As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Caso de uso: Gerenciando e aprimorando sua equipe de saúde
A implementação de estratégias de transformação e aprimoramento de talentos ajuda as forças de trabalho a permanecerem hábeis no uso de novas tecnologias e práticas em serviços médicos e de saúde. Iniciativas proativas de aprimoramento de habilidades garantem que os profissionais de saúde possam oferecer atendimento de alta qualidade aos pacientes, otimizar a eficiência operacional e manter a conformidade com os padrões regulatórios. Além disso, a transformação de talentos promove uma cultura de aprendizado contínuo. Isso é fundamental para se adaptar às mudanças no cenário da saúde e enfrentar os desafios emergentes da saúde pública. As abordagens tradicionais de treinamento, como o treinamento em sala de aula e os módulos estáticos de aprendizado, oferecem conteúdo uniforme para um público amplo. Eles geralmente carecem de caminhos de aprendizagem personalizados, que são essenciais para atender às necessidades específicas e aos níveis de proficiência de cada profissional. Essa one-size-fits-all estratégia pode resultar em desengajamento e retenção de conhecimento abaixo do ideal.
Consequentemente, as organizações de saúde devem adotar soluções inovadoras, escaláveis e orientadas pela tecnologia que possam determinar a lacuna de cada um de seus funcionários em seu estado atual e em seu estado futuro potencial. Essas soluções devem recomendar caminhos de aprendizagem hiperpersonalizados e o conjunto certo de conteúdo de aprendizagem. Isso prepara efetivamente a força de trabalho para o futuro da saúde.
No setor de saúde, você pode aplicar a IA generativa para ajudá-lo a entender e aprimorar sua força de trabalho. Por meio da conexão de grandes modelos de linguagem (LLMs) e recuperadores avançados, as organizações podem entender quais habilidades possuem atualmente e identificar as principais habilidades que podem ser necessárias no futuro. Essas informações ajudam você a preencher a lacuna contratando novos trabalhadores e aprimorando a força de trabalho atual. Usando o Amazon Bedrock e os gráficos de conhecimento, as organizações de saúde podem desenvolver aplicativos específicos de domínio que facilitam o aprendizado contínuo e o desenvolvimento de habilidades.
O conhecimento fornecido por essa solução ajuda você a gerenciar talentos de forma eficaz, otimizar o desempenho da força de trabalho, impulsionar o sucesso organizacional, identificar as habilidades existentes e criar uma estratégia de talentos. Essa solução pode ajudá-lo a realizar essas tarefas em semanas, em vez de meses.
Visão geral da solução
Essa solução é uma estrutura de transformação de talentos da área de saúde que consiste nos seguintes componentes:
-
Analisador inteligente de currículos — Esse componente pode ler o currículo de um candidato e extrair com precisão as informações do candidato, incluindo habilidades. Solução inteligente de extração de informações criada usando o modelo Llama 2 ajustado no Amazon Bedrock em um conjunto de dados de treinamento proprietário que abrange currículos e perfis de talentos de mais de 19 setores. Esse processo baseado em LLM economiza centenas de horas automatizando o processo de revisão manual de currículos e combinando os melhores candidatos com as vagas abertas.
-
Gráfico de conhecimento — Um gráfico de conhecimento criado no Amazon Neptune, um repositório unificado de informações sobre talentos, incluindo a taxonomia de funções e habilidades da organização e do setor, capturando a semântica dos talentos da área de saúde usando definições de habilidades, funções e suas propriedades, relações e restrições lógicas.
-
Ontologia de habilidades — A descoberta da proximidade de habilidades entre as habilidades do candidato e as habilidades ideais do estado atual ou do futuro (recuperadas usando um gráfico de conhecimento) é obtida por meio de algoritmos de ontologia que medem a semelhança semântica entre as habilidades do candidato e as habilidades do estado-alvo.
