O Amazon Redshift não permitirá mais a criação de funções definidas pelo usuário (UDFs) do Python a partir de 1.º de novembro de 2025. Se quiser usar UDFs do Python, você deve criá-las antes dessa data. As UDFs do Python existentes continuarão a funcionar normalmente. Para ter mais informações, consulte a publicação de blog
Carregamento de dados de hosts remotos
Você pode usar o comando COPY para carregar dados em paralelo de um ou mais hosts remotos, como instâncias do Amazon EC2 ou outros computadores. O COPY se conecta aos hosts remotos usando SSH e executa comandos nos hosts remotos para gerar a saída de texto.
O host remoto pode ser uma instância do Amazon EC2 Linux ou outro computador Unix ou Linux configurado para aceitar conexões SSH. Este guia assume que seu host remoto é uma instância do Amazon EC2. Quando o procedimento for diferente para outro computador, o guia indicará a diferença.
O Amazon Redshift pode conectar-se a vários hosts e abrir várias conexões SSH para cada host. O Amazon Redshifts envia um comando exclusivo por meio de cada conexão a fim de gerar saída de texto para a saída padrão do host, que o Amazon Redshift lê como faria com um arquivo de texto.
Antes de começar
Antes de começar, você deve ter o seguinte:
-
Uma ou mais máquinas host, como instâncias do Amazon EC2, às quais você pode se conectar usando SSH.
-
Fontes de dados nos hosts.
Você fornecerá comandos que o cluster do Amazon Redshift executará nos hosts para gerar a saída de texto. Depois que o cluster se conecta a um host, o comando COPY executa os comandos, lê o texto da saída padrão dos hosts e carrega os dados em paralelo em uma tabela do Amazon Redshift. A saída de texto deve estar em um formulário que o comando COPY possa ingerir. Para obter mais informações, consulte Preparação de dados de entrada
-
Acesso aos hosts para seu computador.
Para uma instância do Amazon EC2, você usará uma conexão SSH para acessar o host. Você precisará acessar o host para adicionar a chave pública do cluster do Amazon Redshift ao arquivo de chaves autorizadas do host.
-
Um cluster do Amazon Redshift em execução.
Para obter informações sobre como iniciar um cluster, consulte o Guia de conceitos básicos do Amazon Redshift.
Processo de carregamento de dados
Esta seção orienta você pelo processo de carregamento de dados de hosts remotos. As seções a seguir fornecem os detalhes de que você precisa para realizar cada etapa.
-
Etapa 1: Recuperar a chave pública do cluster e os endereços IP dos nós do cluster
A chave pública permite que os nós de cluster do Amazon Redshift estabeleçam conexões SSH com os hosts remotos. Você usará o endereço IP de cada nó do cluster para configurar os grupos de segurança do host ou firewall para permitir o acesso de seu cluster Amazon Redshift usando esses endereços IP.
-
Você adiciona a chave pública do cluster do Amazon Redshift ao arquivo de chaves autorizadas do host para que o host reconheça o cluster do Amazon Redshift e aceite a conexão SSH.
-
Etapa 3: Configurar o host para aceitar todos os endereços IP do cluster do Amazon Redshift
Para Amazon EC2, modifique os grupos de segurança da instância para adicionar regras de entrada para aceitar os endereços IP do Amazon Redshift. Para outros hosts, modifique o firewall para que os nós do Amazon Redshift possam estabelecer conexões SSH com o host remoto.
-
Etapa 4: Obter a chave pública para o host
Você pode, opcionalmente, especificar que o Amazon Redshift deve usar a chave pública para identificar o host. Você precisará localizar a chave pública e copiar o texto em seu arquivo de manifesto.
-
Etapa 5: Criar um arquivo manifesto
O manifesto é um arquivo de texto formatado em JSON com os detalhes de que o Amazon Redshift precisa para se conectar aos hosts e buscar os dados.
-
Etapa 6: Carregar o arquivo manifesto para um bucket do Amazon S3
O Amazon Redshift lê o manifesto e usa essas informações para se conectar ao host remoto. Se o bucket do Amazon S3 não residir na mesma região que seu cluster Amazon Redshift, você deve usar a opção REGION para especificar a região na qual os dados estão localizados.
