As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Altere os aplicativos Python e Perl para oferecer suporte à migração do banco de dados do Microsoft SQL Server para o Amazon Aurora Edição Compatível com PostgreSQL
Dwarika Patra e Deepesh Jayaprakash, da Amazon Web Services
Resumo
Esse padrão descreve as alterações nos repositórios de aplicativos que podem ser necessárias quando você migra bancos de dados do Microsoft SQL Server para o Amazon Aurora Edição Compatível com PostgreSQL. O padrão pressupõe que esses aplicativos sejam baseados em Python ou em Perl e fornece instruções separadas para essas linguagens de script.
A migração de bancos de dados do SQL Server para o Aurora compatível com PostgreSQL envolve conversão de esquemas, conversão de objetos de banco de dados, migração de dados e carregamento de dados. Devido às diferenças entre o PostgreSQL e o SQL Server (relacionadas a tipos de dados, objetos de conexão, sintaxe e lógica), a tarefa de migração mais difícil envolve fazer as alterações necessárias na base de código para que ela funcione corretamente com o PostgreSQL.
Em um aplicativo baseado em Python, objetos e classes de conexão estão espalhados por todo o sistema. Além disso, a base de código do Python pode usar várias bibliotecas para se conectar ao banco de dados. Se a interface de conexão do banco de dados mudar, os objetos que executam as consultas em linha do aplicativo também precisarão de alterações.
Em um aplicativo baseado em Perl, as alterações envolvem objetos de conexão, drivers de conexão de banco de dados, instruções SQL em linha estáticas e dinâmicas e como o aplicativo lida com consultas dinâmicas complexas de DML e conjuntos de resultados.
Ao migrar seu aplicativo, você também pode considerar possíveis melhorias na AWS, como a substituição do servidor FTP pelo acesso ao Amazon Simple Storage Service (Amazon S3).
O processo de migração de aplicativos envolve os seguintes desafios:
Objetos de conexão. Se os objetos de conexão estiverem espalhados no código com várias bibliotecas e chamadas de função, talvez seja necessário encontrar uma maneira generalizada de alterá-los para oferecer suporte ao PostgreSQL.
Tratamento de erros ou exceções durante a recuperação ou atualizações de registros. Se você tiver operações condicionais de criação, leitura, atualização e exclusão (CRUD) no banco de dados que retornam variáveis, conjuntos de resultados ou data frames, quaisquer erros ou exceções podem resultar em erros de aplicativo com efeitos em cascata. Eles devem ser tratados com cuidado, com validações adequadas e pontos de economia. Um desses pontos de salvamento é chamar grandes consultas SQL em linha ou objetos de banco de dados dentro de blocos
BEGIN...EXCEPTION...END.Controle de transações e sua validação. Isso inclui confirmações e reversões manuais e automáticas. O driver do PostgreSQL para Perl exige que você sempre defina explicitamente o atributo de confirmação automática.
Tratamento de consultas SQL dinâmicas. Isso requer uma forte compreensão da lógica de consulta e testes iterativos para garantir que as consultas funcionem conforme o esperado.
Desempenho. Você deve garantir que as alterações no código não resultem na degradação do desempenho do aplicativo.
Esse padrão explica detalhadamente o processo de conversão.
Pré-requisitos e limitações
Pré-requisitos
Conhecimento prático das sintaxes Python e Perl.
Habilidades básicas em SQL Server e PostgreSQL.
Compreensão da arquitetura de seu aplicativo existente.
Acesso ao código do aplicativo, ao banco de dados do SQL Server e ao banco de dados do PostgreSQL.
Acesso ao ambiente de desenvolvimento Windows ou Linux (ou outro Unix) com credenciais para desenvolver, testar e validar alterações em aplicativos.
Para um aplicativo baseado em Python, bibliotecas Python padrão que seu aplicativo pode exigir, como Pandas para lidar com quadros de dados e psycopg2 ou para conexões de banco de dados. SQLAlchemy
Para um aplicativo baseado em Perl, são necessários pacotes Perl com bibliotecas ou módulos dependentes. O módulo rede abrangente de arquivos do Perl (CPAN) pode oferecer suporte à maioria dos requisitos do aplicativo.
Todas as bibliotecas ou módulos personalizados dependentes necessários.
Credenciais de banco de dados para acesso de leitura ao SQL Server e read/write acesso ao Aurora.