-
Caminho e conteúdo de aprendizado — Esse componente é um mecanismo de recomendação de aprendizado que pode recomendar o conteúdo de aprendizado correto a partir de um catálogo de materiais didáticos de qualquer fornecedor, com base nas lacunas de habilidades identificadas. Identificar os melhores caminhos de aprimoramento de habilidades para cada candidato, analisando as lacunas de habilidades e recomendando conteúdo de aprendizagem priorizado, para permitir um desenvolvimento profissional contínuo e contínuo para cada candidato durante a transição para uma nova função.
Essa solução automatizada baseada em nuvem é alimentada por serviços de aprendizado de máquina LLMs, gráficos de conhecimento e Geração Aumentada de Recuperação (RAG). Ele pode ser escalado para processar dezenas ou milhares de currículos em um período mínimo de tempo, criar perfis instantâneos de candidatos, identificar lacunas em seu estado futuro atual ou potencial e, em seguida, recomendar com eficiência o conteúdo de aprendizagem certo para preencher essas lacunas.
A imagem a seguir mostra o end-to-end fluxo da estrutura. A solução foi desenvolvida e aperfeiçoada no LLMs Amazon Bedrock. Eles LLMs recuperam dados da base de conhecimento de talentos da área de saúde no Amazon Neptune. Algoritmos baseados em dados fazem recomendações para caminhos de aprendizagem ideais para cada candidato.
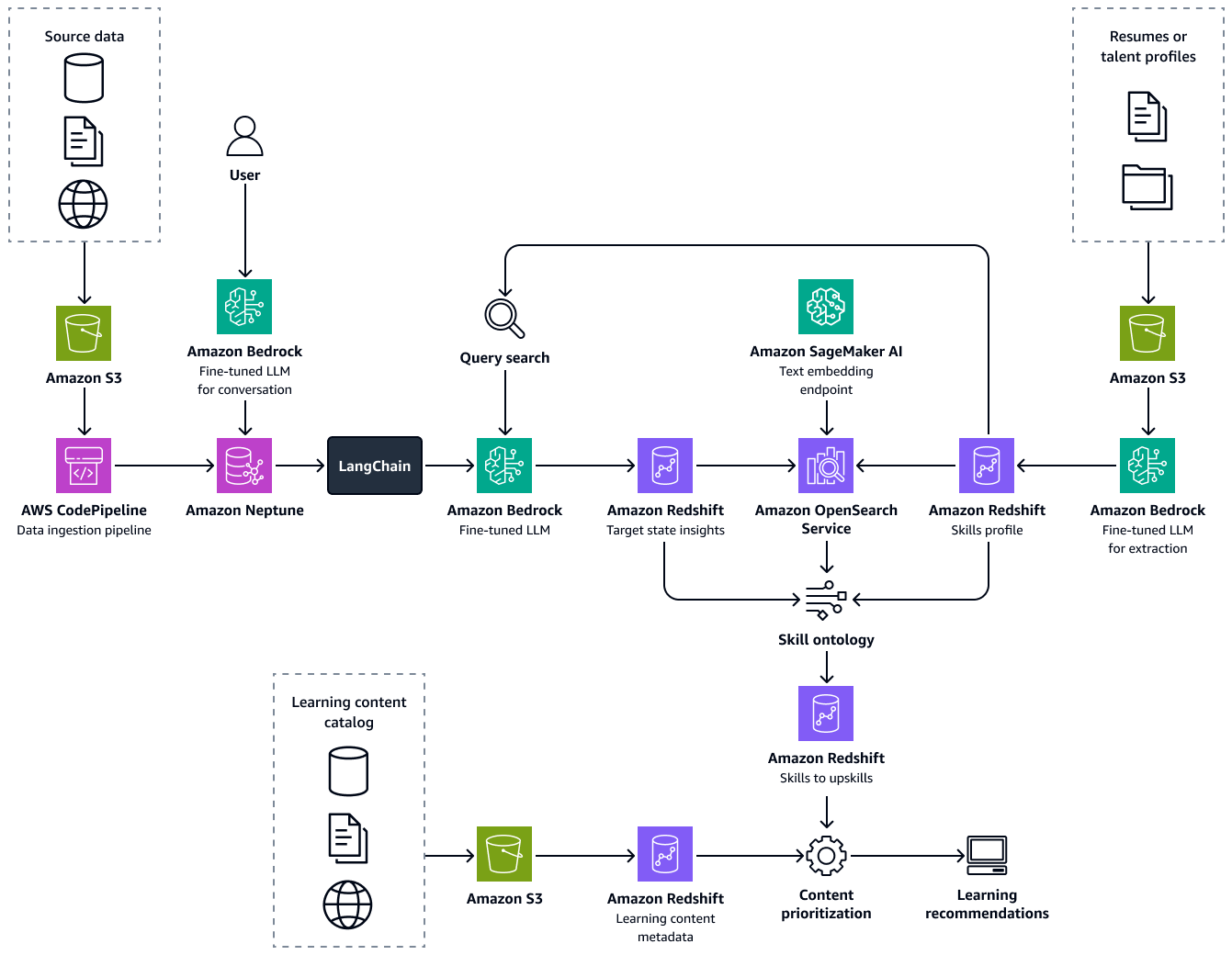
A criação dessa solução consiste nas seguintes etapas:
Etapa 1: Extrair informações sobre talentos e criar um perfil de habilidades
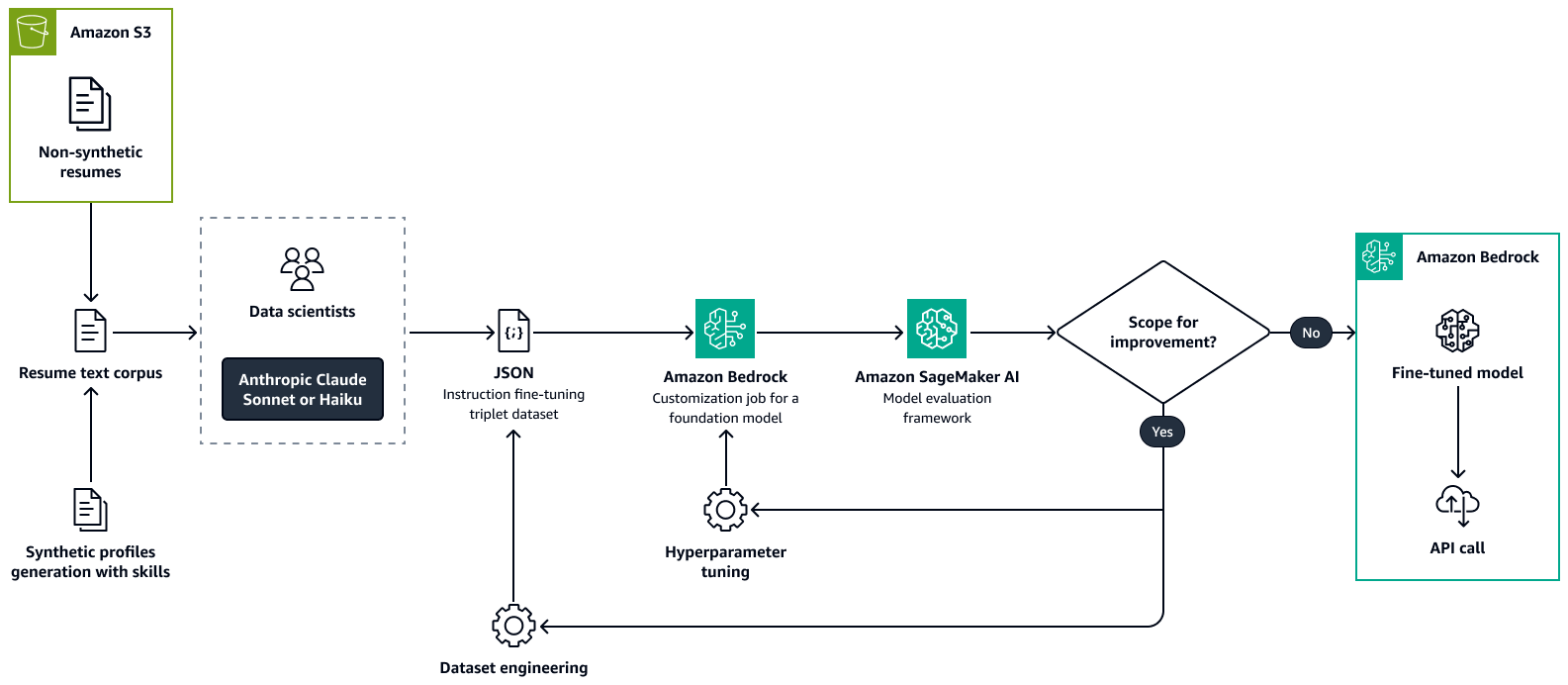
