As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Caso de uso: previsão de resultados de pacientes e taxas de readmissão
A análise preditiva baseada em IA oferece mais benefícios ao prever os resultados dos pacientes e permitir planos de tratamento personalizados. Isso pode melhorar a satisfação do paciente e os resultados de saúde. Ao integrar esses recursos de IA com o Amazon Bedrock e outras tecnologias, os profissionais de saúde podem obter ganhos significativos de produtividade, reduzir custos e elevar a qualidade geral do atendimento ao paciente.
Você pode armazenar dados médicos, como históricos de pacientes, notas clínicas, medicamentos e tratamentos, em um gráfico de conhecimento
Essa solução ajuda você a prever a probabilidade de uma readmissão. Essas previsões podem melhorar os resultados dos pacientes e reduzir os custos de saúde. Essa solução também pode ajudar os médicos e administradores do hospital a concentrarem sua atenção nos pacientes com maior risco de readmissão. Também os ajuda a iniciar intervenções proativas com esses pacientes por meio de alertas, autoatendimento e ações baseadas em dados.
Visão geral da solução
Essa solução usa uma estrutura de geração aumentada de recuperação múltipla (RAG) para analisar os dados do paciente. Ele prevê a probabilidade de readmissão hospitalar para pacientes individuais e ajuda a calcular uma pontuação de propensão à readmissão em nível hospitalar. Essa solução integra os seguintes recursos:
-
Gráfico de conhecimento — armazena dados estruturados e cronológicos do paciente, como consultas hospitalares, readmissões anteriores, sintomas, resultados laboratoriais, tratamentos prescritos e histórico de adesão à medicação
-
Banco de dados vetorial — armazena dados clínicos não estruturados, como resumos de alta, anotações médicas e registros de consultas perdidas ou efeitos colaterais de medicamentos relatados
-
LLM ajustado — Consome dados estruturados do gráfico de conhecimento e dados não estruturados do banco de dados vetoriais para gerar inferências sobre o comportamento do paciente, a adesão ao tratamento e a probabilidade de readmissão
Os modelos de pontuação de risco quantificam as inferências do LLM em pontuações numéricas. Você pode agregar as pontuações em uma pontuação de propensão à readmissão em nível hospitalar. Essa pontuação define a exposição ao risco de cada paciente e você pode calculá-la periodicamente ou conforme necessário. Todas as inferências e pontuações de risco são indexadas e armazenadas no Amazon OpenSearch Service para que