As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Recuperadores para fluxos de trabalho do RAG
Esta seção explica como criar um retriever. Você pode usar uma solução de pesquisa semântica totalmente gerenciada, como o Amazon Kendra, ou criar uma pesquisa semântica personalizada usando um banco de dados vetoriais. AWS
Antes de analisar as opções do recuperador, certifique-se de compreender as três etapas do processo de pesquisa vetorial:
-
Você separa os documentos que precisam ser indexados em partes menores. Isso é chamado de fragmentação.
-
Você usa um processo chamado incorporação
para converter cada fragmento em um vetor matemático. Em seguida, você indexa cada vetor em um banco de dados vetoriais. A abordagem usada para indexar os documentos influencia a velocidade e a precisão da pesquisa. A abordagem de indexação depende do banco de dados vetoriais e das opções de configuração que ele fornece. -
Você converte a consulta do usuário em um vetor usando o mesmo processo. O recuperador pesquisa no banco de dados vetoriais por vetores semelhantes ao vetor de consulta do usuário. A similaridade
é calculada usando métricas como distância euclidiana, distância do cosseno ou produto escalar.
Este guia descreve como usar os serviços a seguir Serviços da AWS ou de terceiros para criar uma camada de recuperação personalizada em AWS:
Amazon Kendra
O Amazon Kendra é um serviço de pesquisa inteligente e totalmente gerenciado que usa processamento de linguagem natural e algoritmos avançados de aprendizado de máquina para retornar respostas específicas às perguntas de pesquisa de seus dados. O Amazon Kendra ajuda você a ingerir documentos diretamente de várias fontes e consultá-los depois de serem sincronizados com sucesso. O processo de sincronização cria a infraestrutura necessária para criar uma pesquisa vetorial no documento ingerido. Portanto, o Amazon Kendra não exige as três etapas tradicionais do processo de busca vetorial. Após a sincronização inicial, você pode usar um cronograma definido para lidar com a ingestão contínua.
A seguir estão as vantagens de usar o Amazon Kendra para RAG:
-
Você não precisa manter um banco de dados vetoriais porque o Amazon Kendra gerencia todo o processo de pesquisa vetorial.
-
O Amazon Kendra contém conectores pré-criados para fontes de dados populares, como bancos de dados, rastreadores de sites, buckets, instâncias e instâncias do Amazon S3. Microsoft SharePoint Atlassian Confluence Conectores desenvolvidos por AWS parceiros estão disponíveis, como conectores para e. Box GitLab
-
O Amazon Kendra fornece filtragem de lista de controle de acesso (ACL) que retorna somente documentos aos quais o usuário final tem acesso.
-
O Amazon Kendra pode impulsionar as respostas com base em metadados, como data ou repositório de origem.
A imagem a seguir mostra um exemplo de arquitetura que usa o Amazon Kendra como a camada de recuperação do sistema RAG. Para obter mais informações, consulte Crie rapidamente aplicativos de IA generativa de alta precisão em dados corporativos usando Amazon Kendra LangChain e grandes modelos de linguagem (postagem
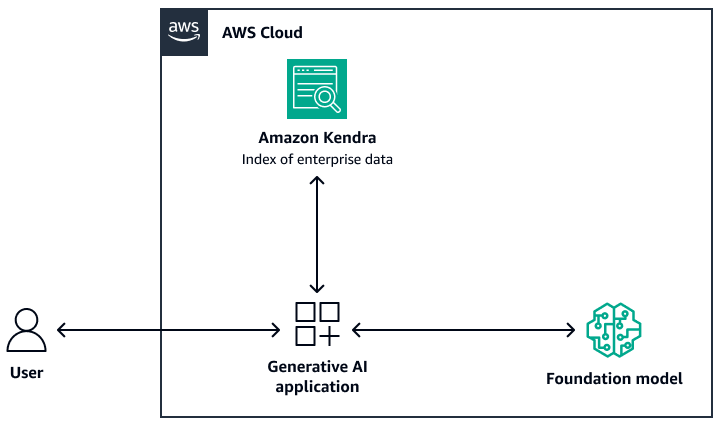
Para o modelo básico, você pode usar o Amazon Bedrock ou um LLM implantado por meio do Amazon AI. SageMaker JumpStart Você pode usar AWS Lambda with LangChain
OpenSearch Serviço Amazon
O Amazon OpenSearch Service fornece algoritmos de ML integrados para pesquisas de k vizinhos mais próximos (k-NN) a fim de realizar uma pesquisa
A seguir estão as vantagens de usar o OpenSearch Service para pesquisa vetorial:
-
Ele fornece controle total sobre o banco de dados vetoriais, incluindo a criação de uma pesquisa vetorial escalável usando o OpenSearch Serverless.