Primeiro, você ajusta um grande modelo de linguagem, como o Llama 2, no Amazon Bedrock com um conjunto de dados personalizado. Isso adapta o LLM para o caso de uso. Durante o treinamento, você extrai de forma precisa e consistente os principais atributos de talento dos currículos dos candidatos ou perfis de talentos semelhantes. Esses atributos de talento incluem habilidades, cargo atual, títulos de experiência com datas, educação e certificações. Para obter mais informações, consulte Personalizar seu modelo para melhorar seu desempenho para seu caso de uso na documentação do Amazon Bedrock.
A imagem a seguir mostra o processo para ajustar um modelo de análise de currículo usando o Amazon Bedrock. Os currículos reais e criados sinteticamente são passados para um LLM para extrair informações importantes. Um grupo de cientistas de dados valida as informações extraídas em relação ao texto original e bruto. As informações extraídas são então concatenadas usando a chain-of-thought
Etapa 2: Descobrir a role-to-skill relevância em um gráfico de conhecimento
Em seguida, você cria um gráfico de conhecimento que encapsula as habilidades e a taxonomia de funções de sua organização e de outras organizações do setor de saúde. Essa base de conhecimento enriquecida é obtida a partir de dados agregados de talentos e organizações no Amazon Redshift. Você pode coletar dados de talentos de uma variedade de provedores de dados do mercado de trabalho e de fontes de dados estruturadas e não estruturadas específicas da organização, como sistemas de planejamento de recursos corporativos (ERP), um sistema de informações de recursos humanos (HRIS), currículos de funcionários, descrições de cargos e documentos de arquitetura de talentos.