os gerentes de atendimento e médicos possam recuperá-las. Ao integrar um agente de IA conversacional a esse banco de dados vetorial, médicos e gerentes de atendimento podem extrair facilmente insights em nível de paciente individual, de toda a instalação ou por especialidade médica. Você também pode configurar alertas automatizados com base nas pontuações de risco, o que incentiva intervenções proativas.
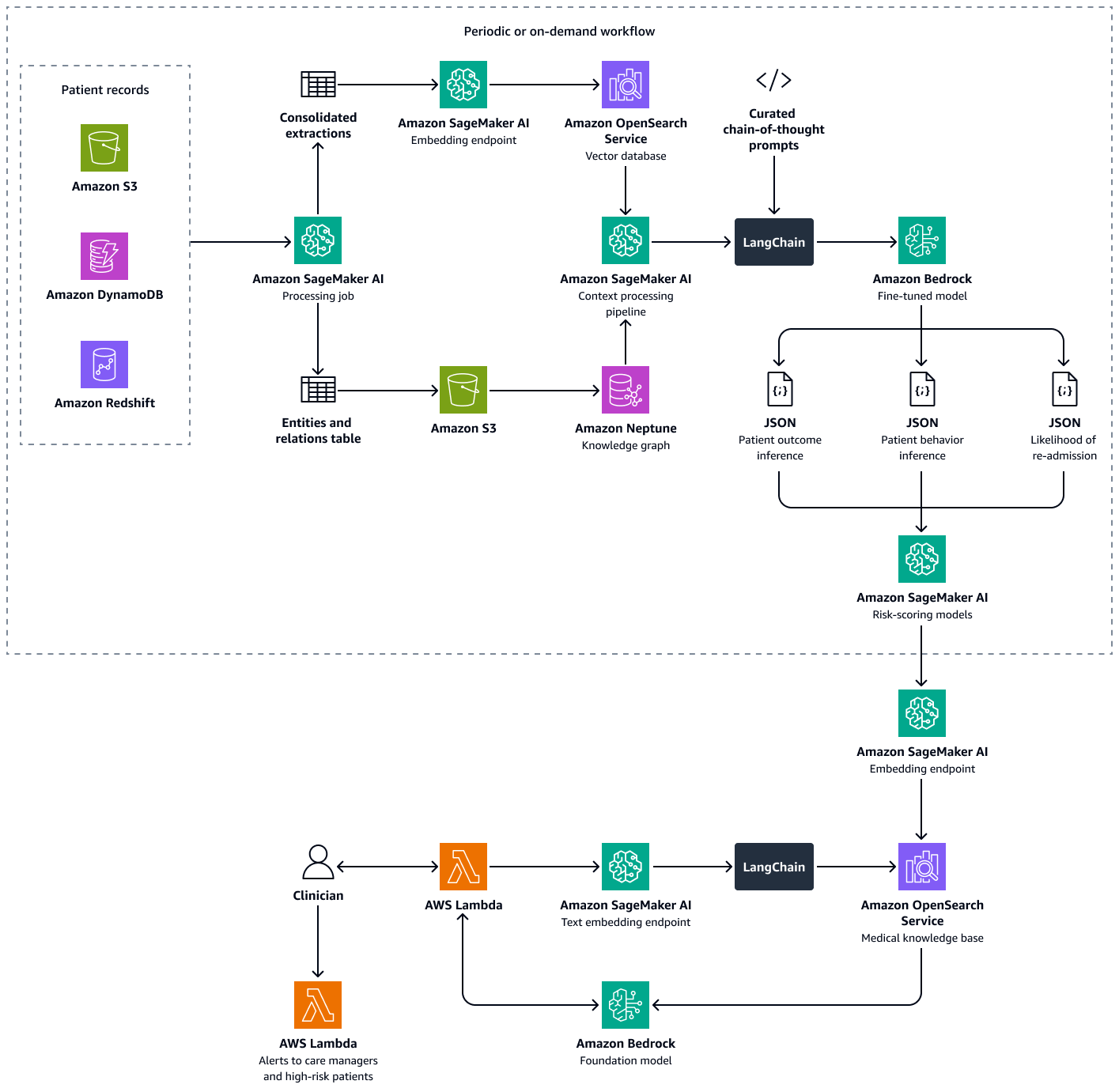
A criação dessa solução consiste nas seguintes etapas:
Etapa 1: Prever os resultados dos pacientes usando um gráfico de conhecimento médico
No Amazon Neptune, você pode usar um gráfico de conhecimento para armazenar conhecimento temporal sobre visitas de pacientes e resultados ao longo do tempo. A maneira mais eficaz de criar e armazenar um gráfico de conhecimento é usar um modelo gráfico e um banco de dados gráfico. Os bancos de dados gráficos são criados especificamente para armazenar e navegar por relacionamentos. Os bancos de dados gráficos facilitam a modelagem e o gerenciamento de dados altamente conectados e têm esquemas flexíveis.
O gráfico de conhecimento ajuda você a realizar análises de séries temporais. A seguir estão os principais elementos do banco de dados gráfico que são usados para predição temporal dos resultados dos pacientes:
-
Dados históricos — Diagnósticos anteriores, medicamentos contínuos, medicamentos usados anteriormente e resultados laboratoriais para o paciente
-
Visitas ao paciente (cronológicas) — Datas das visitas, sintomas, alergias observadas, notas clínicas, diagnósticos, procedimentos, tratamentos, medicamentos prescritos e resultados laboratoriais
-
Sintomas e parâmetros clínicos — Informações clínicas e baseadas em sintomas, incluindo gravidade, padrões de progressão e a resposta do paciente ao medicamento
Você pode usar os insights do gráfico de conhecimento médico para ajustar um LLM no Amazon Bedrock, como o Llama 3. Você ajusta o LLM com dados sequenciais do paciente sobre a resposta do paciente a um conjunto de medicamentos ou tratamentos ao longo do tempo. Use um conjunto de dados rotulado que classifique um conjunto de medicamentos ou tratamentos e dados de interação paciente-clínica em categorias predefinidas que indicam o estado de saúde de um paciente. Exemplos dessas categorias são deterioração da saúde, melhora ou progresso estável. Quando o médico insere um novo contexto sobre o paciente e seus sintomas, o LLM ajustado pode usar os padrões do conjunto de dados de treinamento para prever o resultado potencial do paciente.
