As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
O que é Amazon Managed Service for Apache Flink?
Com o Amazon Managed Service for Apache Flink, você pode usar Java, Scala, Python ou SQL para processar e analisar dados em transmissão. O serviço permite que você crie e execute código Java em fontes de transmissão e fontes estáticas para realizar analytics de séries temporais, alimentar painéis em tempo real e criar métricas.
É possível criar aplicações com a linguagem de sua escolha no Managed Service for Apache Flink usando bibliotecas de código aberto baseadas no Apache Flink
O Managed Service for Apache Flink fornece a infraestrutura subjacente para seus aplicativos Apache Flink. Ele lida com os principais recursos, como provisionamento de recursos computacionais, resiliência de failover AZ, computação paralela, escalabilidade automática e backups de aplicativos (implementados como pontos de verificação e instantâneos). Você pode usar os recursos de programação de alto nível do Flink (como operadores, funções, fontes e coletores) da mesma forma que os usa ao hospedar você mesmo a infraestrutura do Flink.
Decida se vai utilizar o Managed Service for Apache Flink ou o Managed Service for Apache Flink Studio
Você tem duas opções para executar suas tarefas do Flink com o Amazon Managed Service for Apache Flink. Com o Managed Service for Apache Flink, você cria aplicativos Flink em Java, Scala ou Python (e SQL incorporado) usando um IDE de sua escolha e as APIs Datastream ou Table do Apache Flink. Com o Managed Service for Apache Flink Studio você pode consultar interativamente fluxos de dados em tempo real e crie e execute facilmente aplicativos de processamento de fluxo usando SQL, Python e Scala padrão.
É possível selecionar qual método é mais adequado ao seu caso de uso. Se você não tiver certeza, esta seção oferece orientação de alto nível para ajudá-lo.

Antes de decidir se vai usar o Amazon Managed Service for Apache Flink ou o Amazon Managed Service for Apache Flink Studio, você deve considerar seu caso de uso.
Se você planeja operar um aplicativo de longa execução que executará cargas de trabalho como Streaming ETL ou Continuous Applications, considere usar o Managed Service for Apache Flink. Isso ocorre porque você pode criar seu aplicativo Flink usando as APIs do Flink diretamente no IDE de sua escolha. Desenvolver localmente com seu IDE também garante que você possa aproveitar processos e ferramentas comuns do ciclo de vida de desenvolvimento de software (SDLC), como controle de versão de código no Git, automação ou teste unitário. CI/CD
Se você estiver interessado na exploração de dados ad-hoc, quiser consultar dados de transmissão de forma interativa ou criar painéis privados em tempo real, o Managed Service for Apache Flink Studio ajudará você a atingir essas metas com apenas alguns cliques. Usuários acostumados com o SQL podem considerar a implantação de um aplicativo de longa execução diretamente do Studio.
nota
É possível promover seu notebook Studio em um aplicativo de longa duração. No entanto, se você quiser se integrar às suas ferramentas do SDLC, como controle de versão de código no Git CI/CD e automação, ou técnicas como teste unitário, recomendamos o Managed Service for Apache Flink usando o IDE de sua escolha.
Escolha quais APIs do Apache Flink usar no Managed Service for Apache Flink
Você pode criar aplicações usando Java, Python e Scala no Managed Service for Apache Flink usando as APIs do Apache Flink em um IDE de sua escolha. Você pode encontrar orientações sobre como criar aplicativos usando a API Flink Datastream and Table na documentação. É possível selecionar o idioma no qual você cria seu aplicativo Flink e as APIs usadas para melhor atender às necessidades de seu aplicativo e operações. Se você não tiver certeza, esta seção oferece orientação de alto nível para ajudá-lo.
