As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Arquitetura
O diagrama a seguir mostra a arquitetura da solução descrita neste guia. Um AWS Glue trabalho lê dados de um bucket do Amazon Simple Storage Service (Amazon S3), que é um serviço de armazenamento de objetos baseado em nuvem que ajuda você a armazenar, proteger e recuperar dados. Você pode iniciar o AWS Glue Spark SQL trabalho por meio do AWS Management Console, AWS Command Line Interface (AWS CLI) ou da AWS Glue API. O AWS Glue Spark SQL job processa os dados brutos em um bucket do Amazon S3 e, em seguida, armazena os dados processados em um bucket diferente.
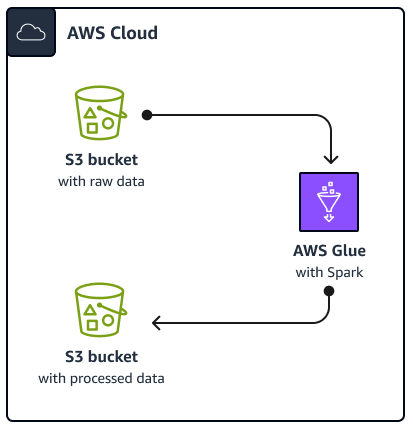
Para fins de exemplo, este guia descreve um básico AWS GlueSpark SQL trabalho, que está escrito em Python and Spark SQL (PySpark). Esse AWS Glue trabalho é usado para demonstrar as melhores práticas para Spark SQL afinação. Embora este guia se concentre em AWS Glue, as melhores práticas deste guia também se aplicam ao Amazon EMR Spark SQL empregos.
O diagrama a seguir mostra o ciclo de vida de um Spark SQL consulta. A ferramenta Spark SQL O Catalyst Optimizer gera um plano de consulta. Um plano de consulta é uma série de etapas, como instruções, usadas para acessar os dados em um sistema de banco de dados relacional SQL. Para desenvolver um desempenho otimizado Spark
SQL plano de consulta, a primeira etapa é visualizar o EXPLAIN plano, interpretar o plano e, em seguida, ajustar o plano. Você pode usar o Spark SQL interface de usuário (UI) ou o Spark SQL Servidor de histórico para visualizar o plano.
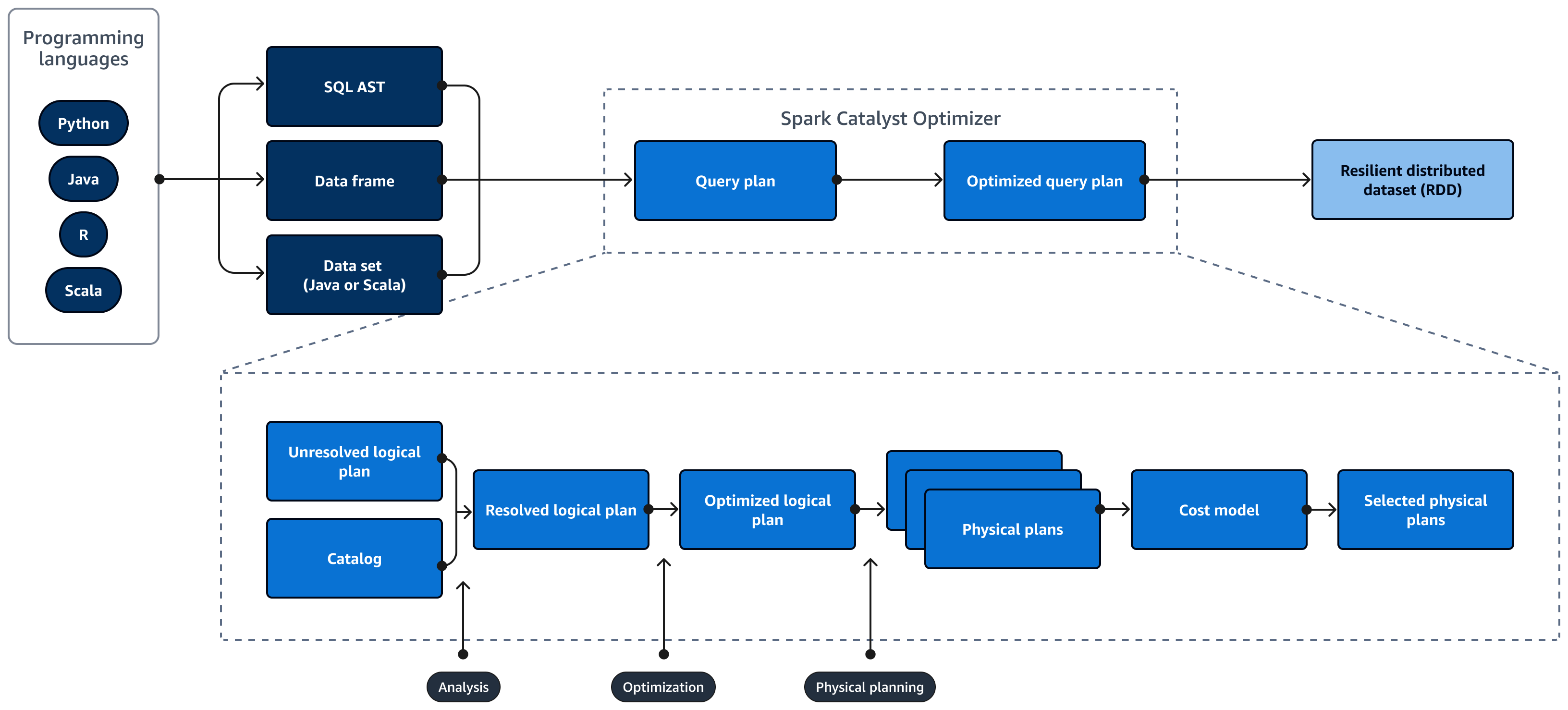
Spark O Catalyst Optimizer converte o plano de consulta inicial em um plano de consulta otimizado da seguinte forma:
-
Análise e declaração APIs — A fase de análise é a primeira etapa. O plano lógico não resolvido, em que os objetos referenciados na consulta SQL não são conhecidos ou não correspondem a uma tabela de entrada, é gerado com atributos e tipos de dados não vinculados. A ferramenta Spark SQL Em seguida, o Catalyst Optimizer aplica um conjunto de regras para criar um plano lógico. O analisador SQL pode gerar uma Árvore de Sintaxe Abstrata SQL (AST) e fornecê-la como uma entrada para o plano lógico. A entrada também pode ser um quadro de dados ou um objeto de conjunto de dados que é construído usando uma API. A tabela a seguir mostra quando você deve usar SQL, quadros de dados ou conjuntos de dados.