Crie o gráfico de conhecimento no Amazon Neptune. Os nós representam habilidades e funções, e as bordas representam as relações entre eles. Enriqueça esse gráfico com metadados para incluir detalhes como nome da organização, setor, família de cargos, tipo de habilidade, tipo de função e etiquetas do setor.
Em seguida, você desenvolve um aplicativo Graph Retrieval Augmented Generation (Graph RAG). O Graph RAG é uma abordagem RAG que recupera dados de um banco de dados gráfico. A seguir estão os componentes do aplicativo Graph RAG:
-
Integração com um LLM no Amazon Bedrock — O aplicativo usa um LLM no Amazon Bedrock para compreensão da linguagem natural e geração de consultas. Os usuários podem interagir com o sistema usando linguagem natural. Isso o torna acessível a partes interessadas não técnicas.
-
Orquestração e recuperação de informações — Uso ou LlamaIndex
LangChain orquestradores para facilitar a integração entre o LLM e o gráfico de conhecimento de Neptune. Eles gerenciam o processo de conversão de consultas de linguagem natural em consultas OpenCypher . Em seguida, eles executam as consultas no gráfico de conhecimento. Use engenharia imediata para instruir o LLM sobre as melhores práticas para criar consultas OpenCypher. Isso ajuda a otimizar as consultas para recuperar o subgráfico relevante, que contém todas as entidades e relacionamentos pertinentes sobre as funções e habilidades consultadas. -
Geração de insights — O LLM no Amazon Bedrock processa os dados gráficos recuperados. Ele gera insights detalhados sobre o estado atual e projeta os estados futuros da função consultada e das habilidades associadas.