-
Etapa 7: Executar o comando COPY para carregar os dados
De um banco de dados do Amazon Redshift, execute o comando COPY para carregar os dados em uma tabela do Amazon Redshift.
Etapa 1: Recuperar a chave pública do cluster e os endereços IP dos nós do cluster
Você usará o endereço IP de cada nó do cluster para configurar os grupos de segurança do host para permitir o acesso de seu cluster Amazon Redshift usando esses endereços IP.
Para recuperar a chave pública do cluster e os endereços IP dos nós de seu cluster usando o console
-
Acesse o Console de Gerenciamento do Amazon Redshift.
-
No painel de navegação, selecione o link Clusters.
-
Selecione seu cluster na lista.
-
Localize o grupo Configurações de ingestão do SSH.
Observe a Chave pública do cluster e Endereços IP dos nós. Você vai usá-los em etapas subsequentes.
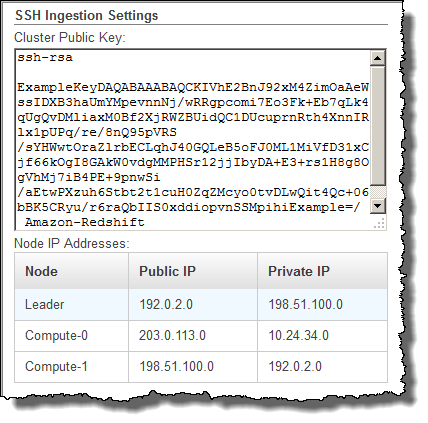
Você usará os endereços IP na Etapa 3 para configurar o host para aceitar a conexão do Amazon Redshift. Dependendo à qual tipo de host você se conectar e se ele está em uma VPC, você usará endereços IP públicos ou endereços IP privados.
Para recuperar a chave pública do cluster e os endereços IP do nó do cluster para seu cluster usando a CLI do Amazon Redshift, execute o comando describe-clusters.
Por exemplo:
aws redshift describe-clusters --cluster-identifier <cluster-identifier>
A resposta incluirá o valor de ClusterPublicKey e a lista de endereços IP privados e públicos, semelhante ao seguinte:
{ "Clusters": [ { "VpcSecurityGroups": [], "ClusterStatus": "available", "ClusterNodes": [ { "PrivateIPAddress": "10.nnn.nnn.nnn", "NodeRole": "LEADER", "PublicIPAddress": "10.nnn.nnn.nnn" }, { "PrivateIPAddress": "10.nnn.nnn.nnn", "NodeRole": "COMPUTE-0", "PublicIPAddress": "10.nnn.nnn.nnn" }, { "PrivateIPAddress": "10.nnn.nnn.nnn", "NodeRole": "COMPUTE-1", "PublicIPAddress": "10.nnn.nnn.nnn" } ], "AutomatedSnapshotRetentionPeriod": 1, "PreferredMaintenanceWindow": "wed:05:30-wed:06:00", "AvailabilityZone": "us-east-1a", "NodeType": "dc2.large", "ClusterPublicKey": "ssh-rsa AAAABexamplepublickey...Y3TAl Amazon-Redshift", ... ... }
Para recuperar a chave pública do cluster e os endereços IP do nó do cluster para o seu cluster usando a API Amazon Redshift, use a ação DescribeClusters. Para obter mais informações, consulte describe-clusters no Guia de CLI do Amazon Redshift ou DescribeClusters no Guia de API do Amazon Redshift.
Etapa 2: Adicionar a chave pública do cluster do Amazon Redshift ao arquivo de chaves autorizadas do host
Você adiciona a chave pública do cluster ao arquivo de chaves autorizadas de cada host para que o host reconheça o Amazon Redshift e aceite a conexão SSH.
Para adicionar a chave pública do cluster do Amazon Redshift ao arquivo de chaves autorizadas do host
-
Acesse o host usando uma conexão SSH.
Para obter informações sobre como se conectar a uma instância usando SSH, consulte Conectar-se à instância do Linux no Manual do usuário do Amazon EC2.
-
Copie a chave pública do Amazon Redshift do console ou do texto de resposta da CLI.
