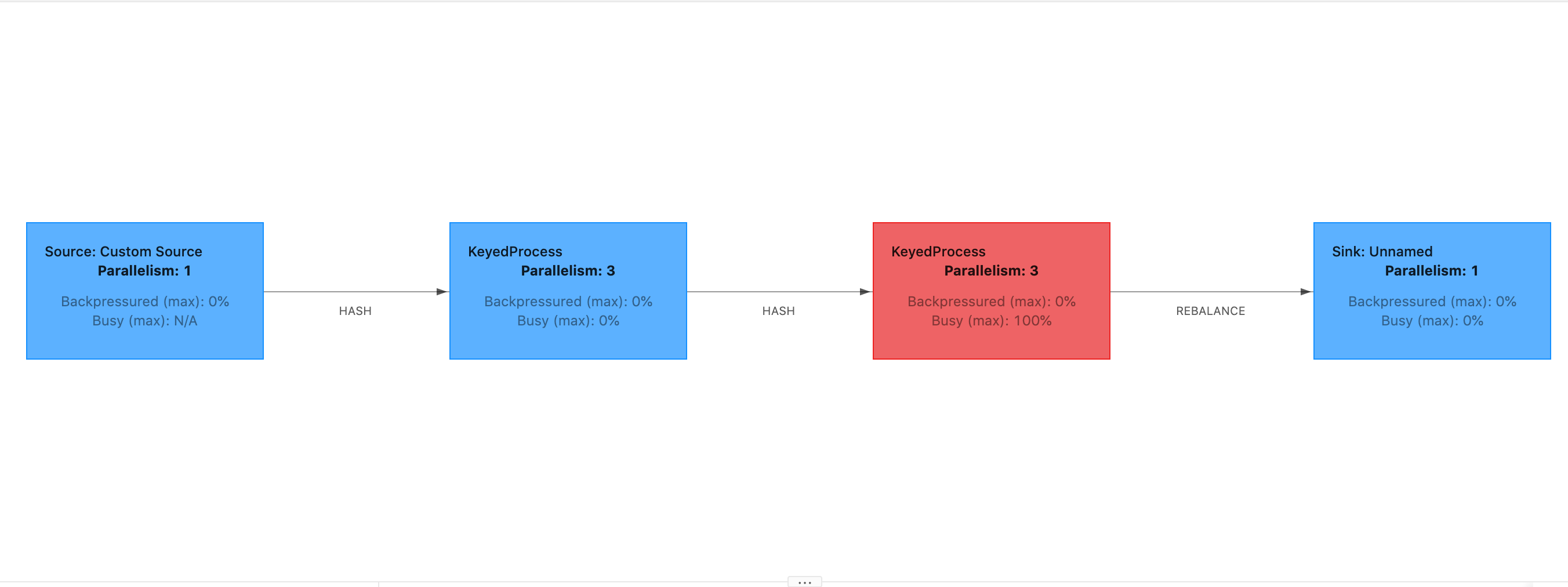
Você pode investigar o que está demorando tanto usando Flink Flame Graphs ou TaskManager thread dumps. Uma vez identificado o gargalo, ele pode ser investigado mais detalhadamente usando o Flame graphs ou despejos de thread.
Despejos de thread
Os despejos de thread são outra ferramenta de depuração que está em um nível um pouco mais baixo do que o Flame graphs. Um despejo de thread gera o estado de execução de todos os threads em um determinado momento. O Flink usa um despejo de thread JVM, que é um estado de execução de todos os threads no processo do Flink. O estado de um thread é apresentado por um rastreamento de pilha do thread, bem como por algumas informações adicionais. Na verdade, os Flame graphs são criados usando vários rastreamentos de pilha obtidos em rápida sucessão. O gráfico é uma visualização feita a partir desses traços que facilita a identificação dos caminhos de código comuns.
"KeyedProcess (1/3)#0" prio=5 Id=1423 RUNNABLE at app//scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:154) at $line33.$read$$iw$$iw$ExpensiveFunction.processElement(<console>>19) at $line33.$read$$iw$$iw$ExpensiveFunction.processElement(<console>:14) at app//org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:83) at app//org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:205) at app//org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.processElement(AbstractStreamTaskNetworkInput.java:134) at app//org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.emitNext(AbstractStreamTaskNetworkInput.java:105) at app//org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:66) ...
Acima está um trecho de um despejo de thread retirado da interface do usuário do Flink para um único thread. A primeira linha contém algumas informações gerais sobre esse thread, incluindo:
O nome do tópico KeyedProcess (1/3) #0
Prioridade do thread prio=5
Uma ID de thread exclusiva Id=1423
Estado do thread EXECUTÁVEL
O nome de um thread geralmente fornece informações sobre o propósito geral do thread. Os encadeamentos do operador podem ser identificados pelo nome, pois os encadeamentos do operador têm o mesmo nome do operador, bem como uma indicação da subtarefa à qual estão relacionados, por exemplo, o encadeamento KeyedProcess (1/3) #0 é do KeyedProcessoperador e da 1ª (de 3) subtarefa.
Os threads podem estar em um dos seguintes estados:
NOVO: o thread foi criado, mas ainda não foi processado
EXECUTÁVEL: o thread é executado na CPU
BLOQUEADO: o thread está esperando que outro thread libere seu bloqueio
AGUARDANDO: o thread está aguardando usando um método
wait(),join()oupark()TEMPORIZADO_AGUARDANDO: o thread está aguardando usando um método sleep, wait, join ou park, mas com um tempo de espera máximo.
nota
No Flink 1.13, a profundidade máxima de um único rastreamento de pilha no despejo de thread é limitada a 8.
nota
Os despejos de thread devem ser o último recurso para depurar problemas de desempenho em um aplicativo Flink, pois podem ser difíceis de ler e exigem que várias amostras sejam coletadas e analisadas manualmente. Se possível, é preferível usar Flame graphs.
Despejos de thread no Flink
No Flink, um despejo de thread pode ser feito escolhendo a opção Gerenciadores de tarefas na barra de navegação esquerda da interface do usuário do Flink, selecionando um gerenciador de tarefas específico e navegando até a guia Despejo de thread. O despejo de thread pode ser baixado, copiado para seu editor de texto (ou analisador de thread dump) favorito ou analisado diretamente na visualização de texto na interface do usuário Web do Flink (no entanto, essa última opção pode ser um pouco complicada.
Para determinar qual gerenciador de tarefas usar, um despejo de tópicos da TaskManagersguia pode ser usado quando um determinado operador é escolhido. Isso mostra que o operador está sendo executado em diferentes subtarefas de um operador e pode ser executado em diferentes gerenciadores de tarefas.
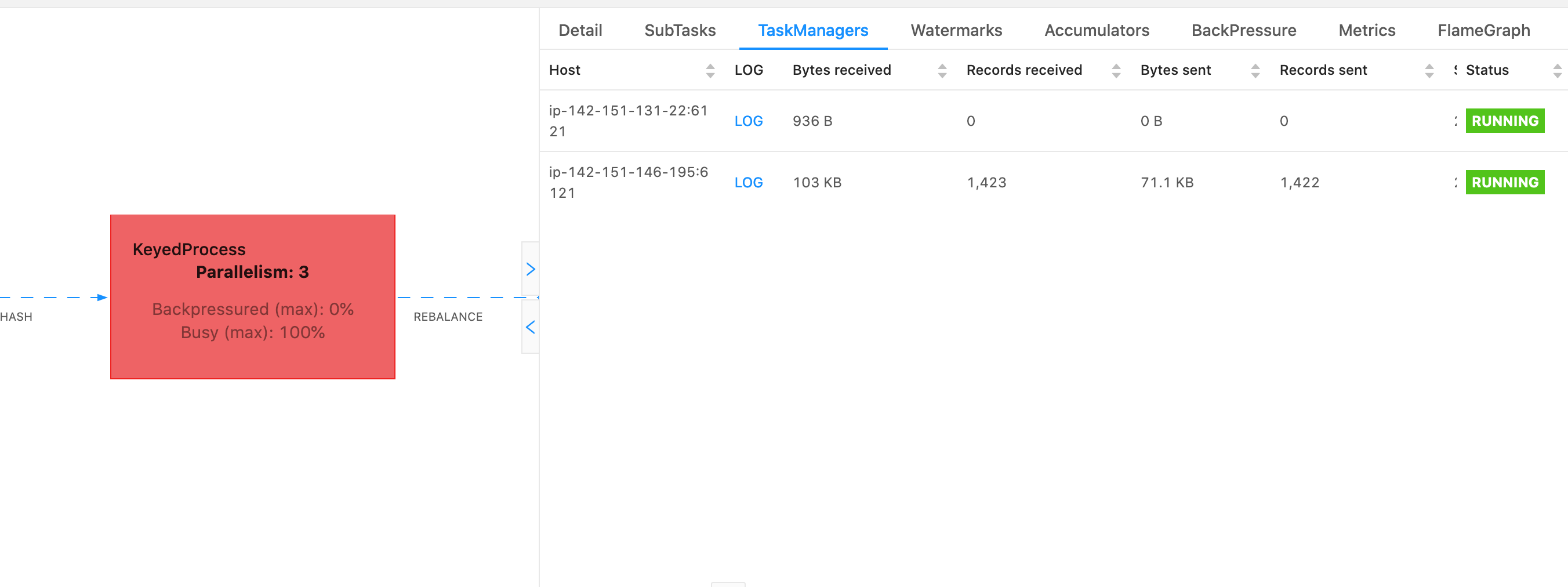
O dump será composto por vários rastreamentos de pilha. No entanto, ao investigar o dump, os relacionados a um operador são os mais importantes. Eles podem ser facilmente encontrados, pois os threads do operador têm o mesmo nome do operador, bem como uma indicação da subtarefa à qual estão relacionados. Por exemplo, o rastreamento de pilha a seguir é do KeyedProcessoperador e é a primeira subtarefa.