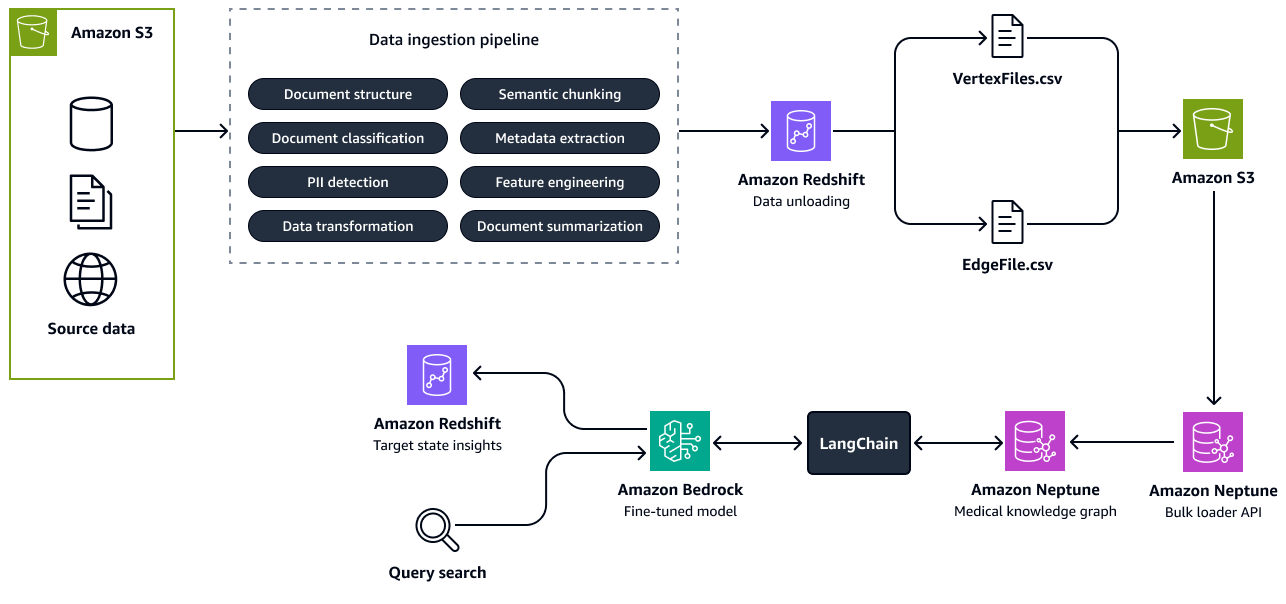
A imagem a seguir mostra as etapas para criar um gráfico de conhecimento a partir dos dados de origem. Você passa os dados de origem estruturados e não estruturados para o pipeline de ingestão de dados. O pipeline extrai e transforma as informações em uma formação de carga em massa CSV compatível com o Amazon Neptune. A API do carregador em massa carrega os arquivos CSV que estão armazenados em um bucket do Amazon S3 para o gráfico de conhecimento do Neptune. Para consultas de usuários relacionadas a talentos, futuro estado, funções ou habilidades relevantes, o LLM aperfeiçoado no Amazon Bedrock interage com o gráfico de conhecimento por meio de um LangChain orquestrador. O orquestrador recupera o contexto relevante do gráfico de conhecimento e envia as respostas para a tabela de insights no Amazon Redshift. A ferramenta LangChain um orquestrador, como o Graph QAChain
Etapa 3: Identificar lacunas de habilidades e recomendar treinamento
Nesta etapa, você calcula com precisão a proximidade entre o estado atual de um profissional de saúde e as possíveis funções do future state. Para fazer isso, você realiza uma análise de afinidade de habilidades comparando os conjuntos de habilidades do indivíduo com a função profissional. Em um banco de dados vetorial do Amazon OpenSearch Service, você armazena informações de taxonomia de habilidades e metadados de habilidades, como a descrição da habilidade, o tipo de habilidade e os grupos de habilidades. Use um modelo de incorporação do Amazon Bedrock, como os modelos Amazon Titan Text Embeddings, para incorporar a habilidade-chave identificada aos vetores. Por meio de uma pesquisa vetorial, você recupera as descrições das habilidades do estado atual e das habilidades do estado alvo e realiza uma análise ontológica. A análise fornece pontuações de proximidade entre os pares de habilidades do estado atual e do estado alvo. Para cada par, você usa as pontuações computadas da ontologia para identificar as lacunas nas afinidades de habilidades. Em seguida, você recomenda o caminho ideal para o aprimoramento de habilidades, que o candidato pode considerar durante as transições de funções.
