As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Organize um pipeline de ETL com validação, transformação e particionamento usando AWS Step Functions
Sandip Gangapadhyay, Amazon Web Services
Resumo
Esse padrão descreve como criar um pipeline de extração, transformação e carregamento (ETL) com tecnologia sem servidor para validar, transformar, compactar e particionar um grande conjunto de dados CSV para otimizar o desempenho e os custos. O pipeline é orquestrado AWS Step Functions e inclui recursos de tratamento de erros, repetição automática e notificação ao usuário.
Quando um arquivo CSV é carregado em uma pasta de origem do bucket do Amazon Simple Storage Service (Amazon S3), o pipeline de ETL começa a ser executado. O pipeline valida o conteúdo e o esquema do arquivo CSV de origem, transforma o arquivo CSV em um formato Apache Parquet compactado, particiona o conjunto de dados por ano, mês e dia e o armazena em uma pasta separada para que as ferramentas de análise possam processá-lo.
O código que automatiza esse padrão está disponível em GitHub, no pipeline ETL com AWS Step Functions
Pré-requisitos e limitações
Pré-requisitos
Um ativo Conta da AWS.
AWS Command Line Interface (AWS CLI) instalado e configurado com o seu Conta da AWS, para que você possa criar AWS recursos implantando uma AWS CloudFormation pilha. Recomendamos usar a AWS CLI versão 2. Para obter instruções, consulte Instalação ou atualização para a versão mais recente do AWS CLI na AWS CLI documentação. Para obter instruções de configuração, consulte Configurações e configurações do arquivo de credenciais na AWS CLI documentação.
Um bucket do Amazon S3.
Um conjunto de dados CSV com o esquema correto. (O repositório de código
incluído nesse padrão fornece um arquivo CSV de amostra com o esquema e o tipo de dados corretos que você pode usar.) Um navegador da web que suporta AWS Management Console o. (Consulte a lista de navegadores compatíveis
.) AWS Glue acesso ao console.
AWS Step Functions acesso ao console.
Limitações
Em AWS Step Functions, o limite máximo para manter registros históricos é de 90 dias. Para obter mais informações, consulte as cotas de serviço do Step Functions na AWS Step Functions documentação.
Versões do produto
Python 3.13 para AWS Lambda
AWS Glue versão 4.0
Arquitetura
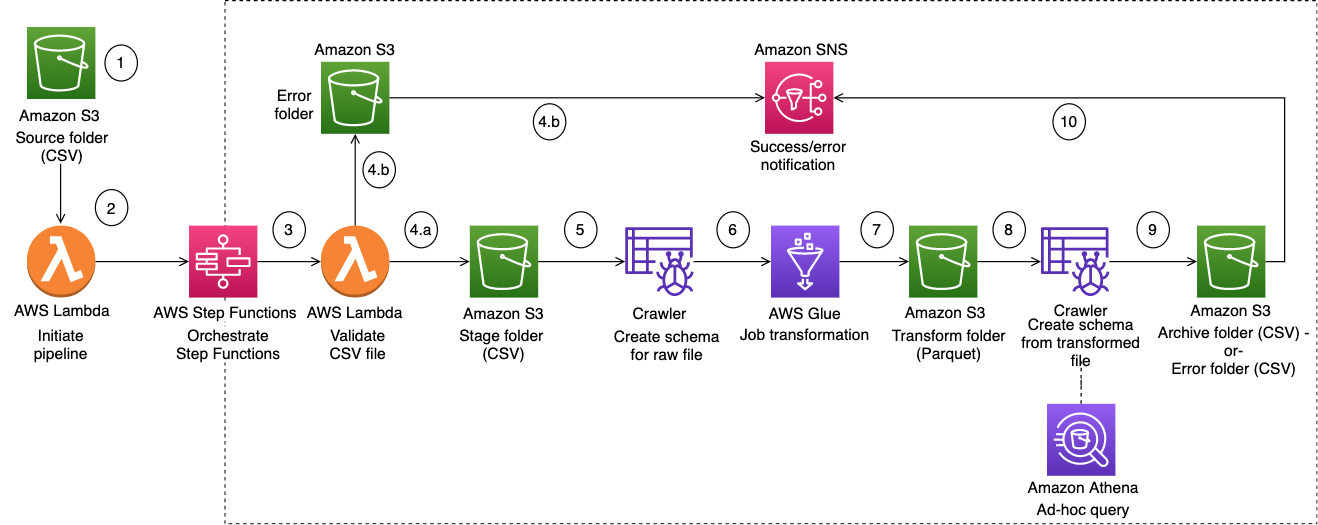
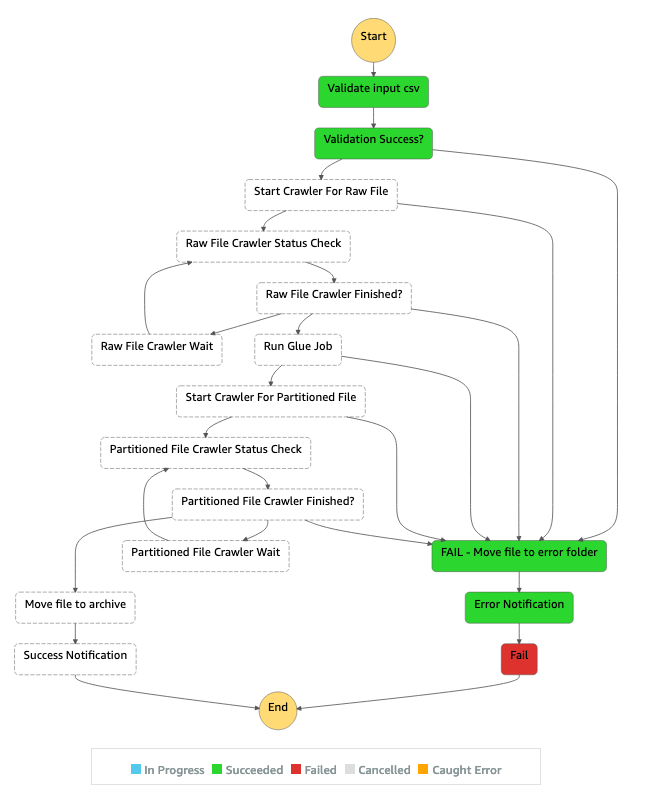
O fluxo de trabalho ilustrado no diagrama consiste nestas etapas de alto nível:
O usuário carrega um arquivo CSV na pasta de origem no Amazon S3.
Um evento de notificação do Amazon S3 inicia uma AWS Lambda função que inicia a AWS Step Functions máquina de estado.
A função do Lambda valida o esquema e o tipo de dados do arquivo CSV bruto.
Dependendo dos resultados da validação:
Se a validação do arquivo de origem for bem-sucedida, o arquivo será movido para a pasta de estágio para processamento adicional.
Se a validação falhar, o arquivo será movido para a pasta de erro e uma notificação de erro será enviada por meio do Amazon Simple Notification Service (Amazon SNS) (Amazon SNS).
Um AWS Glue rastreador cria o esquema do arquivo bruto a partir da pasta de estágio no Amazon S3.
Um AWS Glue trabalho transforma, compacta e particiona o arquivo bruto no formato Parquet.
O AWS Glue trabalho também move o arquivo para a pasta de transformação no Amazon S3.
O AWS Glue rastreador cria o esquema a partir do arquivo transformado. O esquema resultante pode ser usado por qualquer trabalho de análise. Você pode usar o Amazon Athena para realizar consultas ad-hoc.
Se o pipeline for concluído sem erros, o arquivo do esquema será movido para a pasta de arquivamento. Se algum erro for encontrado, o arquivo será movido para a pasta de erros.
O Amazon SNS envia uma notificação que indica sucesso ou falha com base no status de conclusão do pipeline.
Todos os AWS recursos usados nesse padrão não têm servidor. Não há servidores para gerenciar.
Ferramentas
Serviços da AWS
AWS Glue
— AWS Glue é um serviço de ETL totalmente gerenciado que facilita que os clientes preparem e carreguem seus dados para análise. AWS Step Functions
— AWS Step Functions é um serviço de orquestração sem servidor que permite combinar AWS Lambda funções e outras Serviços da AWS para criar aplicativos essenciais para os negócios. Por meio do console AWS Step Functions gráfico, você vê o fluxo de trabalho do seu aplicativo como uma série de etapas orientadas por eventos. Amazon S3
: o Amazon Simple Storage Service (Amazon S3) é um serviço de armazenamento de objetos que oferece escalabilidade líder do setor, disponibilidade de dados, segurança e performance. Amazon SNS
— O Amazon Simple Notification Service (Amazon SNS) é um serviço de mensagens altamente disponível, durável, seguro e totalmente pub/sub gerenciado que permite dissociar microsserviços, sistemas distribuídos e aplicativos sem servidor. AWS Lambda
— AWS Lambda é um serviço de computação que permite executar código sem provisionar ou gerenciar servidores. AWS Lambda executa seu código somente quando necessário e escala automaticamente, de algumas solicitações por dia a milhares por segundo.
Código
O código desse padrão está disponível em GitHub, no ETL Pipeline com AWS Step Functions
template.yml— AWS CloudFormation modelo para criar o pipeline ETL com AWS Step Functions.parameter.json: contém todos os parâmetros e valores de parâmetros. Você atualiza esse arquivo para alterar os valores dos parâmetros, conforme descrito na seção Épicos.myLayer/pythonpasta — Contém os pacotes Python necessários para criar a AWS Lambda camada necessária para este projeto.A pasta
lambda: contém as seguintes funções do Lambda:move_file.py: move o conjunto de dados de origem para a pasta de arquivamento, transformação ou erro.check_crawler.py— Verifica o status do AWS Glue rastreador quantas vezes for configurado pela variável deRETRYLIMITambiente antes de enviar uma mensagem de falha.start_crawler.py— Inicia o AWS Glue rastreador.start_step_function.py— Começa AWS Step Functions.start_codebuild.py— Inicia o AWS CodeBuild projeto.validation.py: valida o conjunto de dados brutos de entrada.s3object.py— Cria a estrutura de diretórios necessária dentro do bucket do Amazon S3.notification.py: envia notificações de sucesso ou erro no final do pipeline.