A imagem a seguir mostra as etapas sequenciais envolvidas no ajuste fino de um LLM no Amazon Bedrock usando um conjunto de dados de treinamento específico da área de saúde. Esses dados podem incluir condições médicas do paciente e respostas aos tratamentos ao longo do tempo. Esse conjunto de dados de treinamento ajudaria o modelo a fazer previsões generalizadas sobre os resultados dos pacientes.
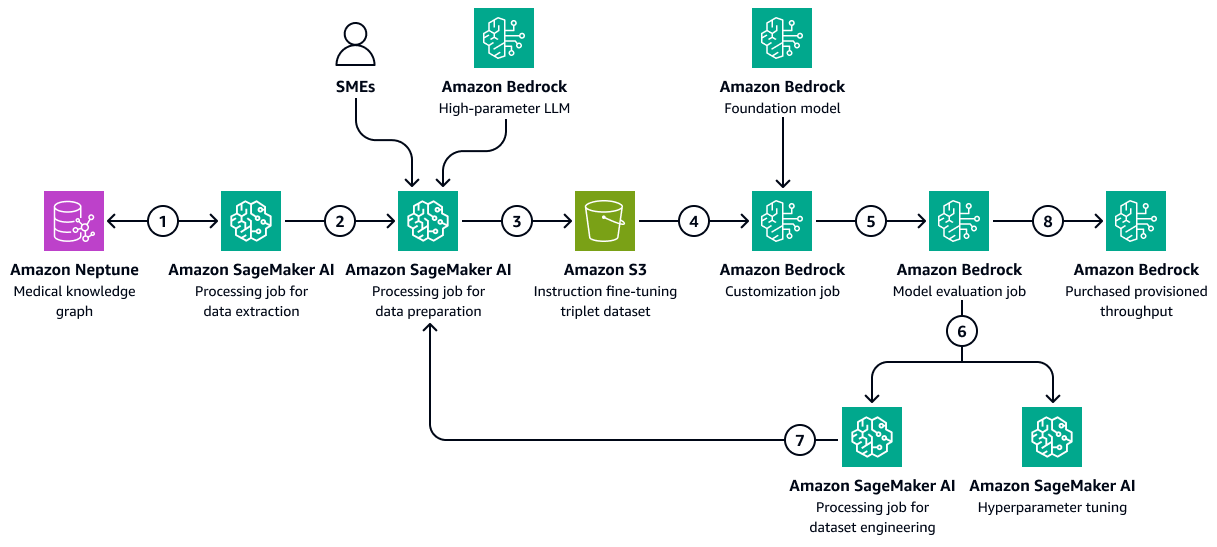
O diagrama mostra o seguinte fluxo de trabalho:
-
O trabalho de extração de dados da Amazon SageMaker AI consulta o gráfico de conhecimento para recuperar dados cronológicos sobre as respostas de diferentes pacientes a um conjunto de medicamentos ou tratamentos ao longo do tempo.
-
O trabalho de preparação de dados de SageMaker IA integra um Amazon Bedrock LLM e contribuições de especialistas no assunto (). SMEs O trabalho classifica os dados recuperados do gráfico de conhecimento em categorias predefinidas (como deterioração da saúde, melhora ou progresso estável) que indicam o estado de saúde de cada paciente.
-
O trabalho cria um conjunto de dados de ajuste fino que inclui as informações extraídas do gráfico de conhecimento, as chain-of-thought solicitações e a categoria de resultados do paciente. Ele carrega esse conjunto de dados de treinamento em um bucket do Amazon S3.