Para cada função, recomendar o conteúdo de aprendizagem correto para aprimoramento ou requalificação envolve uma abordagem sistemática que começa com a criação de um catálogo abrangente de conteúdo de aprendizagem. Esse catálogo, que você armazena em um banco de dados do Amazon Redshift, agrega conteúdo de vários provedores e inclui metadados, como duração do conteúdo, nível de dificuldade e modo de aprendizado. A próxima etapa é extrair as principais habilidades oferecidas por cada conteúdo e, em seguida, mapeá-las de acordo com as habilidades individuais necessárias para a função alvo. Você consegue esse mapeamento analisando a cobertura fornecida pelo conteúdo por meio de uma análise de proximidade de habilidades. Essa análise avalia até que ponto as habilidades ensinadas pelo conteúdo se alinham às habilidades desejadas para a função. Os metadados desempenham um papel fundamental na seleção do conteúdo mais adequado para cada habilidade, garantindo que os alunos recebam recomendações personalizadas que atendam às suas necessidades de aprendizado. Use LLMs no Amazon Bedrock para extrair habilidades dos metadados do conteúdo, realizar engenharia de recursos e validar as recomendações de conteúdo. Isso melhora a precisão e a relevância no processo de aprimoramento ou requalificação.
Alinhamento com o AWS Well-Architected Framework
A solução está alinhada com todos os seis pilares do Well-Architected AWS Framework:
-
Excelência operacional — Um pipeline modular e automatizado aumenta a excelência operacional. Os principais componentes do pipeline são desacoplados e automatizados, permitindo atualizações mais rápidas do modelo e monitoramento mais fácil. Além disso, os canais de treinamento automatizados oferecem suporte a lançamentos mais rápidos de modelos ajustados.
-
Segurança — Essa solução processa informações confidenciais e de identificação pessoal (PII), como dados em currículos e perfis de talentos. Em AWS Identity and Access Management (IAM), implemente políticas de controle de acesso refinadas e garanta que somente funcionários autorizados tenham acesso a esses dados.
-
Confiabilidade — A solução usa Serviços da AWS, como Neptune, Amazon Bedrock e Service OpenSearch , que fornecem tolerância a falhas, alta disponibilidade e acesso ininterrupto a insights, mesmo durante alta demanda.
-
Eficiência de desempenho — Os bancos de dados vetoriais aprimorados do LLMs Amazon Bedrock and OpenSearch Service foram projetados para processar grandes conjuntos de dados com rapidez e precisão, a fim de fornecer recomendações de aprendizado personalizadas e oportunas.
-
Otimização de custos — Essa solução usa uma abordagem RAG, que reduz a necessidade de pré-treinamento contínuo dos modelos. Em vez de ajustar todo o modelo repetidamente, o sistema ajusta apenas processos específicos, como extrair informações de currículos e estruturar resultados. Isso resulta em economias de custo significativas. Ao minimizar a frequência e a escala do treinamento de modelos com uso intensivo de recursos e ao usar serviços em pay-per-use nuvem, as organizações de saúde podem otimizar seus custos operacionais e, ao mesmo tempo, manter o alto desempenho.
-
Sustentabilidade — Essa solução usa serviços escaláveis e nativos da nuvem que alocam recursos de computação dinamicamente. Isso reduz o consumo de energia e o impacto ambiental, ao mesmo tempo em que apoia iniciativas de transformação de talentos em grande escala e com uso intensivo de dados.
