As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Migrar valores do Oracle CLOB para linhas individuais no PostgreSQL na AWS
Criado por Sai Krishna Namburu (AWS) e Sindhusha Paturu (AWS)
Resumo
Este padrão descreve como dividir os valores do Oracle Character Large Object (CLOB) em linhas individuais no Amazon Aurora Edição Compatível com PostgreSQL e no Amazon Relational Database Service (Amazon RDS) para o PostgreSQL. O PostgreSQL não dá suporte ao tipo de dados CLOB.
As tabelas com partições de intervalo são identificadas no banco de dados Oracle de origem, e o nome da tabela, o tipo de partição, o intervalo da partição e outros metadados são capturados e carregados no banco de dados de destino. Você pode carregar dados CLOB com menos de 1 GB em tabelas de destino como texto usando o AWS Database Migration Service (AWS DMS) ou pode exportar os dados no formato CSV, carregá-los em um bucket do Amazon Simple Storage Service (Amazon S3) e migrá-los para o banco de dados PostgreSQL de destino.
Após a migração, você pode usar o código PostgreSQL personalizado fornecido com esse padrão para dividir os dados CLOB em linhas individuais com base no novo identificador de caracteres de linha (CHR(10)) e preencher a tabela de destino.
Pré-requisitos e limitações
Pré-requisitos
Uma tabela de banco de dados Oracle que tem partições de intervalo e registros com um tipo de dados CLOB.
Um banco de dados compatível com o Aurora PostgreSQL ou Amazon RDS para PostgreSQL que tem uma estrutura de tabela semelhante à tabela de origem (mesmas colunas e tipos de dados).
Limitações
O valor do CLOB não pode exceder 1 GB.
Cada linha na tabela de destino deve ter um novo identificador de caractere de linha.
Versões do produto
Oracle 12c
Aurora Postgres 11.6
Arquitetura
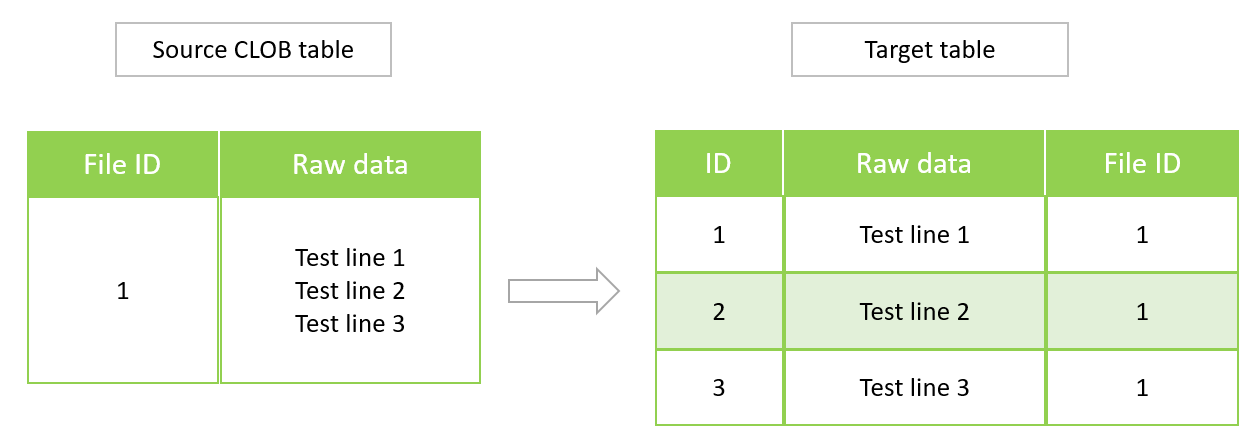
O diagrama a seguir mostra uma tabela Oracle de origem com dados CLOB e a tabela PostgreSQL equivalente na versão 11.6 compatível com o Aurora PostgreSQL.
Ferramentas
Serviços da AWS
O Amazon Aurora Edição Compatível com PostgreSQL é um mecanismo de banco de dados relacional totalmente gerenciado e em conformidade com ACID, que ajuda você a configurar, operar e escalar as implantações de PostgreSQL.
O Amazon Relational Database Service (Amazon RDS) para PostgreSQL ajuda você a configurar, operar e escalar um banco de dados relacional PostgreSQL na Nuvem AWS.
O AWS Database Migration Service (AWS DMS) ajuda você a migrar armazenamentos de dados para a Nuvem AWS ou entre combinações de configurações na nuvem e on-premises.
O Amazon Simple Storage Service (Amazon S3) é um serviço de armazenamento de objetos baseado na nuvem que ajuda você a armazenar, proteger e recuperar qualquer quantidade de dados.
Outras ferramentas
Você pode usar as seguintes ferramentas de cliente para se conectar, acessar e gerenciar seus bancos de dados compatíveis com o Aurora PostgreSQL e o Amazon RDS para PostgreSQL. (Essas ferramentas não são usadas nesse padrão).
O pgAdmin
é uma ferramenta de gerenciamento de código aberto para PostgreSQL. Ele fornece uma interface gráfica que ajuda você a criar, manter e usar objetos de banco de dados. DBeaver
é uma ferramenta de banco de dados de código aberto para desenvolvedores e administradores de banco de dados. Você pode usar a ferramenta para manipular, monitorar, analisar, administrar e migrar seus dados.
Práticas recomendadas
Para obter as práticas recomendadas para migrar seu banco de dados do Oracle para o PostgreSQL, consulte a Publicação de blog da AWS práticas recomendadas para migrar um banco de dados Oracle para o Amazon RDS PostgreSQL ou o Amazon Aurora PostgreSQL: considerações sobre o processo de migração e a infraestrutura
Para obter as melhores práticas de configuração da tarefa do AWS DMS para migrar objetos binários grandes, consulte Migração de objetos binários grandes () LOBs na documentação do AWS DMS.
Épicos
| Tarefa | Descrição | Habilidades necessárias |
|---|---|---|
Analisar os dados do CLOB. | No banco de dados Oracle de origem, analise os dados CLOB para ver se eles contêm cabeçalhos de coluna, para que você possa determinar o método para carregar os dados na tabela de destino. Para analisar os dados de entrada, use a consulta a seguir.
| Desenvolvedor |
Carregar os dados do CLOB no banco de dados de destino. | Migre a tabela que tem dados CLOB para uma tabela provisória (de teste) no banco de dados de destino do Aurora ou do Amazon RDS. Você pode usar o AWS DMS ou carregar os dados como um arquivo CSV em um bucket do Amazon S3. Para obter informações sobre o uso do AWS DMS para essa tarefa, consulte Usar um banco de dados Oracle como fonte e Usar um banco de dados PostgreSQL como destino na documentação do AWS DMS. Para obter informações sobre o uso do Amazon S3 para essa tarefa, consulte Usar o Amazon S3 como destino na documentação do AWS DMS. | Engenheiro de migração, DBA |
Validar a tabela PostgreSQL de destino. | Valide os dados de destino, incluindo cabeçalhos, em relação aos dados de origem usando as seguintes consultas no banco de dados de destino.
Compare os resultados com os resultados da consulta do banco de dados de origem (da primeira etapa). | Desenvolvedor |
Dividir os dados do CLOB em linhas separadas. | Execute o código PostgreSQL personalizado fornecido na seção Informações adicionais para dividir os dados CLOB e inseri-los em linhas separadas na tabela PostgreSQL de destino. | Desenvolvedor |
| Tarefa | Descrição | Habilidades necessárias |
|---|---|---|
Validar os dados na tabela de destino. | Valide os dados inseridos na tabela de destino usando as seguintes consultas.
| Desenvolvedor |
Recursos relacionados
Tipo de dados CLOB
(documentação da Oracle) Tipos de dados
(documentação do PostgreSQL)
Mais informações
Função PostgreSQL para dividir dados CLOB
do $$ declare totalstr varchar; str1 varchar; str2 varchar; pos1 integer := 1; pos2 integer ; len integer; begin select rawdata||chr(10) into totalstr from clobdata_pg; len := length(totalstr) ; raise notice 'Total length : %',len; raise notice 'totalstr : %',totalstr; raise notice 'Before while loop'; while pos1 < len loop select position (chr(10) in totalstr) into pos2; raise notice '1st position of new line : %',pos2; str1 := substring (totalstr,pos1,pos2-1); raise notice 'str1 : %',str1; insert into clobdatatarget(data) values (str1); totalstr := substring(totalstr,pos2+1,len); raise notice 'new totalstr :%',totalstr; len := length(totalstr) ; end loop; end $$ LANGUAGE 'plpgsql' ;
Exemplos de entrada e saída
Você pode usar os exemplos a seguir para testar o código PostgreSQL antes de migrar seus dados.
Crie um banco de dados Oracle com três linhas de entrada.
CREATE TABLE clobdata_or ( id INTEGER GENERATED ALWAYS AS IDENTITY, rawdata clob ); insert into clobdata_or(rawdata) values (to_clob('test line 1') || chr(10) || to_clob('test line 2') || chr(10) || to_clob('test line 3') || chr(10)); COMMIT; SELECT * FROM clobdata_or;
Ele exibe a seguinte saída.
id | dados brutos |
1 | linha de teste 1 linha de teste 2 linha de teste 3 |
Carregue os dados de origem em uma tabela de preparação do PostgreSQL (clobdata_pg) para processamento.
SELECT * FROM clobdata_pg; CREATE TEMP TABLE clobdatatarget (id1 SERIAL,data VARCHAR ); <Run the code in the additional information section.> SELECT * FROM clobdatatarget;
Ele exibe a seguinte saída.
id1 | dados |
1 | linha de teste 1 |
2 | linha de teste 2 |
3 | linha de teste 3 |