-
Um trabalho de personalização do Amazon Bedrock usa esse conjunto de dados de treinamento para ajustar um LLM.
-
O trabalho de personalização do Amazon Bedrock integra o modelo básico preferido do Amazon Bedrock ao ambiente de treinamento. Ele inicia o trabalho de ajuste fino e usa o conjunto de dados de treinamento e os hiperparâmetros de treinamento que você configura.
-
Um trabalho de avaliação do Amazon Bedrock avalia o modelo ajustado usando uma estrutura de avaliação de modelo pré-projetada.
-
Se o modelo precisar ser aprimorado, o trabalho de treinamento será executado novamente com mais dados após uma análise cuidadosa do conjunto de dados de treinamento. Se o modelo não demonstrar melhoria incremental no desempenho, considere também a modificação dos hiperparâmetros de treinamento.
-
Depois que a avaliação do modelo atender aos padrões definidos pelas partes interessadas da empresa, você hospeda o modelo ajustado para a taxa de transferência provisionada do Amazon Bedrock.
Etapa 2: Prever o comportamento do paciente em relação aos medicamentos ou tratamentos prescritos
O Fine-Tuned LLMs pode processar notas clínicas, resumos de alta e outros documentos específicos do paciente a partir do gráfico de conhecimento médico temporal. Eles podem avaliar se é provável que o paciente siga os medicamentos ou tratamentos prescritos.
Essa etapa usa o gráfico de conhecimento criado emEtapa 1: Prever os resultados dos pacientes usando um gráfico de conhecimento médico. O gráfico de conhecimento contém dados do perfil do paciente, incluindo a adesão histórica do paciente como nódulo. Também inclui casos de não adesão a medicamentos ou tratamentos, efeitos colaterais aos medicamentos, falta de acesso ou barreiras de custo aos medicamentos ou regimes de dosagem complexos como atributos desses linfonodos.
O Fine-Tuned LLMs pode consumir dados anteriores de atendimento de prescrições do gráfico de conhecimento médico e resumos descritivos das notas clínicas de um banco de dados vetoriais do Amazon Service. OpenSearch Essas notas clínicas podem mencionar consultas frequentemente perdidas ou não adesão aos tratamentos. O LLM pode usar essas notas para prever a probabilidade de não adesão futura.
-
Prepare os dados de entrada da seguinte forma:
-
Dados estruturados — Extraia dados recentes do paciente, como as últimas três visitas e os resultados do laboratório, do gráfico de conhecimento médico.
-
Dados não estruturados — Recupere as notas clínicas recentes do banco de dados vetoriais do Amazon OpenSearch Service.
-
-
Crie um prompt de entrada que inclua o histórico do paciente e o contexto atual. Veja a seguir um exemplo de prompt:
You are a highly specialized AI model trained in healthcare predictive analytics. Your task is to analyze a patient's historical medical records, adherence patterns, and clinical context to predict the **likelihood of future non-adherence** to prescribed medications or treatments. ### **Patient Details** - **Patient ID:** {patient_id} - **Age:** {age} - **Gender:** {gender} - **Medical Conditions:** {medical_conditions} - **Current Medications:** {current_medications} - **Prescribed Treatments:** {prescribed_treatments} ### **Chronological Medical History** - **Visit Dates & Symptoms:** {visit_dates_symptoms} - **Diagnoses & Procedures:** {diagnoses_procedures} - **Prescribed Medications & Treatments:** {medications_treatments} - **Past Adherence Patterns:** {historical_adherence} - **Instances of Non-Adherence:** {past_non_adherence} - **Side Effects Experienced:** {side_effects} - **Barriers to Adherence (e.g., Cost, Access, Dosing Complexity):** {barriers} ### **Patient-Specific Insights** - **Clinical Notes & Discharge Summaries:** {clinical_notes} - **Missed Appointments & Non-Compliance Patterns:** {missed_appointments} ### **Let's think Step-by-Step to predict the patient behaviour** 1. You should first analyze past adherence trends and patterns of non-adherence. 2. Identify potential barriers, such as financial constraints, medication side effects, or complex dosing regimens. 3. Thoroughly examine clinical notes and documented patient behaviors that may hint at non-adherence. 4. Correlate adherence history with prescribed treatments and patient conditions. 5. Finally predict the likelihood of non-adherence based on these contextual insights. ### **Output Format (JSON)** Return the prediction in the following structured format: ```json { "patient_id": "{patient_id}", "likelihood_of_non_adherence": "{low | moderate | high}", "reasoning": "{detailed_explanation_based_on_patient_history}" } -
Passe o prompt para o LLM ajustado. O LLM processa a solicitação e prevê o resultado. Veja a seguir um exemplo de resposta do LLM:
{ "patient_id": "P12345", "likelihood_of_non_adherence": "high", "reasoning": "The patient has a history of missed appointments, has reported side effects to previous medications. Additionally, clinical notes indicate difficulty following complex dosing schedules." } -
Analise a resposta do modelo para extrair a categoria de resultado previsto. Por exemplo, a categoria do exemplo de resposta na etapa anterior pode ser a de alta probabilidade de não adesão.