-
Copie e cole os conteúdos da chave pública no arquivo
/home/<ssh_username>/.ssh/authorized_keysno host remoto. O<ssh_username>deve corresponder ao valor do campo "nome de usuário" no arquivo manifesto. Inclua a string completa com o prefixo “ssh-rsa” e o sufixo “Amazon-Redshift”. Por exemplo:ssh-rsa AAAACTP3isxgGzVWoIWpbVvRCOzYdVifMrh… uA70BnMHCaMiRdmvsDOedZDOedZ Amazon-Redshift
Etapa 3: Configurar o host para aceitar todos os endereços IP do cluster do Amazon Redshift
Se você estiver trabalhando com uma instância do Amazon EC2 ou um cluster do Amazon EMR, adicione regras de entrada ao grupo de segurança do host para permitir o tráfego de cada nó do cluster do Amazon Redshift. Para Tipo, selecione SSH com protocolo TCP na porta 22. Para Fonte, insira os endereços IP do nó do cluster do Amazon Redshift que você recuperou em Etapa 1: Recuperar a chave pública do cluster e os endereços IP dos nós do cluster. Para obter informações sobre como adicionar regras a um grupo de segurança do Amazon EC2, consulte Autorizar tráfego de entrada para as instâncias no Manual do usuário do Amazon EC2.
Use os endereços IP privados quando:
-
Você tem um cluster do Amazon Redshift que não está em uma Virtual Private Cloud (VPC) e uma instância do Amazon EC2-Classic, ambos na mesma região da AWS.
-
Você tem um cluster do Amazon Redshift que está em um VPC e uma instância do Amazon EC2 -VPC, ambos na mesma região da AWS e no mesmo VPC.
Caso contrário, use os endereços IP públicos.
Para obter mais informações sobre como usar o Amazon Redshift em uma VPC, consulte “Gerenciamento de clusters em uma VPC” no Guia de gerenciamento de clusters do Amazon Redshift.
Etapa 4: Obter a chave pública para o host
Opcionalmente, você pode fornecer a chave pública do host no arquivo de manifesto para que o Amazon Redshift possa identificar o host. O comando COPY não requer a chave pública do host, mas por motivo de segurança, recomendamos veementemente o uso de uma chave pública para ajudar a evitar ataques “man-in-the-middle”.
Você pode encontrar a chave pública do host no seguinte local, onde <ssh_host_rsa_key_name> é o nome exclusivo para a chave pública do host:
: /etc/ssh/<ssh_host_rsa_key_name>.pub
nota
O Amazon Redshift é compatível somente com chaves RSA. Não oferecemos suporte para chaves DSA.
Ao criar seu arquivo manifesto na etapa 5, você colará o texto da chave pública no campo “chave pública” na entrada do arquivo manifesto.
Etapa 5: Criar um arquivo manifesto
O comando COPY pode conectar-se a vários hosts usando SSH e criar várias conexões SSH para cada host. O COPY executa um comando em cada conexão do host e carrega a saída dos comandos para a tabela em paralelo. O arquivo manifesto é um arquivo de texto no formato JSON que o Amazon Redshift usa para se conectar ao host. O arquivo manifesto especifica os endpoints do host SSH e os comandos que serão executados nos hosts para retornar dados ao Amazon Redshift. Você também pode incluir a chave pública do host, o nome de usuário de login e um sinalizador obrigatório para cada entrada.
Crie o arquivo manifesto no computador local. Em uma etapa posterior, você carrega o arquivo no Amazon S3.
O arquivo manifesto está no seguinte formato:
{ "entries": [ {"endpoint":"<ssh_endpoint_or_IP>", "command": "<remote_command>", "mandatory":true, "publickey": "<public_key>", "username": "<host_user_name>"}, {"endpoint":"<ssh_endpoint_or_IP>", "command": "<remote_command>", "mandatory":true, "publickey": "<public_key>", "username": "host_user_name"} ] }
O arquivo manifesto contém um construto "entradas" para cada conexão SSH. Cada entrada representa uma única conexão SSH. Você pode ter várias conexões para um único host ou várias conexões para vários hosts. As aspas duplas são obrigatórias conforme mostrado, tanto para os nomes dos campos quanto para os valores. O único valor que não precisa de aspas duplas é o valor booleano true ou false para o campo obrigatório.
Veja a seguir as descrições dos campos no arquivo manifesto.