-
Ele fornece controle sobre a estratégia de fragmentação.
-
Ele usa algoritmos de vizinho mais próximo aproximado (ANN) das bibliotecas Non-Metric Space Library (NMSLIB)
, Faiss e Apache Lucene para potencializar uma pesquisa k-NN. Você pode alterar o algoritmo com base no caso de uso. Para obter mais informações sobre as opções para personalizar a pesquisa vetorial por meio do OpenSearch Service, consulte Explicação sobre os recursos do banco de dados vetoriais do Amazon OpenSearch Service (postagem AWS no blog). -
OpenSearch O Serverless se integra às bases de conhecimento do Amazon Bedrock como um índice vetorial.
Amazon Aurora PostgreSQL e pgvector
A edição compatível com o Amazon Aurora PostgreSQL é um mecanismo de banco de dados relacional totalmente gerenciado que ajuda você a configurar, operar e escalar implantações do PostgreSQL. pgvector
Veja a seguir as vantagens de usar pgvector e Aurora PostgreSQL compatíveis:
-
Ele suporta a pesquisa exata e aproximada do vizinho mais próximo. Ele também suporta as seguintes métricas de similaridade: distância L2, produto interno e distância do cosseno.
-
Ele suporta arquivo invertido com compressão plana (IVFFlat)
e indexação hierárquica de mundos pequenos navegáveis ( HNSW). -
Você pode combinar a pesquisa vetorial com consultas sobre dados específicos do domínio que estão disponíveis na mesma instância do PostgreSQL.
-
O Aurora compatível com PostgreSQL é otimizado e fornece armazenamento em cache em camadas. I/O Para cargas de trabalho que excedem a memória de instância disponível, o pgvector pode aumentar as consultas por segundo para pesquisa vetorial em até 8 vezes.
Amazon Neptune Analytics
O Amazon Neptune Analytics é um mecanismo de banco de dados gráfico otimizado para memória para análise. Ele oferece suporte a uma biblioteca de algoritmos analíticos gráficos otimizados, consultas gráficas de baixa latência e recursos de pesquisa vetorial em travessias de gráficos. Ele também possui pesquisa de similaridade vetorial integrada. Ele fornece um ponto final para criar um gráfico, carregar dados, invocar consultas e realizar pesquisas de similaridade vetorial. Para obter mais informações sobre como criar um sistema baseado em RAG que usa o Neptune Analytics, consulte Usando gráficos de conhecimento para criar aplicativos GraphRag com o Amazon Bedrock e o Amazon
A seguir estão as vantagens de usar o Neptune Analytics:
-
Você pode armazenar e pesquisar incorporações em consultas gráficas.
-
Se você integrar o Neptune Analytics LangChain com, essa arquitetura oferece suporte a consultas gráficas em linguagem natural.
-
Essa arquitetura armazena grandes conjuntos de dados gráficos na memória.
Amazon MemoryDB
O Amazon MemoryDB é um serviço de banco de dados em memória durável que oferece desempenho ultrarrápido. Todos os seus dados são armazenados na memória, que suporta leitura em microssegundos, latência de gravação de um dígito em milissegundos e alta taxa de transferência. A pesquisa vetorial do MemoryDB amplia a funcionalidade do MemoryDB e pode ser usada em conjunto com a funcionalidade existente do MemoryDB. Para obter mais informações, consulte a Resposta de perguntas com o repositório LLM e RAG ativado
O diagrama a seguir mostra um exemplo de arquitetura que usa o MemoryDB como banco de dados vetorial.
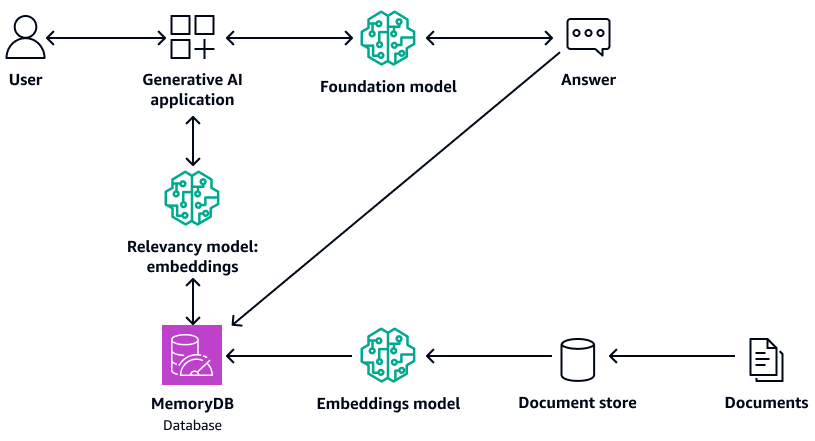
A seguir estão as vantagens de usar o MemoryDB:
-
Ele suporta algoritmos de indexação Flat e HNSW. Para obter mais informações, consulte A pesquisa vetorial do Amazon MemoryDB agora está disponível ao público em geral
no AWS blog de notícias -
Ele também pode atuar como uma memória de buffer para o modelo básico. Isso significa que as perguntas respondidas anteriormente são recuperadas do buffer em vez de passarem pelo processo de recuperação e geração novamente. O diagrama a seguir mostra esse processo.