-
(Opcional) Use logits de modelo ou métodos adicionais para atribuir pontuações de confiança. Logits são as probabilidades não normalizadas do item pertencer a uma determinada classe ou categoria.
Etapa 3: Prever a probabilidade de readmissão do paciente
As readmissões hospitalares são uma grande preocupação devido ao alto custo da administração da saúde e ao seu impacto no bem-estar do paciente. O cálculo das taxas de readmissão hospitalar é uma forma de medir a qualidade do atendimento ao paciente e o desempenho de um profissional de saúde.
Para calcular a taxa de readmissão, você definiu um indicador, como uma taxa de readmissão de 7 dias. Esse indicador é a porcentagem de pacientes internados que retornam ao hospital para uma visita não planejada dentro de sete dias após a alta. Para prever a chance de readmissão de um paciente, um LLM ajustado pode consumir dados temporais do gráfico de conhecimento médico que você criou em. Etapa 1: Prever os resultados dos pacientes usando um gráfico de conhecimento médico Esse gráfico de conhecimento mantém registros cronológicos de encontros com pacientes, procedimentos, medicamentos e sintomas. Esses registros de dados contêm o seguinte:
-
Duração do tempo desde a última alta do paciente
-
A resposta do paciente aos tratamentos e medicamentos anteriores
-
A progressão dos sintomas ou condições ao longo do tempo
Você pode processar esses eventos de séries temporais para prever a probabilidade de readmissão de um paciente por meio de um prompt de sistema organizado. O prompt transmite a lógica de previsão ao LLM ajustado.
-
Prepare os dados de entrada da seguinte forma:
-
Histórico de adesão — Extraia datas de coleta de medicamentos, frequências de recarga de medicamentos, detalhes de diagnóstico e medicação, histórico médico cronológico e outras informações do gráfico de conhecimento médico.
-
Indicadores comportamentais — Recupere e inclua notas clínicas sobre consultas perdidas e efeitos colaterais relatados pelo paciente.