SQL Quadros de dados Conjuntos de dados Erros de sintaxe Runtime Tempo de compilação Tempo de compilação Erros de análise Runtime Runtime Tempo de compilação Para obter mais informações sobre os tipos de entradas, consulte o seguinte:
-
Uma API de conjunto de dados fornece uma versão digitada. Isso reduz o desempenho devido à forte dependência das funções lambda definidas pelo usuário. O RDD ou os conjuntos de dados são digitados estaticamente. Por exemplo, ao definir um RDD, você precisa fornecer explicitamente a definição do esquema.
-
Uma API de quadro de dados fornece operações relacionais não digitadas. Os quadros de dados são digitados dinamicamente. Semelhante ao RDD, quando você define um quadro de dados, o esquema permanece o mesmo. Os dados ainda estão estruturados. No entanto, essas informações só estão disponíveis em tempo de execução. Isso permite que o compilador escreva instruções semelhantes a SQL e defina novas colunas em tempo real. Por exemplo, ele pode acrescentar colunas a um quadro de dados existente sem precisar definir uma nova classe para cada operação.
-
A Spark SQL a consulta é avaliada quanto a erros de sintaxe e análise durante o tempo de execução, o que proporciona tempos de execução mais rápidos.
-
-
Catálogo —Spark SQL uses Apache Hive Metastore (HMS) para gerenciar os metadados de entidades relacionais persistentes, como bancos de dados, tabelas, colunas e partições.
-
Otimização — O otimizador reescreve o plano de consulta usando heurística e custo. Ele faz o seguinte para produzir um plano lógico otimizado:
-
Colunas de ameixas
-
Reduz os predicados
-
Reordena uniões
-
-
Planos físicos e o planejador — Spark SQL O Catalyst Optimizer converte o plano lógico em um conjunto de planos físicos. Isso significa que ele converte o quê em como.
-
Planos físicos selecionados — Spark SQL O Catalyst Optimizer seleciona o plano físico mais econômico.
-
Plano de consulta otimizado — Spark SQL executa o plano de consulta otimizado para desempenho e custo otimizado. Spark SQL O Gerenciamento de Memória rastreia o uso da memória e distribui a memória entre tarefas e operadores. A ferramenta Spark SQL O motor de tungstênio pode melhorar substancialmente a eficiência da memória e da CPU para Spark SQL aplicações. Ele também implementa o processamento de modelos de dados binários e opera diretamente em dados binários. Isso ignora a necessidade de desserialização e reduz significativamente a sobrecarga associada à conversão e desserialização de dados.