"KeyedProcess (1/3)#0" prio=5 Id=595 RUNNABLE at app//scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:155) at $line360.$read$$iw$$iw$ExpensiveFunction.processElement(<console>:19) at $line360.$read$$iw$$iw$ExpensiveFunction.processElement(<console>:14) at app//org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:83) at app//org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:205) at app//org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.processElement(AbstractStreamTaskNetworkInput.java:134) at app//org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.emitNext(AbstractStreamTaskNetworkInput.java:105) at app//org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:66) ...
Isso pode se tornar confuso se houver vários operadores com o mesmo nome, mas podemos nomear operadores para contornar isso. Por exemplo:
.... .process(new ExpensiveFunction).name("Expensive function")
Flame graphs
Os Flame graphs são uma ferramenta de depuração útil que visualiza os rastreamentos da pilha do código de destino, o que permite identificar os caminhos de código mais frequentes. Eles são criados por meio de rastreamentos de pilha de amostras várias vezes. O eixo x de um Flame graph mostra os diferentes perfis da pilha, enquanto o eixo y mostra a profundidade da pilha e chama o rastreamento da pilha. Um único retângulo em um Flame graph representa uma estrutura de pilha, e a largura de uma chama mostra com que frequência ela aparece nas pilhas. Para obter mais detalhes sobre os Flame graphs e como usá-los, consulte Flame graphs
No Flink, o gráfico de chama de um operador pode ser acessado por meio da interface do usuário da Web selecionando um operador e, em seguida, escolhendo a FlameGraphguia. Depois que amostras suficientes forem coletadas, o Flame graph será exibido. A seguir está a FlameGraph versão ProcessFunction que estava demorando muito para chegar ao posto de controle.
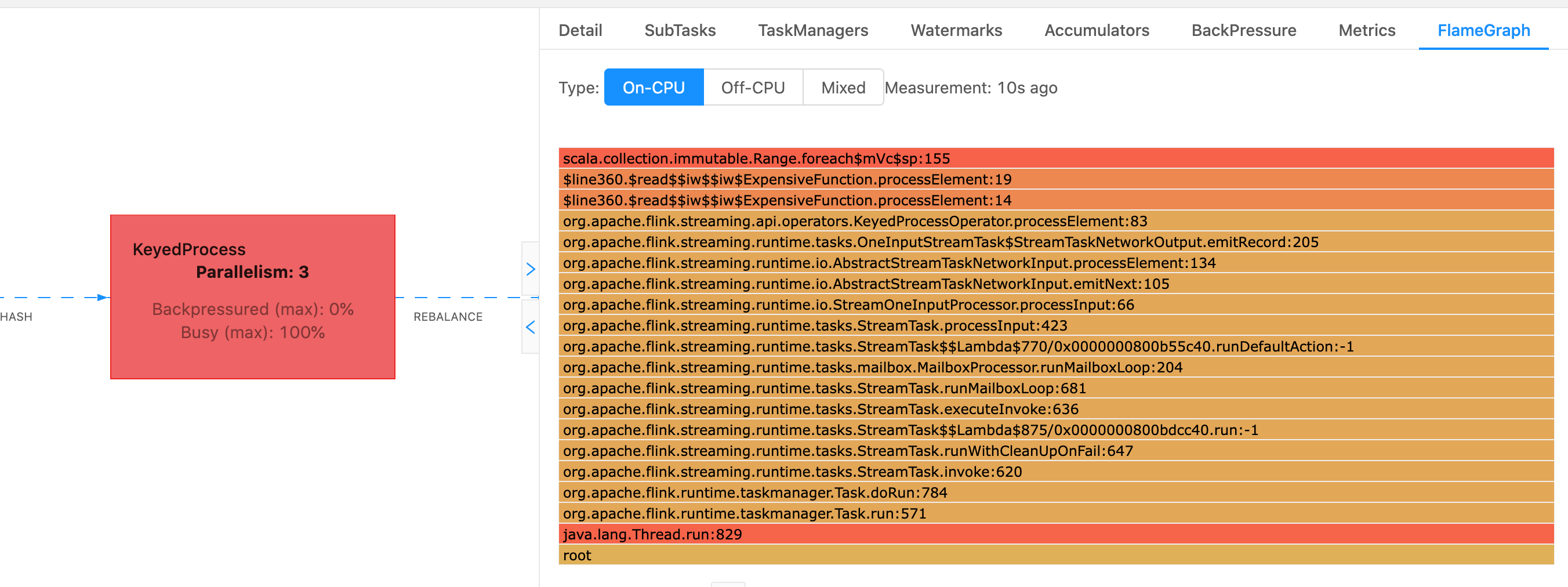
Este é um gráfico de chama muito simples e mostra que todo o tempo de CPU está sendo gasto em uma visão geral processElement do ExpensiveFunction operador. Você também obtém o número da linha para ajudar a determinar onde a execução do código está ocorrendo.