-
-
Crie um prompt de entrada que inclua o histórico de adesão e os indicadores comportamentais. Veja a seguir um exemplo de prompt:
You are a highly specialized AI model trained in healthcare predictive analytics. Your task is to analyze a patient's historical medical records, clinical events, and adherence patterns to predict the **likelihood of hospital readmission** within the next few days. ### **Patient Details** - **Patient ID:** {patient_id} - **Age:** {age} - **Gender:** {gender} - **Primary Diagnoses:** {diagnoses} - **Current Medications:** {current_medications} - **Prescribed Treatments:** {prescribed_treatments} ### **Chronological Medical History** - **Recent Hospital Encounters:** {encounters} - **Time Since Last Discharge:** {time_since_last_discharge} - **Previous Readmissions:** {past_readmissions} - **Recent Lab Results & Vital Signs:** {recent_lab_results} - **Procedures Performed:** {procedures_performed} - **Prescribed Medications & Treatments:** {medications_treatments} - **Past Adherence Patterns:** {historical_adherence} - **Instances of Non-Adherence:** {past_non_adherence} ### **Patient-Specific Insights** - **Clinical Notes & Discharge Summaries:** {clinical_notes} - **Missed Appointments & Non-Compliance Patterns:** {missed_appointments} - **Patient-Reported Side Effects & Complications:** {side_effects} ### **Reasoning Process – You have to analyze this use case step-by-step.** 1. First assess **time since last discharge** and whether recent hospital encounters suggest a pattern of frequent readmissions. 2. Second examine **recent lab results, vital signs, and procedures performed** to identify clinical deterioration. 3. Third analyze **adherence history**, checking if past non-adherence to medications or treatments correlates with readmissions. 4. Then identify **missed appointments, self-reported side effects, or symptoms worsening** from clinical notes. 5. Finally predict the **likelihood of readmission** based on these contextual insights. ### **Output Format (JSON)** Return the prediction in the following structured format: ```json { "patient_id": "{patient_id}", "likelihood_of_readmission": "{low | moderate | high}", "reasoning": "{detailed_explanation_based_on_patient_history}" } -
Passe o prompt para o LLM ajustado. O LLM processa a solicitação e prevê a probabilidade e os motivos da readmissão. Veja a seguir um exemplo de resposta do LLM:
{ "patient_id": "P67890", "likelihood_of_readmission": "high", "reasoning": "The patient was discharged only 5 days ago, has a history of more than two readmissions to hospitals where the patient received treatment. Recent lab results indicate abnormal kidney function and high liver enzymes. These factors suggest a medium risk of readmission." } -
Categorize a previsão em uma escala padronizada, como baixa, média ou alta.
-
Analise o raciocínio fornecido pelo LLM e identifique os principais fatores que contribuem para a previsão.
-
Mapeie os resultados qualitativos para pontuações quantitativas. Por exemplo, muito alto pode ser igual a uma probabilidade de 0,9.
-
Use conjuntos de dados de validação para calibrar as saídas do modelo em relação às taxas reais de readmissão.
Etapa 4: Calcular a pontuação de propensão à readmissão hospitalar
Em seguida, você calcula uma pontuação de propensão à readmissão hospitalar por paciente. Essa pontuação reflete o impacto líquido das três análises realizadas nas etapas anteriores: resultados potenciais do paciente, comportamento do paciente em relação a medicamentos e tratamentos e probabilidade de readmissão do paciente. Ao agregar a pontuação de propensão à readmissão em nível de paciente ao nível de especialidade e, em seguida, ao nível hospitalar, você pode obter informações para médicos, gerentes de cuidados e administradores. A pontuação de propensão à readmissão hospitalar ajuda você a avaliar o desempenho geral por instalação, especialidade ou condição. Em seguida, você pode usar essa pontuação para implementar intervenções proativas.
-
Atribua pesos a cada um dos diferentes fatores (previsão de resultados, probabilidade de adesão, readmissão). A seguir estão exemplos de pesos:
-
Peso da previsão de resultado: 0,4
-
Peso da previsão de aderência: 0,3
-
Peso da probabilidade de readmissão: 0,3
-
-
Use o cálculo a seguir para calcular a pontuação composta:
ReadadmissionPropensityScore= (OutcomeScore×OutcomeWeight) + (AdherenceScore×AdherenceWeight) + (ReadmissionLikelihoodScore×ReadmissionLikelihoodWeight) -
Certifique-se de que todas as pontuações individuais estejam na mesma escala, como 0 a 1.
-
Defina os limites para a ação. Por exemplo, pontuações acima de 0,7 iniciam alertas.
Com base nas análises acima e na pontuação de propensão à readmissão de um paciente, médicos ou gerentes de atendimento podem configurar alertas para monitorar seus pacientes individuais com base na pontuação computada. Se estiver acima de um limite predefinido, eles serão notificados quando esse limite for atingido. Isso ajuda os gerentes de atendimento a serem proativos em vez de reativos ao criar planos de cuidados de alta para seus pacientes. Salve os resultados, o comportamento e as pontuações de propensão à readmissão do paciente em um formato indexado em um banco de dados vetorial do Amazon OpenSearch Service para que os gerentes de atendimento possam recuperá-los facilmente usando um agente conversacional de IA.