- endpoint
-
O endereço URL ou endereço IP do host. Por exemplo, "
ec2-111-222-333.compute-1.amazonaws.com" ou "22.33.44.56" - command
-
O comando que será executado pelo host para gerar a saída de texto ou a saída binária (gzip, lzop ou bzip2). O comando pode ser qualquer um que o usuário "host_user_name" tenha permissão para executar. O comando pode ser tão simples quanto imprimir um arquivo ou pode ser consultar um banco de dados ou iniciar um script. A saída (arquivo de texto, arquivo binário gzip, arquivo binário lzop ou arquivo bzip2) deve estar em um formato que o comando COPY do Amazon Redshift possa ingerir. Para obter mais informações, consulte Preparação de dados de entrada.
- publickey
-
(Opcional) A chave pública do host. Se fornecida, o Amazon Redshift usará a chave pública para identificar o host. Se a chave pública não for fornecida, o Amazon Redshift não tentará a identificação do host. Por exemplo, se a chave pública do host remoto for:
ssh-rsa AbcCbaxxx…xxxDHKJ root@amazon.com, insira o seguinte texto no campo de chave pública:AbcCbaxxx…xxxDHKJ. - mandatory
-
(Opcional) Indica se o comando COPY deve falhar se a conexão falhar. O padrão é
false. Se o Amazon Redshift não fizer com sucesso pelo menos uma conexão, o comando COPY falhará. - username
-
(Opcional) O nome de usuário que será utilizado para fazer logon no sistema do host e executar o comando remoto. O nome de login do usuário deve ser o mesmo do login que foi usado para adicionar a chave pública ao arquivo de chaves autorizadas do host na etapa 2. O nome de usuário padrão é "redshift".
O exemplo a seguir mostra um manifesto concluído para abrir quatro conexões ao mesmo host e executar um comando diferente em cada conexão:
{ "entries": [ {"endpoint":"ec2-184-72-204-112.compute-1.amazonaws.com", "command": "cat loaddata1.txt", "mandatory":true, "publickey": "ec2publickeyportionoftheec2keypair", "username": "ec2-user"}, {"endpoint":"ec2-184-72-204-112.compute-1.amazonaws.com", "command": "cat loaddata2.txt", "mandatory":true, "publickey": "ec2publickeyportionoftheec2keypair", "username": "ec2-user"}, {"endpoint":"ec2-184-72-204-112.compute-1.amazonaws.com", "command": "cat loaddata3.txt", "mandatory":true, "publickey": "ec2publickeyportionoftheec2keypair", "username": "ec2-user"}, {"endpoint":"ec2-184-72-204-112.compute-1.amazonaws.com", "command": "cat loaddata4.txt", "mandatory":true, "publickey": "ec2publickeyportionoftheec2keypair", "username": "ec2-user"} ] }
Etapa 6: Carregar o arquivo manifesto para um bucket do Amazon S3
Carregue o arquivo manifesto para um bucket do Amazon S3. Se o bucket do Amazon S3 não residir na mesma região da AWS que seu cluster do Amazon Redshift, você deve usar a opção REGION para especificar a região da AWS na qual o manifesto está localizado. Para obter informações sobre como criar um bucket do Amazon S3 e carregar um arquivo, consulte Guia do usuário do Amazon Simple Storage Service.
Etapa 7: Executar o comando COPY para carregar os dados
Execute um comando COPY para conectar-se ao host e carregar os dados em uma tabela do Amazon Redshift. No comando COPY, especifique o caminho do objeto Amazon S3 explícito para o arquivo manifesto e inclua a opção SSH. Por exemplo,
COPY sales FROM 's3://amzn-s3-demo-bucket/ssh_manifest' IAM_ROLE 'arn:aws:iam::0123456789012:role/MyRedshiftRole' DELIMITER '|' SSH;
nota
Se você usar a compactação automática, o comando COPY realizará duas leituras de dados, ou seja, executará o comando remoto duas vezes. A primeira leitura é para fornecer um exemplo para a análise de compactação e a segunda leitura efetivamente carrega os dados. Se a execução do comando remoto duas vezes causar um problema devido a possíveis efeitos colaterais, você deverá desativar a compactação automática. Para desativar a compactação automática, execute o comando COPY com a opção COMPUPDATE definida como desativado. Para obter mais informações, consulte Carregamento de tabelas com compactação automática.
