As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Fase de processamento
O Amazon Textract extrai o conteúdo do arquivo PDF como sequências de caracteres que não podem ser usadas diretamente por aplicativos downstream (por exemplo, para gerar estatísticas agregando números). Valores de dados identificados e transformados corretamente são necessários porque podem ser usados com mais facilidade por seus aplicativos downstream (por exemplo, para traçar tendências de custo como uma série temporal). Para implementar o processamento de arquivos PDF, um arquivo PDF de cada novo tipo de arquivo PDF deve ser processado uma vez por meio do Amazon Textract, que então gera um Template arquivo no formato JSON.
Depois que a AWS Lambda função é iniciada noFase de ingestão, ela executa as etapas mostradas no diagrama a seguir.
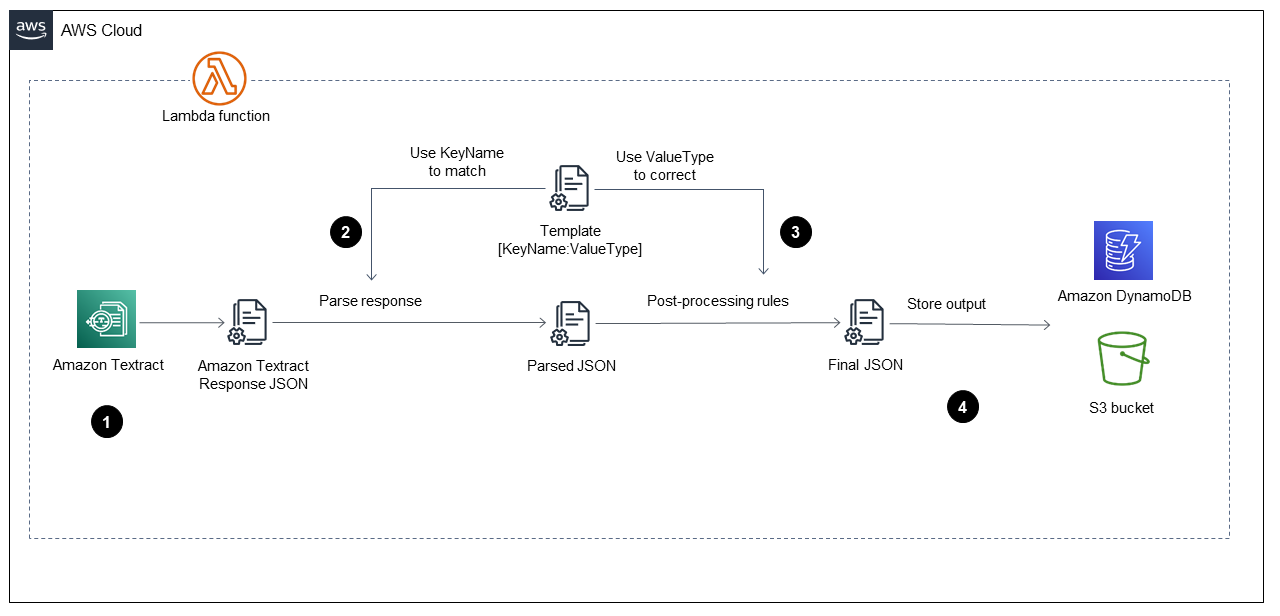
O diagrama mostra a função Lambda implementando as seguintes etapas:
-
Chama o Amazon Textract para processar o arquivo PDF, extrair o conteúdo e retornar um arquivo formatado em JSON.
-
Pega o arquivo JSON e analisa formulários e tabelas usando um arquivo
TemplateJSON predefinido que tem o nome de chave e o tipo de valor corretos para cada campo. Esse processo fornece um arquivo JSON analisado. -
Aplica as regras de pós-processamento e usa o arquivo
TemplateJSON para corrigir cada valor no arquivo JSON analisado. Isso produz o arquivoFinalJSON. O arquivoTemplateJSON predefinido pode ser armazenado no bucket do S3. -
Armazena o arquivo
FinalJSON no Amazon DynamoDB como um registro para cada arquivo PDF, além de um arquivo JSON para cada arquivo PDF em um bucket de saída do S3.
Para um step-by-step fluxo de trabalho que usa o Amazon Textract para extrair automaticamente conteúdo de arquivos PDF e processá-lo em uma saída limpa, consulte o padrão Extrair automaticamente conteúdo de arquivos PDF usando o Amazon Textract no AWS site Prescriptive Guidance. O padrão usa uma técnica de correspondência de modelos para identificar corretamente o campo obrigatório, o nome da chave e as tabelas e, em seguida, aplica correções de pós-processamento a cada tipo de dados.
Melhores práticas para a fase de processamento
Use as quatro melhores práticas a seguir para garantir uma fase de processamento bem-sucedida:
-
Crie um arquivo JSON modelo para cada tipo de arquivo PDF que você deseja processar. Você pode armazenar esses diferentes arquivos JSON de modelo em um bucket do S3 chamado pela função Lambda. Se você quiser processar diferentes tipos de arquivo PDF em uma função Lambda, use um identificador exclusivo para cada tipo de arquivo PDF (por exemplo, o nome da pasta do tipo de arquivo PDF no bucket do S3). Depois que a função Lambda é invocada, ela recupera o arquivo JSON de modelo apropriado e o processa.
-
Configure um mecanismo para rastrear com precisão o status de cada etapa na função Lambda. Por exemplo, você pode adicionar
Successstatus após a chamada do Amazon Textract, quando o arquivo JSON final é salvo em uma tabela do Amazon DynamoDB ou quando os arquivos PDF são salvos em um bucket do S3. Você também pode criar uma tabela separada do DynamoDB para rastrear o status de cada arquivo PDF nas diferentes etapas, o que fornece visibilidade do processo. -
Gerencie a limitação e a queda de conexões repetindo automaticamente as operações com falha ao processar em lote muitos arquivos PDF. A limitação pode ocorrer no Amazon Textract se sua conexão cair ou você exceder o número máximo de transações por segundo (TPS). Para obter mais informações e etapas para repetir automaticamente operações com falha, consulte Como lidar com chamadas limitadas e conexões interrompidas na documentação do Amazon Textract.
-
Se você tiver arquivos PDF com várias páginas, poderá usar uma operação assíncrona para processar o arquivo inteiro ou dividir o arquivo PDF em uma página individual, usar uma operação síncrona para processar cada página e combinar os resultados de cada página. Para uma implementação completa do código de uma operação assíncrona, consulte Detecção e análise de texto em documentos de várias páginas na documentação do Amazon Textract. Para obter mais informações sobre o uso de uma operação síncrona, consulte Detecção e análise de texto em documentos de página única na documentação do Amazon Textract.