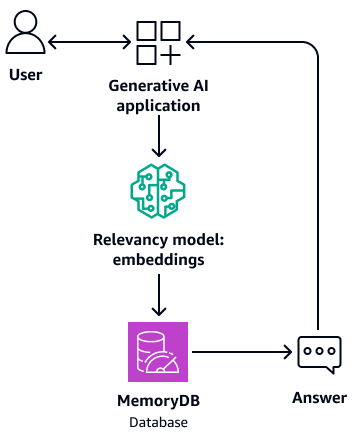
-
Como usa um banco de dados na memória, essa arquitetura fornece um tempo de consulta de milissegundos de um dígito para a pesquisa semântica.
-
Ele fornece até 33.000 consultas por segundo com 95— 99% de recall e 26.500 consultas por segundo com mais de 99% de recall. Para obter mais informações, consulte o vídeo AWS re:Invent 2023 - Pesquisa vetorial de latência ultrabaixa para Amazon
MemoryDB em. YouTube
Amazon DocumentDB
O Amazon DocumentDB (compatível com MongoDB) é um serviço de banco de dados rápido, confiável e inteiramente gerenciado. Ele facilita a configuração, a operação e a escalabilidade de bancos MongoDB de dados compatíveis na nuvem. A pesquisa vetorial do Amazon DocumentDB combina a flexibilidade e a rica capacidade de consulta de um banco de dados de documentos baseado em JSON com o poder da pesquisa vetorial. Para obter mais informações, consulte a Resposta de perguntas com o repositório LLM e RAG ativado
O diagrama a seguir mostra um exemplo de arquitetura que usa o Amazon DocumentDB como banco de dados vetoriais.
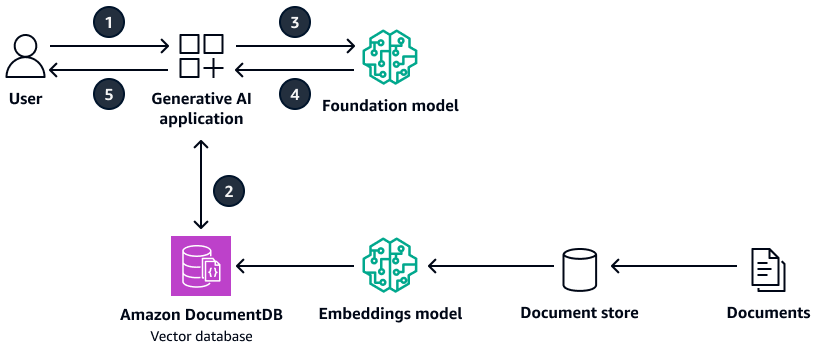
O diagrama mostra o seguinte fluxo de trabalho:
-
O usuário envia uma consulta para o aplicativo generativo de IA.
-
O aplicativo generativo de IA realiza uma pesquisa por similaridade no banco de dados vetorial Amazon DocumentDB e recupera os extratos relevantes do documento.
-
O aplicativo generativo de IA atualiza a consulta do usuário com o contexto recuperado e envia a solicitação ao modelo básico de destino.
-
O modelo básico usa o contexto para gerar uma resposta à pergunta do usuário e retorna a resposta.
-
O aplicativo generativo de IA retorna a resposta ao usuário.
A seguir estão as vantagens de usar o Amazon DocumentDB:
-
Ele suporta tanto o HNSW quanto os métodos de IVFFlat indexação.
-
Ele suporta até 2.000 dimensões nos dados vetoriais e suporta as métricas de distância do produto euclidiano, cosseno e ponto.
-
Ele fornece tempos de resposta em milissegundos.
Pinecone
Pinecone
O diagrama a seguir mostra uma arquitetura de exemplo usada Pinecone como banco de dados vetoriais.