O diagrama a seguir mostra o fluxo de trabalho de um agente conversacional de IA que um médico ou gerente de atendimento pode usar para obter informações sobre os resultados dos pacientes, o comportamento esperado e a propensão à readmissão. Os usuários podem recuperar insights no nível do paciente, do departamento ou do hospital. O agente de IA recupera esses insights, que são armazenados em um formato indexado em um banco de dados vetorial do Amazon OpenSearch Service. O agente usa a consulta para recuperar dados relevantes e fornece respostas personalizadas, incluindo ações sugeridas para pacientes com alto risco de readmissão. Com base no nível de risco, o agente também pode configurar lembretes para pacientes e cuidadores.
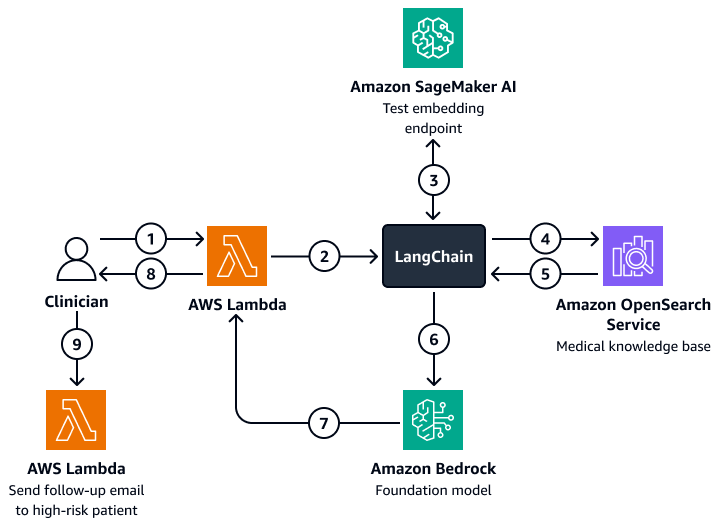
O diagrama mostra o seguinte fluxo de trabalho:
-
O médico faz uma pergunta a um agente conversacional de IA, que abriga uma AWS Lambda função.
-
A função Lambda inicia um LangChain agente.
-
A ferramenta LangChain O agente envia a pergunta do usuário para um endpoint de incorporação de texto do Amazon SageMaker AI. O endpoint incorpora a pergunta.
-
A ferramenta LangChain o agente passa a pergunta incorporada para uma base de conhecimento médico no Amazon OpenSearch Service.
-
O Amazon OpenSearch Service retorna os insights específicos que são mais relevantes para a consulta do usuário para o LangChain agente.
-
A ferramenta LangChain os agentes enviam a consulta e o contexto recuperado da base de conhecimento para um modelo da Amazon Bedrock Foundation.
-
O modelo Amazon Bedrock Foundation gera uma resposta e a envia para a função Lambda.
-
A função Lambda retorna a resposta ao médico.
-
O médico inicia uma função Lambda que envia um e-mail de acompanhamento a um paciente com alto risco de readmissão.
Alinhamento com o AWS Well-Architected Framework
-
Excelência operacional — A solução é um sistema automatizado e desacoplado que usa o Amazon Bedrock e AWS Lambda para alertas em tempo real.
-
Segurança — Essa solução foi projetada para estar em conformidade com os regulamentos de saúde, como o HIPAA. Você também pode implementar criptografia, controle de acesso refinado e grades de proteção Amazon Bedrock para ajudar a proteger os dados dos pacientes.
-
Confiabilidade — A arquitetura usa tolerância a falhas e sem servidor. Serviços da AWS
-
Eficiência de desempenho — o Amazon OpenSearch Service e o fine-tuned LLMs podem fornecer previsões rápidas e precisas.
-
Otimização de custos — tecnologias e pay-per-inference modelos sem servidor ajudam a minimizar os custos. Embora o uso de LLM ajustado possa incorrer em custos extras, o modelo usa uma abordagem RAG que reduz os dados e o tempo computacional necessários para o processo de ajuste fino.
-
Sustentabilidade — A arquitetura minimiza o consumo de recursos por meio do uso da infraestrutura sem servidor. Ele também oferece suporte a operações de saúde eficientes e escaláveis.