PostgreSQL para validar e depurar alterações de aplicativos com serviços e usuários.
Acesso a ferramentas de desenvolvimento durante a migração de aplicativos, como Visual Studio Code, Sublime Text ou pgAdmin.
Limitações
Algumas versões, módulos, bibliotecas e pacotes do Python ou Perl não são compatíveis com o ambiente de nuvem.
Algumas bibliotecas e estruturas de terceiros usadas para o SQL Server não podem ser substituídas para oferecer suporte à migração do PostgreSQL.
As variações de desempenho podem exigir alterações em seu aplicativo, nas consultas em linha do Transact-SQL (T-SQL), nas funções do banco de dados e nos procedimentos armazenados.
PostgreSQL suporta nomes em minúsculas para nomes de tabelas, nomes de colunas e outros objetos de banco de dados.
Alguns tipos de dados, como colunas UUID, são armazenados somente em letras minúsculas. Os aplicativos Python e Perl devem lidar com essas diferenças de maiúsculas e minúsculas.
As diferenças na codificação de caracteres devem ser tratadas com o tipo de dados correto para as colunas de texto correspondentes no banco de dados do PostgreSQL.
Versões do produto
Python 3.6 ou superior (use a versão compatível com seu sistema operacional)
Perl 5.8.3 ou superior (use a versão compatível com seu sistema operacional)
Edição 4.2 ou superior do Aurora compatível com PostgreSQL (veja detalhes)
Arquitetura
Pilha de tecnologia de origem
Linguagem de script (programação de aplicativos): Python 2.7 ou superior ou Perl 5.8
Banco de dados: Microsoft SQL Server versão 13
Sistema operacional: Red Hat Enterprise Linux (RHEL) 7
Pilha de tecnologias de destino
Linguagem de script (programação de aplicativos): Python 3.6 ou superior ou Perl 5.8 ou superior
Banco de dados: Aurora 4.2 compatível com PostgreSQL
Sistema operacional: RHEL 7
Arquitetura de migração
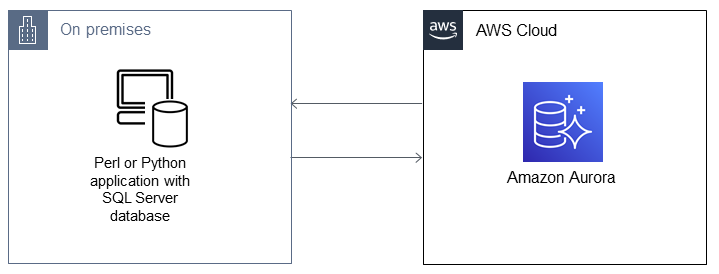
Ferramentas
Ferramentas e serviços da AWS
A Edição compatível com PostgreSQL do Amazon Aurora é um mecanismo de banco de dados relacional totalmente gerenciado, compatível com PostgreSQL e compatível com ACID que combina a velocidade e a confiabilidade de bancos de dados comerciais de alta tecnologia com a economia de bancos de dados de código aberto. O Aurora PostgreSQL é um substituto imediato do PostgreSQL e torna mais fácil e econômico configurar, operar e escalar suas implantações novas e existentes do PostgreSQL.
A AWS Command Line Interface (AWS CLI) é uma ferramenta de código aberto que permite que você interaja com serviços da AWS usando comandos no shell da linha de comando.
Outras ferramentas
Épicos
| Tarefa | Descrição | Habilidades necessárias |
|---|---|---|
Siga estas etapas de conversão de código para migrar seu aplicativo para o PostgreSQL. |
Os épicos a seguir fornecem instruções detalhadas para algumas dessas tarefas de conversão para aplicativos Python e Perl. | Desenvolvedor de aplicativos |
Use uma lista de verificação para cada etapa da migração. | Adicione o seguinte à sua lista de verificação para cada etapa da migração do aplicativo, incluindo a etapa final:
| Desenvolvedor de aplicativos |
| Tarefa | Descrição | Habilidades necessárias |
|---|---|---|
Analise sua base de código Python existente. | Sua análise deve incluir o seguinte para facilitar o processo de migração do aplicativo:
| Desenvolvedor de aplicativos |
Converta suas conexões de banco de dados para suportar o PostgreSQL. | A maioria dos aplicativos Python usa a biblioteca pyodbc para se conectar aos bancos de dados do SQL Server da seguinte maneira.
Converta a conexão do banco de dados para suportar o PostgreSQL da seguinte maneira.
| Desenvolvedor de aplicativos |
Altere as consultas SQL em linha para PostgreSQL. | Converta suas consultas SQL em linha em um formato compatível com PostgreSQL. Por exemplo, a consulta do SQL Server a seguir recupera uma string de uma tabela.
Após a conversão, a consulta SQL em linha compatível com PostgreSQL tem a seguinte aparência.
| Desenvolvedor de aplicativos |
Gerencie consultas SQL dinâmicas. | O SQL dinâmico pode estar presente em um script ou em vários scripts do Python. Exemplos anteriores mostraram como usar a função string replace (substituição de strings) do Python para inserir variáveis para estruturar consultas SQL dinâmicas. Uma abordagem alternativa é anexar a string de consulta com variáveis sempre que aplicável. No exemplo a seguir, a string de consulta é estruturada dinamicamente com base nos valores retornados por uma função.
Esses tipos de consultas dinâmicas são muito comuns durante a migração do aplicativo. Siga estas etapas para lidar com consultas dinâmicas:
| Desenvolvedor de aplicativos |
Gerencie conjuntos de resultados, variáveis e data frames. | No Microsoft SQL Server, você usa métodos Python, como pyodbc (Microsoft SQL Server)
No Aurora, para realizar tarefas semelhantes, como conectar-se ao PostgreSQL e buscar conjuntos de resultados, você pode usar psycopg2 ou. SQLAlchemy Essas bibliotecas do Python fornecem o módulo de conexão e o objeto cursor para percorrer os registros do banco de dados do PostgreSQL, conforme mostrado no exemplo a seguir. psycopg2 (Aurora compatível com PostgreSQL)
SQLAlchemy (Compatível com Aurora PostgreSQL)
| Desenvolvedor de aplicativos |
Teste seu aplicativo durante e após a migração. | Testar o aplicativo do Python migrado é um processo contínuo. Como a migração inclui alterações no objeto de conexão (psycopg2 ou SQLAlchemy), tratamento de erros, novos recursos (quadros de dados), alterações de SQL em linha, funcionalidades de cópia em massa (
| Desenvolvedor de aplicativos |
| Tarefa | Descrição | Habilidades necessárias |
|---|---|---|
Analise sua base de código Perl existente. | Sua análise deve incluir o seguinte para facilitar o processo de migração do aplicativo. Você deve identificar:
| Desenvolvedor de aplicativos |
Converta as conexões do aplicativo do Perl e do módulo do DBI para suportar o PostgreSQL. | Os aplicativos baseados em Perl geralmente usam o módulo do Perl DBI, que é um módulo padrão de acesso ao banco de dados para a linguagem de programação Perl. Você pode usar o mesmo módulo do DBI com drivers diferentes para SQL Server e PostgreSQL. Para obter mais informações sobre os módulos do Perl, instalações e outras instruções necessários, consulte a documentação do DBD::Pg
| Desenvolvedor de aplicativos |
Altere as consultas SQL em linha para PostgreSQL. | Seu aplicativo pode ter consultas SQL em linha com No SQL Server:
Para o PostgreSQL, converta para:
| Desenvolvedor de aplicativos |
Gerencie consultas SQL dinâmicas e variáveis do Perl. | As consultas SQL dinâmicas são instruções SQL criadas no runtime do aplicativo. Essas consultas são estruturadas dinamicamente quando o aplicativo está em execução, dependendo de determinadas condições, portanto, o texto completo da consulta não é conhecido até o runtime. Um exemplo é um aplicativo de análise financeira que analisa as 10 principais ações diariamente, e essas ações mudam todos os dias. As tabelas SQL são criadas com base nos melhores desempenhos e os valores não são conhecidos até o runtime. Digamos que as consultas SQL em linha deste exemplo sejam passadas para uma função de encapsulamento para obter o conjunto de resultados em uma variável e, em seguida, uma variável use uma condição para determinar se a tabela existe:
Este é um exemplo de manipulação de variáveis, seguido pelas consultas SQL Server e PostgreSQL para este caso de uso.
SQL Server:
PostgreSQL:
O exemplo a seguir usa uma variável do Perl em SQL em linha, que executa uma instrução SQL Server:
PostgreSQL:
| Desenvolvedor de aplicativos |
| Tarefa | Descrição | Habilidades necessárias |
|---|---|---|
Converta estruturas adicionais do SQL Server em PostgreSQL. | As alterações a seguir se aplicam a todos os aplicativos, independentemente da linguagem de programação.
| Desenvolvedor de aplicativos |
| Tarefa | Descrição | Habilidades necessárias |
|---|---|---|
Aproveite os serviços da AWS para aprimorar o desempenho. | Ao migrar para a nuvem AWS, você pode refinar o design do aplicativo e do banco de dados para aproveitar os serviços da AWS. Por exemplo, se as consultas do seu aplicativo do Python, que está conectado a um servidor de banco de dados compatível com o Aurora PostgreSQL, estiverem demorando mais do que as consultas originais do Microsoft SQL Server, considere criar um feed de dados históricos diretamente para um bucket do Amazon Simple Storage Service (Amazon S3) a partir do servidor Aurora e usar consultas SQL baseadas no Amazon Athena para gere relatórios e consultas de dados analíticos para seus painéis de usuário. | Desenvolvedor de aplicativos, arquiteto de nuvem |
Recursos relacionados
Mais informações
Tanto o Microsoft SQL Server quanto o Aurora compatível com PostgreSQL são compatíveis com o ANSI SQL. No entanto, você ainda deve estar ciente de quaisquer incompatibilidades na sintaxe, nos tipos de dados da coluna, nas funções específicas do banco de dados nativo, nas inserções em massa e na diferenciação de maiúsculas e minúsculas ao migrar seu aplicativo do Python ou Perl do SQL Server para o PostgreSQL.
As seções a seguir fornecem mais informações sobre possíveis inconsistências.
Comparação de tipos de dados
Alterações no tipo de dados do SQL Server para o PostgreSQL podem levar a diferenças significativas nos dados resultantes com os quais os aplicativos operam. Para obter uma comparação dos tipos de dados, consulte a tabela no site da Sqlines
Funções SQL nativas ou integradas
O comportamento de algumas funções difere entre os bancos de dados SQL Server e PostgreSQL. A tabela a seguir oferece uma comparação.
Microsoft SQL Server | Descrição | PostgreSQL |
|---|---|---|
| Converte um valor de um tipo de dados para outro. | PostgreSQL |
| Retorna a data e hora do sistema de banco de dados atual, em um formato |
|
| Adiciona um time/date intervalo a uma data. | Expressão |
| Converte um valor em um formato de dados específico. |
|
| Retorna a diferença entre duas datas. |
|
| Limita o número de linhas em um conjunto de |
|
Blocos anônimos
Uma consulta SQL estruturada é organizada em seções como declaração, executáveis e tratamento de exceções. A tabela a seguir compara as versões do Microsoft SQL Server e PostgreSQL de um bloco anônimo simples. Para blocos anônimos complexos, recomendamos que você chame uma função de banco de dados personalizada em seu aplicativo.
Microsoft SQL Server | PostgreSQL |
|---|---|
|
|
Outras diferenças
Inserções de linhas em massa: o equivalente do PostgreSQL do utilitário bcp do Microsoft SQL Server
é COPY . Sensibilidade a maiúsculas e minúsculas: os nomes das colunas diferenciam maiúsculas de minúsculas no PostgreSQL, portanto, é necessário converter os nomes das colunas do SQL Server para letras minúsculas ou maiúsculas. Isso se torna um fator quando você extrai ou compara dados ou coloca nomes de colunas em conjuntos de resultados ou variáveis. O exemplo a seguir identifica colunas nas quais os valores podem ser armazenados em maiúsculas ou minúsculas.
my $sql_qry = "SELECT $record_id FROM $exampleTable WHERE LOWER($record_name) = \'failed transaction\'";
Concatenação: o SQL Server usa
+como operador para concatenação de strings, enquanto o PostgreSQL usa||.Validação: você deve testar e validar consultas e funções SQL em linha antes de usá-las no código do aplicativo para PostgreSQL.
Inclusão da biblioteca ORM: você também pode procurar incluir ou substituir a biblioteca de conexão de banco de dados existente por bibliotecas ORM Python, como SQLAlchemy
PynomoDB. Isso ajudará a consultar e manipular facilmente dados de um banco de dados usando um paradigma orientado a objetos.