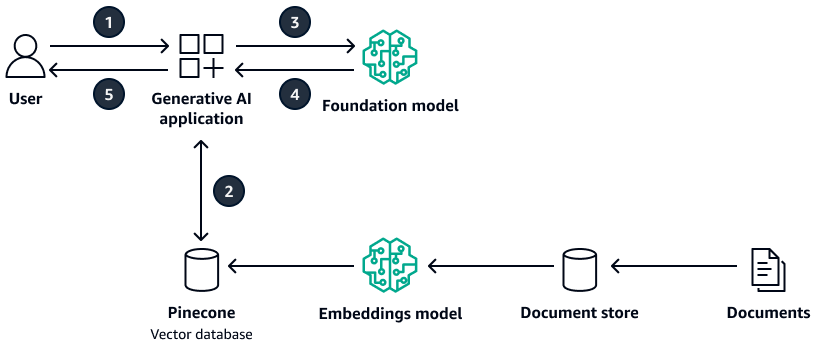
O diagrama mostra o seguinte fluxo de trabalho:
-
O usuário envia uma consulta para o aplicativo generativo de IA.
-
O aplicativo generativo de IA realiza uma pesquisa por similaridade no banco de dados Pinecone vetorial e recupera os extratos relevantes do documento.
-
O aplicativo generativo de IA atualiza a consulta do usuário com o contexto recuperado e envia a solicitação ao modelo básico de destino.
-
O modelo básico usa o contexto para gerar uma resposta à pergunta do usuário e retorna a resposta.
-
O aplicativo generativo de IA retorna a resposta ao usuário.
A seguir estão as vantagens de usarPinecone:
-
É um banco de dados vetorial totalmente gerenciado e elimina a sobrecarga de gerenciar sua própria infraestrutura.
-
Ele fornece os recursos adicionais de filtragem, atualizações dinâmicas de índices e aumento de palavras-chave (pesquisa híbrida).
MongoDB Atlas
MongoDB
Atlas
Para obter mais informações sobre como usar a pesquisa MongoDB Atlas vetorial para RAG, consulte Retrieval-Augmented Generation with, LangChain Amazon SageMaker AI e MongoDB Atlas Semantic Search ( JumpStartpostagem
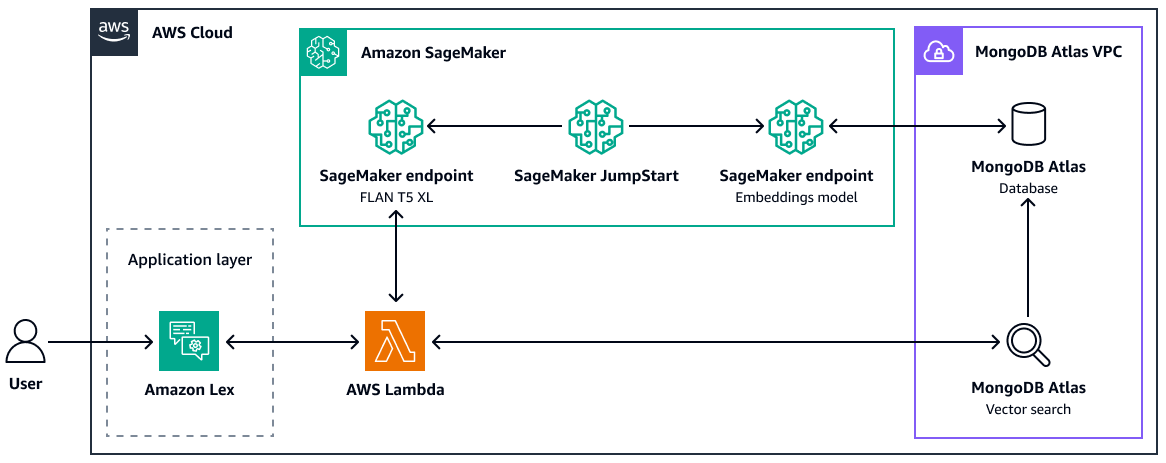
A seguir estão as vantagens de usar a pesquisa MongoDB Atlas vetorial:
-
Você pode usar sua implementação existente do MongoDB Atlas para armazenar e pesquisar incorporações vetoriais.
-
Você pode usar a API de MongoDB consulta
para consultar as incorporações vetoriais. -
Você pode escalar de forma independente a pesquisa vetorial e o banco de dados.
-
As incorporações vetoriais são armazenadas perto dos dados de origem (documentos), o que melhora o desempenho da indexação.
Weaviate
Weaviate
A seguir estão as vantagens de usarWeaviate:
-
É de código aberto e apoiado por uma comunidade forte.
-
Ele foi criado para pesquisa híbrida (vetores e palavras-chave).
-
Você pode implantá-lo AWS como uma oferta gerenciada de software como serviço (SaaS) ou como um cluster Kubernetes.
