As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Componentes de arquitetura de um data warehouse do Amazon Redshift
Recomendamos que você tenha uma compreensão básica dos principais componentes da arquitetura em um data warehouse do Amazon Redshift. Esse conhecimento pode ajudá-lo a entender melhor como criar suas consultas e tabelas para obter um desempenho ideal.
Um data warehouse no Amazon Redshift consiste nos seguintes componentes principais da arquitetura:
-
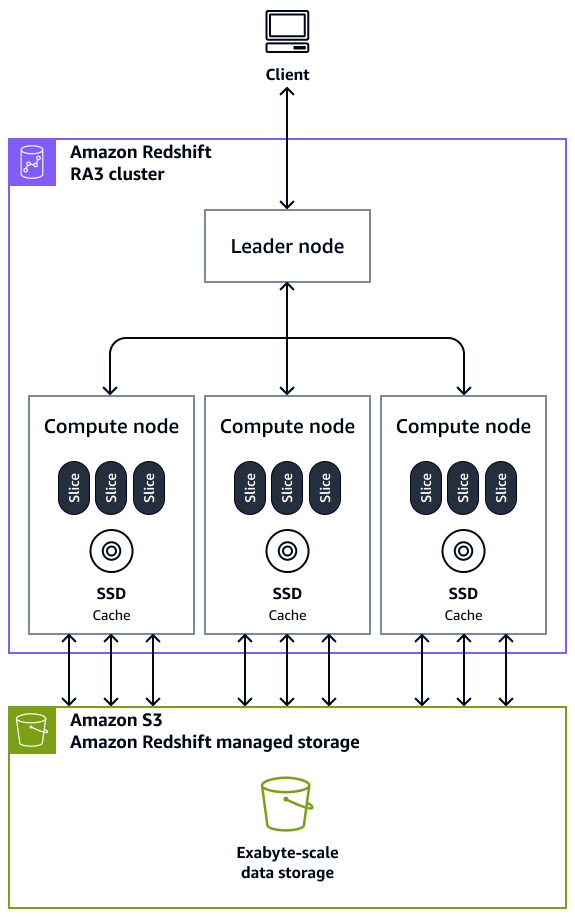
Clusters — Um cluster, composto por um ou mais nós de computação, é o principal componente da infraestrutura de um data warehouse do Amazon Redshift. Os nós de computação são transparentes para aplicativos externos, mas seu aplicativo cliente interage diretamente somente com o nó líder. Um cluster típico tem dois ou mais nós de computação. Os nós de computação são coordenados por meio do nó líder.
-
Nó líder — Um nó líder gerencia as comunicações dos programas clientes e de todos os nós de computação. Um nó líder também prepara os planos para executar uma consulta sempre que uma consulta for enviada a um cluster. Depois que os planos estiverem prontos, o nó líder compila o código, distribui o código compilado para os nós de computação e, em seguida, atribui fatias de dados a cada nó de computação para processar os resultados da consulta.
-
Nó de computação — Um nó de computação executa uma consulta. O nó líder compila o código para elementos individuais do plano para executar a consulta e atribui o código a nós de computação individuais. Os nós de computação executam o código compilado e reenviam os resultados intermediários ao nó líder para agregação final. Cada nó de computação tem sua própria CPU dedicada, memória e armazenamento em disco conectado. À medida que o workload cresce, você pode aumentar a capacidade computacional e a capacidade de armazenamento de um cluster aumentando o número de nós, atualizando o tipo de nó ou ambos.
-
Fatia do nó — um nó de computação é particionado em unidades chamadas fatias. Cada fatia em um nó de computação recebe uma parte da memória e do espaço em disco do nó, onde processa uma parte da carga de trabalho atribuída ao nó. Assim, as fatias funcionam em paralelo para completar a operação. Os dados são distribuídos entre fatias com base no estilo de distribuição e na chave de distribuição de uma tabela específica. Uma distribuição uniforme dos dados possibilita que o Amazon Redshift atribua uniformemente cargas de trabalho às fatias e maximize os benefícios do processamento paralelo. O número de fatias por nó de computação é decidido com base no tipo de nó. Para obter mais informações, consulte Clusters e nós no Amazon Redshift na documentação do Amazon Redshift.
-
Processamento paralelo massivo (MPP) — O Amazon Redshift usa a arquitetura MPP para processar dados rapidamente, até mesmo consultas complexas e grandes quantidades de dados. Vários nós de computação executam o mesmo código de consulta em partes dos dados para maximizar o processamento paralelo.
-
Aplicativo cliente — O Amazon Redshift se integra a várias ferramentas de extração, transformação e carregamento (ETL), relatórios de business intelligence (BI), mineração de dados e análise. Todos os aplicativos cliente se comunicam com o cluster somente por meio do nó principal.
O diagrama a seguir mostra como os componentes de arquitetura de um data warehouse do Amazon Redshift trabalham juntos para acelerar as consultas.