Para usar o código de amostra, siga as instruções na seção Épicos.
Épicos
| Tarefa | Descrição | Habilidades necessárias |
|---|---|---|
Clone o repositório de código de amostra. |
| Desenvolvedor |
Atualizar valores de parâmetro. | Na sua cópia local do repositório, edite o arquivo
| Desenvolvedor |
Faça o upload do código-fonte no bucket do Amazon S3. | Antes de implantar o AWS CloudFormation modelo que automatiza o pipeline de ETL, você deve empacotar os arquivos de origem do modelo e enviá-los para um bucket do Amazon S3. Para fazer isso, execute o seguinte AWS CLI comando com seu perfil pré-configurado:
em que:
| Desenvolvedor |
| Tarefa | Descrição | Habilidades necessárias |
|---|---|---|
Implante o CloudFormation modelo. | Para implantar o AWS CloudFormation modelo, execute o seguinte AWS CLI comando:
em que:
| Desenvolvedor |
Verifique o andamento. | No AWS CloudFormation console | Desenvolvedor |
Anote o nome do AWS Glue banco de dados. | A guia Saídas da pilha exibe o nome do banco de dados. AWS Glue O nome da chave é | Desenvolvedor |
| Tarefa | Descrição | Habilidades necessárias |
|---|---|---|
Inicie o pipeline de ETL. |
| Desenvolvedor |
Verifique o conjunto de dados particionado. | Quando o pipeline de ETL for concluído, verifique se o conjunto de dados particionado está disponível na pasta de transformação do Amazon S3 ( | Desenvolvedor |
Verifique o AWS Glue banco de dados particionado. |
| Desenvolvedor |
Executar consultas. | (Opcional) Use o Amazon Athena para executar consultas ad-hoc no banco de dados particionado e transformado. Para obter instruções, consulte Executar consultas SQL no Amazon Athena na AWS documentação. | Analista de banco de dados |
Solução de problemas
| Problema | Solução |
|---|---|
AWS Identity and Access Management Permissões (IAM) para o AWS Glue trabalho e o rastreador | Se você personalizar ainda mais o AWS Glue trabalho ou o rastreador, certifique-se de conceder as permissões apropriadas do IAM na função do IAM usada pelo AWS Glue trabalho ou fornecer permissões de dados para. AWS Lake Formation Para obter mais informações, consulte a documentação do AWS. |
Recursos relacionados
AWS service (Serviço da AWS) documentação
Mais informações
O diagrama a seguir mostra o AWS Step Functions fluxo de trabalho de um pipeline ETL bem-sucedido, a partir do painel AWS Step Functions Inspector.
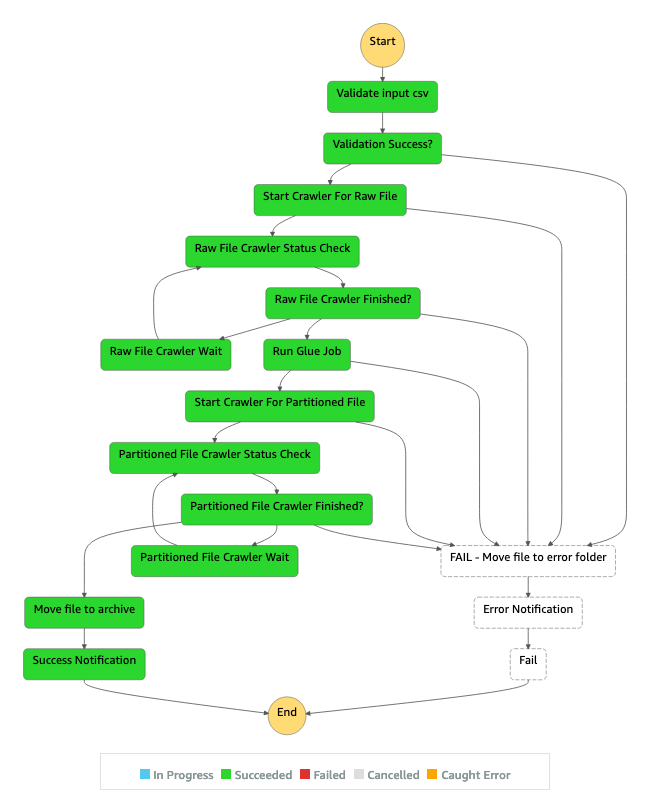
O diagrama a seguir mostra o AWS Step Functions fluxo de trabalho de um pipeline de ETL que falha devido a um erro de validação de entrada, no painel Step Functions Inspector.