Escolha uma API do Flink
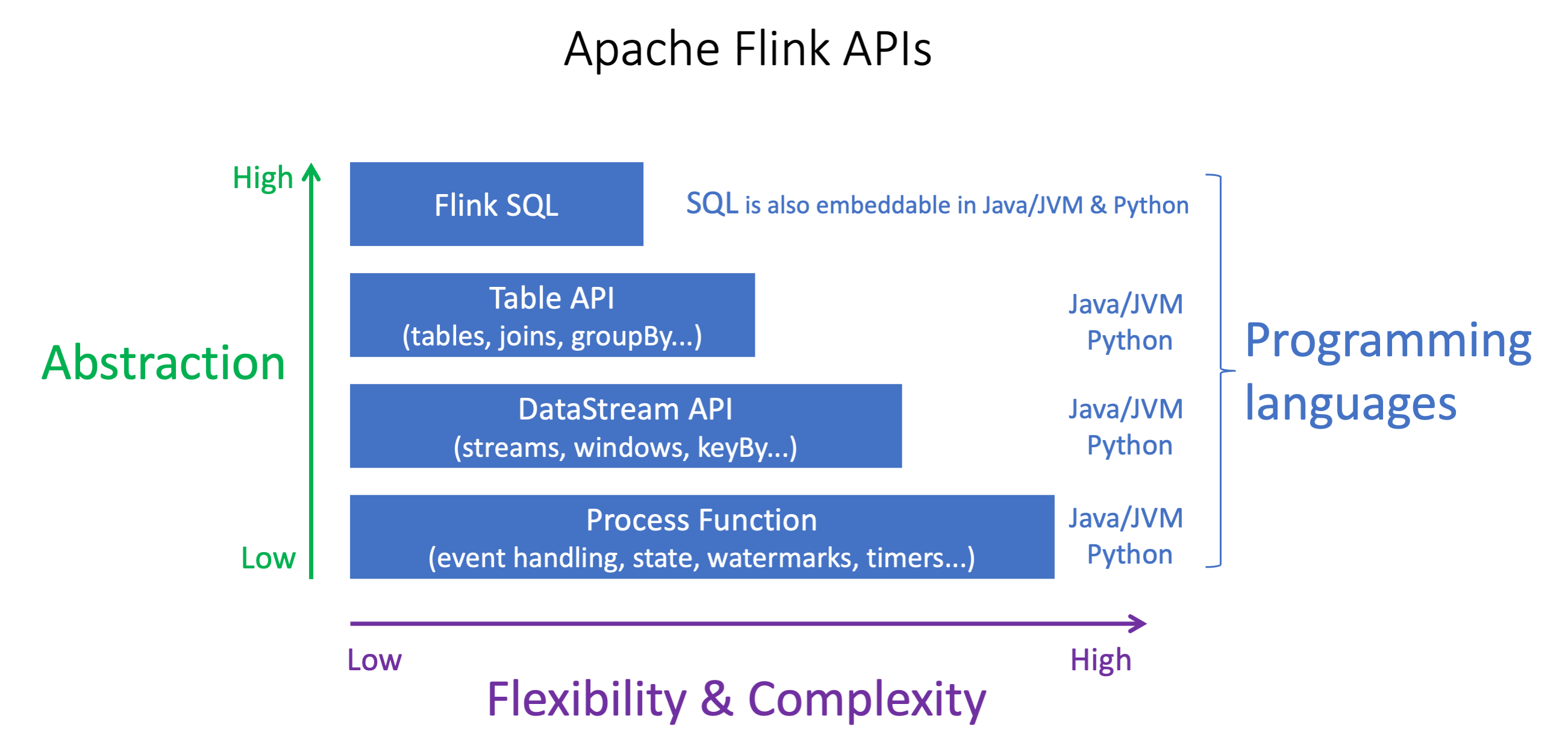
As APIs do Apache Flink têm diferentes níveis de abstração que podem afetar a maneira como você decide criar seu aplicativo. Elas são expressivos e flexíveis e podem ser usadas juntas para criar seu aplicativo. Não é necessário usar apenas uma API do Flink. Você pode aprender mais sobre as APIs do Flink na documentação do Apache Flink
O Flink oferece quatro níveis de abstração de API: Flink SQL, API de tabela, DataStream API e função de processo, que são usados em conjunto com a API. DataStream Tudo isso é compatível com o Amazon Managed Service for Apache Flink. É recomendável começar com um nível mais alto de abstração sempre que possível. No entanto, alguns recursos do Flink só estão disponíveis com a API Datastream, onde você pode criar seu aplicativo em Java, Python ou Scala. Você deve considerar o uso da API Datastream caso:
precisa de controle refinado sobre o estado
deseja aproveitar a capacidade de chamar um banco de dados externo ou endpoint de forma assíncrona (por exemplo, para inferência)
deseja usar temporizadores personalizados (por exemplo, para implementar janelas personalizadas ou tratamento tardio de eventos)
-
deseja ser capaz de modificar o fluxo do seu aplicativo sem redefinir o estado
nota
Como escolher uma linguagem com a API DataStream:
O SQL pode ser incorporado em qualquer aplicativo Flink, independentemente da linguagem de programação selecionada.
Se você planeja usar a DataStream API, nem todos os conectores são compatíveis com Python.
Se você precisar latency/high de baixo rendimento, considere Java/Scala independentemente da API.
Se você usar o Async IO na API Process Functions, precisará usar Java.
A escolha da API também pode afetar sua capacidade de desenvolver a lógica do aplicativo sem necessidade de redefinir o estado. Isso depende de um recurso específico, a capacidade de definir o UID nos operadores, que só está disponível na API DataStream para Java e Python. Para obter mais informações, consulte Definir UUIDs para todos os operadores
Conceitos básicos com aplicativos de dados de transmissão
Você pode começar criando um aplicativo do Managed Service for Apache Flink que lê e processa continuamente dados em transmissão. Em seguida, crie seu código usando o IDE de sua escolha e teste-o com dados de transmissão ao vivo. Você também pode configurar destinos para os quais o Managed Service for Apache Flink enviará os resultados.
Para começar, recomendamos que você leia as seguintes seções:
De modo alternativo, você pode começar criando um notebook Studio para Managed Service for Apache Flink que permita que você consulte interativamente fluxos de dados em tempo real e crie e execute facilmente aplicativos de processamento de fluxo usando SQL, Python e Scala padrão. Com alguns cliques no Console de gerenciamento da AWS, você pode iniciar um notebook sem servidor para consultar fluxos de dados e obter resultados em segundos. Para começar, recomendamos que você leia as seguintes seções:
