As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Emule o Oracle DR usando um banco de dados global Aurora compatível com PostgreSQL
Criado por HariKrishna Boorgadda (AWS)
Resumo
As práticas recomendadas para recuperação de desastres (DR) empresarial consistem basicamente em projetar e implementar sistemas de hardware e software tolerantes a falhas que possam sobreviver a um desastre (continuidade dos negócios) e retomar as operações normais (retomada dos negócios), com intervenção mínima e, idealmente, sem perda de dados. Criar ambientes tolerantes a falhas para satisfazer os objetivos corporativos de DR pode ser caro e demorado, além de exigir um forte comprometimento da empresa.
O Oracle Database fornece três abordagens diferentes para DR que fornecem o mais alto nível de proteção e disponibilidade de dados em comparação com qualquer outra abordagem para proteger dados do Oracle.
Dispositivo Oracle Zero Data Loss Recovery
Oracle Active Data Guard
Oráculo GoldenGate
Esse padrão fornece uma forma de emular o Oracle GoldenGate DR usando um banco de dados global Amazon Aurora. A arquitetura de referência usa o Oracle GoldenGate para DR em três regiões da AWS. O padrão percorre a redefinição da plataforma de origem para o banco de dados global Aurora nativo de nuvem, baseado na edição do Amazon Aurora compatível com PostgreSQL.
O banco de dados global Aurora foi criado para aplicações com uma presença mundial. Um único banco de dados Aurora abrange várias regiões da AWS com até cinco regiões secundárias. Os bancos de dados globais do Aurora fornecem os seguintes atributos:
Replicação física em nível de armazenamento
Leituras globais de baixa latência
Recuperação de desastres rápida após interrupções em toda a região
Migrações rápidas entre regiões
Baixo atraso de replicação em todas as regiões
Little-to-no impacto no desempenho do seu banco de dados
Para obter mais informações sobre os atributos e vantagens do banco de dados global Aurora, consulte Usar o Amazon Aurora Global Database. Para obter mais informações sobre failovers não planejados e gerenciados, consulte Uso de failover em um Amazon Aurora Global Database.
Pré-requisitos e limitações
Pré-requisitos
Uma conta AWS ativa
Um driver PostgreSQL Java Database Connectivity (JDBC) para conectividade de aplicativos
Um banco de dados global do Aurora baseado no Amazon Aurora Edição Compatível com PostgreSQL
Um banco de dados do Oracle Real Application Clusters (RAC) migrou para o banco de dados global Aurora baseado em compatibilidade com o Aurora PostgreSQL
Limitações dos bancos de dados globais do Aurora
Os bancos de dados globais Aurora não estão disponíveis em todas as regiões da AWS. Para obter uma lista de regiões compatíveis, consulte Bancos de dados globais do Aurora PostgreSQL.
Para obter informações sobre atributos que não são compatíveis e outras limitações dos bancos de dados globais do Aurora, consulte as Limitações do Amazon Aurora Global Database.
Versões do produto
Edição do Amazon Aurora compatível com PostgreSQL versão 10.14 ou superior
Arquitetura
Pilha de tecnologia de origem
Banco de dados de quatro nós do Oracle RAC
Oráculo GoldenGate
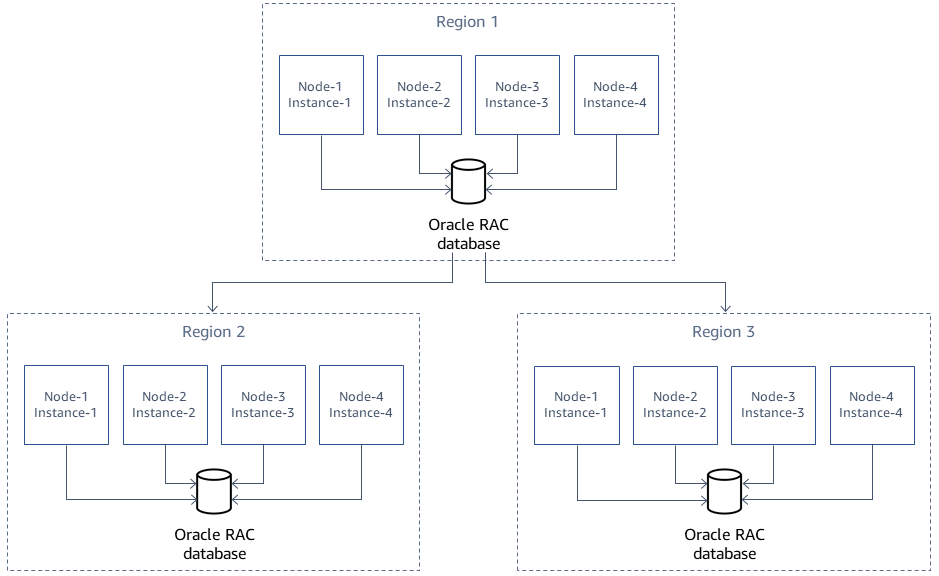
Arquitetura de origem
O diagrama a seguir mostra três clusters com Oracle RAC de quatro nós em diferentes regiões da AWS replicados usando o Oracle. GoldenGate
Pilha de tecnologias de destino
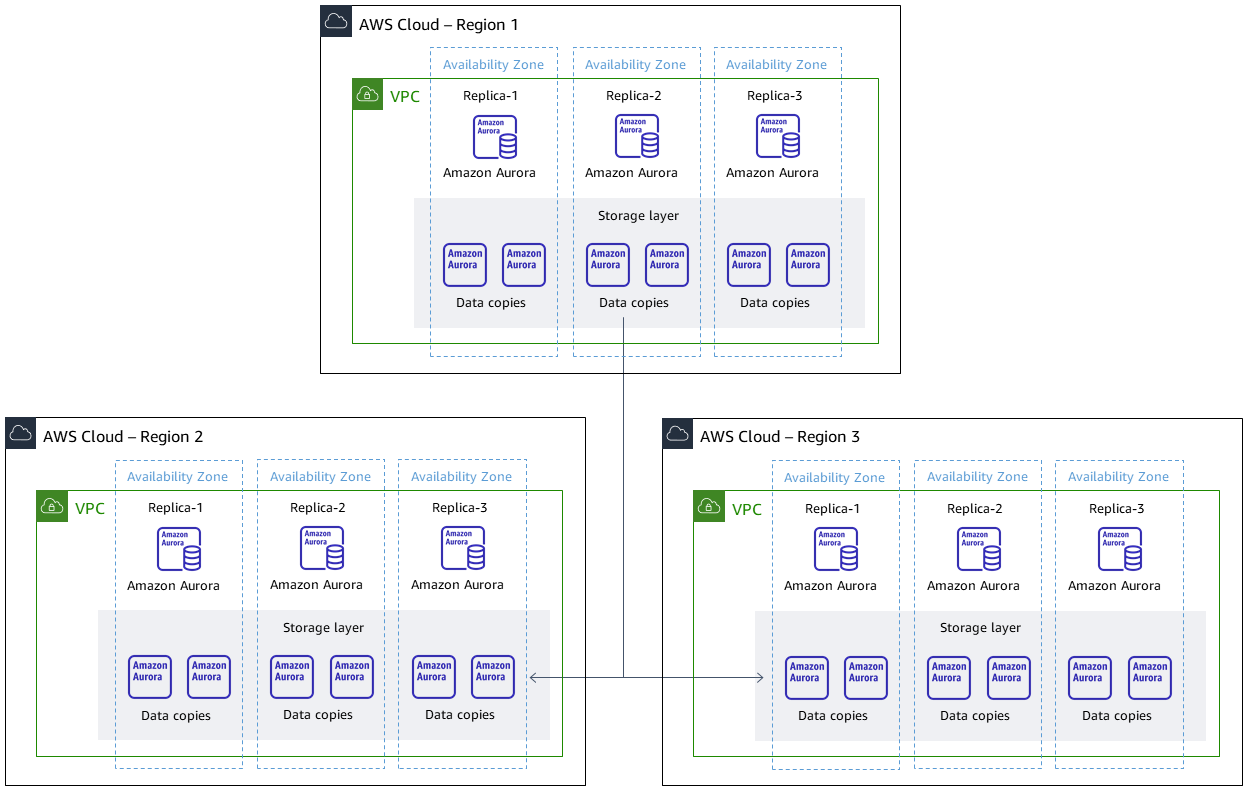
Um Amazon Aurora Global Database de três clusters baseado no Aurora PostgreSQL, compatível com um cluster na região primária e dois clusters em diferentes regiões secundárias
Arquitetura de destino
Ferramentas
Serviços da AWS
O Amazon Aurora Edição Compatível com PostgreSQL é um mecanismo de banco de dados relacional totalmente gerenciado e compatível com ACID que ajuda você a configurar, operar e escalar implantações do PostgreSQL.
Os Amazon Aurora Global Database abrangem várias regiões da AWS, fornecendo leituras globais de baixa latência e recuperação rápida de interrupções raras que podem afetar uma região inteira da AWS.
Épicos
| Tarefa | Descrição | Habilidades necessárias |
|---|---|---|
Conecte um ou mais clusters secundários do Aurora. | No menu Console de Gerenciamento da AWS, selecione Amazon Aurora. Selecione o cluster primário, selecione Actions e Adicionar região na lista suspensa. | DBA |
Selecione a classe da instância. | Você pode alterar a classe da instância do cluster secundário. No entanto, recomendamos mantê-la igual à classe de instância do cluster primário. | DBA |
Adicione a terceira região. | Repita as etapas desse épico para adicionar um cluster na terceira região. | DBA |
| Tarefa | Descrição | Habilidades necessárias |
|---|---|---|
Remova o cluster primário do banco de dados Aurora global. |
| DBA |
Reconfigure o aplicativo a fim de desviar o tráfego de gravação para o cluster recém-promovido. | Modifique o endpoint no aplicativo usando o do cluster recém-promovido. | DBA |
Pare de emitir qualquer operação de gravação para o cluster indisponível. | Interrompa o aplicativo e qualquer atividade de data manipulation language (DML – linguagem de manipulação de dados) no cluster que você removeu. | DBA |
Crie um novo banco de dados global Aurora. | Agora você pode criar um banco de dados Aurora global com o cluster recém-promovido como cluster primário. | DBA |
| Tarefa | Descrição | Habilidades necessárias |
|---|---|---|
Selecione o cluster primário a ser iniciado a partir do banco de dados global. | No console do Amazon Aurora, selecione o cluster primário na configuração do banco de dados global. | DBA |
Inicie o cluster. | Na lista suspensa Ações, selecione Iniciar. Esse processo pode levar algum tempo. Atualize a tela para ver o status ou verifique na coluna Status o estado atual do cluster após a conclusão da operação. | DBA |
| Tarefa | Descrição | Habilidades necessárias |
|---|---|---|
Exclua os clusters secundários restantes. | Após a conclusão do piloto de failover, remova os clusters secundários do banco de dados global. | DBA |
Exclua o cluster primário. | Remova o cluster. | DBA |
Recursos relacionados
